Lesedauer: 30 Minuten
Diskriminative Modelle, auch als bedingte Modelle bezeichnet, sind eine Klasse von Modellen, die in der statistischen Klassifikation verwendet werden, insbesondere beim überwachten maschinellen Lernen.
Im Gegensatz zur generativen Modellierung, die von der gemeinsamen Wahrscheinlichkeit P(x,y) ausgeht, untersucht die diskriminative Modellierung die P(y|x), d. h. sie sagt die Wahrscheinlichkeit von y(Ziel) voraus, wenn x(Trainingsmuster) gegeben sind.
- Lassen Sie uns dies mit Hilfe eines mathematischen Beispiels verstehen:
Angenommen, die Eingabedaten sind x und die Menge der Etiketten für x ist y. Betrachten wir die folgenden 4 Datenpunkte:
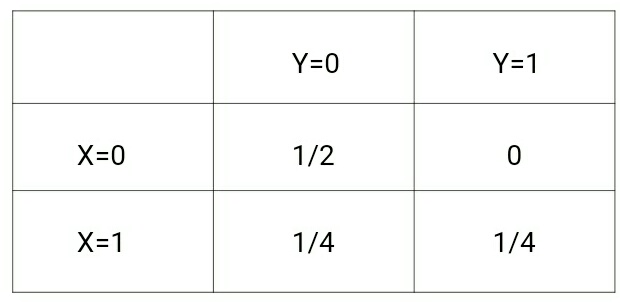
(x,y) –> {(0,0), (0,0), (1,0), (1,1)}Für die oben genannten Daten ist p(x,y) wie folgt:
während p(y|x) wie folgt ist:
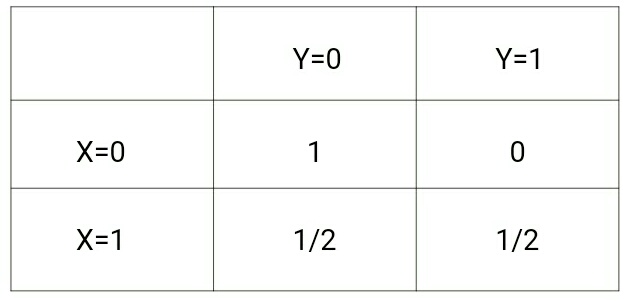
Wenn wir einen Blick auf diese beiden Matrizen werfen, werden wir den Unterschied zwischen den beiden Wahrscheinlichkeitsverteilungen verstehen.
Diskriminative Algorithmen versuchen also, p(y|x) direkt aus den Daten zu lernen, und versuchen dann, die Daten zu klassifizieren.
Die generativen Algorithmen hingegen versuchen, p(x,y) zu lernen, das später in p(y|x) umgewandelt werden kann, um die Daten zu klassifizieren. Einer der Vorteile generativer Algorithmen ist, dass man p(x,y) verwenden kann, um neue Daten zu erzeugen, die den vorhandenen Daten ähnlich sind. Andererseits bieten diskriminative Algorithmen im Allgemeinen eine bessere Leistung bei Klassifizierungsaufgaben.
In diskriminativen Modellen müssen wir, um das Label y aus dem Trainingsbeispiel x vorherzusagen, auswerten:
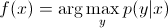
was lediglich die wahrscheinlichste Klasse y unter Berücksichtigung von x auswählt. Es ist, als würden wir versuchen, die Entscheidungsgrenze zwischen den Klassen zu modellieren. Dieses Verhalten ist sehr deutlich in neuronalen Netzen, wo die berechneten Gewichte als eine komplex geformte Kurve gesehen werden können, die die Elemente einer Klasse im Raum isoliert.
- focus on decision boundary.
- more powerful with lot of examples.
- not designed to use unlabeled data.
- only supervised task.
Diskriminative Klassifikatoren Beispiele
Diskriminative Modelle werden in folgenden Ansätzen bevorzugt:
- Logistische Regression
- Scalar Vector Machine
- Traditionelle neuronale Netze
- Nächste-Nachbarn-Suche
- Conditional Random Fields (CRF)s
Vorteile von diskriminativen Modellen
- Diskriminative Modelle werden verwendet, um eine bessere Genauigkeit bei den Trainingsdaten zu erzielen.
- Wenn die Trainingsdaten groß sind, wird die Genauigkeit für zukünftige Daten gut sein.
- Wenn die Anzahl der Parameter begrenzt ist, wird ein diskriminatives Modell versuchen, die Vorhersage von y aus x zu optimieren, während ein generatives Modell versuchen wird, die gemeinsame Vorhersage von x und y zu optimieren. Aus diesem Grund übertreffen diskriminative Modelle generative Modelle bei bedingten Vorhersageaufgaben.