Google Analyticsin regex (eli säännölliset lausekkeet) on aliarvostettu taitolaji.
Jos haluat tehdä minkäänlaista suodatusta tai kohdentamista perusasioita pidemmälle, regexin hyvä hallinta antaa sinulle Analyticsin supervoimia.

Regex antaa sinulle supervoimia. – kuvan lähde
Säännöllisillä lausekkeilla on tietysti paljon laajempia käyttötapauksia kuin analytiikka ja markkinointi. Tässä artikkelissa käsittelemme kuitenkin joitakin taktisia käyttötapauksia, jotka voivat auttaa sinua käyttäjäymmärryksessä, tietojen organisoinnissa ja jopa edistyneessä kohdentamisessa ja hakukonemarkkinoinnin käyttötapauksissa.
Mutta ensin tehdään lyhyt yhteenveto siitä, mitä säännölliset lausekkeet ovat, erityisesti suhteessa Google Analyticsiin.
- Google Analytics RegEx: Mitä se on?
- Google Analytics RegEx Cheat Sheet
- Putki (|)
- Takaviivoitus (\)
- Varjomerkki (^)
- USDOLLARIMERKKI ($)
- Piste (.)
- Tähti (*)
- Piste-steriskiyhdistelmä (.*)
- Plussamerkki (+)
- Kysymysmerkki (?)
- Parentheses ()
- Neliösulkeet ()
- Dashes (-)
- Sirappisulkeet ({ })
- Google Analytics RegEx: Konkreettisia esimerkkejä, joita voit käyttää
- Google Analytics RegEx -vinkit & Vältettävät virheet
- Google Analyticsin ulkopuolella: RegEx for Other Marketing Uses
- Conclusion
Google Analytics RegEx: Mitä se on?
Säännölliset lausekkeet ovat erityisiä tekstimerkkejä hakumallien kuvaamiseen.
Huh?
Suhteessa analytiikkaan säännölliset lausekkeet auttavat sinua löytämään, määrittelemään ja poimimaan asioita. Vielä tarkemmin sanottuna Google Analyticsin kanssa ne voivat auttaa sinua luomaan joustavampia määritelmiä esimerkiksi näkymäsuodattimille, tavoitteille, segmenteille, yleisöille, sisältöryhmille ja kanavien ryhmittelyille.
Periaatteessa ne ovat ennalta määriteltyjä merkkejä tai merkkisarjoja, jotka vastaavat laajasti tai suppeasti digitaalisen analytiikan tiedoissasi esiintyviä kuvioita ja valitsevat niitä. Ne ovat yleinen työkalu, jota voidaan käyttää monin tavoin (lukuisat ohjelmointikielet ja työkalut sallivat regexin). Analytiikassa käytämme niitä kuitenkin pääasiassa datan kuvioiden täsmäyttämiseen.
Se ei tietenkään ole hyödyllinen vain analytiikassa. Erityisesti, jos käytät Google Tag Manageria tai jos käytät monimutkaista kohdentamista A/B-testeissäsi, käytät paljon regexiä. Kuten MeasurementMarketing.io:n perustaja Chris Mercer sanoo:
”Käytämme regexiä päivittäin. Se auttaa meitä määrittelemään selkeästi kaiken Google Analyticsin tavoitteen suppilovaiheista Google Tag Managerin tiettyihin triggereihin.”
Jos kuitenkin haluat sukeltaa syvemmälle ja todella opetella säännöllisiä lausekkeita, tässä on muutama resurssi (ei välttämätön Google Analyticsin perusasioihin ja luultavasti jollekulle, jolla on enemmän teknisiä taitoja):
- Regulaariset lausekkeet: The Complete Tutorial
- Mastering Regular Expressions 3rd Edition (Book)
- Learn Regular Expressions the Hard Way
Voit myös opetella vuorovaikutteisesti jotain RegexOnen tai RegexR:n kaltaisten ohjelmien avulla, jotka molemmat ovat hienoja. Mutta mennäänpä sen ohi ja käydään läpi yleisimmin käytetyt Google Analyticsin regex-merkit, jotta voit alkaa käyttää niitä.
Google Analytics RegEx Cheat Sheet
Katso seuraavia Google Analyticsin regex-merkkejä eräänlaisena huijauslomakkeena – et luultavasti tule käyttämään niitä heti, mutta käymällä lyhyesti läpi, mitä pystyt regexin avulla hakemaan vastausta, kun se on tarpeen.
Lyhyeksi yhteenvedoksi en ole löytänyt mitään tiiviimpää ja ytimekkäämpää kuin tämä opas:

Hyvin lyhyt opas Google Analyticsin regexiin – kuvalähde
Voit kuitenkin huomata, että pelkällä tuollaisella viitekehyksellä opas on hiukan epämääräinen ja epäselvä. Käydään siis läpi yleisimmin käytetyt Google Analyticsin regexit ja näytetään samalla vastaavat käyttötapaukset.
Putki (|)
Kun haluat sanoa ”TAI”, kannattaa käyttää putkea (|). Kuten esimerkiksi ”This | That”, joka tarkoittaisi ”This OR That”.
Jos olet Google Analyticsin segmenttien innokas käyttäjä, olet jo tottunut käyttämään loogisia OR-operaattoreita.
Tämä on yksi yksinkertaisimmista ja yleisimmistä Google Analyticsissa käytettävistä säännöllisistä lausekkeista. Sillä on monia käyttökohteita, joskin yksi käytetyimmistä saattaa olla tavoitteiden asettaminen. Jos sinulla on kaksi kiitos-sivua, joilla on eri URL-osoitteet (/thank-you/ ja /subscription-confirmed/), mutta haluaisit seurata molempia niistä tavoitteen täyttymisenä, voit käyttää tätä säännöllistä lauseketta.
Voit käyttää sitä myös suodattimissa. Oletetaan, että haluat tarkastella käyttäytymisraporttia kahdesta artikkelista (Sisältömarkkinoinnin oppitunneista ja Sisällönanalytiikasta), joiden URL-osoitteet ovat /content-marketing-analytics/ ja /content-marketing-lessons/. Voisit kirjoittaa suodattimeksi ”content-marketing-analytics|content-marketing-lessons” ja saada vain nämä artikkelit.
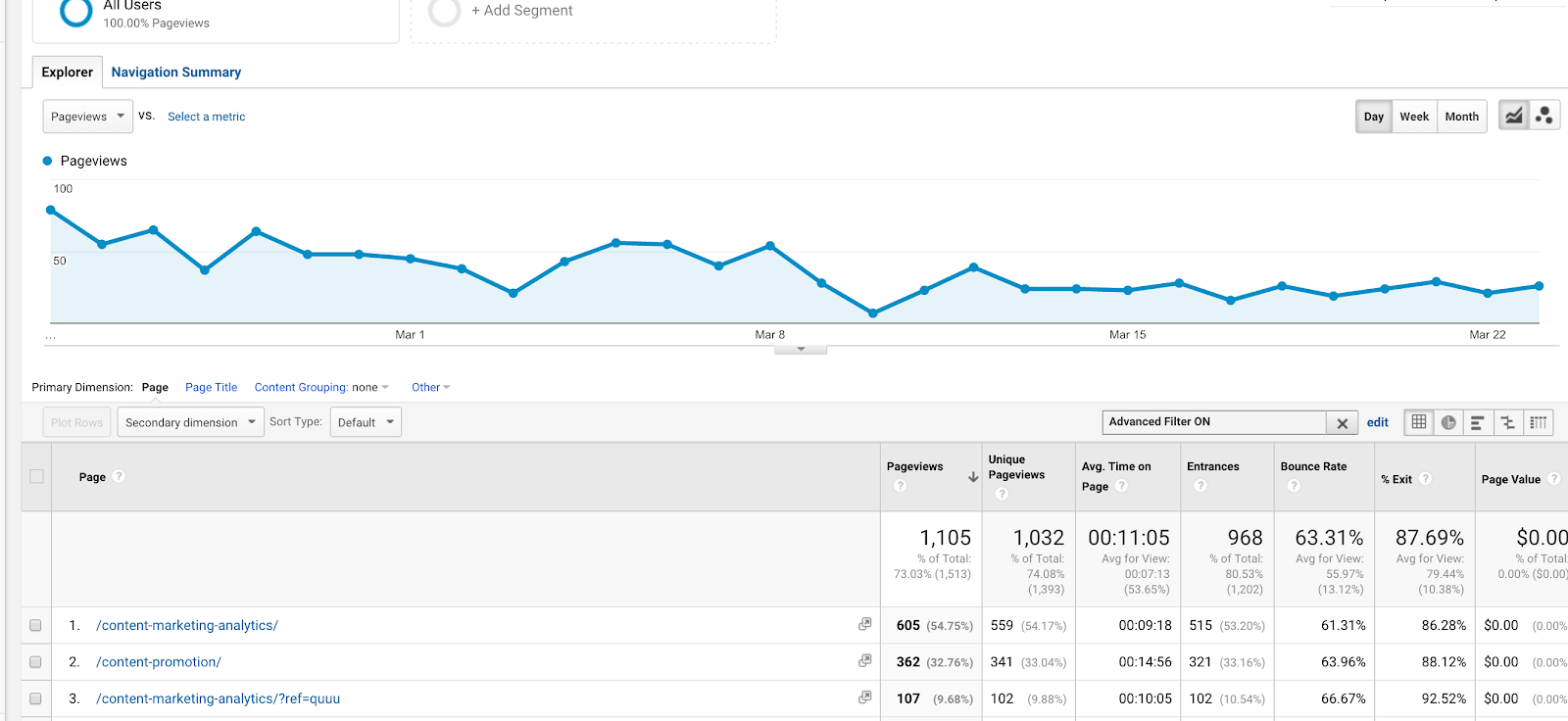
Putken (|) käyttäminen suodattimessa tulosten saamiseksi kahdesta erillisestä blogikirjoituksesta
Takaviivoitus (\)
Takaviivoitus (\) on toinen suoraviivainen ja yleisesti käytetty säännönmukainen lausekkeen muotoinen lausekkeen muotoinen lausekkeen muotoinen lausekkeen muotoinen lausekkeen muotoinen lausekkeen muotoinen lausekkeen muotoinen lausekkeen muotoinen lausekkeen muotoinen lausekkeen muotoinen lausekkeen muotoinen lausekkeen muotoinen lauseke. Se tarkoittaa: ”Pidä seuraavaa merkkiä tavallisena tekstinä eikä regexinä.”
Se tarkoittaa, että on olemassa monia tavallisessa tekstissä esiintyviä säännöllisiä lausekkeita, kuten piste, kysymysmerkki ja muita, joiden kohdalla on selvitettävä, luetaanko ne säännöllisinä lausekkeina vai tavallisena tekstinä.
Yleistä kyselymerkkijonoa verkossa käytetään, kun joku hakee jotain sivustollasi. Kun esimerkiksi etsin ”pieniä koiran leluja” osoitteessa petsmart.com, näyttöön tulee tämä kyselymerkkijono:
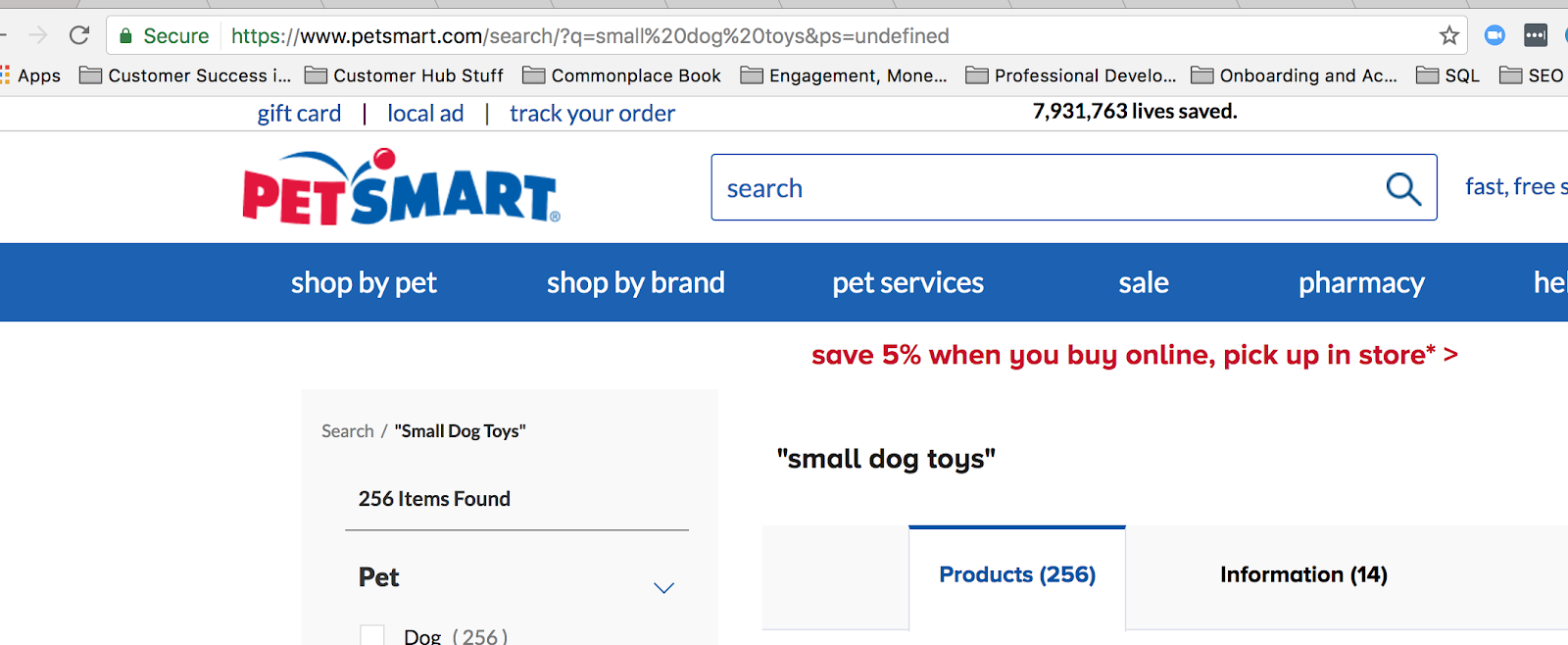
Kun käytät sivustohakua, URL-osoitteeseen luodaan kyselymerkkijono.
Kysymysmerkki tässä ilmaisee, että sivustohaun on tapahtunut, mutta kysymysmerkki on myös yleisesti käytetty säännöllinen lauseke Google Analyticsissa. Siksi meidän on selvitettävä backslash-merkkiä käytettäessä, että tässä tapauksessa kysymysmerkki on luettava tavallisena tekstinä.
Esitettäköön, että haluamme sovittaa kaikkiin Google Analyticsissa oleviin kyselymerkkijonoihin, jotka alkavat kirjaimella /search/?q= (koska se merkitsee hakua). Tällöin säännöllinen lauseke olisi:
search\/\?q=
Voit tarkistaa tämän käyttämällä debuggeria, kuten regex101.com:
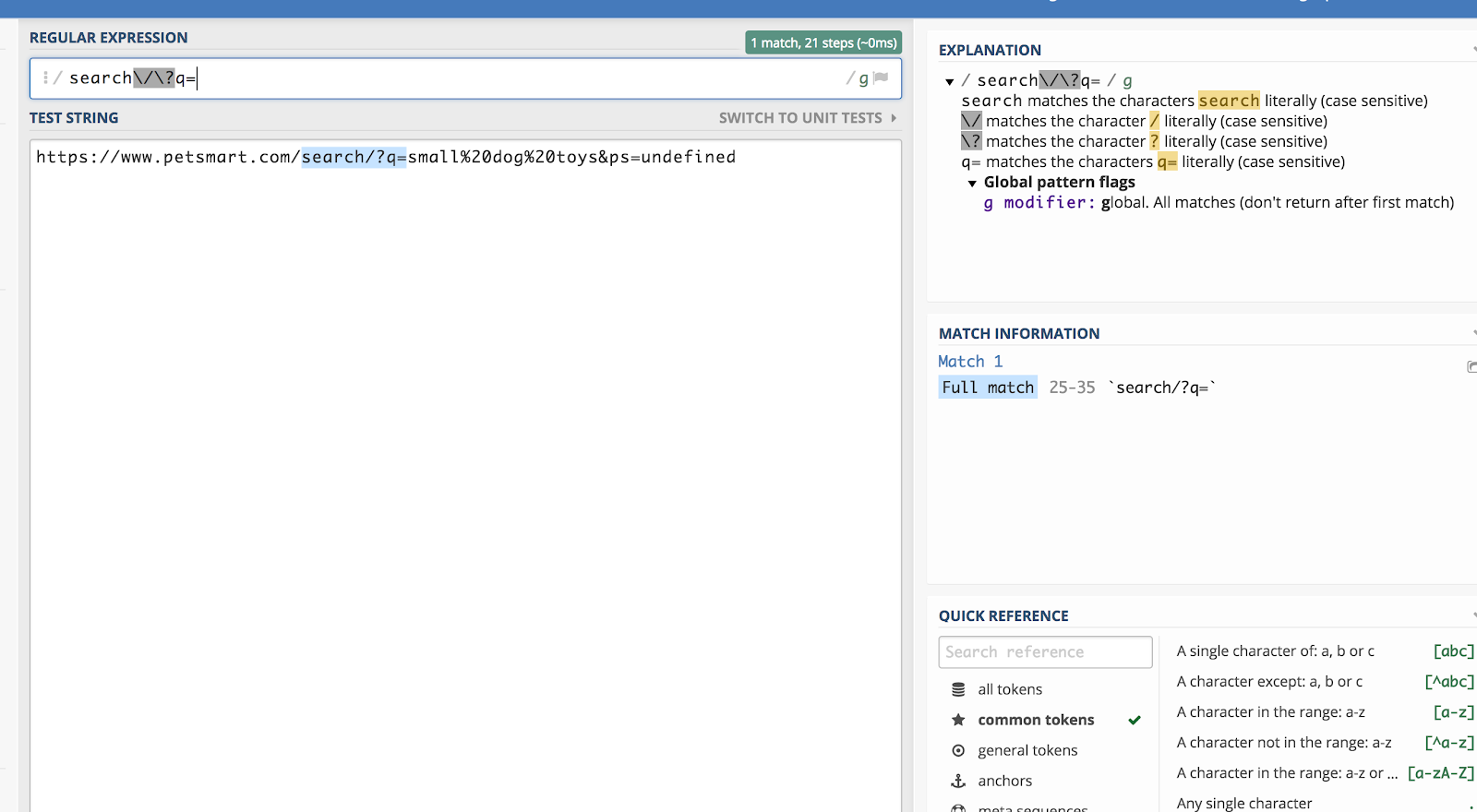
Takasviiva (\) ”pakenee” regexistä yhden merkin verran jälkikäteen ja lukee sen tavallisena tekstinä.
Varjomerkki (^)
Varjomerkki (^) tarkoittaa, että lause alkaa jollain. Tämä on tärkeää, kun sinulla on lauseke, joka voisi esiintyä missä tahansa, mutta haluat etsiä nimenomaan sen alkukohdan. Katso esimerkiksi tätä esimerkkiä, jossa on muutama eri lause, jotka sisältävät sanat ”Tehtävä: onnistui.”
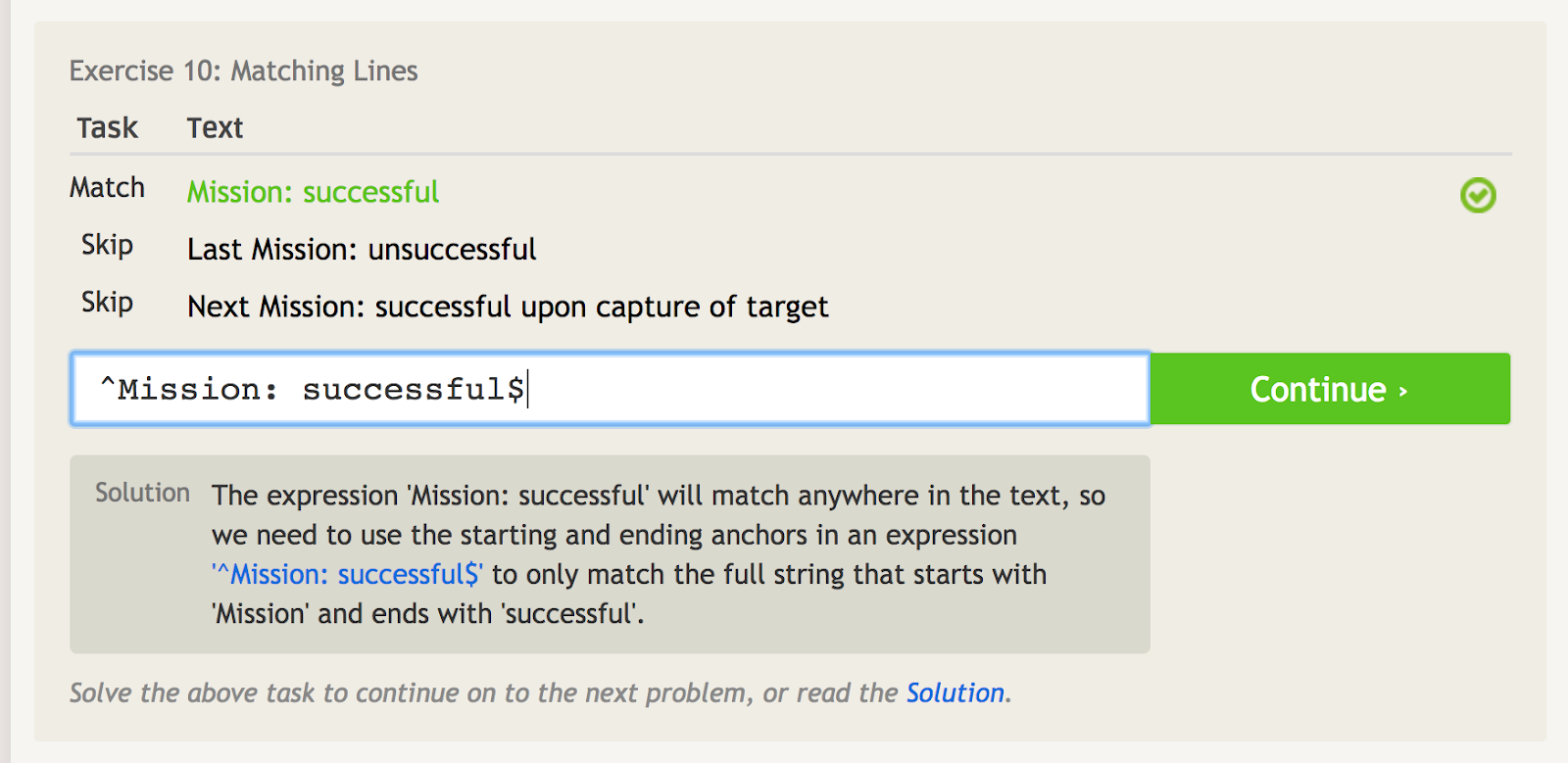
Caret ilmoittaa aloitusankkurin, joten voimme etsiä täsmäämään ainoastaan ensimmäistä lausetta tässä.
Asettakaamme, että sinulla on joukko AdWords-kampanjoita, jotka kaikki alkavat samalla lauseella (koska olet huono tulevaisuuden suunnittelija):
- Freemium-kampanja lopullinen
- Ensimmäinen Freemium-kampanjamme
- Luova Freemium-kampanjatarjous
- Testaa Freemium-kampanjaa
Haluaisit kirjoittaa ^Freemium-kampanja täsmäämään ensimmäiseen kampanjaan, eikä mihinkään muuhun.
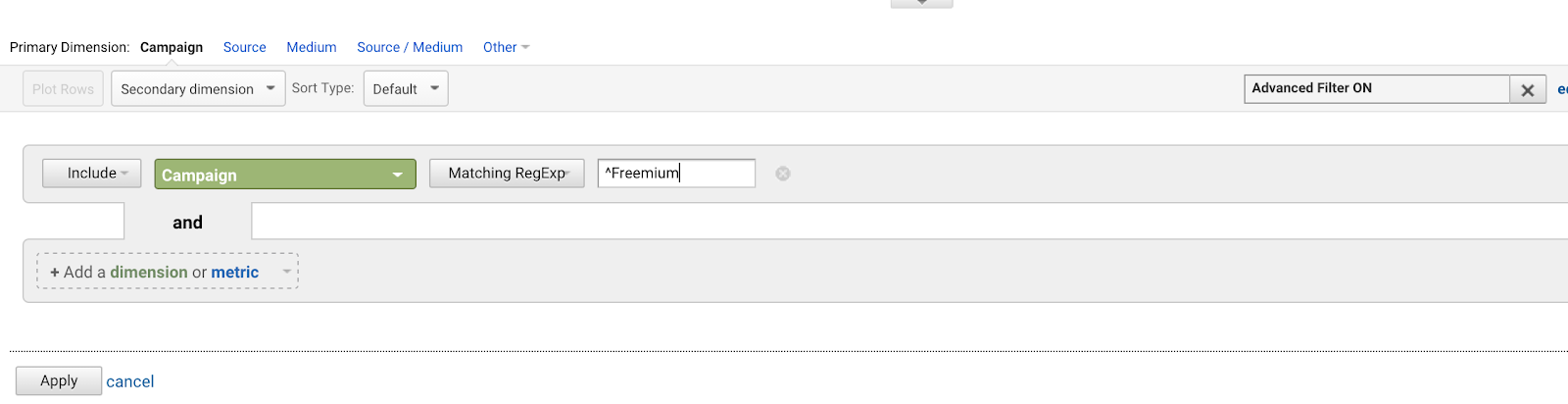
Karetin (^) käyttäminen vastaa merkkijonoja, jotka alkavat näillä merkeillä
USDOLLARIMERKKI ($)
USDOLLARIMERKKI ($) tarkoittaa, että lause päättyy johonkin.
Kun yhdistät nämä kaksi yhdistelmää keskenään, voit tähdätä täsmällisesti täsmääviin lauseisiin.
Jos olet käynnistänyt kampanjan nimeltä ”paidacquisitionfb” ja myöhemmin käynnistänyt kampanjan nimeltä ”paidacquisitionfb-2”, koska et ole suunnitellut hyvin etukäteen ja ajatellut, että sinulla olisi muitakin samannimisiä kampanjoita (tapahtuu koko ajan), voit eristää ensimmäisen kirjoittamalla:
^paidacquisitionfb$
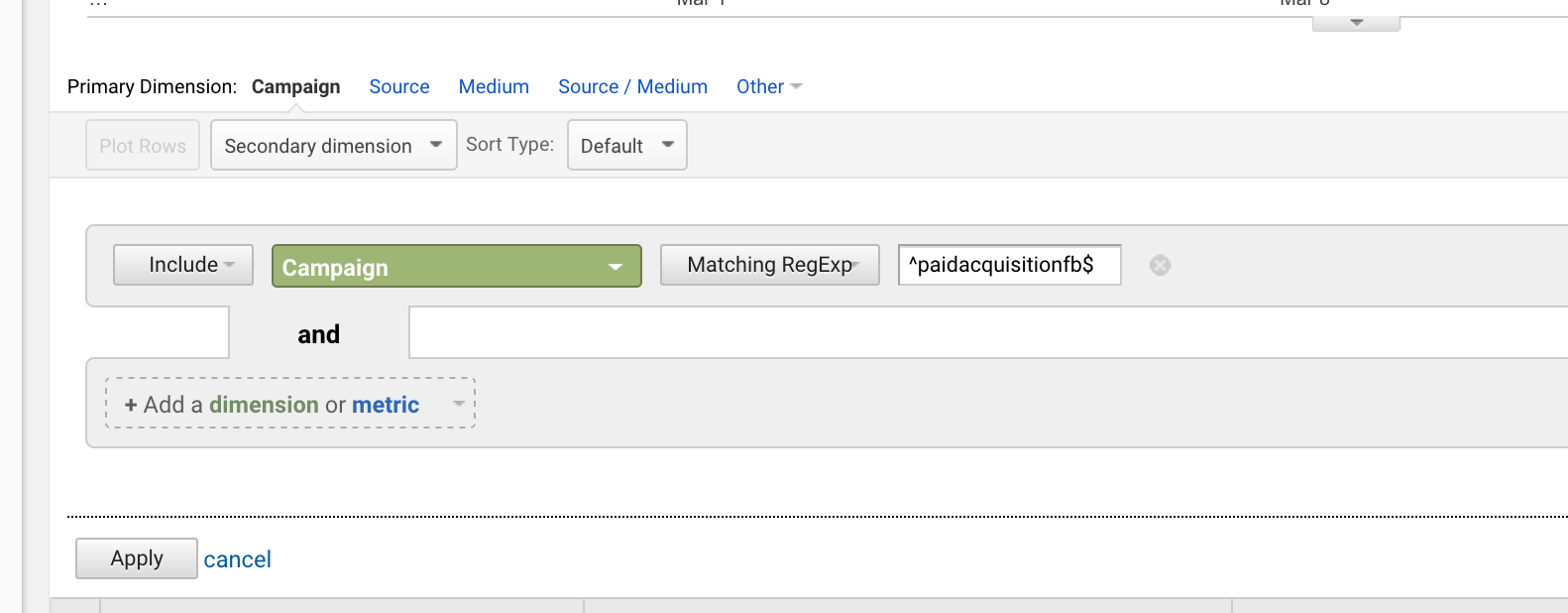
Carettin ja dollarin käyttäminen yhdessä on hyvin yleistä.
Jos blogissasi on esimerkiksi valtavasti kategoriasivuja, ja ne kaikki päättyvät sivunumeroihin, voit kirjoittaa yksinkertaisen Google Analyticsin regexin, jolla voit tarkastella vain blogin kategoriasivuja (^/page/*/$). Näin saisit sellaisia listauksia kuin:
- /sivu/1
- /sivu/2
- /sivu/3
…ja niin edelleen.
Piste (.)
Piste (.) täsmää mihin tahansa merkkiin, eli mihin tahansa merkkiin, jonka löydät näppäimistöltäsi: numeroihin, kirjaimiin, jopa välilyönteihin. Se ei ole erittäin hyödyllinen yksinään, mutta sitä käytetään koko ajan yhdessä muiden säännöllisten lausekkeiden kanssa, erityisesti asteriskin kanssa (tulossa seuraavaksi).
Esitellään, että haluat käyttää sitä yksinään, ja käytetään esimerkkiä ”ki..”. Se sopisi kaikkeen, mikä alkaa kirjaimilla K ja I, ja sitten kahteen seuraavaan merkkiin, mitä tahansa ne ovatkin.
Jos sinulla olisi siis merkkijono, joka sisältäisi sanat kill, kind, kiss, kin, kid! ja kit, se sopisi kaikkiin niihin. Hetkinen, mitä? Kyllä, se täsmäisi ”kit” ja ”kin”, kunhan niiden jälkeen on välilyönti (se poimii myös välilyönnit). Tätä logiikkaa noudattaen se poimisi myös huutomerkin sanassa ”kid!”
Voit nähdä, miksi asiat menevät sekaisin, jos käytät tätä yksinään.
Tässä on havainnollistus yllä olevasta esimerkistä Regex101:n avulla.com:
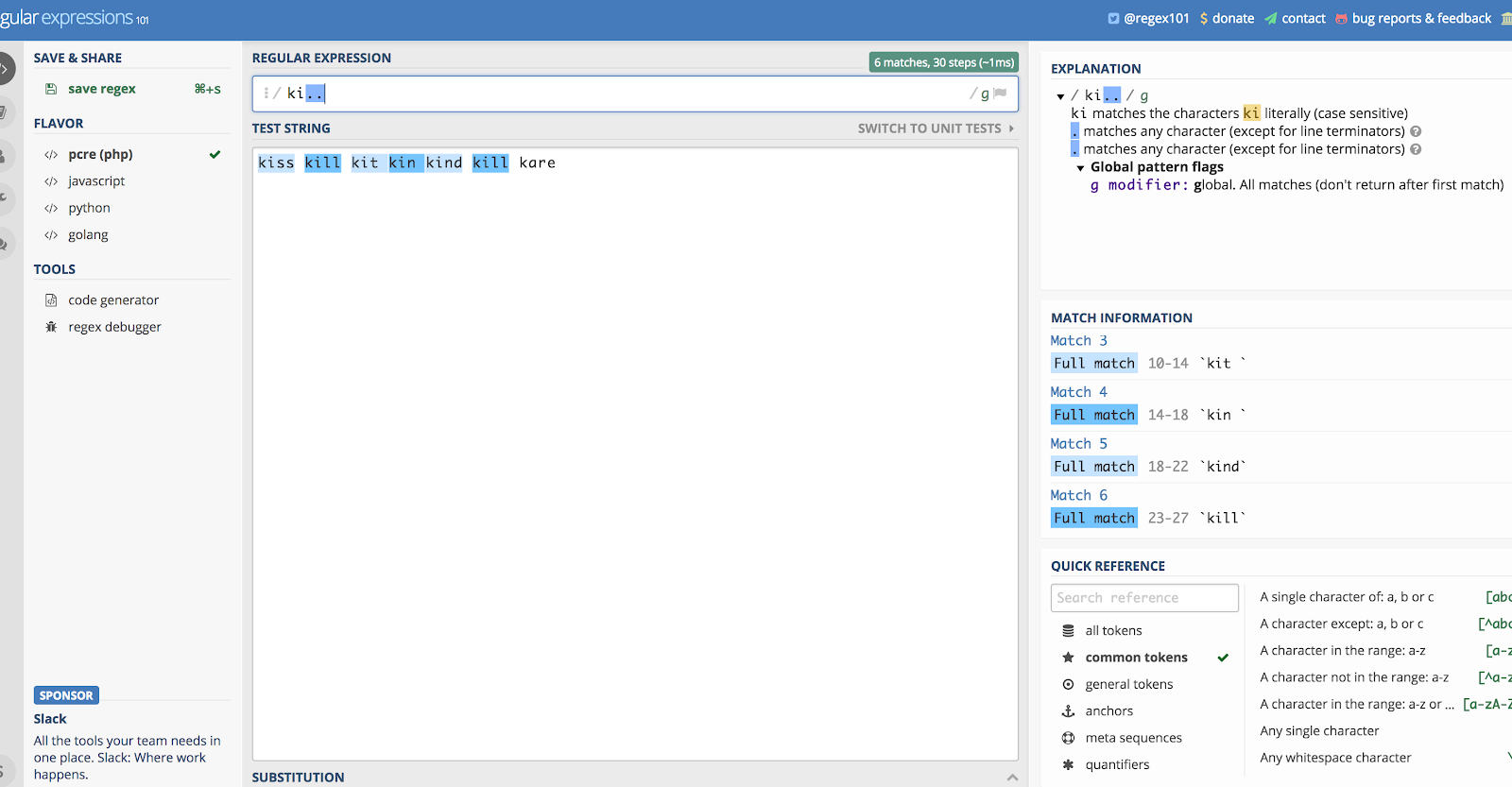
Piste (.) täsmää melkein mihin tahansa.
Tähti (*)
Tähti (*) täsmää nollaan tai useampaan edellisistä kohteista. Vähän hämmentävää, kun sanot sen näin, joten käytän vain esimerkkiä.
Muistatko sen Budweiserin ”wazzup”-mainoksen jokin aika sitten? Olisi aika vaikea arvata, miten joku kirjoittaisi tuon lauseen, jos hän etsisi sitä (vaikkapa YouTubesta). Mutta teoriassa voisit kiteyttää kaikki kirjoitusasun variaatiot tekemällä näin:
waz*up
Tässä on havainnollistus siitä, miten tämä toimii regex101:ssä:
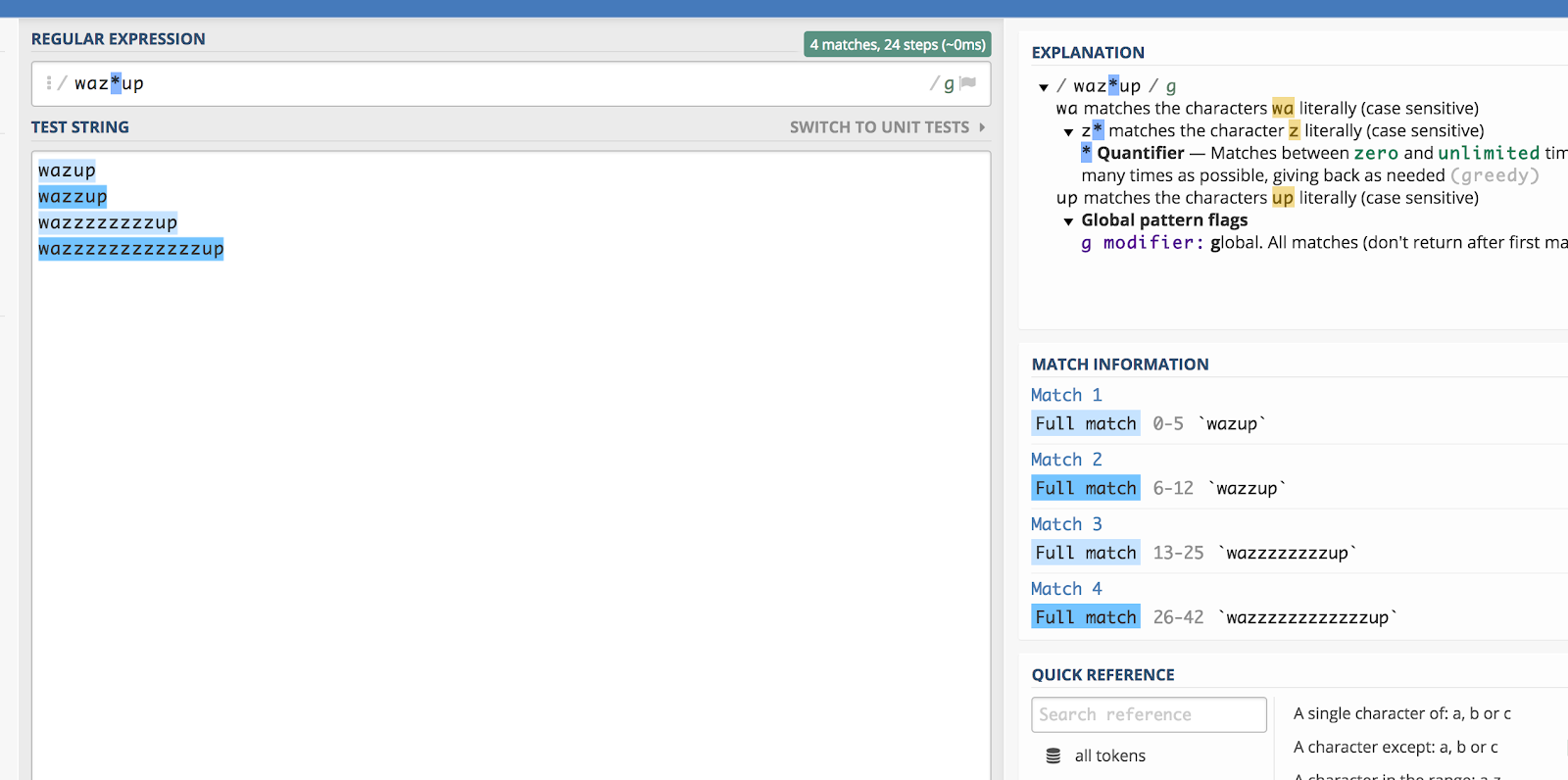
Tähti (*) täsmää edelliseen merkkiin nolla kertaa tai useammin.
Jos haluat olla supertarkka ja ottaa huomioon isot ja pienet kirjaimet, voit kirjoittaa jotakuinkin näin:
*
Mutta poikkean aiheesta.
Missä asteriski on itse asiassa tehokkain ja yleisemmin käytetty, on pisteen kanssa tai osana muita regex-yhdistelmiä.
Piste-steriskiyhdistelmä (.*)
Piste-steriskiyhdistelmä (.*) tarkoittaa periaatteessa, että kaikki käy. Sitä käytetään hyvin yleisesti.
Käytät tätä yhdistelmää, kun haluat sovittaa mitä tahansa merkkijonossa. Koska piste tarkoittaa, että täsmää minkä tahansa merkin kanssa, ja * tarkoittaa, että täsmää nollaa tai useampaa merkkiä ennen sitä, tämä yhdistelmä on erittäin tehokas.
Esimerkki: Sinulla on useita erityyppisiä asiakastilejä, mutta haluaisit nähdä kaikkien niiden tiedot. Niillä kaikilla on samanlaiset sivut, joten sivusi näyttävät jotakuinkin tältä:
/customer/pro/login/
/customer/free/login/
/customer/starter/login/
Voit kirjoittaa seuraavan regex-lausekkeen tehdäksesi tämän:
/customer/.*/login
Käytän yleisesti tätä Google Analyticsin regex-lauseketta segmenttien määrittämiseen käyttäjille, joilla on käyttäjätunnus.
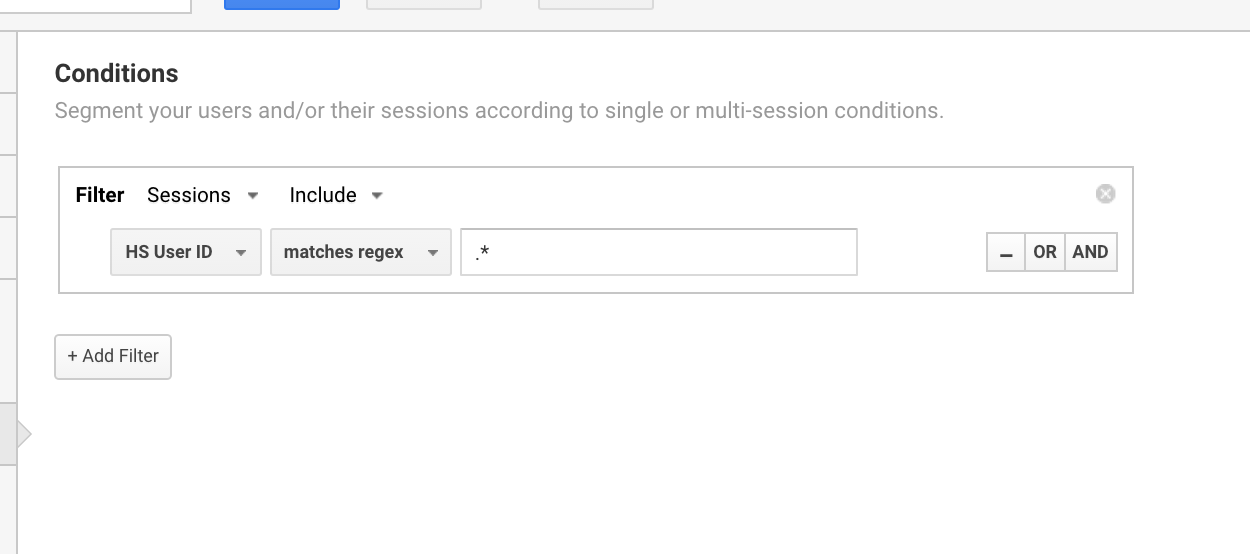
Käytän Google Analyticsin regexiä eristämään kaikki istunnot, joilla on käyttäjätunnus.
Plussamerkki (+)
Plussamerkki (+) on hyvin samankaltainen kuin *-merkki sillä erotuksella, että se täsmää YKSINÄISIIN tai useampiin edellisiin merkkeihin. Tästä ei ole paljon muuta sanottavaa kuin se, että se on hyvin vähän erilainen kuin asteriski. Tässä on ero:
Kuvittele, että sinulla on sanat: hello, hhello ja hhhello.
Jos kirjoitat hh+ello, se vastaa vain kahta jälkimmäistä, mutta jos kirjoitat hh*ello, se vastaa kaikkia niitä.
Pieni ero. Todellisuudessa käytän lähes aina tähteä plusmerkin sijaan.
Kysymysmerkki (?)
Kysymysmerkki (?) on helppo. Se tarkoittaa yksinkertaisesti sitä, että viimeinen merkki on vaihtoehto.
Sitä, että sinulle on aivan sama, onko sana monikossa vai ei (kuten kengät). Se voi olla ”kenkä” tai ”kengät”, ja haluat kaapata sen kummallakin tavalla. Silloin voit kirjoittaa ”kengät?”
Tässä on esimerkki, jossa käytetään nimeäni. Jos joku kirjoittaisi sen ”Alex Birket” sivustohaun aikana, haluaisin luultavasti silti nähdä sen. Voin siis kirjoittaa:
Alex Birkett?
Tältä se näyttää regex101.com-sivustolla:
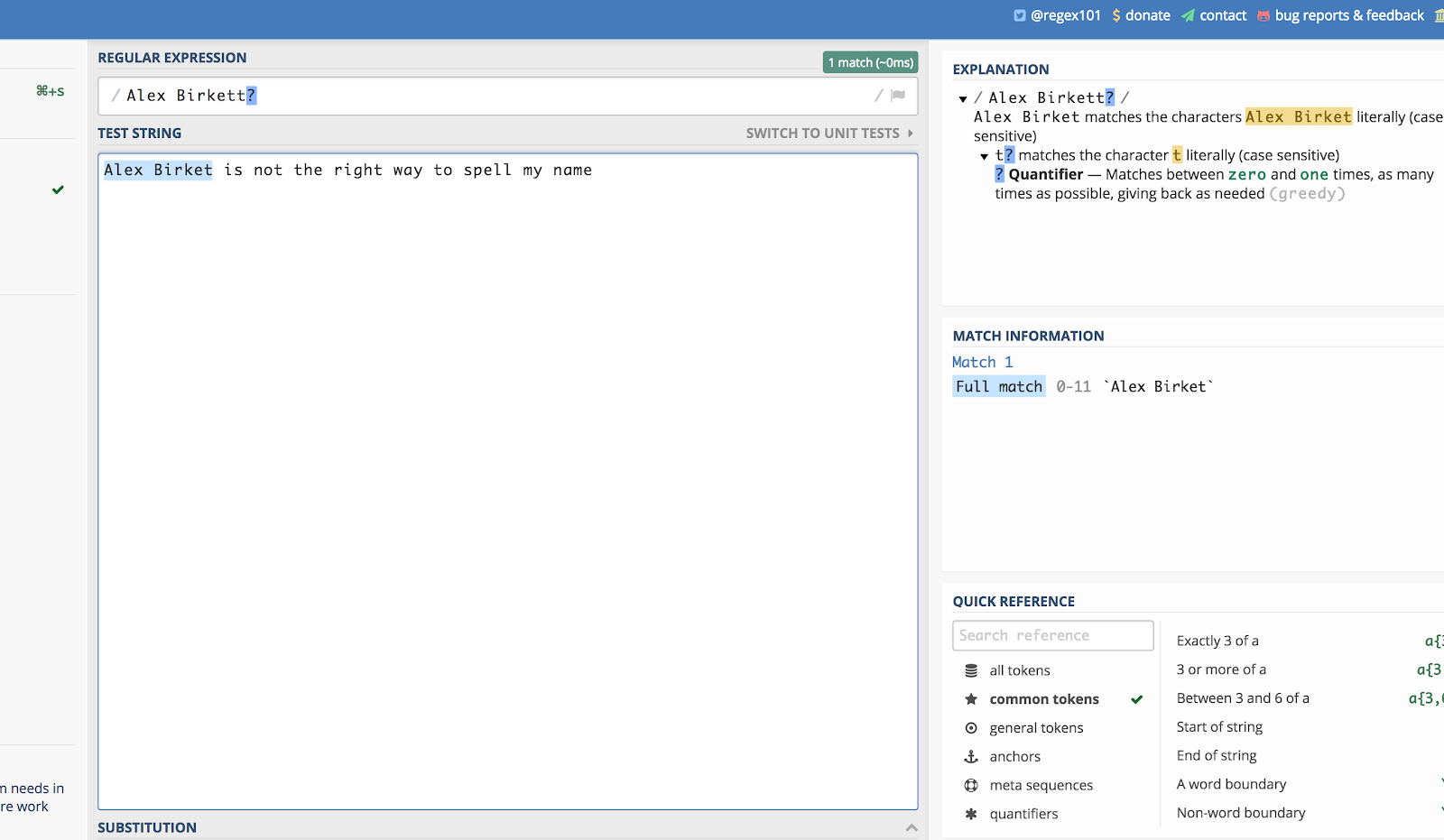
Kysymysmerkki (?) tekee sen niin, että sitä edeltävä viimeinen merkki on valinnainen.
Parentheses ()
Parentheses toimii samalla tavalla kuin matematiikassa. Ne kertovat sinulle priorisoida ja eristää logiikan, että se on pelissä niiden sisällä.
Esitettäköön, että sinulla on SaaS-yritys, jolla on kolme tarjontaa ja haluat sovittaa kaikki hinnoittelusivut yhteen. URL-osoitteesi ovat seuraavat:
site.com/tuotteet/tapaamiset/hinnoittelu
site.com/tuotteet/crm/hinnoittelu
site.com/products/email/pricing
Voidaksesi napata kaikki kolme näistä, voisit käyttää tällaista säännöllistä lauseketta:
^/products/(meetings|crm|email)/pricing$
Neliösulkeet ()
Neliösulkeet () luovat luettelon. Jos sinulla on kolme merkkijonoa, ”asia1”, ”asia 2” ja ”asia3”, voit sovittaa ne kaikki kirjoittamalla ”asia” tai ”asia” (katkoviivoista lisää myöhemmin – niitä käytetään yleisesti hakasulkujen kanssa.
Hakasulkuja voidaan käyttää sovittamaan yhteen sanan tai merkkijonon useita iteraatioita ja samalla sulkemaan pois useita muita iteraatioita. Jos esimerkiksi haluat yhdistää sanat ”can”, ”man” ja ”fan”, mutta et sanoja ”dan”, ”ran” tai ”pan”, voit käyttää tätä varten seuraavaa regexiä:
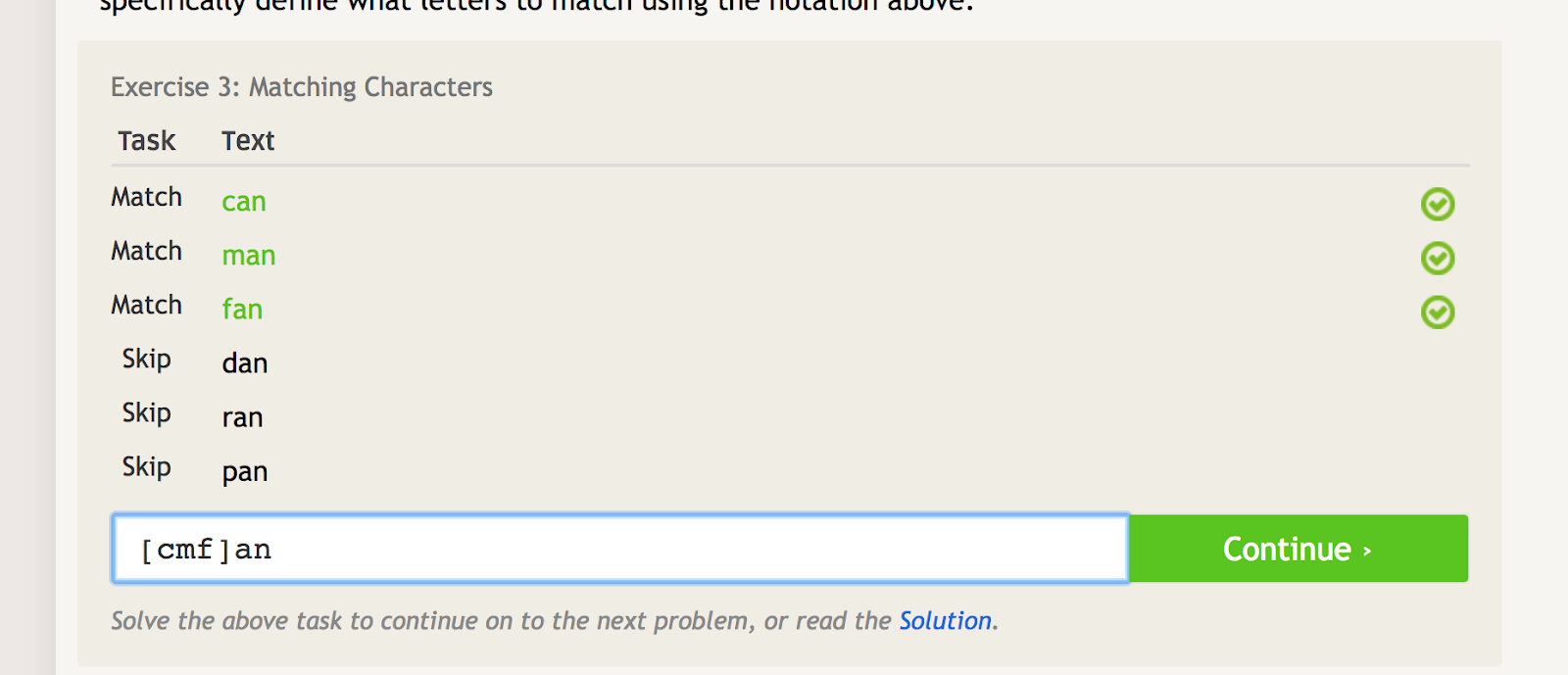
Neliösulkeet luovat useita täsmäämisehtoja riippuen siitä, mitä merkkejä laitat niiden sisään. – kuvan lähde
Tätä voit käyttää, jos sinulla on useita eri tuotteita, joilla on samanlaiset nimet, kuten ”kengät1”, ”kengät3” ja ”kengät5”. Voisit sovittaa yhteen nämä, etkä mitään muuta, käyttämällä ”kengät”
Dashes (-)
Dashes (-) toimii lineaaristen tuoteluetteloiden luomiseksi.
Kun käytät hakasulkeita, sinun ei tarvitse yksinkertaisesti luetella kaikkea pois, jos se esiintyy lineaarisesti. Jos siis haluaisit sopia numerosarjaan, jossa viimeinen voi olla mitä tahansa nollasta yhdeksään, voisit kirjoittaa näin:
1234
Vai voisitko kirjoittaa paljon yksinkertaisemmin:
1234
Tämä toimii myös kirjaimille. Kuvitellaan, että sinulla on sivuluokka, joka päättyy kahteen satunnaiseen kirjaimeen. Jotain tällaista:
/page-aa/
Voit sovittaa kaikki nämä kirjoittamalla:
/page-*/
Voit nähdä esimerkin tästä regex101:ssä täältä:
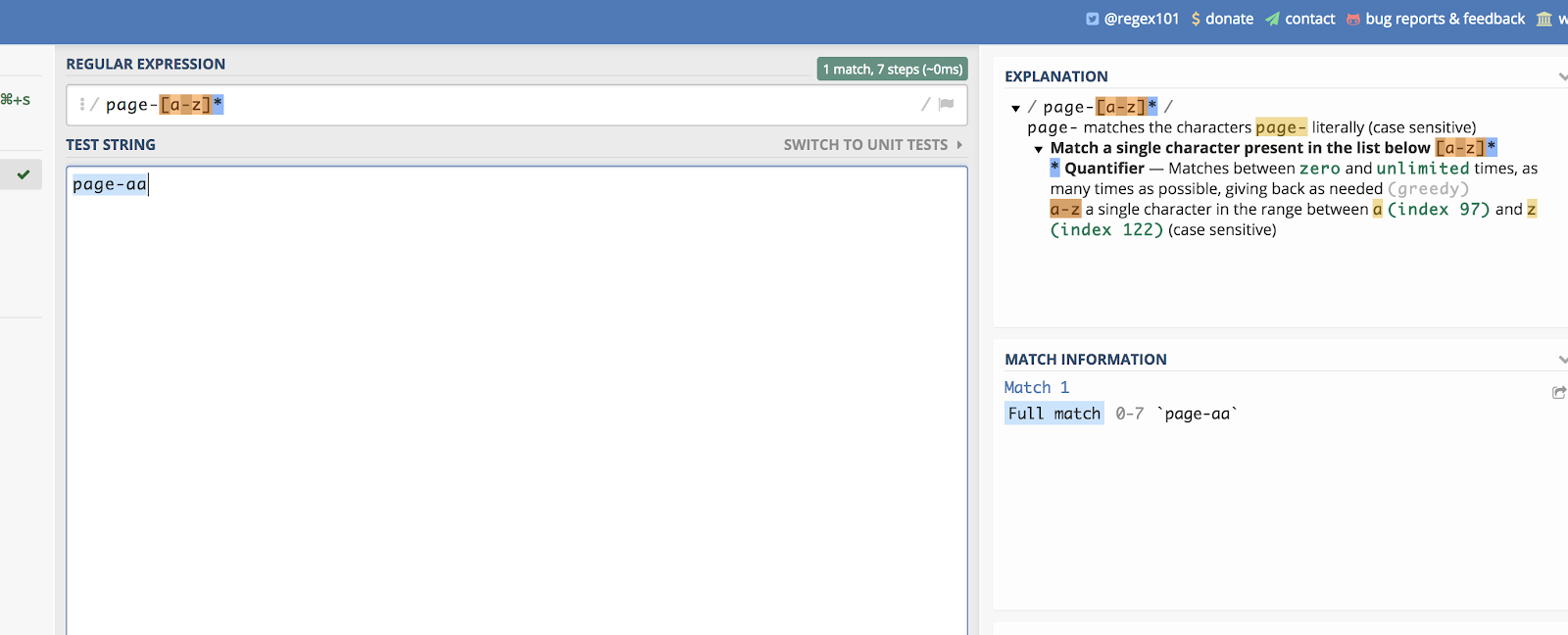
Viivoitusviivojen avulla voit luoda lineaarisen listan sovittamista varten.
Sirappisulkeet ({ })
Sirappisulkeet ({}) kertovat, kuinka monta kertaa viimeinen kohta toistetaan.
Jos esimerkiksi haluat yhdistää vain ”wazzzzup”, voit käyttää ”waz{4}up”.
Mutta jos haluat yhdistää ”wazzzzzup” ja ”wazzzup”, mutta et ”wazup”, voit käyttää ”waz{3,5}up”. Tämä tarkoittaa periaatteessa sitä, että merkkiä ”z” on vastattava vähintään kolme kertaa, mutta enintään viisi kertaa.
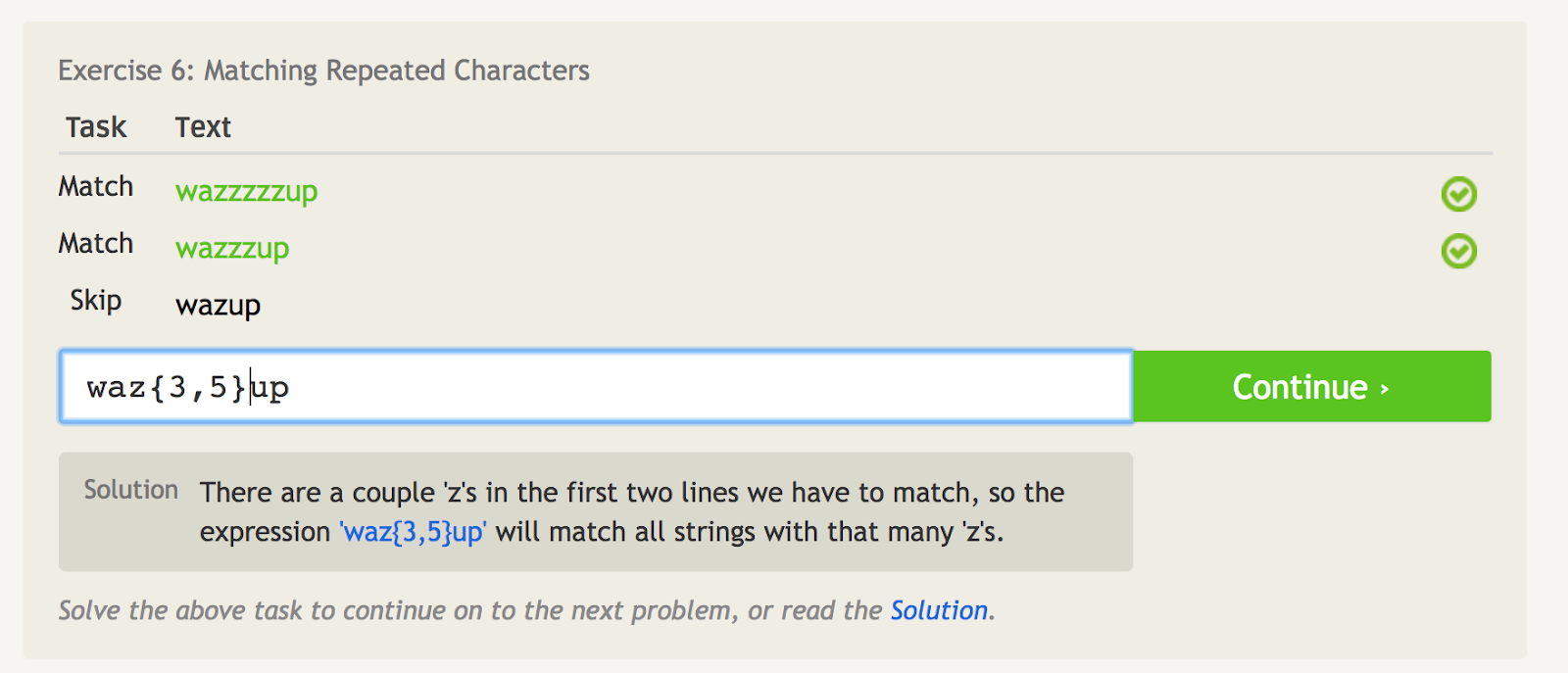
Sirappisulkeet kertovat, kuinka monta kertaa viimeistä kohtaa toistetaan. – kuvan lähde
En todellakaan ole käyttänyt tätä säännöllistä lauseketta paljon Google Analyticsissa, mutta yleinen käyttötapaus voisi olla postinumeroille. Yleensä kaupungin kaksi ensimmäistä merkkiä ovat samat (78- esimerkiksi Austinissa, TX:ssä). Voit siis etsiä mitä tahansa Austinin, TX:n postinumeroa kirjoittamalla:
78{3}
Tässä sanotaan, että kolme viimeistä kirjainta voi olla mikä tahansa satunnainen luku nollasta yhdeksään.
Google Analytics RegEx: Konkreettisia esimerkkejä, joita voit käyttää
Yksi tavallisimmista Google Analyticsin regexin käyttötapauksista on suodattimien rakentaminen. Käydään läpi kolme esimerkkiä, yksi yksinkertainen ja yksi hieman monimutkaisempi.
Ensiksi esimerkki, joka on saanut inspiraationsa Jenny Halaszin loistavasta postauksesta Search Engine Landissa.
Esitettäköön, että sinulla on sotkuinen sivuston arkkitehtuuri, mutta haluat katsoa kaikki viestit, joissa on tietty alihakemisto. Se voi olla mitä tahansa, vaikkapa sivuston kategoria tai sisältötyyppi. Tässä esimerkissä etsimme sivuston kategoriaa /music/, mutta vain kolmannessa alihakemistossa. Tässä tapauksessa voit kirjoittaa ^/.*/.*/music/.*, jolloin saat kyseisen raportin.

Tämä Google Analytics -regex näyttää sinulle vain /music/ kolmannessa alihakemistossa. – kuvan lähde
Se näyttää ensi silmäyksellä hämmentävältä – mutta kun olet oppinut, mitä nämä säännölliset lausekkeet tarkoittavat, se on melko suoraviivaista. Pohjimmiltaan kerromme GA:lle vain, että se etsii laskeutumissivua, joka alkaa (^) vinoviivalla, sitten millä tahansa merkillä (.*), sitten vinoviivalla, sitten millä tahansa merkillä (.*), sitten vinoviivalla ja sitten musiikilla.
LawnStarter käyttää samanlaista taktiikkaa raportointiin. Heidän strategiansa on luoda kaupunkikohtaista sisältöä kaupunkisivujensa alikansioon käyttäen seuraavaa muotoa:
https://www.lawnstarter.com/{{kaupunkisivun transaktiosivu }}/{{tietosisällön tietopala }}
Suodattaakseen sisällön pois konversiosuppiloista ja liikenneraportoinnista he käyttävät perustaja Ryan Farleyn mukaan seuraavaa regexiä.
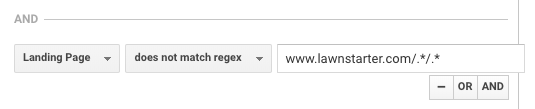
Tämä regex auttaa LawnStarteria sovittamaan kaupunkikohtaista sisältöä sivustollaan.
Käsitellään seuraavaksi läpi, miten suodatin asetetaan yhdelle Google Analytics -näkymälle. On todennäköistä, että sinulla on toteutusasiantuntija, joka tekee tämän – mutta jos ei, mittaa aina kahdesti ja leikkaa kerran. Nämä asiat on helppo sotkea (minkä vuoksi Google Analytics -tilillesi kannattaa myös määrittää hiekkalaatikkonäkymä, jotta voit kokeilla asioita ensin).
Suodattimien määrittämiseksi siirry kohtaan Hallinta > Suodattimet > Lisää suodatin.
Yleisimmin Google Analyticsissa käytetty suodatin lienee oman IP-osoitteesi (omien IP-osoitteidesi) liikenteen poissulkeminen.
Monille tämä voidaan asettaa yksinkertaisesti, koska sinulla on vain yksi IP-osoite. Suuremmissa yrityksissä sinulla voi olla useita IP-osoitteita, ja voit asettaa poissulkemiset helpommin Google Analyticsin regexillä.
Jos esimerkiksi kirjoittaisit 63\.212\.171\.., se sulkisi pois kaikki IP-osoitteet 63.212.171.1-63.212.171.9.
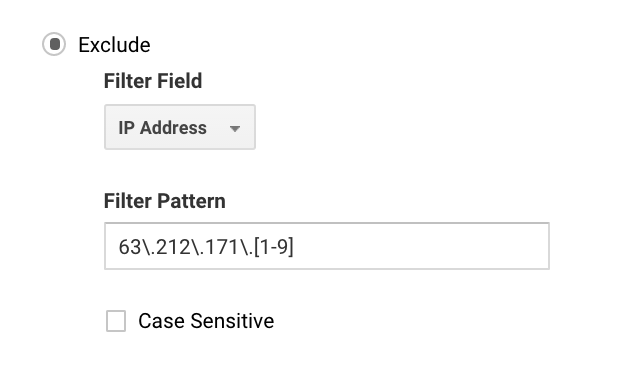
Tämä Google Analyticsin regex sulkee pois useita IP-osoitteita.
Toinen asia, jonka voit tehdä Google Analyticsin regexillä, on asettaa suodattimia, jotka siivoavat kyselyparametreja.
Tämä voi olla sekä ärsyttävää että ongelmallista data-analyysin kannalta.
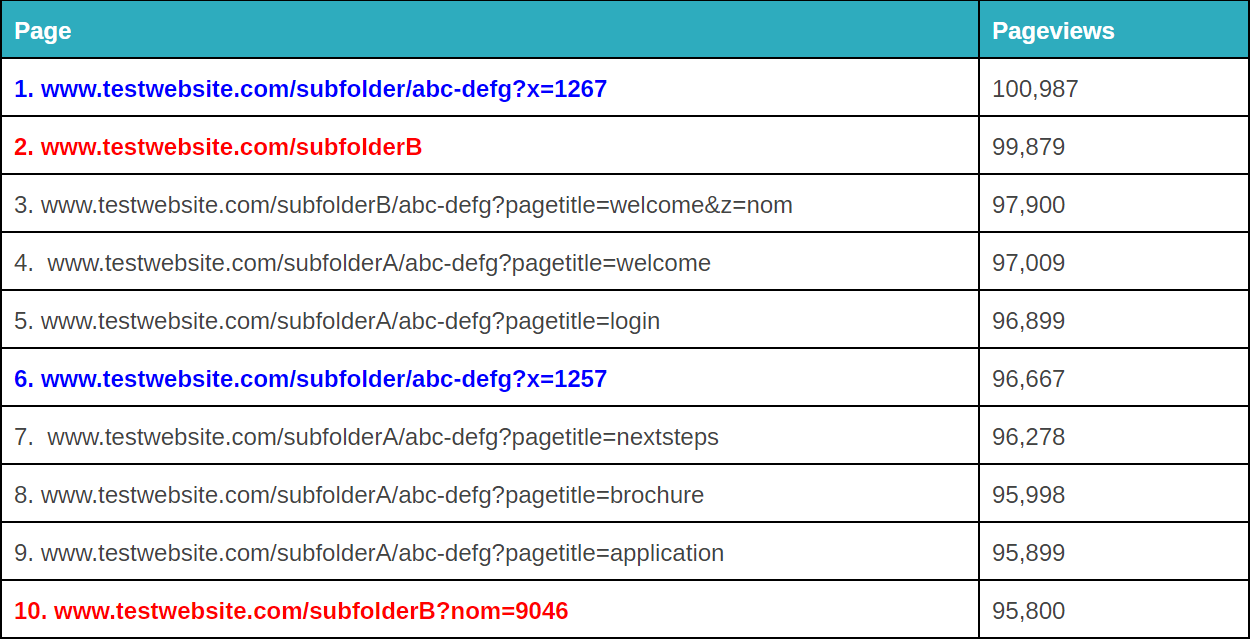
Murtuneet kyselyparametrit voivat olla ärsyttäviä. – kuvan lähde
Se riippuu siitä, millainen erityistilanteesi on, mutta on olemassa muutamia eri tapoja, joilla voit käyttää regexiä tuon siivoamiseen (huomautus: voit tehdä tämän myös Google Tag Managerissa tai Excelissä ongelman laajuudesta riippuen. Siitä lisää täällä).
Keskustellaan lopuksi yhdestä esimerkistä, jonka avulla voimme järjestää aladomainin seurannan paremmin. Jos sinulla on useita verkkotunnuksia tai aliverkkotunnuksia, on mahdollista, että sinulla on päällekkäisiä URL-osoitteita, ellet aseta suodatinta lisäämään isäntänimeäsi pyynnön URi:n eteen. Toisin sanoen sinulla saattaa olla kaksi URL-osoitetta:
- site.com/about
- blog.site.com/about
Nämä edustavat kahta eri sivua (toinen on sivua yrityksestäsi ja toinen on blogisi about-osio). Mutta ne molemmat näkyisivät Google Analyticsissa nimellä /about, ellet aseta seuraavaa suodatinta (käyttämällä piste-asteriskiyhdistelmää Google Analyticsin säännöllisiä lausekkeita):
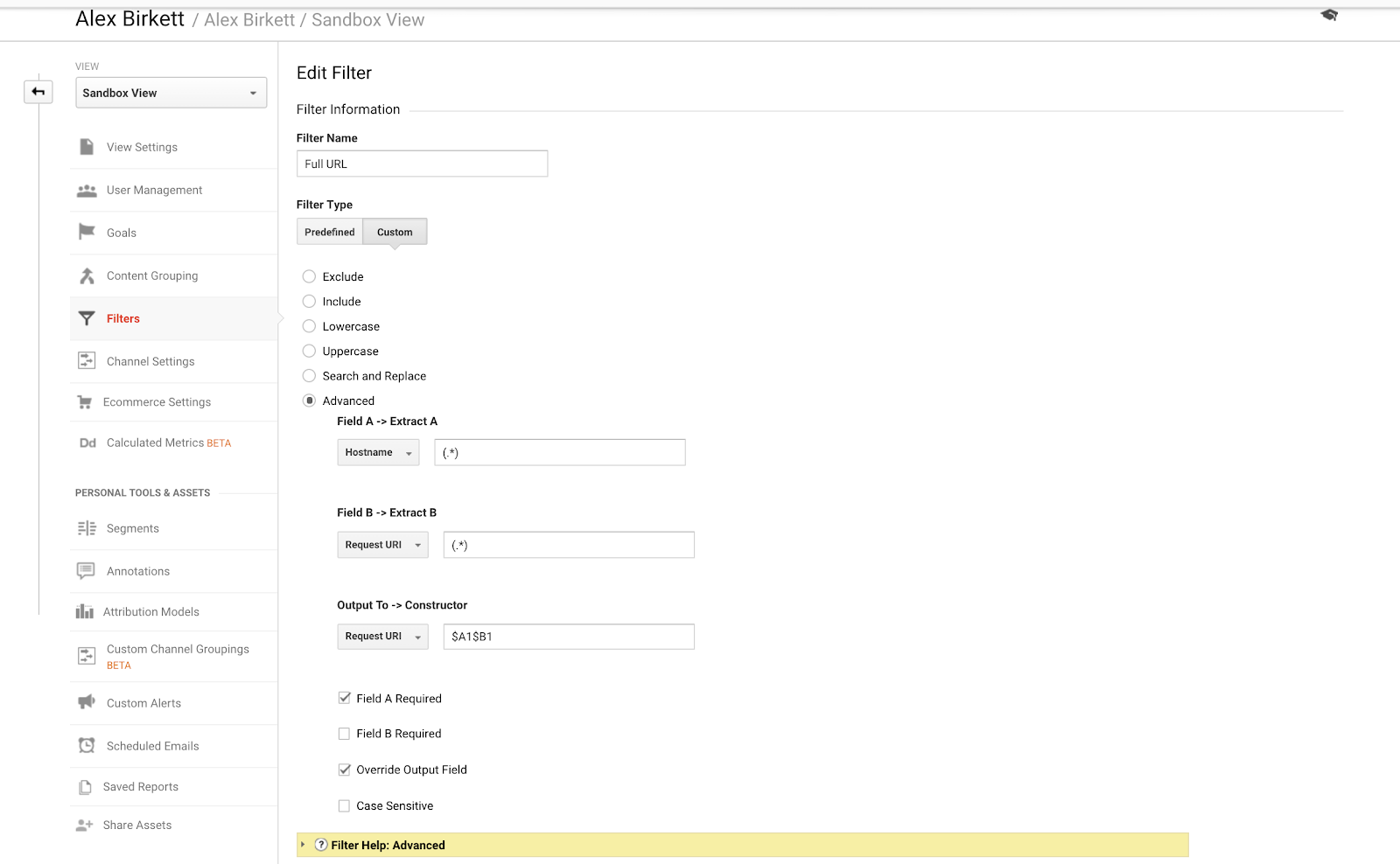
On melko yksinkertaista määrittää tämä perustavanlaatuinen GA-suodatin. – Kuvan lähde
Olemme itse asiassa jo käsitelleet näiden suodattimien määrittämistä melko perusteellisesti aiemmassa KlientBoostin postauksessa, joka käsitteli verkkotunnusten ja aliverkkotunnusten seurantaa.
Google Analytics RegEx -vinkit & Vältettävät virheet
Regulaariset lausekkeet kuuluvat niihin asioihin, joiden opetteleminen vaatii harjoittelua ja käsien likaamista. Sellaisena tulet tekemään virheitä.
Se on oikeastaan tärkein vinkki: kokeile asioita ja katso, toimivatko ne. Olen listannut tässä postauksessa runsaasti resursseja, joiden avulla voit testata regexiäsi, regex101.comista regexbuddy.comiin. Kasta varpaasi ja käytä näitä resursseja.
Vaikka, joidenkin ennakkotietojen ja heuristiikkojen avulla voit oppia nopeammin ja saada enemmän virheitä kiinni.
Yksi asia, joka kannattaa todella opetella, on se, miten ”paeta” regexissä (puhuimme tästä noin backslash-merkinnän kanssa). Leho Kraav, CXL-instituutin teknologiajohtaja, ilmaisee asian näin:
”Sanoisin, että opettele ”opettelemaan asioiden oikeanlaista escapettamista” – on helppoa saada mismatcheja, kun merkit ovat samoja, mutta niiden merkitys on erilainen riippuen siitä, onko ne escapattu vai ei.”
Jos kyselyssäsi on esimerkiksi kysymysmerkki, sekin on säännönmukainen lausekkeenne, joten se on tehtävä selväksi takaviivalla. MeasurementMarketing.io:n perustaja Chris Mercer sanoo myös, että tämän kyvyn opettelematta jättäminen on yksi suurimmista virheistä, joita hän näkee aloittelijoiden tekevän:
”Yleisin virhe, jonka näemme regexiä käyttävillä aloittelijoilla, on se, että he unohtavat ”paeta” regex-symbolit. Jos esimerkiksi etsit sivuja, jotka vastaavat regexiä ”thankyou/?success=yes”, se ei toimi. Itse ”?” on regex-symboli, ja se on poistettava käytöstä käyttämällä ”escape-merkkiä” (” \”. Tässä tapauksessa ”thankyou/\?success=yes” toimisi.”
Toinen vinkki? Pidä se yksinkertaisena. Ihmiset yrittävät monimutkaistaa asioita (katso monimutkaisin koskaan näkemäsi regex, jonka Leho on kirjoittanut, täältä), mutta säännölliset lausekkeet ovat ”ahneita” ja täsmäävät niin paljon kuin mahdollista. Google Analytics julkaisi blogikirjoituksessa vinkkejä ja selitti asian näin:
”Jos sinun täytyy kirjoittaa lauseke, joka vastaa ”uusia käyntejä”, ja ainoat vaihtoehdot, joita vastaat, ovat ”uudet käynnit” ja ”toistuvat käynnit”, pelkkä sana ”uusi” riittää.”
Regulaarilausekkeet täsmäävät kaikkeen, mihin pystyvät, ellet pakota niitä olemaan. Jos lausekkeesi on ”visits”, se vastaa ”new visits” ja ”repeat visits”. Loppujen lopuksi ne molemmat sisälsivät ilmauksen ”visits”. Jotta ne eivät olisi niin ahneita, niistä on tehtävä spesifisempiä.”
Aloita siis hitaasti, pidä homma yksinkertaisena äläkä hukuta itseäsi monimutkaisuuteen (virheiden mahdollisuus korreloi tässä tapauksessa monimutkaisuuden kanssa).
Mercer toistaa myös tämän kohdan ja neuvoo ottamaan asiat haltuun vähitellen:
”Kun aloitat ensin, keskity siihen, että tulet hyväksi… ja sitten paranet. On helppo hukkua kaikkiin mahdollisuuksiin, joita regex tarjoaa, mutta jos aloitat vain perusasioista, kuten hallitset ”tai”-symbolin (” | ”), saat nopeasti kokemusta ja alat ymmärtää, mitä kaikkea regexillä on mahdollista tehdä.”
Loppuvinkki minulta: opettele googlettamaan asioita. Tämä pätee kaikkeen ohjelmointiin, mutta erityisesti säännöllisiin lausekkeisiin. Unohdat asioita, ja jos et kirjoita regexiä päivittäin, ei ole mitään järkeä opetella kaikkea ulkoa. Opettele etsimään asioita ja etsimään vastauksia siihen, mitä yrität tehdä.
Google Analyticsin ulkopuolella: RegEx for Other Marketing Uses
Regex on myös asia, johon kaikkien SEO-ammattilaisten tulisi tutustua. Ensinnäkin tietenkin siksi, että SEO ja digitaalinen analytiikka (esim. Google Analytics) liittyvät erottamattomasti toisiinsa. Toiseksi siksi, että joitakin samoja täsmääviä lausekkeita, joita kirjoitamme suodattaaksemme ja täsmäyttääksemme merkkejä Google Analytics -tiedoissamme, voidaan käyttää myös tietojen poimimisessa SEO-taktiikoita varten.
Muiden sanojen mukaan säännölliset lausekkeet ovat tärkeitä web-skrappauksessa.
Web-skrappauksen ja SEO:n tapauksessa työskentelet tavallisesti ohjelmointikielen, kuten Pythonin, kautta, mutta periaatteet ovat samat.
Esimerkiksi voit kaavata kaiken lihavoidun tekstin sivulta käyttämällä tätä:
<strong>(+)</strong>
Od kuten tässä SEJ:n artikkelissa mainitaan, jos kaavittaisiin ESPN:ää kaikkien kirjoittajien osalta, voitaisiin kirjoittaa näin:
”kolumnisti”:”(.*??)”
Yhteensopivuuden ja tervejärkisyyden vuoksi en aio uppoutua edistyneempään web-skrappaukseen asti. Riittää, kun tiedän, että regex on tärkeä tälläkin alueella. Jos kuitenkin haluat oppia lisää, suosittelen näitä lähteitä:
- Web Scraping with Regular Expressions
- Scraping with Regular Expressions (Stanford)
- How to Use Regex for SEO & Website Data Extraction
Säännöllisten lausekkeiden avulla voit työskennellä SEO-tietojesi parissa muutenkin kuin pelkällä webin kaapimisella. Voit esimerkiksi käyttää regexiä muokkaamaan Screaming Frogin käyttöä entisestään.
Jenny Halasz antoi hyvän esimerkin regexin käyttämisestä datan siivoamiseen Search Engine Landin postauksessa:
”Sanotaan esimerkiksi, että sinulla on lista URL-osoitteita ja sinun täytyy pilkkoa ne pelkkään TLD:hen (Top Level Domain).
Voit käyttää yksinkertaista find/replacea http:lle ja www:lle, mutta miten voit helposti kopioida kaikki tiedostonimet? Voit poistaa ne kaikki manuaalisesti, mutta se on hankalaa. Käyttämällä yksinkertaista regex-vaderkoodia (/*) voit poistaa vinoviivan ja kaiken sen jälkeen tulevan.”
Voisimme puhua loputtomiin säännöllisistä lausekkeista SEO:ssa ja web scrapingissa, mutta linkitän vain muutamaan hyvään resurssiin, jos haluat oppia lisää (se on loppujen lopuksi hyvin monipuolinen kieli, jolla on monia käyttötapauksia muuallakin kuin analytiikassa):
- How Regular Expression Affects SEO
- 5 Powerful Awesome Awesome Htaccess Redirect Tricks
- How to Use Regular Expression for Report Segmentation
Conclusion
Googlen analytiikan regex on oikeastaan jotain, joka jokaisen analyytikon pitäisi tuntea, vaikka et kuvittelisikaan itseäsi tekniseksi. Sen lisäksi joidenkin säännöllisten lausekkeiden osaaminen (tai ainakin se, miten etsiä vastauksia ja soveltaa niitä oikeisiin ongelmiin) voi auttaa markkinoijia myös erilaisissa toiminnoissa.
Huomautan vain, että se ei ole kovin yleinen taito, joten luultavasti teet vaikutuksen joihinkin kollegoihisi uusilla teknisillä markkinointitaidoillasi.
Kehotan siis sinua, aloita opettelu, ja mikä vielä tärkeämpää, aloita ihan vain harjoittelemaan säännöllisten lausekkeiden käyttöä. Ne eivät ole niin pelottavia.