By Altexsoft.
Utrzymanie klienta jest jednym z podstawowych filarów wzrostu dla produktów z modelem biznesowym opartym na subskrypcji. Konkurencja jest silna na rynku SaaS, gdzie klienci mogą wybierać spośród wielu dostawców, nawet w obrębie jednej kategorii produktów. Kilka złych doświadczeń – lub nawet jedno – i klient może zrezygnować. A jeśli rzesze niezadowolonych klientów będą rezygnować, zarówno straty materialne, jak i uszczerbek na reputacji będą ogromne.
W tym artykule skontaktowaliśmy się z ekspertami z HubSpot i ScienceSoft, aby porozmawiać o tym, jak firmy SaaS radzą sobie z problemem rezygnacji klientów za pomocą modelowania predykcyjnego. Poznasz podejścia i najlepsze praktyki do rozwiązywania tego problemu. Omówimy zbieranie danych o relacjach klientów z marką, charakterystykę zachowań klientów, które najbardziej korelują z rezygnacją, a także zbadamy logikę stojącą za wyborem najlepiej działających modeli uczenia maszynowego.
- Co to jest wskaźnik rezygnacji klientów?
- Impact of customer churn on businesses
- Przypadki użycia do przewidywania rezygnacji klientów
- Identyfikacja zagrożonych klientów za pomocą uczenia maszynowego: rozwiązywanie problemów w skrócie
- Predicting customer churn with machine learning
- Zrozumienie problemu i cel końcowy
- Gromadzenie danych
- Przygotowanie i wstępne przetwarzanie danych
- Modelowanie i testowanie
- Wdrażanie i monitorowanie
- Wniosek
Co to jest wskaźnik rezygnacji klientów?
Klient rezygnuje (lub customer attrition) to tendencja klientów do porzucania marki i zaprzestania bycia płacącym klientem danej firmy. Odsetek klientów, którzy zaprzestają korzystania z produktów lub usług firmy w określonym czasie, nazywany jest wskaźnikiem rezygnacji klienta (attrition). Jednym ze sposobów obliczenia wskaźnika rezygnacji jest podzielenie liczby klientów utraconych w danym przedziale czasowym przez liczbę klientów pozyskanych, a następnie pomnożenie tej liczby przez 100 procent. Na przykład, jeśli zdobyłeś 150 klientów i straciłeś trzech w zeszłym miesiącu, to Twój miesięczny wskaźnik rezygnacji wynosi 2 procent.
Wskaźnik rezygnacji jest wskaźnikiem zdrowia dla firm, których klienci są abonentami i płacą za usługi na zasadzie powtarzalności, zauważa szef działu analityki danych w ScienceSoft Alex Bekker, „Klienci decydują się na produkt lub usługę na konkretny okres, który może być raczej krótki – powiedzmy, miesiąc. Dzięki temu klient pozostaje otwarty na ciekawsze lub korzystniejsze oferty. Ponadto, za każdym razem, gdy kończy się ich obecne zobowiązanie, klienci mają szansę ponownie rozważyć i zdecydować się nie kontynuować współpracy z firmą. Oczywiście, pewien naturalny churn jest nieunikniony, a liczba ta różni się w zależności od branży. Jednak wyższy wskaźnik rezygnacji jest wyraźnym sygnałem, że firma robi coś nie tak.”
Jest wiele rzeczy, które marki mogą robić źle, od skomplikowanego onboardingu, kiedy klienci nie otrzymują łatwych do zrozumienia informacji na temat użytkowania produktu i jego możliwości, po słabą komunikację, np. brak informacji zwrotnej lub opóźnione odpowiedzi na zapytania. Inna sytuacja: Długoletni klienci mogą czuć się niedoceniani, ponieważ nie otrzymują tylu bonusów, co nowi.
Ogólnie rzecz biorąc, to ogólne doświadczenie klienta definiuje postrzeganie marki i wpływa na to, jak klienci rozpoznają stosunek wartości do ceny produktów lub usług, z których korzystają.
Rzeczywistość jest taka, że nawet lojalni klienci nie będą tolerować marki, jeśli mieli z nią jeden lub kilka problemów. Na przykład, 59 procent amerykańskich respondentów badania przeprowadzonego przez PricewaterhouseCoopers (PwC) zauważyło, że pożegna się z marką po kilku złych doświadczeniach, a 17 procent z nich po zaledwie jednym złym doświadczeniu.
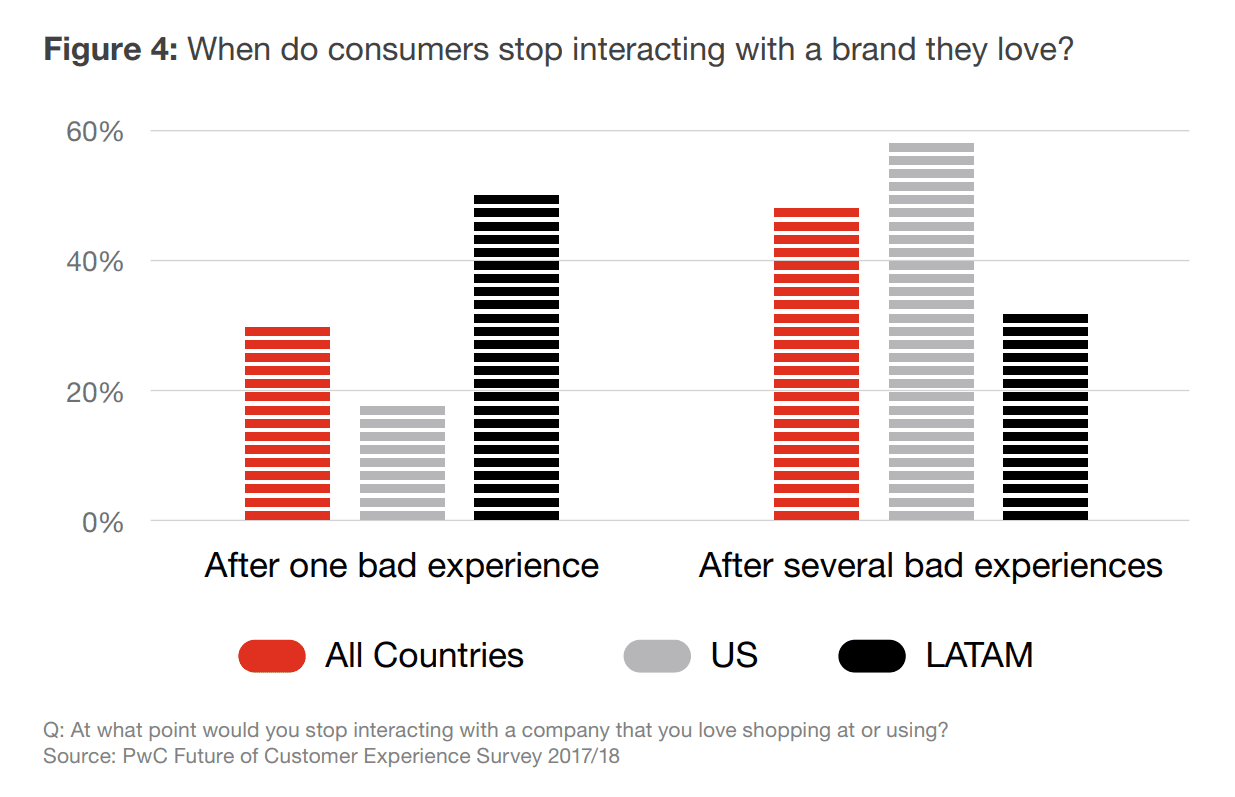
Złe doświadczenia mogą zrazić nawet lojalnych klientów. Źródło: PwC
Impact of customer churn on businesses
Well, churn is bad. Ale jak dokładnie wpływa on na wyniki firmy w dłuższej perspektywie?
Nie lekceważ wpływu nawet niewielkiego odsetka rezygnacji, mówi Michael Redbord, dyrektor generalny Service Hub w HubSpot. „W biznesie opartym na subskrypcji, nawet niewielki odsetek miesięcznych/kwartalnych rezygnacji będzie szybko narastał w czasie. Już 1 proc. miesięcznych rezygnacji przekłada się na prawie 12 proc. rezygnacji rocznych. Biorąc pod uwagę, że pozyskanie nowego klienta jest o wiele droższe niż utrzymanie istniejącego, firmy z wysokim wskaźnikiem rezygnacji szybko znajdą się w finansowym dołku, ponieważ będą musiały przeznaczać coraz więcej zasobów na pozyskiwanie nowych klientów.”
Wiele badań koncentrujących się na pozyskiwaniu i utrzymywaniu klientów jest dostępnych online. Zgodnie z tym przeprowadzonym przez Invesp, firmę zajmującą się optymalizacją współczynnika konwersji, pozyskanie nowego klienta może kosztować nawet pięć razy więcej niż utrzymanie istniejącego klienta.
Stopy rezygnacji korelują z utraconymi przychodami i zwiększonymi wydatkami na akwizycję. Ponadto, odgrywają one bardziej zniuansowaną rolę w potencjale wzrostu firmy, kontynuuje Michael, „Dzisiejsi nabywcy nie wstydzą się dzielić swoimi doświadczeniami ze sprzedawcami poprzez kanały takie jak strony recenzenckie i media społecznościowe, a także sieci peer-to-peer. Badania HubSpot Research wykazały, że 49 procent kupujących zgłosiło chęć podzielenia się swoim doświadczeniem z firmą w mediach społecznościowych. W świecie, w którym spada zaufanie do firm, „słowo z ust” odgrywa bardziej kluczową rolę w procesie zakupu niż kiedykolwiek wcześniej. Z tego samego badania HubSpot Research wynika, że 55 procent kupujących nie ufa już firmom, od których kupuje w takim stopniu jak kiedyś, 65 procent nie ufa informacjom prasowym firm, 69 procent nie ufa reklamom, a 71 procent nie ufa sponsorowanym reklamom w sieciach społecznościowych.”

Spojrzenie na stan zaufania klientów do firm. Źródło: HubSpot Research Trust Survey
Ekspert stwierdza, że firmy z wysokim wskaźnikiem rezygnacji nie tylko nie wywiązują się ze swoich relacji z byłymi klientami, ale także szkodzą swoim przyszłym wysiłkom akwizycyjnym, tworząc negatywne word-of-mouth wokół swoich produktów.
Dostawca rozwiązań conversational analytics CallMiner przeprowadził wywiady z 1000 dorosłych osób, aby dowiedzieć się, dlaczego i w jaki sposób wchodzą w interakcje z firmami. Badanie wykazało, że amerykańskie firmy tracą około 136 miliardów dolarów rocznie z powodu utraty klientów. Co więcej, zachowania firm, które spowodowały, że klienci zerwali więzi z markami, mogły zostać skorygowane.
Przypadki użycia do przewidywania rezygnacji klientów
Jak już wspomnieliśmy, wskaźnik rezygnacji jest jednym z krytycznych wskaźników wydajności dla firm subskrypcyjnych. Model biznesowy oparty na subskrypcji – zapoczątkowany przez angielskich wydawców książek w XVII wieku – jest bardzo popularny wśród współczesnych dostawców usług. Przyjrzyjmy się pokrótce tym firmom:
Usługi strumieniowego przesyłania muzyki i wideo są prawdopodobnie najczęściej kojarzone z subskrypcyjnym modelem biznesowym (Netflix, YouTube, Apple Music, Google Play, Spotify, Hulu, Amazon Video, Deezer, itp.).
Media. Obecność cyfrowa jest koniecznością wśród prasy, więc firmy informacyjne oferują czytelnikom subskrypcje cyfrowe oprócz drukowanych (Bloomberg, The Guardian, Financial Times, The New York Times, Medium itp.).
Firmy telekomunikacyjne (kablowe lub bezprzewodowe). Firmy te mogą zapewnić pełną gamę produktów i usług, w tym sieci bezprzewodowej, Internetu, telewizji, telefonii komórkowej i usług telefonii domowej (AT&T, Sprint, Verizon, Cox Communications, itp.). Niektóre specjalizują się w telekomunikacji mobilnej (China Mobile, Vodafone, T-Mobile, itp.).
Oprogramowanie jako dostawca usług. Przyjęcie oprogramowania w chmurze jest coraz większe. Według Gartnera, rynek SaaS pozostaje największym segmentem rynku chmury. Jego przychody mają wzrosnąć o 17,8 proc. i osiągnąć 85,1 mld dolarów w 2019 roku. Oferta produktowa dostawców SaaS jest szeroka: edycja grafiki i wideo (Adobe Creative Cloud, Canva), księgowość (Sage 50cloud, FreshBooks), eCommerce (BigCommerce, Shopify), e-mail marketing (MailChimp, Zoho Campaigns) i wiele innych.
Te typy firm mogą wykorzystywać wskaźnik rezygnacji do mierzenia skuteczności operacji międzydziałowych i zarządzania produktem.
Identyfikacja zagrożonych klientów za pomocą uczenia maszynowego: rozwiązywanie problemów w skrócie
Firmy, które stale monitorują sposób, w jaki ludzie angażują się w korzystanie z produktów, zachęcają klientów do dzielenia się opiniami i szybko rozwiązują ich problemy, mają większe szanse na utrzymanie korzystnych dla obu stron relacji z klientami.
Wyobraźmy sobie teraz firmę, która od pewnego czasu gromadzi dane o klientach, dzięki czemu może je wykorzystać do identyfikacji wzorców zachowań potencjalnych klientów rezygnujących z usług, segmentacji tych zagrożonych klientów i podjęcia odpowiednich działań w celu odzyskania ich zaufania. Ci, którzy stosują proaktywne podejście do zarządzania odpływem klientów, korzystają z analityki predykcyjnej. Jest to jeden z czterech rodzajów analityki, który polega na przewidywaniu prawdopodobieństwa przyszłych wyników, zdarzeń lub wartości poprzez analizę bieżących i historycznych danych. Analityka predykcyjna wykorzystuje różne techniki statystyczne, takie jak eksploracja danych (rozpoznawanie wzorców) i uczenie maszynowe (ML).
„Jedną ze słabości śledzenia rzeczywistego odpływu klientów jest to, że służy on jedynie jako opóźniony wskaźnik słabego doświadczenia klienta, w którym to przypadku model predykcyjny staje się niezwykle cenny” – zauważa Michael Redbord z HubSpot.
Główną cechą uczenia maszynowego jest budowanie systemów zdolnych do znajdowania wzorców w danych, uczących się na ich podstawie bez konieczności programowania. W kontekście przewidywania rezygnacji klientów są to cechy zachowania online, które wskazują na malejącą satysfakcję klienta z korzystania z usług/produktów firmy.
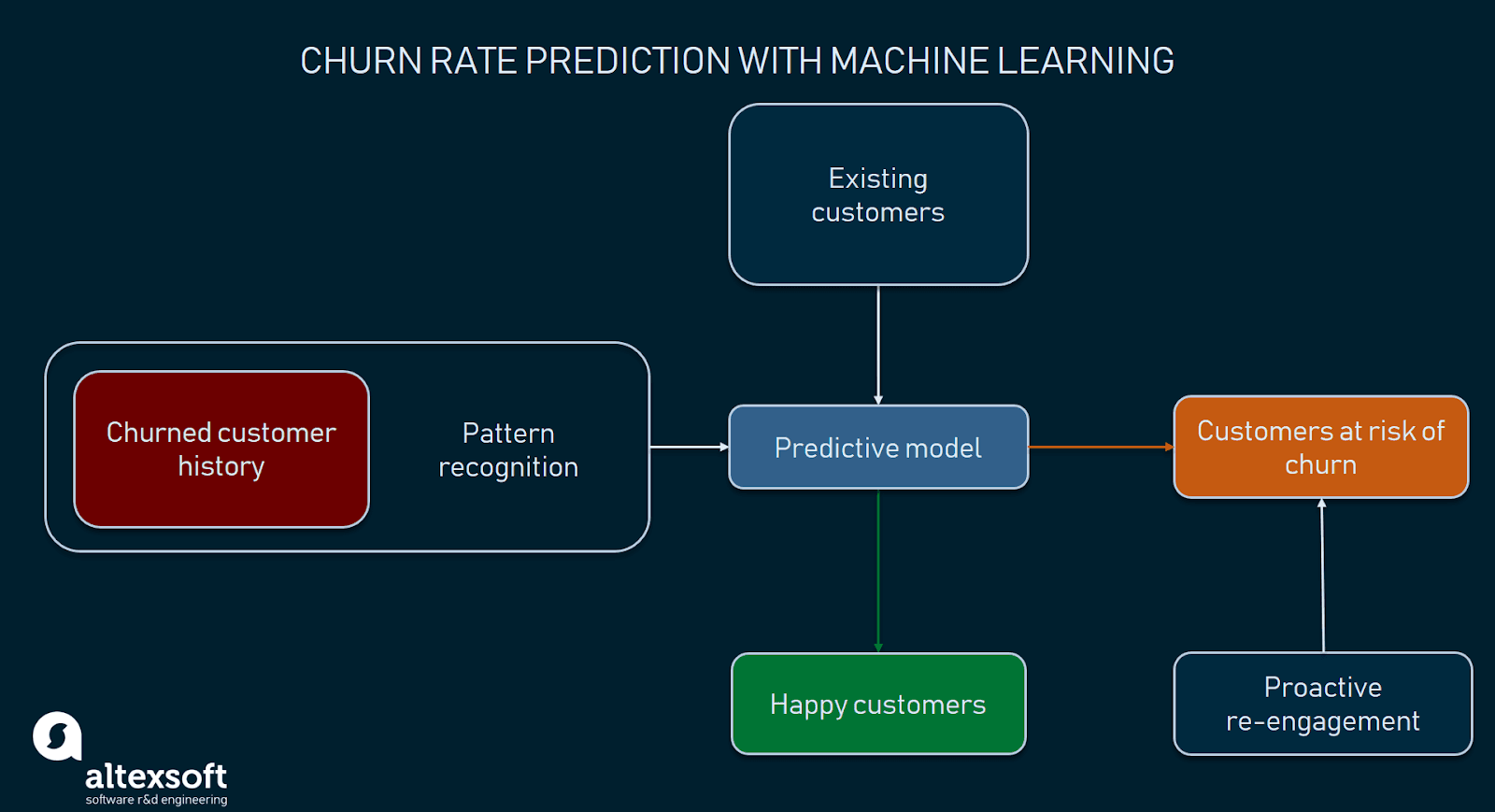
Wykrywanie klientów zagrożonych rezygnacją pomaga podjąć działania z wyprzedzeniem
Alex Bekker z firmy ScienceSoft również podkreśla znaczenie uczenia maszynowego dla proaktywnego zarządzania rezygnacją: „Jeśli chodzi o identyfikację potencjalnych churnersów, algorytmy uczenia maszynowego mogą tu wykonać świetną robotę. Ujawniają one pewne wspólne wzorce zachowań tych klientów, którzy już opuścili firmę. Następnie algorytmy ML sprawdzają zachowanie obecnych klientów w odniesieniu do tych wzorców i sygnalizują, jeśli odkryją potencjalnych rezygnantów.”
Biznesy oparte na subskrypcji wykorzystują ML do analityki predykcyjnej, aby dowiedzieć się, którzy obecni użytkownicy nie są w pełni zadowoleni z ich usług i zająć się ich problemami, gdy nie jest jeszcze za późno: „Identyfikacja klientów zagrożonych rezygnacją już na 11 miesięcy przed odnowieniem umowy umożliwia naszemu zespołowi ds. obsługi klienta zaangażowanie tych klientów, zrozumienie ich bolączek, a wraz z nimi ułożenie długoterminowego planu skoncentrowanego na pomocy klientowi w osiągnięciu wartości z zakupionej usługi” – wyjaśnia Michael.
Przypadki użycia modelowania predykcyjnego rezygnacji wykraczają poza proaktywne angażowanie się w sprawy potencjalnych klientów rezygnujących z usług i wybieranie skutecznych działań retencyjnych. Według Redborda, oprogramowanie oparte na ML pozwala menedżerom ds. sukcesu klienta określić, z którymi klientami powinni się skontaktować. Innymi słowy, pracownicy mogą być pewni, że rozmawiają z właściwymi klientami we właściwym czasie.
Zespoły sprzedaży, obsługi klienta i marketingu mogą również wykorzystać wiedzę z analizy danych w celu dostosowania swoich działań. „Na przykład, jeśli klient wykazuje oznaki ryzyka rezygnacji, to prawdopodobnie nie jest to najlepszy moment dla działu sprzedaży, aby dotrzeć do niego z informacją o dodatkowych usługach, którymi klient może być zainteresowany. Powinien to raczej zrobić CSM, aby pomóc klientowi w ponownym zaangażowaniu się i dostrzeżeniu wartości w produktach, które obecnie posiada. Podobnie jak w przypadku sprzedaży, marketing może angażować klientów w różny sposób, w zależności od ich aktualnego wskaźnika ryzyka rezygnacji: Na przykład, klienci bez ryzyka rezygnacji są lepszymi kandydatami do udziału w studium przypadku niż klient, który jest obecnie zagrożony rezygnacją” – wyjaśnia ekspert HubSpot. Ogólnie rzecz biorąc, strategia interakcji z klientem powinna być oparta na etyce i wyczuciu czasu. A wykorzystanie uczenia maszynowego do analizy danych o klientach może przynieść spostrzeżenia, które zasilą tę strategię.
Predicting customer churn with machine learning
Ale jak zacząć pracę z predykcją wskaźnika churn? Jakie dane są potrzebne? I jakie są kroki do wdrożenia?
Jak w przypadku każdego zadania uczenia maszynowego, specjaliści od nauki o danych potrzebują najpierw danych do pracy. W zależności od celu, badacze definiują, jakie dane muszą zebrać. Następnie, wybrane dane są przygotowywane, wstępnie przetwarzane i przekształcane w formę odpowiednią do budowy modeli uczenia maszynowego. Kolejną istotną częścią pracy jest znalezienie odpowiednich metod szkolenia maszyn, dostrajanie modeli i wybieranie tych, które osiągają najlepsze wyniki. Po wybraniu modelu, który przewiduje prognozy z najwyższą dokładnością, może on zostać wdrożony do produkcji.
Ogólny zakres prac, jakie wykonują naukowcy zajmujący się danymi w celu zbudowania systemów opartych na technologii ML, zdolnych do przewidywania odpływu klientów, może wyglądać następująco:
- Zrozumienie problemu i ostatecznego celu
- Gromadzenie danych
- Przygotowanie i wstępne przetwarzanie danych
- Modelowanie i testowanie
- Wdrażanie i monitorowanie modelu
Jeśli chcesz dowiedzieć się, co dzieje się podczas tych kroków, przeczytaj nasz artykuł o strukturze projektu uczenia maszynowego. Teraz dowiedzmy się, jak zrealizować każdy z tych etapów w kontekście predykcji churn.
Zrozumienie problemu i cel końcowy
Ważne jest, aby zrozumieć, jakie spostrzeżenia należy uzyskać z analizy. W skrócie, musisz zdecydować, jakie pytanie zadać, a co za tym idzie, jaki typ problemu uczenia maszynowego rozwiązać: klasyfikację czy regresję. Brzmi to skomplikowanie, ale proszę z nami poczekać.
Klasyfikacja. Celem klasyfikacji jest określenie, do jakiej klasy lub kategorii należy dany punkt danych (w naszym przypadku klient). W przypadku problemów z klasyfikacją, naukowcy wykorzystują dane historyczne z predefiniowanymi zmiennymi docelowymi AKA etykietami (churner/non-churner) – odpowiedzi, które należy przewidzieć – w celu wytrenowania algorytmu. Dzięki klasyfikacji firmy mogą odpowiedzieć na następujące pytania:
- Czy ten klient zrezygnuje czy nie?
- Czy klient odnowi swoją subskrypcję?
- Czy użytkownik obniży plan cenowy?
- Czy są jakieś oznaki nietypowego zachowania klienta?
Czwarte pytanie o oznaki nietypowego zachowania reprezentuje rodzaj problemu klasyfikacyjnego zwanego wykrywaniem anomalii. Wykrywanie anomalii polega na identyfikacji wartości odstających – punktów danych, które znacząco odbiegają od reszty danych.
Regresja. Prognozowanie odpływu klientów może być również sformułowane jako zadanie regresji. Analiza regresji jest techniką statystyczną służącą do szacowania zależności pomiędzy zmienną docelową a innymi wartościami danych, które wpływają na zmienną docelową, wyrażoną w wartościach ciągłych. Gdyby to było zbyt trudne – wynikiem regresji jest zawsze jakaś liczba, natomiast klasyfikacja zawsze sugeruje kategorię. Ponadto, analiza regresji pozwala oszacować, jak wiele różnych zmiennych w danych wpływa na zmienną docelową. Dzięki regresji firmy mogą przewidzieć, w jakim okresie czasu istnieje prawdopodobieństwo rezygnacji konkretnego klienta lub otrzymać szacunkowe prawdopodobieństwo rezygnacji na klienta.
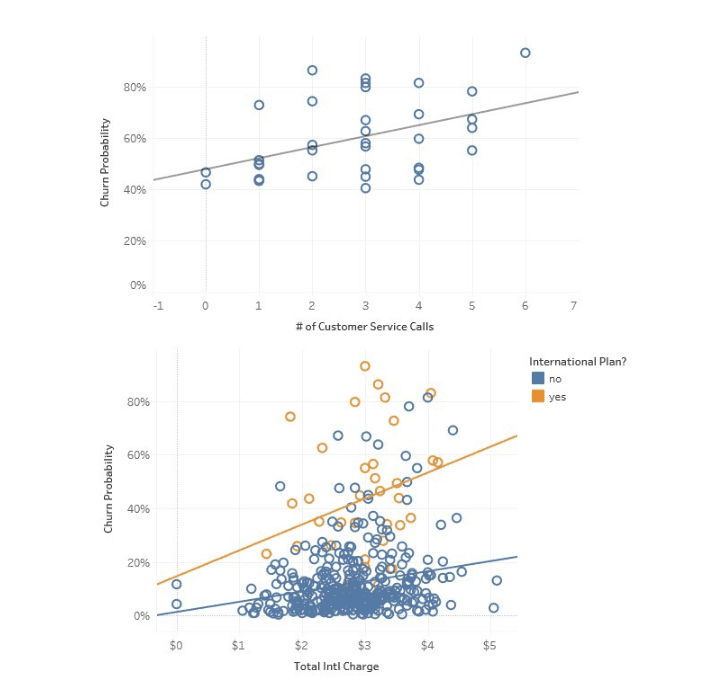
To jest przykład regresji logistycznej użytej do przewidywania prawdopodobieństwa rezygnacji w telekomunikacji przez Towards Data Science. Wizualizacja przedstawia, w jaki sposób liczba połączeń serwisowych i wykorzystanie planów międzynarodowych koreluje z rezygnacją
Gromadzenie danych
Identyfikacja źródeł danych. Po zidentyfikowaniu, jakiego rodzaju insightów należy szukać, można zdecydować, jakie źródła danych są niezbędne do dalszego modelowania predykcyjnego. Załóżmy najczęstsze źródła danych, które możesz wykorzystać do przewidywania churn:
- SystemyCRM (w tym rejestry sprzedaży i wsparcia klienta)
- Serwisy analityczne (np., Google Analytics, AWStats, CrazyEgg)
- Feedback w mediach społecznościowych i na platformach recenzenckich
- Feedback dostarczany na życzenie dla Twojej organizacji, itp.
Oczywiście lista może być dłuższa lub krótsza w zależności od branży.
Przygotowanie i wstępne przetwarzanie danych
Dane historyczne, które zostały wybrane do rozwiązania problemu, muszą zostać przekształcone w format odpowiedni dla uczenia maszynowego. Ponieważ wydajność modelu, a tym samym jakość otrzymanych wniosków zależy od jakości danych, głównym celem jest upewnienie się, że wszystkie punkty danych są prezentowane przy użyciu tej samej logiki, a ogólny zbiór danych jest wolny od niespójności. Wcześniej napisaliśmy artykuł na temat podstawowych technik przygotowania zbioru danych, więc zachęcamy do zapoznania się z nim, jeśli chcesz dowiedzieć się więcej na ten temat.
Inżynieria cech, ekstrakcja i selekcja. Inżynieria cech jest bardzo ważną częścią przygotowania zbioru danych. Podczas tego procesu naukowcy tworzą zestaw atrybutów (cech wejściowych), które reprezentują różne wzorce zachowań związane z poziomem zaangażowania klienta w usługę lub produkt. W szerokim znaczeniu cechy są mierzalnymi charakterystykami obserwacji, które model ML bierze pod uwagę, aby przewidzieć wyniki (w naszym przypadku decyzja dotyczy prawdopodobieństwa rezygnacji.)
Chociaż charakterystyka zachowań jest specyficzna dla każdej branży, podejście do identyfikacji zagrożonych klientów jest uniwersalne, zauważa Alex: „Firma szuka określonych wzorców zachowań, które ujawniają potencjalnych klientów rezygnujących.”
Cyfrowy marketer i przedsiębiorca Neil Patel klasyfikuje cechy na cztery grupy. Cechy demograficzne klientów i funkcje wsparcia sprawdzają się w każdej branży. Z kolei cechy zachowania użytkownika i kontekstowe są typowe dla modelu biznesowego SaaS:
- cechy demograficzne klienta, które zawierają podstawowe informacje o kliencie (np. wiek, poziom wykształcenia, lokalizacja, dochód)
- cechy zachowania użytkownika opisujące, w jaki sposób dana osoba korzysta z usługi lub produktu (np, etap cyklu życia, liczba logowań do konta, długość aktywnej sesji, pora dnia, w której produkt jest aktywnie wykorzystywany, wykorzystywane funkcje lub moduły, działania, wartość pieniężna)
- cechy wsparcia, które charakteryzują interakcje z obsługą klienta (np, wysłane zapytania, liczba interakcji, historia ocen satysfakcji klienta)
- cechy kontekstowe reprezentujące inne informacje kontekstowe o kliencie.
Specjaliści z firmy HubSpot starają się zrozumieć, „co czyni klienta skutecznym”, wykorzystując takie wskaźniki, jak odwiedzający witrynę, wygenerowane leady i stworzone transakcje. Dyrektor generalny Service Hub Michael Redbord mówi: „Śledzimy nie tylko dane dotyczące użytkowania (np. opublikowanie wpisu na blogu, edycja przewidywanej wartości zamkniętej transakcji lub wysłanie wiadomości e-mail), ale również dane dotyczące wyników (np. liczba kliknięć w wiadomość e-mail, liczba wyświetleń wpisu na blogu, wartość dolarowa transakcji zamkniętych w ciągu kwartału). Ważne jest, aby zrozumieć nie tylko to, w jaki sposób Twoi klienci korzystają z Twojego produktu, ale także jakie widzą rezultaty. Jeśli klienci nie generują wartości z produktu, zazwyczaj widzimy wzrost prawdopodobieństwa rezygnacji.”
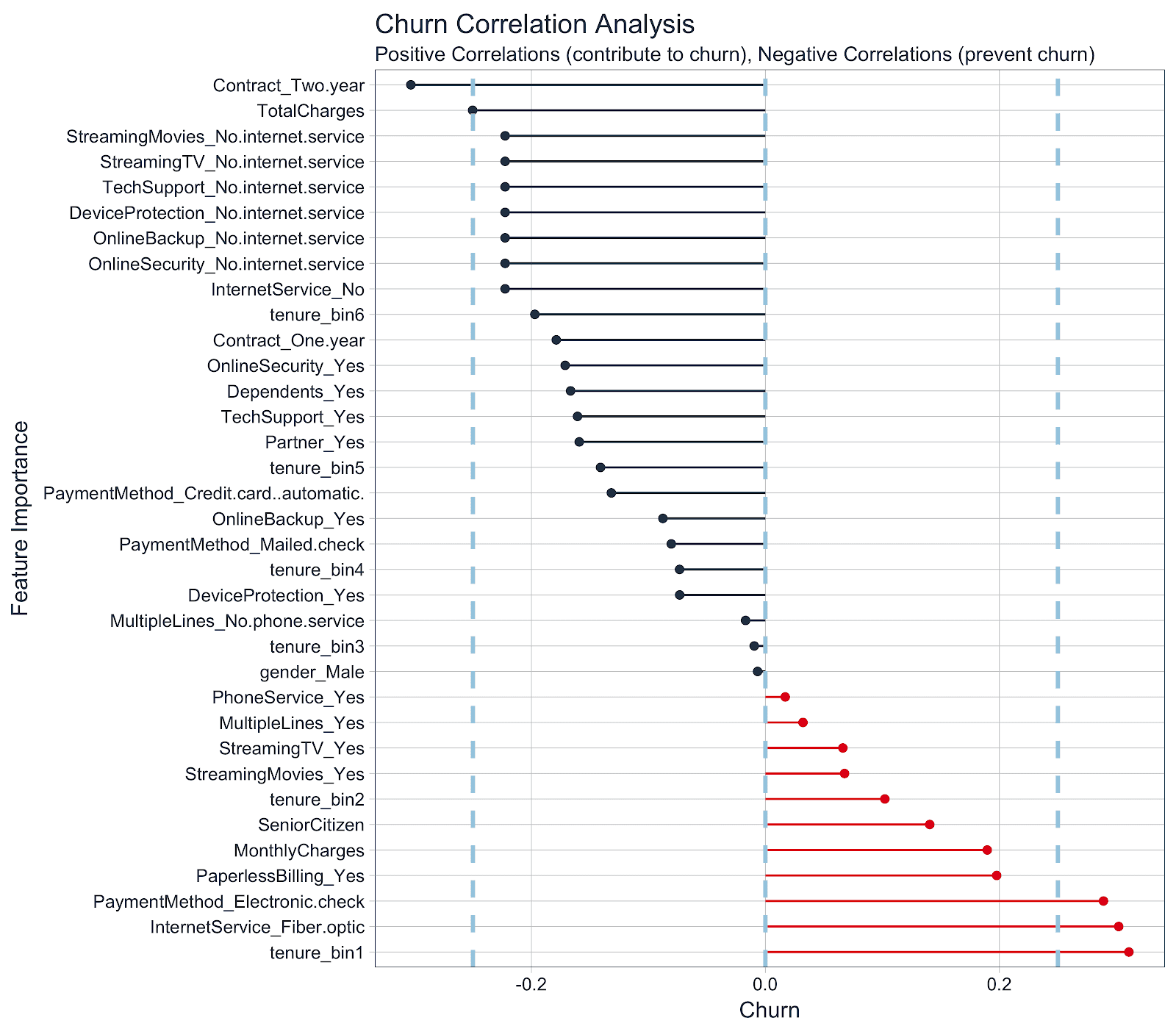
How different user behavior, subscription, and demographic features correlate with churn in Internet service by Matt Dancho for RStudio blog
Ale posiadanie zbyt dużej ilości danych nie zawsze jest dobre.
Feature extraction aims at reducing the number of variables (attributes) by leaving the ones that represent the most discriminative information. Ekstrakcja cech pomaga zmniejszyć wymiarowość danych (wymiary to kolumny z atrybutami w zbiorze danych) i wykluczyć nieistotne informacje.
Podczas selekcji cech specjaliści weryfikują wcześniej wyekstrahowane cechy i definiują ich podgrupę, która jest najbardziej skorelowana z odpływem klientów. W wyniku selekcji cech specjaliści dysponują zbiorem danych zawierającym tylko istotne cechy.
Metody. Szef działu analityki danych ScienceSoft Alex Bekker zauważa, że takie metody jak permutation importance, pakiet ELI5 Python i SHAP (SHapley Additive exPlanations) mogą być użyte do określenia najbardziej istotnych i użytecznych cech.
Zasada działania wszystkich metod polega na wyjaśnieniu, w jaki sposób modele dokonują swoich przewidywań (na podstawie jakich cech model wysnuł konkretny wniosek). Interpretowalność modeli jest jednym z priorytetowych problemów w tej dziedzinie, a naukowcy ciągle opracowują rozwiązania, aby go rozwiązać. Więcej na temat interpretowalności można przeczytać w naszym artykule na temat postępów i trendów w AI i data science.
Ważność permutacyjna jest jednym ze sposobów definiowania ważności cechy – wpływu cechy na przewidywania. Jest ona obliczana na modelach, które zostały już wytrenowane. W ten sposób odbywa się permutacja ważności: Badacz danych zmienia kolejność punktów danych w jednej kolumnie, zasila model wynikowym zbiorem danych i określa, w jakim stopniu ta zmiana obniża jego dokładność. Cechy, które mają największy wpływ na wyniki, są najważniejsze.
Innym sposobem na przeprowadzenie permutacji ważności jest usunięcie cechy ze zbioru danych i ponowne wytrenowanie modelu.
Permutację ważności można przeprowadzić za pomocą ELI5 – otwartej biblioteki Pythona, która pozwala na wizualizację, debugowanie klasyfikatorów ML (algorytmów) i interpretację ich wyników.
Zgodnie z dokumentacją ELI5, metoda ta działa najlepiej na zbiorach danych, które nie zawierają dużej liczby kolumn (cech).
Używając frameworka SHAP (SHapley Additive exPlanations), specjaliści mogą interpretować decyzje „dowolnego modelu uczenia maszynowego”. SHAP przypisuje również każdej z cech wartość ważności dla danej predykcji.
Segmentacja klientów. Rozwijające się firmy oraz te rozszerzające swoją ofertę produktową zazwyczaj segmentują swoich klientów za pomocą wcześniej zdefiniowanych i wybranych cech. Klienci mogą być podzieleni na podgrupy w oparciu o etap cyklu życia, potrzeby, stosowane rozwiązania, poziom zaangażowania, wartość pieniężną lub podstawowe informacje. Ponieważ każda kategoria klientów dzieli wspólne wzorce zachowań, możliwe jest zwiększenie dokładności predykcji poprzez wykorzystanie modeli ML wyszkolonych specjalnie na zbiorach danych reprezentujących każdy segment.
Na przykład HubSpot wykorzystuje takie kryteria segmentacji jak persona klienta, etap cyklu życia, posiadane produkty, region, język i całkowity przychód konta. „Kombinacje takich segmentów to sposób, w jaki dzielimy własność kont i definiujemy książkę biznesu CSM lub sprzedawcy” – mówi Michael.
Dodatkowo, uzbrojeni w wiedzę na temat wartości klienta, pracownicy mogą nadać priorytety swoim działaniom retencyjnym.
Po przygotowaniu danych, wyborze cech i etapach segmentacji klientów przychodzi czas na określenie, jak długo będzie trwało śledzenie zachowań użytkowników przed wyciąganiem prognoz.
Wybór okna obserwacji (historii zdarzeń klienta). Modelowanie predykcyjne polega na poznaniu zależności pomiędzy obserwacjami poczynionymi w okresie (oknie), który kończy się przed określonym punktem czasowym, a przewidywaniami dotyczącymi okresu, który zaczyna się po tym samym punkcie czasowym. Ten pierwszy okres nazywany jest obserwacją, oknem niezależnym, oknem objaśniającym lub historią zdarzeń klienta (dla jasności posłużmy się ostatnią definicją). Drugi okres, który następuje po okresie obserwacji, nazywany jest oknem wyników, zależnym lub oknem odpowiedzi. Innymi słowy, przewidujemy zdarzenia (user churns lub stays) w oknie wydajności, w przyszłości.

Krytyczne jest zdefiniowanie poprawnej historii zdarzeń i okien obserwacji
Inżynier uczenia maszynowego w Spotify, Guilherme Dinis, Jr, w swojej pracy magisterskiej badał zachowanie nowych użytkowników Spotify zarejestrowanych w darmowym planie, aby określić, czy opuszczają oni, czy pozostają aktywni w drugim tygodniu po rejestracji.
Wybierał pierwszy tydzień użytkowania jako historię zdarzeń. Aby sklasyfikować użytkowników jako rezygnujących i aktywnych, Guilherme sprawdził, czy w drugim tygodniu była jakakolwiek aktywność streamingowa. Jeśli użytkownicy kontynuowali słuchanie muzyki, byli klasyfikowani jako non-churners.
„Powody utrzymywania stosunkowo małych okien obserwacji i aktywacji są motywowane wewnętrznymi wcześniejszymi badaniami na tej samej populacji użytkowników, które wskazywały na wysokie prawdopodobieństwo rezygnacji dwa tygodnie po rejestracji”, wyjaśnił inżynier.
Więc, aby zdefiniować długowieczność historii zdarzeń i okno wydajności, musisz rozważyć, kiedy Twoi użytkownicy zazwyczaj rezygnują. Może to być drugi tydzień, jak w przykładzie Spotify, lub może to być 11. miesiąc rocznej subskrypcji. Ale najprawdopodobniej nie chciałbyś dowiedzieć się, że ten abonent jest prawdopodobne, aby churn w miesiącu. Ponieważ będziesz miał bardzo małe ramy czasowe dla ponownego zaangażowania.
Balansowanie czasu dla obserwacji i przewidywań jest w rzeczywistości trudnym zadaniem. Na przykład, jeśli okno obserwacji wynosi jeden miesiąc, to okno wydajności dla klienta z rocznym abonamentem będzie wynosiło 11 miesięcy. Wydaje się, że najkorzystniejsze dla firm byłoby tworzenie krótkiej historii zdarzeń i długich okien wydajnościowych. Poświęcasz mało czasu na obserwację i masz wystarczająco dużo czasu na ponowne zaangażowanie. Niestety, nie zawsze tak to działa. Krótka historia zdarzeń może nie wystarczyć, aby dokonać wiarygodnych prognoz, więc eksperymentowanie z tymi parametrami może stać się powtarzalnym, ciągłym procesem z jego kompromisami. Zasadniczo, musisz określić historię zdarzeń, która byłaby wystarczająca dla modelu, aby dokonać uzasadnionej predykcji, ale nadal, mieć wystarczająco dużo czasu, aby zająć się potencjalnym odpływem klientów.
Modelowanie i testowanie
Głównym celem tego etapu projektu jest opracowanie modelu predykcji odpływu klientów. Specjaliści zazwyczaj trenują wiele modeli, dostrajają je, oceniają i testują, aby określić ten, który wykrywa potencjalnych klientów z pożądanym poziomem dokładności na danych treningowych.
Klasyczne modele uczenia maszynowego są powszechnie stosowane do przewidywania rezygnacji klientów, na przykład regresja logistyczna, drzewa decyzyjne, las losowy i inne. Alex Bekker z ScienceSoft sugeruje użycie Random Forest jako modelu bazowego, a następnie „można ocenić wydajność takich modeli jak XGBoost, LightGBM lub CatBoost”. Naukowcy zajmujący się danymi zazwyczaj używają wydajności modelu bazowego jako metryki do porównania dokładności przewidywania bardziej złożonych algorytmów.
Regresja logistyczna jest algorytmem używanym do problemów klasyfikacji binarnej. Przewiduje prawdopodobieństwo wystąpienia zdarzenia poprzez pomiar związku pomiędzy zmienną zależną a jedną lub więcej zmiennych niezależnych (cech). Dokładniej, regresja logistyczna przewiduje możliwość przynależności instancji (punktu danych) do kategorii domyślnej.
Drzewo decyzyjne jest rodzajem algorytmu uczenia nadzorowanego (z predefiniowaną zmienną docelową.) Chociaż najczęściej używane jest w zadaniach klasyfikacji, może również obsługiwać dane liczbowe. Algorytm ten dzieli próbkę danych na dwa lub więcej jednorodnych zbiorów w oparciu o najbardziej znaczące różnice w zmiennych wejściowych w celu dokonania predykcji. Z każdym podziałem generowana jest część drzewa. W wyniku tego powstaje drzewo z węzłami decyzyjnymi i węzłami liściowymi (które są decyzjami lub klasyfikacjami). Drzewo zaczyna się od węzła głównego – najlepszego predyktora.
Podstawowa struktura drzewa decyzyjnego. Źródło: Python Machine Learning Tutorial
Wyniki predykcji drzew decyzyjnych mogą być łatwo interpretowane i wizualizowane. Nawet osoby bez wykształcenia analitycznego lub data science mogą zrozumieć, jak doszło do powstania określonego wyniku. W porównaniu z innymi algorytmami, drzewa decyzyjne wymagają mniejszego przygotowania danych, co również jest ich zaletą. Mogą one jednak być niestabilne w przypadku niewielkich zmian w danych. Innymi słowy, zmiany w danych mogą prowadzić do wygenerowania diametralnie różnych drzew. Aby rozwiązać ten problem, naukowcy używają drzew decyzyjnych w grupie (AKA ensemble), o której będziemy mówić dalej.
Las losowy jest rodzajem metody uczenia zespołowego, która wykorzystuje liczne drzewa decyzyjne w celu osiągnięcia wyższej dokładności przewidywania i stabilności modelu. Metoda ta radzi sobie zarówno z zadaniami regresji jak i klasyfikacji. Każde drzewo klasyfikuje instancję danych (lub głosuje na jej klasę) na podstawie atrybutów, a las wybiera klasyfikację, która otrzymała najwięcej głosów. W przypadku zadań regresji, brana jest średnia z decyzji różnych drzew.
Tak właśnie Random Forest tworzy predykcje. Źródło: ResearchGate
XGBoost jest implementacją algorytmu gradient boosted tree, który jest powszechnie stosowany do problemów klasyfikacji i regresji. Gradient boosting to algorytm składający się z grupy słabszych modeli (drzew), które sumują swoje oszacowania, aby przewidzieć zmienną docelową z większą dokładnością.
Grupa badaczy z University of Virginia przeanalizowała zależne od czasu dane dotyczące wykorzystania funkcji oprogramowania, takie jak numery logowania i numery komentarzy, w celu przewidzenia rezygnacji klienta SaaS w horyzoncie czasowym trzech miesięcy. Autorzy porównali wydajność modelu z czterema algorytmami klasyfikacji, i „model XGBoost osiągnął najlepsze wyniki w identyfikacji najważniejszych cech użytkowania oprogramowania i klasyfikacji klientów jako typ rezygnacji lub typ nieryzykowny”. Zdolność modelu XGBoost do określenia najważniejszych cech, które reprezentują sposób, w jaki klienci korzystają z oprogramowania SaaS, może pomóc dostawcom usług w uruchomieniu bardziej skutecznych kampanii marketingowych podczas kierowania do potencjalnych klientów, według badaczy.
LightGBM to gradient boosting framework, który wykorzystuje algorytmy uczenia oparte na drzewach. Może być używany do wielu zadań ML, na przykład klasyfikacji i rankingu. Zgodnie z dokumentacją, niektóre zalety LightGBM to szybsze szkolenie i wyższa wydajność, a także większa dokładność. Algorytmy te zużywają mniej pamięci i obsługują duże ilości danych – nie zaleca się stosowania ich na zbiorach danych zawierających mniej niż 10 000 wierszy. LightGBM wspiera również uczenie równoległe i uczenie na GPU (wykorzystanie procesorów graficznych do trenowania dużych zbiorów danych).
CatBoost to kolejna biblioteka gradient boosting na drzewach decyzyjnych. Obsługuje zarówno cechy numeryczne, jak i kategoryczne, dzięki czemu może być wykorzystywany do klasyfikacji, regresji, rankingów i innych zadań uczenia maszynowego. Jedną z zalet CatBoost jest to, że pozwala na trenowanie modeli przy użyciu CPU i dwóch lub więcej GPU.
Wybór techniki. Liczne czynniki mogą wpłynąć na liczbę wymaganych modeli w produkcji oraz ich rodzaj. Chociaż przypadek każdej firmy jest unikalny, ale generalnie podejście do zarządzania danymi klienta i potrzeby biznesowe mają znaczenie. Wybór techniki predykcji może zależeć od:
- Etapu cyklu życia klienta. Specjaliści z HubSpot stwierdzili na przykład, że wybór modelu może zależeć od etapu interakcji klienta z marką. „Klienci w trakcie onboardingu zazwyczaj nie wykazują tych samych metryk wartości, co klienci, którzy korzystają z HubSpot dłużej niż rok. Dlatego model wyszkolony na klientach starszych niż rok może działać naprawdę świetnie dla tych klientów, ale nie być dokładny, gdy zastosuje się go do klientów wciąż będących w trakcie onboardingu” – wyjaśnia Michael z HubSpot.
- Potrzeba wyjaśnienia danych wyjściowych. Kiedy przedstawiciele firmy (np. menedżerowie ds. sukcesu klienta) muszą zrozumieć przyczyny rezygnacji, można wykorzystać tzw. techniki białej skrzynki, takie jak drzewa decyzyjne, las losowy czy regresja logistyczna. Zwiększona interpretowalność jest jednym z głównych powodów, dla których HubSpot wybiera random forest. Czasami wystarczy samo wykrycie rezygnacji, np. gdy zarząd firmy musi oszacować budżet na kolejny rok, biorąc pod uwagę możliwe straty z powodu rezygnacji klientów. W takich przypadkach sprawdzą się mniej interpretowalne modele.
- Customer persona. Pomyśl o firmie dostarczającej wiele produktów, z których każdy jest przeznaczony dla określonego typu użytkownika. Ponieważ różne persony klientów mogą mieć typowe wzorce zachowań, wykorzystanie dedykowanych modeli do przewidywania prawdopodobieństwa ich churnu wydaje się rozsądne. Michael Redbord dodaje: „W rozwijającym się biznesie charakter bazy klientów będzie ewoluował, zwłaszcza gdy wprowadzane są nowe produkty. Modele zbudowane na jednym zestawie klientów mogą nie działać tak dobrze, gdy do bazy klientów dołącza nowa persona. Dlatego też, kiedy wprowadzamy nową linię produktów, zazwyczaj budujemy nowe modele, aby przewidzieć odpływ tych klientów.”
Wdrażanie i monitorowanie
A teraz ostatni etap przepływu pracy w projekcie churn prediction. Wybrany model/modele muszą zostać wdrożone do produkcji. Model może zostać włączony do istniejącego oprogramowania lub stać się rdzeniem nowego programu. Jednak scenariusz „wdrożyć i zapomnieć” nie zadziała: Naukowcy zajmujący się danymi muszą śledzić poziom dokładności modelu i poprawiać go w razie potrzeby.
„Przewidywanie odpływu klientów za pomocą uczenia maszynowego i sztucznej inteligencji to proces iteracyjny, który nigdy się nie kończy. Monitorujemy wydajność modelu i w razie potrzeby dostosowujemy funkcje, aby poprawić dokładność, gdy zespoły zajmujące się obsługą klienta przekazują nam informacje zwrotne lub gdy dostępne są nowe dane. W punkcie każdej interakcji z człowiekiem – rozmowa z działem wsparcia, CSM QBR, rozmowa dotycząca odkryć sprzedażowych – monitorujemy i rejestrujemy ludzką interpretację pomocy klientowi, która wspomaga modele uczenia maszynowego i zwiększa dokładność naszych przewidywań dotyczących zdrowia każdego klienta” – podsumowuje Michael.
Częstotliwość testowania wydajności modelu zależy od tego, jak szybko dane stają się nieaktualne w organizacji.
Wniosek
Stopa rezygnacji jest wskaźnikiem zdrowia dla firm opartych na subskrypcji. Możliwość identyfikacji klientów, którzy nie są zadowoleni z dostarczanych rozwiązań, pozwala firmom poznać słabe punkty produktów lub planów cenowych, problemy operacyjne, a także preferencje i oczekiwania klientów, aby proaktywnie zmniejszyć przyczyny rezygnacji.
Ważne jest określenie źródeł danych i okresu obserwacji, aby mieć pełny obraz historii interakcji z klientami. Wybór najbardziej istotnych cech dla modelu wpłynie na jego wydajność predykcyjną: Im bardziej jakościowy zbiór danych, tym dokładniejsze są prognozy.
Przedsiębiorstwa z dużą bazą klientów i licznymi ofertami skorzystałyby z segmentacji klientów. Liczba i wybór modeli ML może również zależeć od wyników segmentacji. Naukowcy zajmujący się danymi muszą również monitorować wdrożone modele oraz weryfikować i dostosowywać funkcje, aby utrzymać pożądany poziom dokładności predykcji.
Original. Reposted with permission.
Original.