Google Analytics regex (adică expresii regulate) este un set de abilități subapreciate.
Dacă doriți să faceți orice fel de filtrare sau direcționare dincolo de elementele de bază, o bună stăpânire a regex-ului vă va oferi superputeri Analytics.

Regex vă oferă superputeri. – sursa imaginii
Desigur, expresiile regulate au cazuri de utilizare mult mai largi decât analiza și marketingul. Dar, în scopul acestui articol, vom acoperi câteva cazuri de utilizare tactică care v-ar putea ajuta în ceea ce privește perspectivele utilizatorilor, organizarea datelor și chiar cazurile de utilizare a direcționării avansate și a marketingului pentru motoarele de căutare.
Dar, mai întâi, să rezumăm pe scurt ce sunt expresiile regulate, în special în legătură cu Google Analytics.
- Google Analytics RegEx: Ce este?
- Google Analytics RegEx Cheat Sheet
- Pipe (|)
- Backslash (\)
- Caret (^)
- Semnul dolar ($)
- Dot (.)
- Asterisc (*)
- Combinația punct-asterisc (.*)
- Semnul plus (+)
- Semnul de întrebare (?)
- Parentheses ()
- Corele pătrate ()
- Dashes (-)
- Curly brackets ({ })
- Google Analytics RegEx: Exemple specifice pe care le puteți utiliza
- Google Analytics RegEx Tips & Greșeli de evitat
- În afara de Google Analytics: RegEx pentru alte utilizări de marketing
- Concluzie
Google Analytics RegEx: Ce este?
Expresiile regulate sunt șiruri de caractere speciale de text pentru descrierea tiparelor de căutare.
Huh?
În legătură cu analizele, expresiile regulate vă ajută să găsiți, să definiți și să extrageți lucruri. Chiar mai specific, cu Google Analytics, acestea vă pot ajuta să creați definiții mai flexibile pentru lucruri precum filtre de vizualizare, obiective, segmente, audiențe, grupuri de conținut și grupări de canale.
În principiu, acestea sunt caractere predefinite sau o serie de caractere care se potrivesc în mod larg sau restrâns și selectează modele în datele dvs. de analiză digitală. Sunt un instrument general care poate fi utilizat în multe moduri (tone de limbaje și instrumente de programare permit regex). Dar în Analytics, le vom folosi în principal pentru a potrivi tipare în date.
Nu este util doar în Analytics, bineînțeles. În special, dacă sunteți un utilizator Google Tag Manager sau dacă executați o targetare complicată pe testele A/B, veți folosi o mulțime de regex. După cum spune Chris Mercer, fondatorul MeasurementMarketing.io:
„Noi folosim regex zilnic. Ne ajută să definim în mod clar totul, de la pașii de pâlnie într-un obiectiv Google Analytics, până la un declanșator specific în Google Tag Manager.”
Cu toate acestea, dacă doriți să faceți o scufundare profundă și să învățați cu adevărat expresiile regulate, iată câteva resurse (nu sunt necesare pentru chestii de bază în Google Analytics și, probabil, pentru cineva cu mai multă pricepere tehnică):
- Regular Expressions: The Complete Tutorial
- Mastering Regular Expressions 3rd Edition (Book)
- Learn Regular Expressions the Hard Way
De asemenea, puteți învăța în mod interactiv prin intermediul a ceva precum RegexOne sau RegexR, ambele fiind interesante. Dar haideți să trecem peste asta și să trecem în revistă cele mai frecvent utilizate caractere regex din Google Analytics, astfel încât să puteți începe să le puneți în aplicare.
Google Analytics RegEx Cheat Sheet
Considerați următoarele caractere regex din Google Analytics ca un fel de foaie de trișat – probabil că nu le veți folosi imediat, dar o scurtă trecere în revistă a ceea ce sunteți capabil să faceți cu regex vă va permite să căutați răspunsul atunci când este necesar.
Pentru un scurt rezumat, nu am găsit nimic mai condensat și mai la obiect decât acest ghid:

Un ghid foarte scurt pentru Google Analytics regex – sursa imaginii
Cu toate acestea, puteți vedea că, doar cu asta ca referință, este un pic vag și ambiguu. Așa că haideți să trecem în revistă cele mai des folosite regex-uri Google Analytics, arătând în același timp cazurile de utilizare corespunzătoare.
Pipe (|)
Când vreți să spuneți „OR” trebuie să folosiți o pipă (|). Ca în „This | That”, care ar însemna „This OR That”.
Dacă sunteți un utilizator avid al segmentelor Google Analytics, sunteți deja obișnuit să folosiți operatorii logici OR.
Aceasta este una dintre cele mai simple și mai comune expresii regulate utilizate în Google Analytics. Are multe aplicații, deși una dintre cele mai utilizate ar putea fi la configurarea obiectivelor. Dacă aveți două pagini de mulțumire cu URL-uri distincte (/thank-you/ și /subscription-confirmed/), dar doriți să le urmăriți pe amândouă ca finalizare a unui obiectiv, puteți utiliza această expresie regulată.
De asemenea, o puteți utiliza în filtre. Să presupunem că doriți să vizualizați un raport de comportament pentru două articole (despre Lecții de marketing de conținut și Analize de conținut), cu URL-urile /content-marketing-analytics/ și /content-marketing-lessons/. Ați putea scrie, ca filtru, „content-marketing-analytics|content-marketing-lessons” și ați putea obține doar aceste articole.
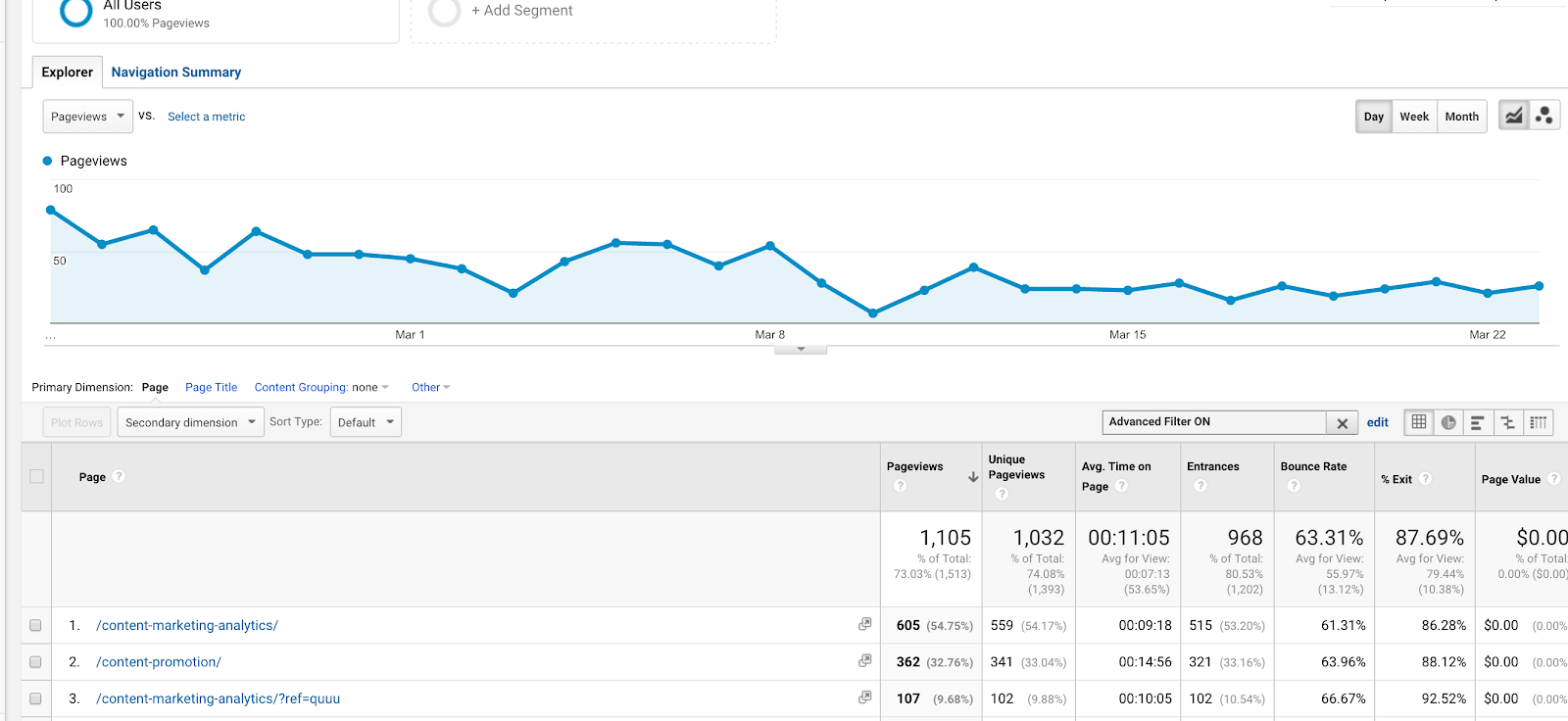
Utilizarea unei țevi (|) într-un filtru pentru a obține rezultate pentru două articole de blog separate
Backslash (\)
Backslash (\) este o altă expresie regulată directă și frecvent utilizată în Google Analytics. Aceasta înseamnă „considerați următorul caracter ca fiind text simplu, și nu regex.”
Cu alte cuvinte, există multe expresii regulate care apar în text simplu, cum ar fi punctul, semnul de întrebare și altele, pe care trebuie să clarificăm dacă trebuie citite ca expresii regulate sau ca text simplu.
Un șir de interogare obișnuit online este utilizat atunci când cineva caută ceva pe site-ul dvs. De exemplu, atunci când caut „jucării mici pentru câini” pe petsmart.com, acesta este șirul de interogare care apare:
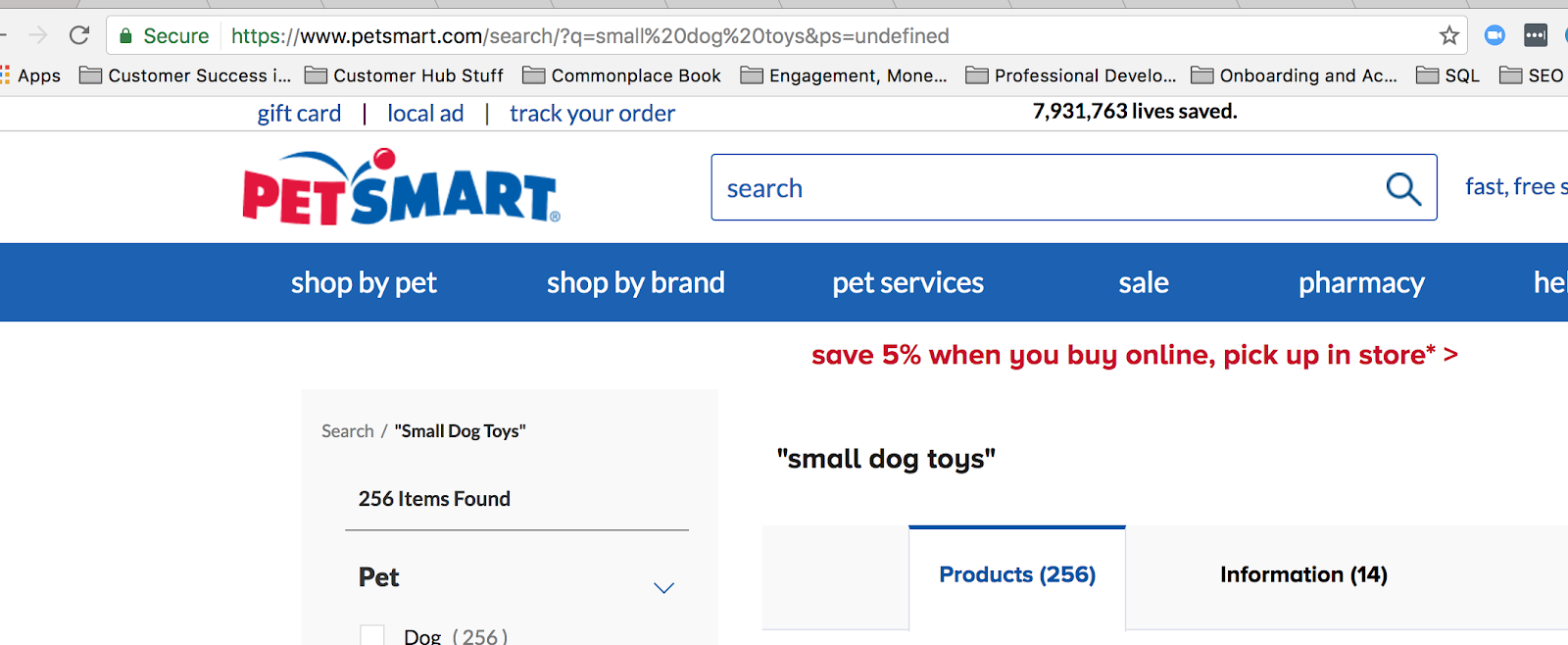
Când utilizați căutarea pe site, creați un șir de interogare în URL.
Semnul de întrebare de aici semnifică faptul că a avut loc o căutare pe site, dar semnul de întrebare este, de asemenea, o expresie regulată utilizată în mod obișnuit în Google Analytics. Prin urmare, trebuie să clarificăm atunci când folosim o backslash, că, în acest caz, semnul întrebării trebuie citit ca text simplu.
Să spunem că dorim să potrivim toate șirurile de interogare din Google Analytics care încep cu /search/?q= (deoarece aceasta semnifică o căutare). Atunci, expresia regulată ar fi:
search\/\?q=
Puteți verifica acest lucru cu ajutorul unui depanator precum regex101.com:
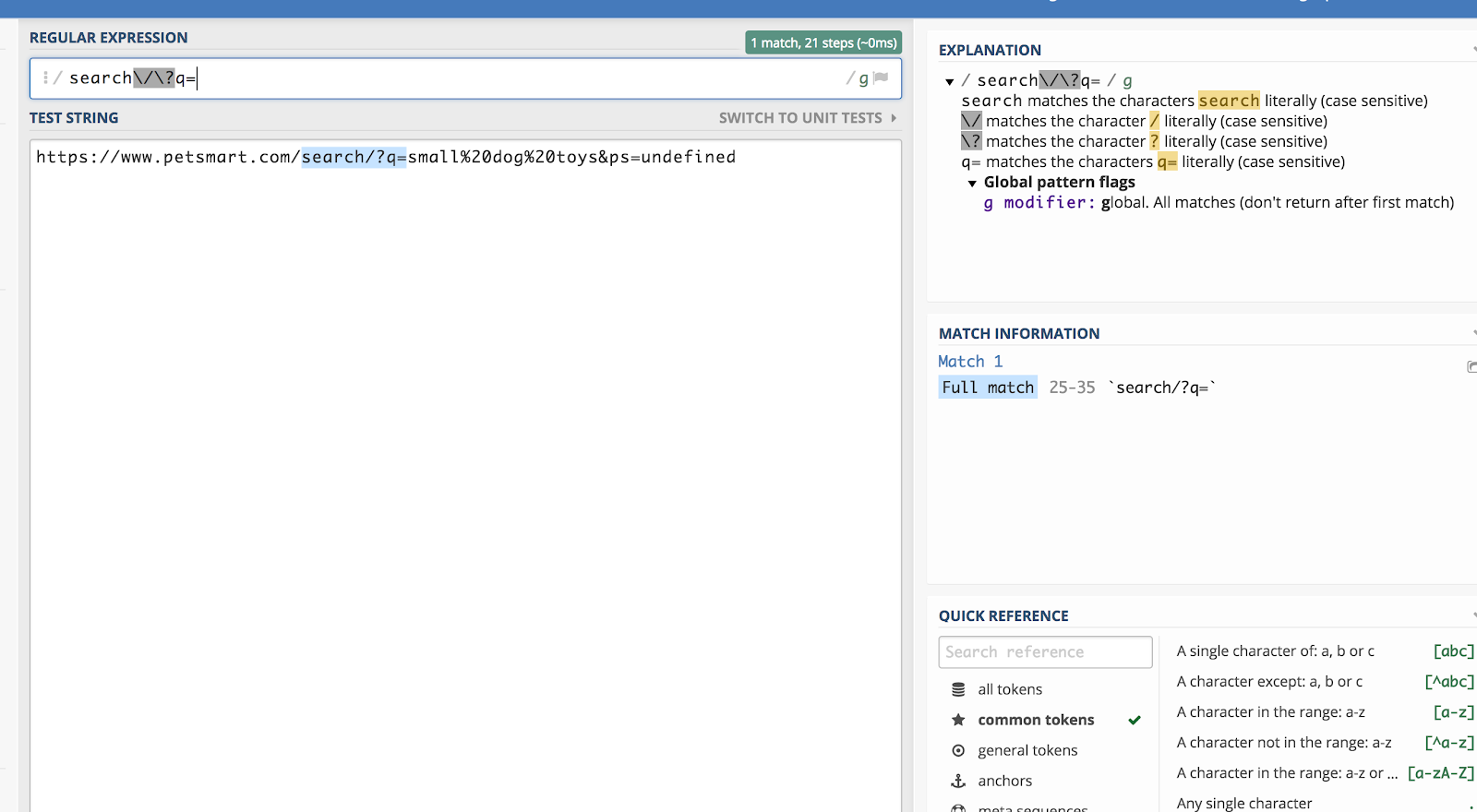
Straba inversă (\) „evadează” din regex pentru un caracter după aceea și o citește ca text simplu.
Caret (^)
Caret (^) înseamnă că o frază începe cu ceva. Acest lucru este important atunci când aveți o frază care ar putea apărea oriunde, dar doriți să potriviți în mod specific fraza la punctul de început. De exemplu, aruncați o privire la acest exemplu de câteva fraze diferite care includ cuvintele „Misiune: reușită.”
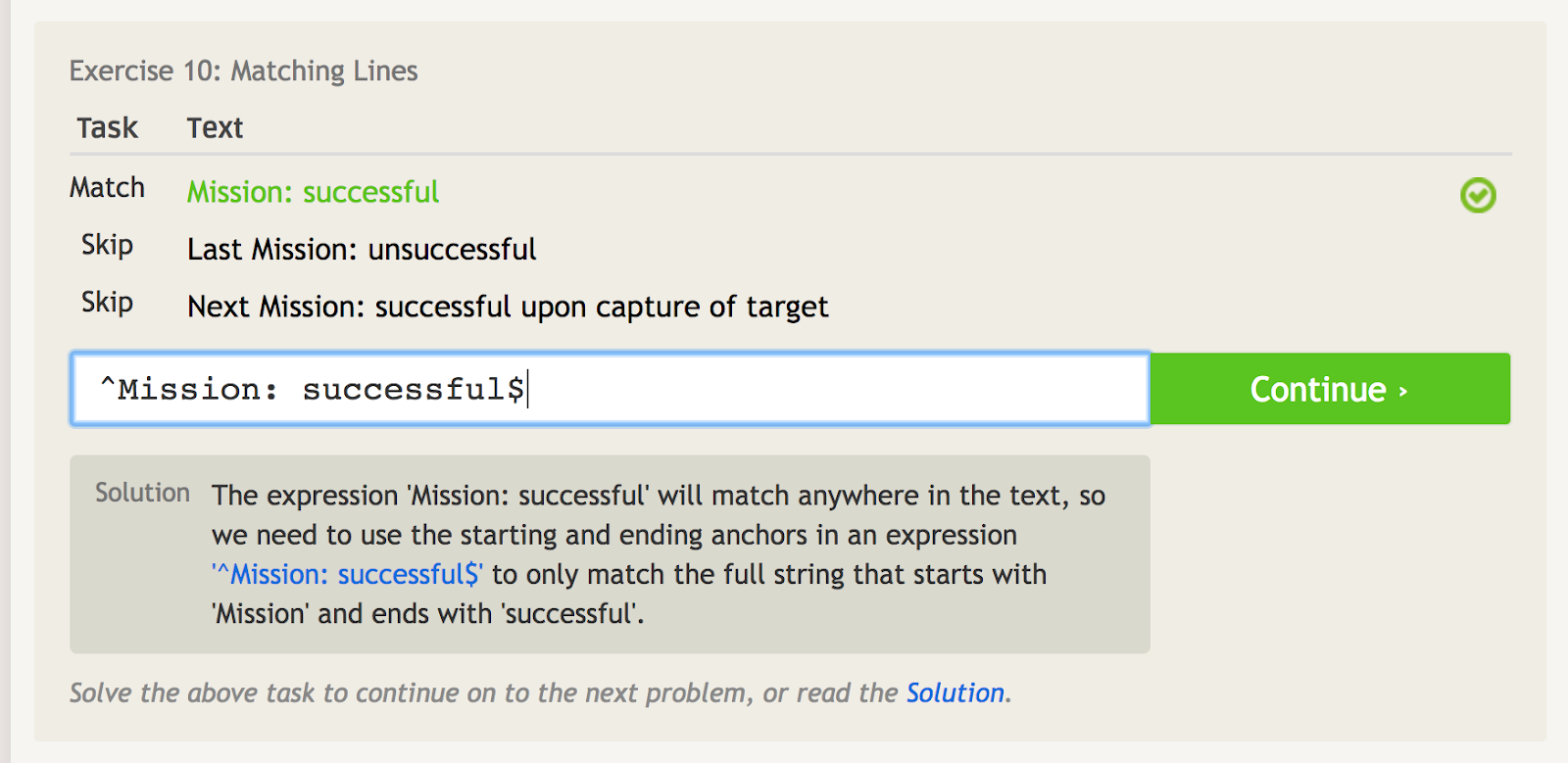
Careta semnalează ancora de început, astfel încât putem potrivi numai prima frază de aici.
Să spunem că aveți o grămadă de campanii AdWords care încep toate cu aceeași frază (pentru că sunteți un planificator prost pentru viitor):
- Freemium Campaign Final
- Prima noastră campanie Freemium
- Ofertă creativă de campanie Freemium
- Test Freemium Campaign
Ați vrea să scrieți ^Freemium Campaign pentru a se potrivi cu prima campanie și cu niciuna dintre celelalte.
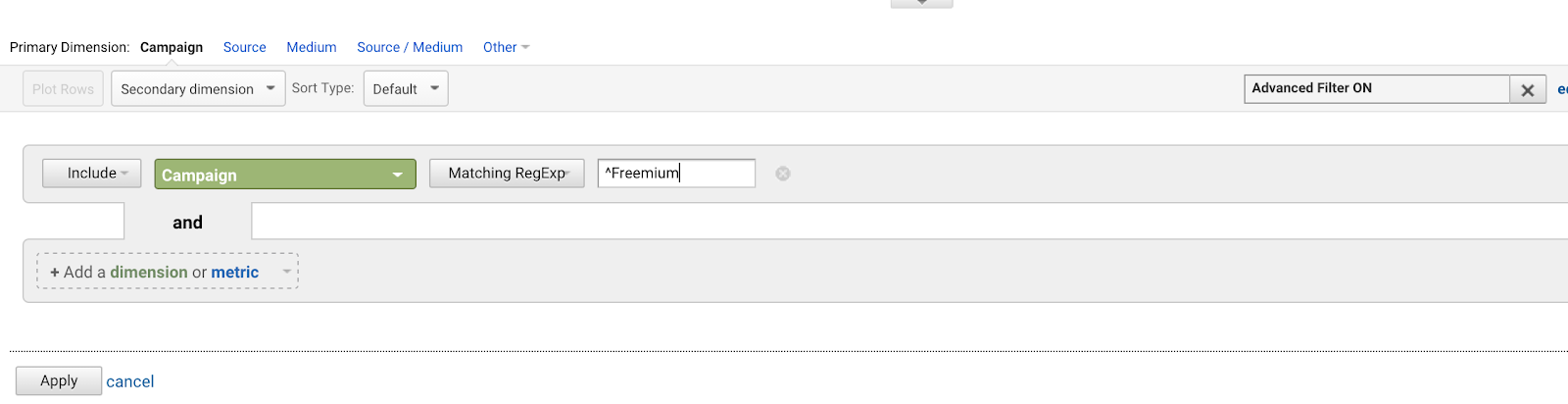
Utilizarea caretului (^) se potrivește cu șirurile de caractere care încep cu aceste caractere
Semnul dolar ($)
Semnul dolar ($) înseamnă că o frază se termină cu ceva.
Când le combinați pe cele două, puteți viza frazele cu potrivire exactă.
Dacă ați lansat o campanie intitulată „paidacquisitionfb” și mai târziu ați lansat una intitulată „paidacquisitionfb-2” pentru că nu v-ați planificat bine și credeți că veți avea alte campanii cu titluri similare (se întâmplă tot timpul), ați putea să o izolați pe prima scriind:
^paidacquisitionfb$
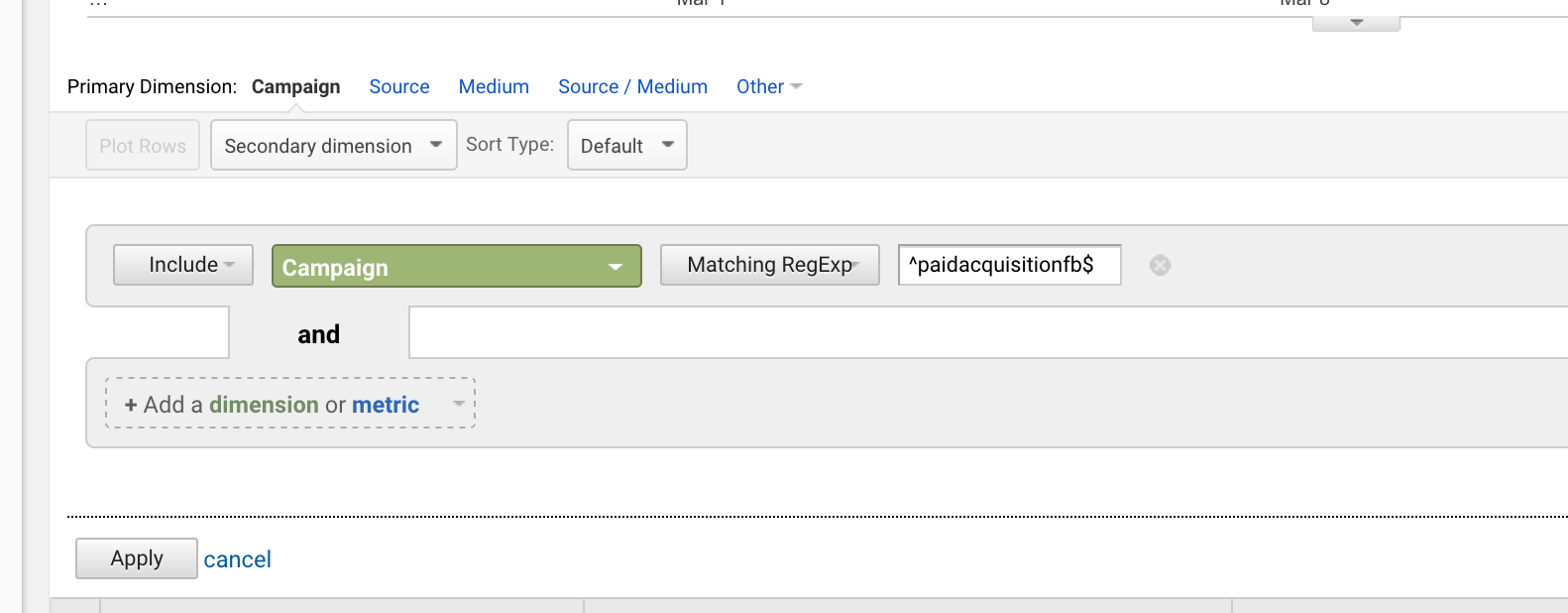
Utilizarea caretului și a dolarului împreună este foarte frecventă.
Dacă aveți tone de pagini de categorie pe blogul dvs., de exemplu, și toate se termină cu un număr de pagină, puteți scrie o bucată simplă de regex Google Analytics pentru a vizualiza doar paginile de categorie ale blogului (^/page/*/$). Acest lucru v-ar da liste de genul:
- /pagina/1
- /pagina/2
- /pagina/3
…și așa mai departe.
Dot (.)
Un punct (.) se potrivește cu orice caracter, ceea ce înseamnă orice puteți găsi pe tastatură: numere, litere, chiar și spații albe. Nu este super util de unul singur, dar este folosit tot timpul împreună cu alte expresii regulate, în special cu asteriscul (care urmează).
Să spunem că vreți să-l folosiți de unul singur, și să folosim exemplul „ki…” Acesta s-ar potrivi cu orice începe cu literele K și I, și apoi cu următoarele două caractere, oricare ar fi ele.
Așa că dacă ați avea un șir care include cuvintele kill, kind, kiss, kin, kid! și kit, s-ar potrivi cu toate acestea. Stai, ce? Da, s-ar potrivi cu „kit” și „kin” atâta timp cât există un spațiu după (preia și spațiile albe). Urmând această logică, ar prelua și semnul exclamării din „kid!”
Vă puteți da seama de ce lucrurile se încurcă dacă îl folosiți doar pe acesta.
Iată o ilustrare a exemplului de mai sus folosind Regex101.com:
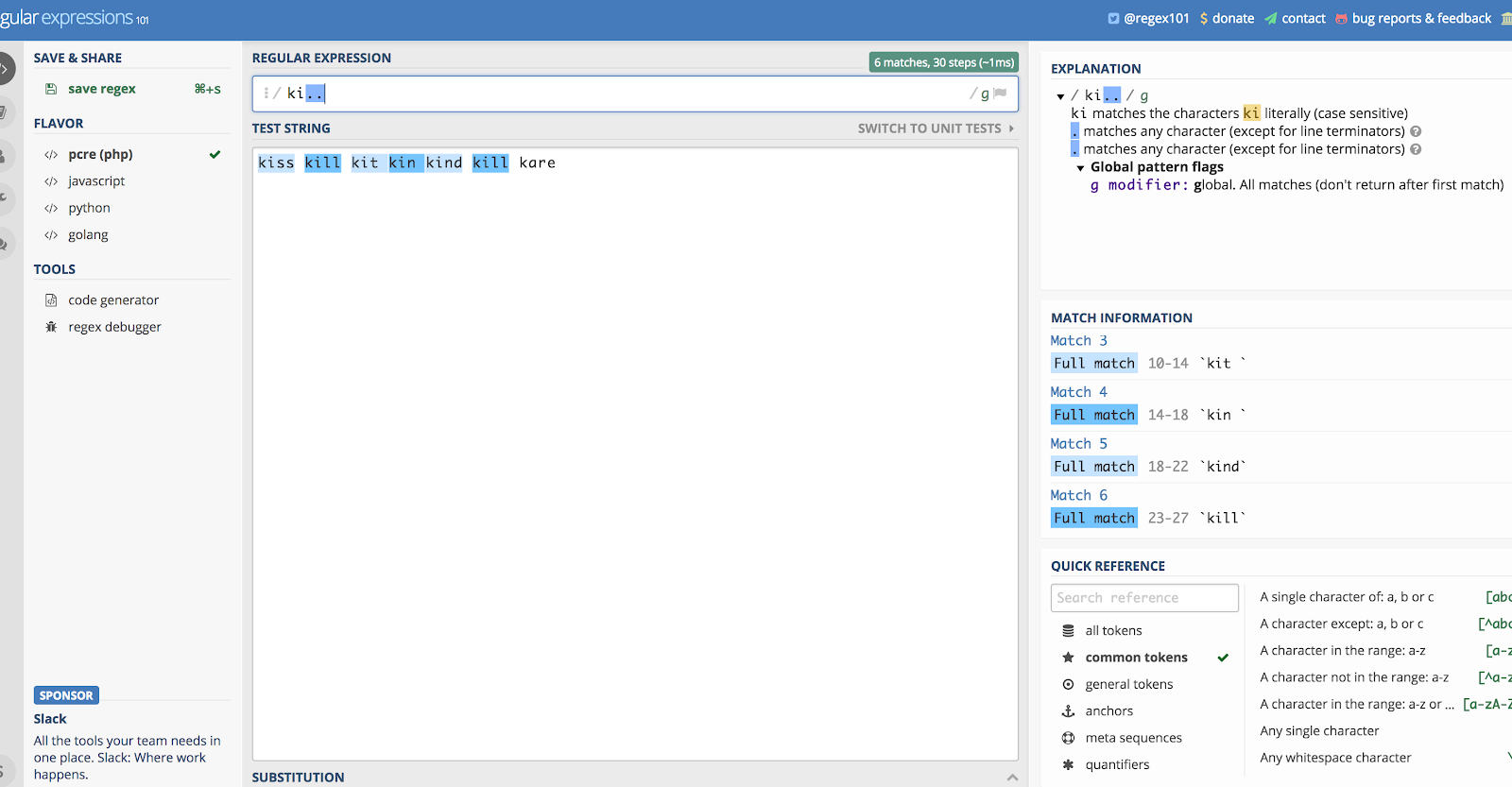
Punctul (.) se potrivește cu aproape orice.
Asterisc (*)
Asteriscul (*) se potrivește cu zero sau mai multe dintre elementele anterioare. E cam confuz când o spui așa, așa că voi folosi doar un exemplu.
Îți amintești reclama aceea „wazzup” de la Budweiser de acum ceva timp? Ar fi destul de dificil să ghicești cum ar scrie cineva acea frază dacă ar căuta-o (să zicem, pe YouTube). Dar, teoretic, ați putea încapsula toate variantele de ortografie făcând acest lucru:
waz*up
Iată o ilustrare a modului în care funcționează acest lucru în regex101:
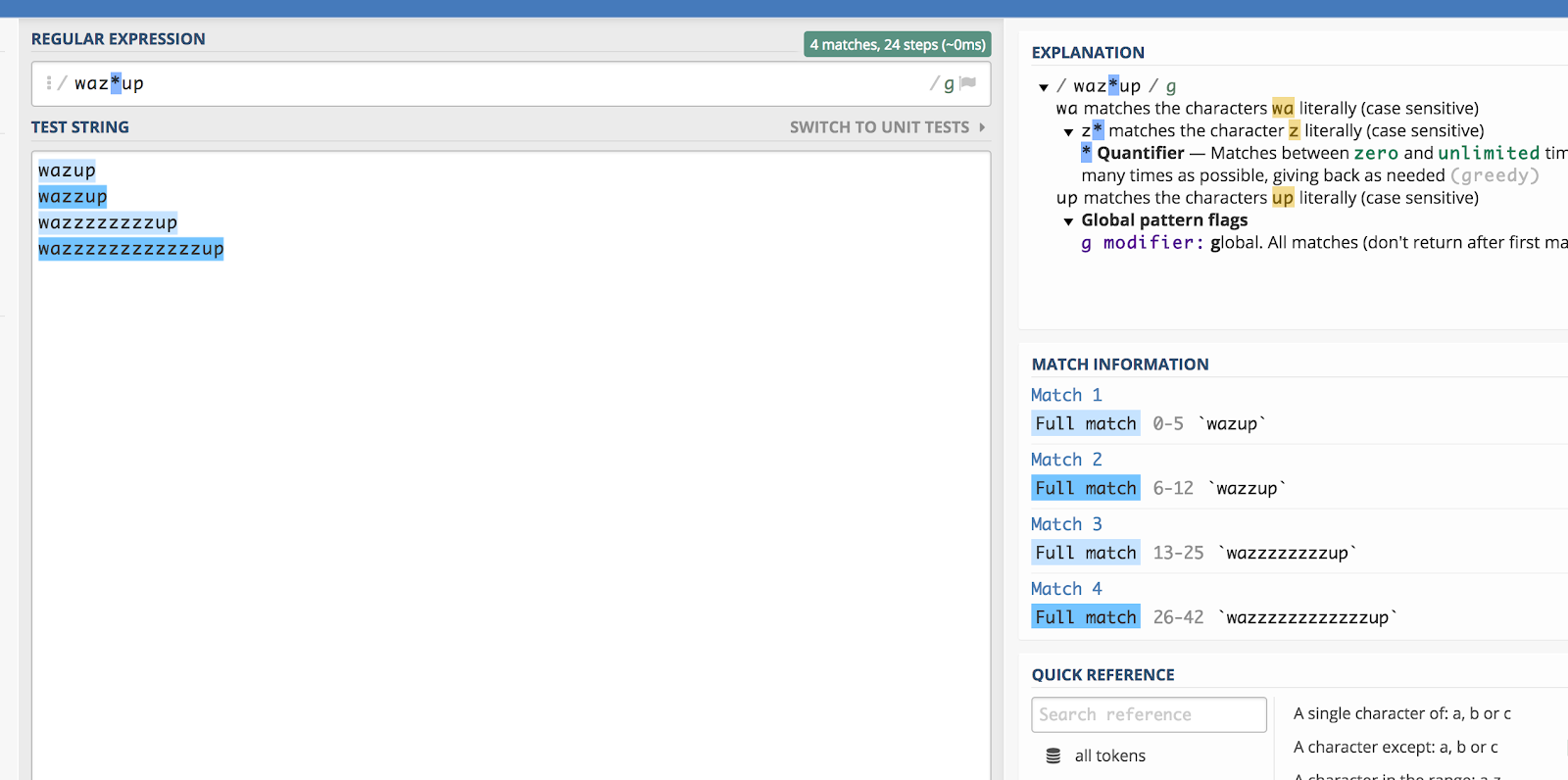
Asteriscul (*) se potrivește cu caracterul anterior de zero sau mai multe ori.
Dacă vreți să fiți super-precis și să țineți cont de caracterele majuscule și minuscule, puteți scrie ceva de genul acesta:
*
Dar divaghez.
Unde asterisc este de fapt cel mai puternic și mai frecvent utilizat este cu un punct sau ca parte a altor combinații regex.
Combinația punct-asterisc (.*)
Combinația punct-asterisc (.*) înseamnă practic că totul este permis. Este foarte des folosită.
Ai folosi această combinație atunci când vrei să potrivești orice într-un șir de caractere. Deoarece punctul înseamnă că se potrivește cu orice caracter, iar * înseamnă că se potrivește cu zero sau mai multe caractere înainte de el, această combinație este foarte puternică.
Exemplu: aveți mai multe tipuri diferite de conturi de clienți, dar ați dori să vedeți datele pentru toate acestea. Toate au pagini similare, astfel încât paginile dvs. să arate cam așa:
/client/pro/login/
/client/free/login/
/client/starter/login/
Puteți scrie următoarea expresie regex pentru a face acest lucru:
/client/.*/login
Utilizez în mod obișnuit această expresie regex de la Google Analytics pentru a configura segmente pentru utilizatorii cu un ID de utilizator.
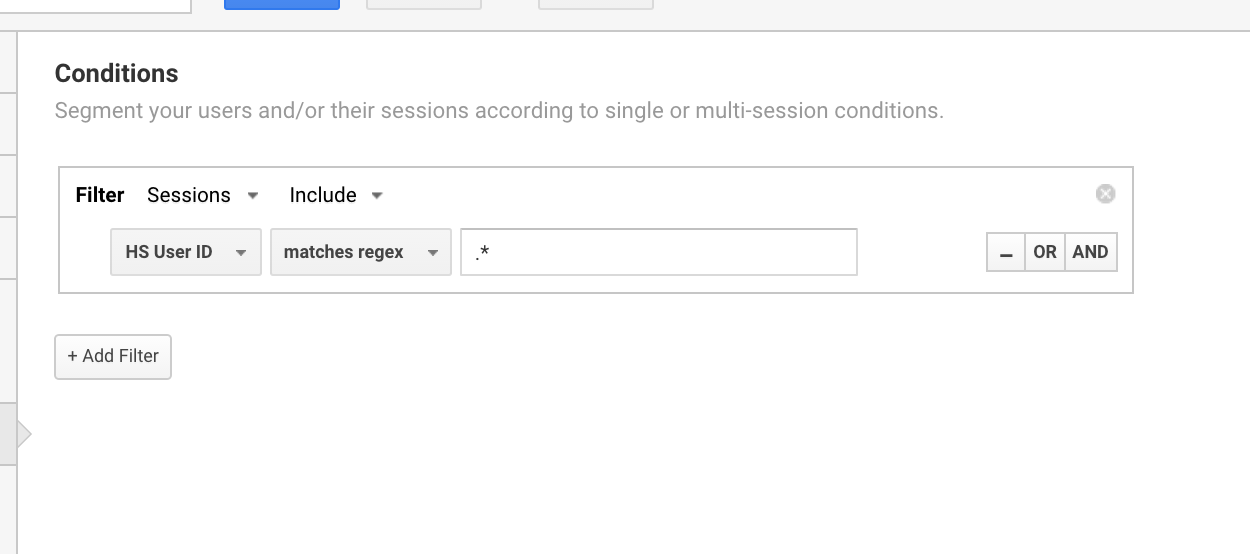
Utilizarea regexului Google Analytics pentru a izola toate sesiunile care au un ID de utilizator.
Semnul plus (+)
Semnul plus (+) este foarte asemănător cu *, cu excepția faptului că se potrivește cu UNUL sau mai multe dintre caracterele anterioare. Nu mai sunt multe de spus în legătură cu acesta, doar că este foarte puțin diferit de asterisc. Iată care este diferența:
Imaginați-vă că aveți cuvintele: bună ziua, bună ziua și bună ziua.
Dacă scrieți bună ziua+bună ziua, se va potrivi doar cu cele două, dar dacă scrieți bună ziua*bună ziua, se va potrivi cu toate cuvintele.
Distincție minoră. În realitate, aproape întotdeauna folosesc asteriscul în loc de semnul plus.
Semnul de întrebare (?)
Semnul de întrebare (?) este unul ușor. Înseamnă pur și simplu că ultimul caracter este opțiune.
Spuneți că nu vă pasă prea mult dacă cuvântul este la plural sau nu (ca în cazul pantofilor). Poate fi „pantof” sau „pantofi” și vreți să îl capturați oricum. Atunci, puteți scrie „shoes?”
Iată un exemplu folosind numele meu. Dacă cineva l-ar scrie „Alex Birket” în timpul unei căutări pe site, probabil că aș vrea totuși să văd asta. Așa că pot scrie:
Alex Birkett?
Iată cum arată în regex101.com:
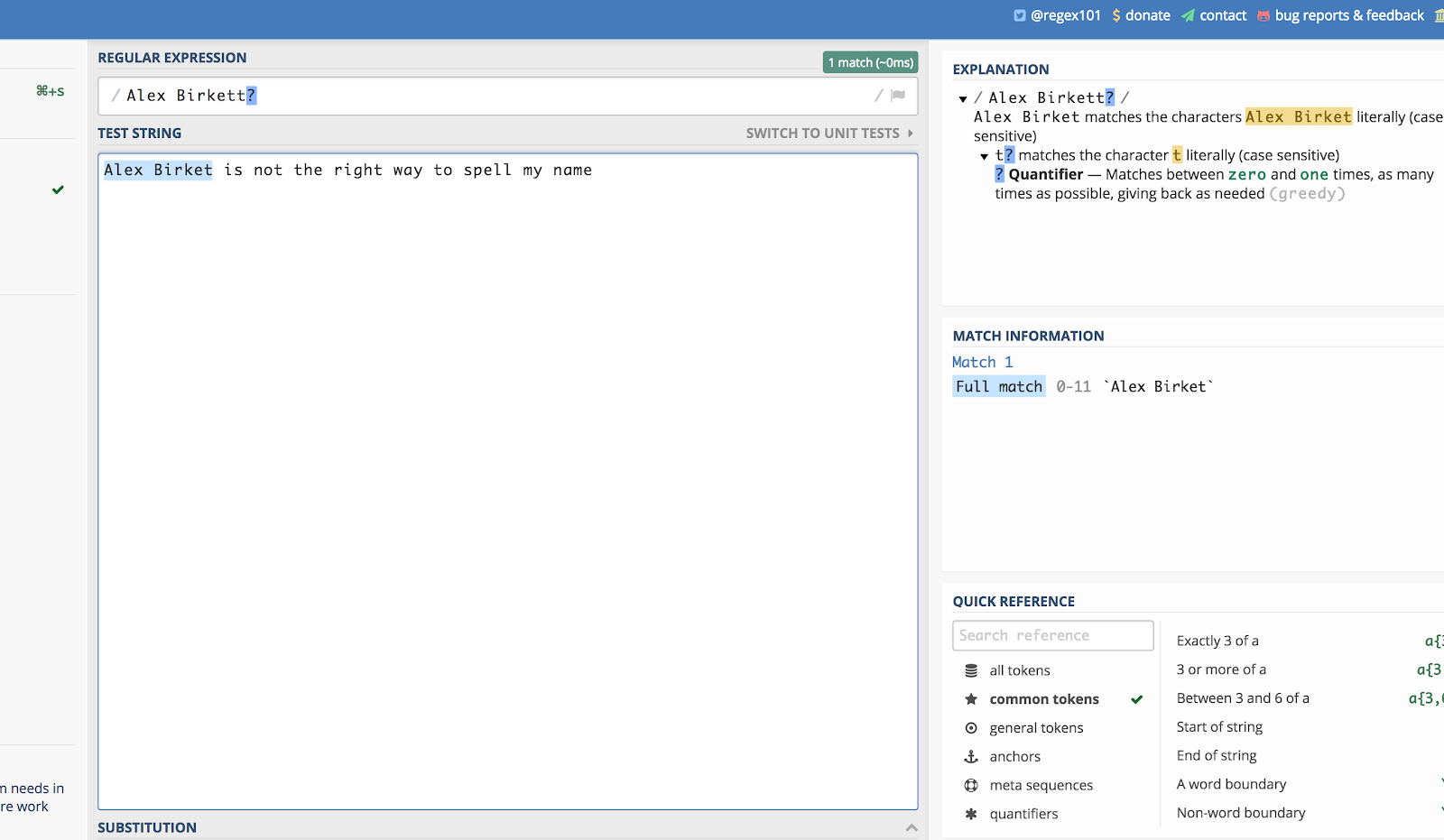
Semnul de întrebare (?) face ca ultimul caracter care îl precede să fie opțional.
Parentheses ()
Parentheses funcționează la fel ca în matematică. Ele vă spun să prioritizați și să izolați logica care este în joc în interiorul lor.
Să spunem că aveți o companie SaaS cu trei oferte și doriți să potriviți toate paginile de prețuri. URL-urile dvs. sunt următoarele:
site.com/products/meetings/pricing
site.com/products/crm/pricing
site.com/products/crm/pricing
site.com/products/products/email/pricing
Pentru a le prinde pe toate cele trei, ați putea folosi o expresie regulată ca aceasta:
^/products/(meetings|crm|email)/pricing$
Corele pătrate ()
Corele pătrate () creează o listă. Dacă aveți trei șiruri de caractere, „lucru1″, lucru 2” și „lucru3”, le puteți potrivi pe toate scriind „lucru” sau „lucru” (mai multe despre liniuțe în curând – acestea sunt utilizate în mod obișnuit cu parantezele pătrate.
Parantezele pătrate pot fi utilizate pentru a potrivi mai multe iterații ale unui cuvânt sau șir de caractere, excluzând în același timp și alte câteva iterații. De exemplu, dacă doriți să vă potriviți cu „can”, „man” și „fan”, dar nu și cu „dan”, „ran” sau „pan”, ați putea folosi următorul regex pentru a face acest lucru:
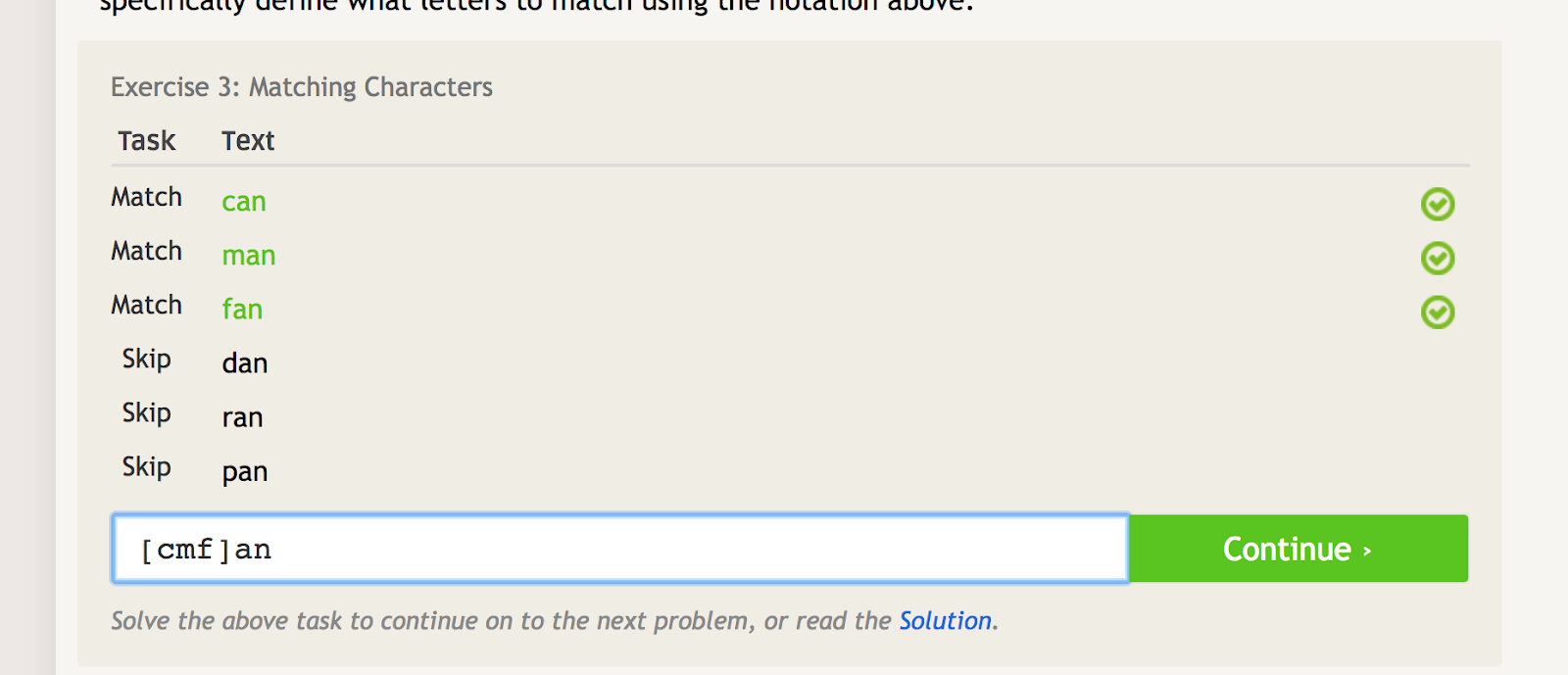
Cuvintele pătrate creează mai multe condiții de potrivire în funcție de caracterele pe care le puneți în interiorul lor. – sursa imaginii
Aceasta este ceva ce puteți folosi dacă aveți câteva produse diferite cu nume similare, cum ar fi „pantofi1″, pantofi3” și „pantofi5”. Ați putea să le potriviți pe acestea, și nimic altceva, folosind „pantofi”
Dashes (-)
Dashes (-) funcționează pentru a crea liste liniare de elemente.
Ca și în cazul în care folosiți paranteze pătrate, nu trebuie să enumerați pur și simplu totul dacă apare liniar. Așadar, dacă ați dori să potriviți un șir de numere în care ultimul ar putea fi orice de la zero la nouă, ați putea scrie așa:
1234
Sau ați putea scrie mult mai simplu:
1234
Acest lucru funcționează și pentru litere. Să ne imaginăm că aveți o categorie de pagină care se termină cu două litere la întâmplare. Ceva de genul:
/page-aa/
Puteți să le potriviți pe toate acestea scriind:
/page-*/
Puteți vedea un exemplu în acest sens pe regex101 aici:
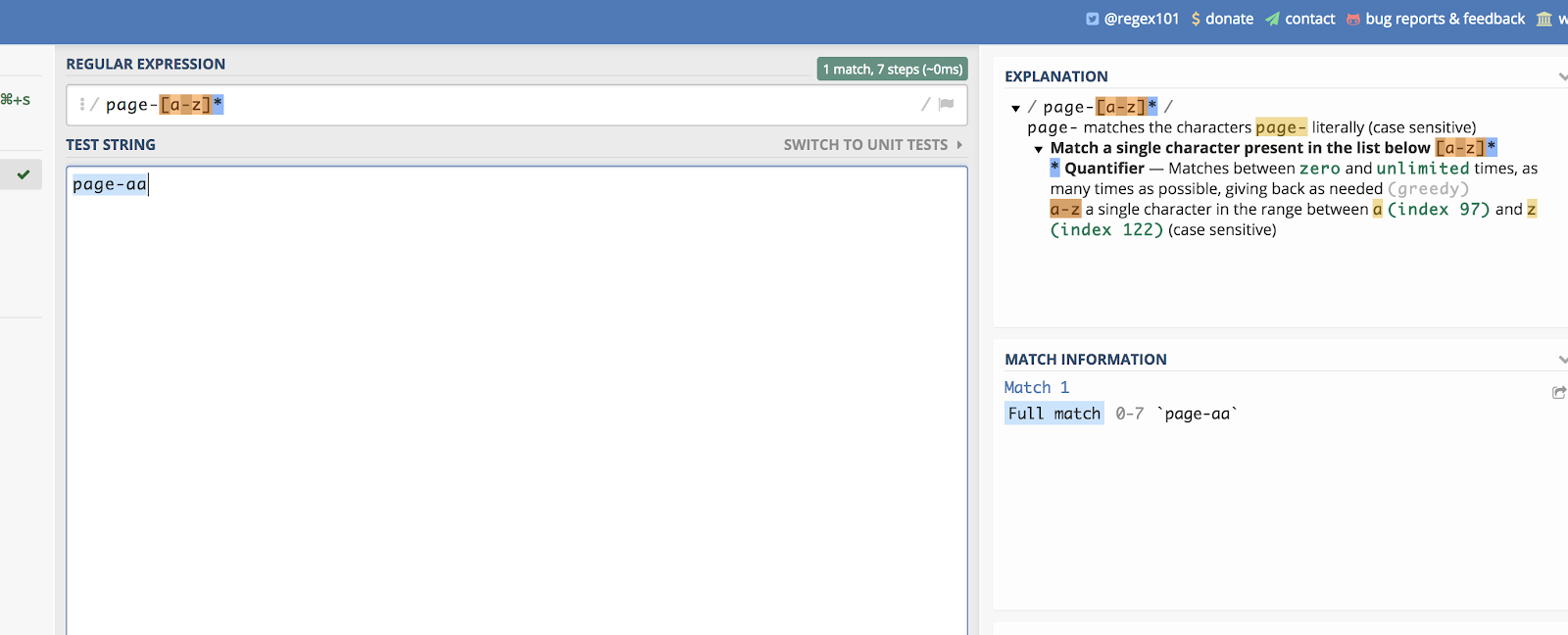
Dashes help you create a linear list to match.
Curly brackets ({ })
Curly brackets ({}) vă spun de câte ori să repetați ultimul element.
De exemplu, dacă doriți să potriviți doar „wazzzzup”, ați putea folosi „waz{4}up”.
Dar dacă doriți să potriviți „wazzzzzup” și „wazzzup”, dar nu și „wazup”, ați putea folosi „waz{3,5}up”. Acest lucru spune practic să se potrivească cu caracterul „z” de cel puțin 3 ori, dar nu mai mult de 5 ori.
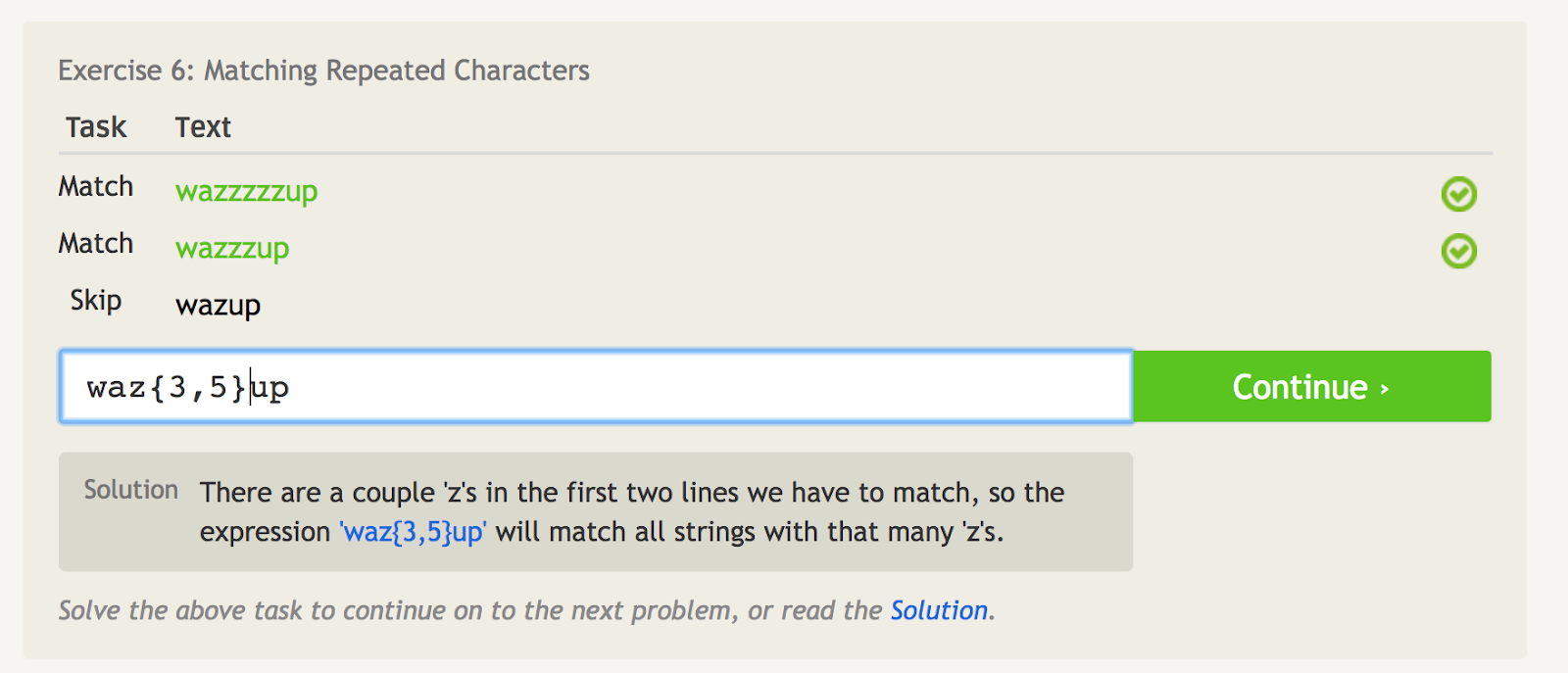
Curly brackets tell you how many times to repeat the last item. – sursa imaginii
Nu am folosit foarte mult această expresie regulată în Google Analytics, dar un caz comun de utilizare ar putea fi pentru codurile poștale. De obicei, primele două caractere sunt aceleași într-un oraș (78- pentru Austin, TX, de exemplu). Așadar, ați putea potrivi orice cod poștal din Austin, TX scriind:
78{3}
Aceasta spune că ultimele trei litere pot fi orice număr aleatoriu de la zero la nouă.
Google Analytics RegEx: Exemple specifice pe care le puteți utiliza
Unul dintre cele mai comune cazuri de utilizare a regex-ului Google Analytics este construirea de filtre. Să trecem în revistă trei exemple, unul simplu și unul puțin mai complicat.
Primul, un exemplu inspirat de o postare grozavă pe Search Engine Land de Jenny Halasz.
Să spunem că aveți o arhitectură de site încurcată, dar doriți să vă uitați la toate postările cu o anumită subdirectorie. Ar putea fi orice, să zicem o categorie a site-ului sau un tip de conținut. În acest exemplu, căutăm o categorie pe site pentru /music/, dar numai în al treilea subdirector. În acest caz, puteți scrie ^/.*/.*/.*/music/.* și vă va oferi acel raport.

Acest regex Google Analytics vă va arăta doar /music/ în cel de-al treilea subdirectorat. – sursa imaginii
Apare confuz la prima vedere – dar după ce înveți ce înseamnă aceste expresii regulate, este destul de simplu. Practic, doar îi spunem lui GA să potrivească pagina de destinație care începe cu (^) o bară oblică, apoi orice caractere (.*), apoi o bară oblică, apoi orice caractere (.*), apoi o bară oblică și apoi muzică.
LawnStarter folosește o tactică similară pentru raportare. Strategia lor este de a crea conținut specific orașului pe un subfolder al paginilor lor de oraș, folosind următorul format:
https://www.lawnstarter.com/{{{ pagina tranzacțională a orașului }}}/{{{ bucată de conținut informațional }}
Pentru a filtra conținutul din pâlcurile de conversie și raportarea traficului, ei folosesc următorul regex, potrivit fondatorului Ryan Farley.
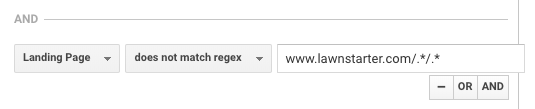
Acest regex ajută LawnStarter să se potrivească cu conținutul specific orașului de pe site-ul lor.
În al doilea rând, să trecem în revistă modul de configurare a unui filtru pentru una dintre vizualizările Google Analytics. Este probabil că veți avea un specialist în implementare care să facă acest lucru – dar dacă nu, aici întotdeauna măsurați de două ori și tăiați o dată. Este ușor să stricați aceste lucruri (care este, de asemenea, motivul pentru care ar trebui să vă configurați contul Google Analytics cu o vizualizare sandbox pentru a încerca lucrurile mai întâi).
Pentru a configura filtre, mergeți la Admin > Filtre > Adăugați filtru.
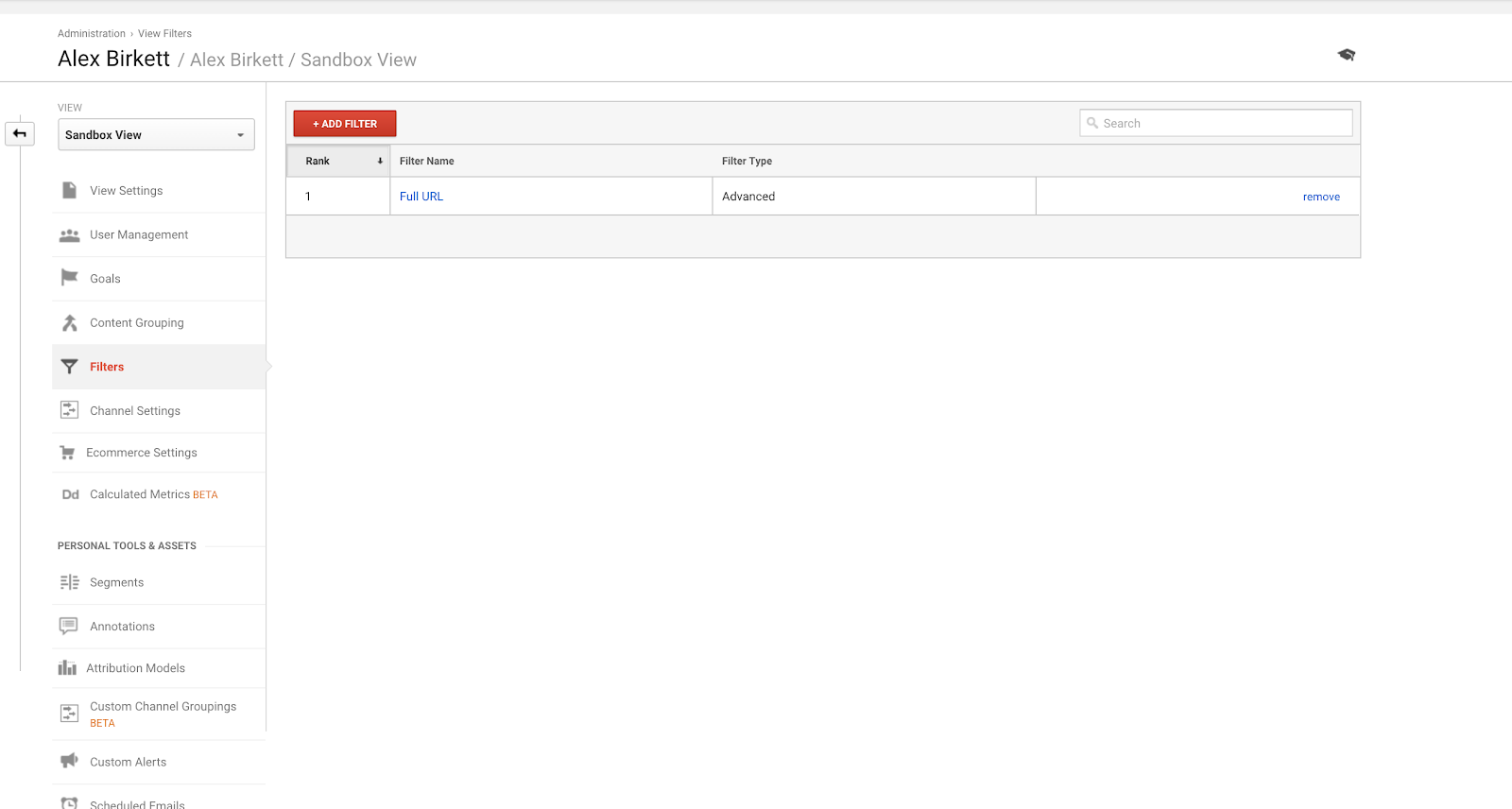
Filtrul cel mai frecvent utilizat în Google Analytics este probabil acela de a exclude traficul de la propria (propriile) adresă (adrese) IP.
Pentru mulți, puteți configura acest lucru simplu, deoarece aveți doar un singur IP. Pentru companiile mai mari, este posibil să aveți o serie de IP-uri și puteți configura mai ușor excluderile cu Google Analytics regex.
De exemplu, dacă ați scris 63\.212\.171\., aceasta ar exclude toate adresele IP de la 63.212.171.1 la 63.212.171.9.
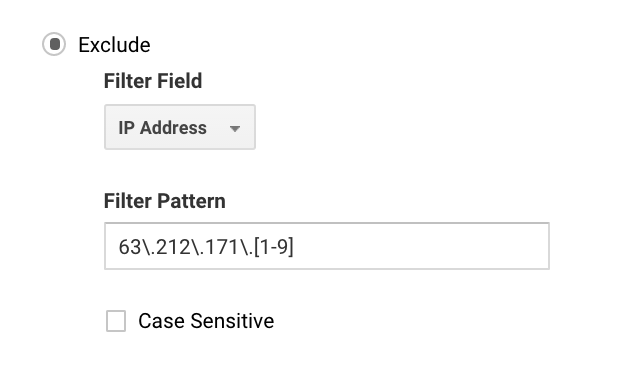
Acest regex Google Analytics exclude mai multe adrese IP.
Un alt lucru pe care îl puteți face cu regex-ul Google Analytics este să configurați filtre pentru a curăța parametrii de interogare.
Acest lucru poate fi atât enervant, cât și problematic pentru analiza datelor.
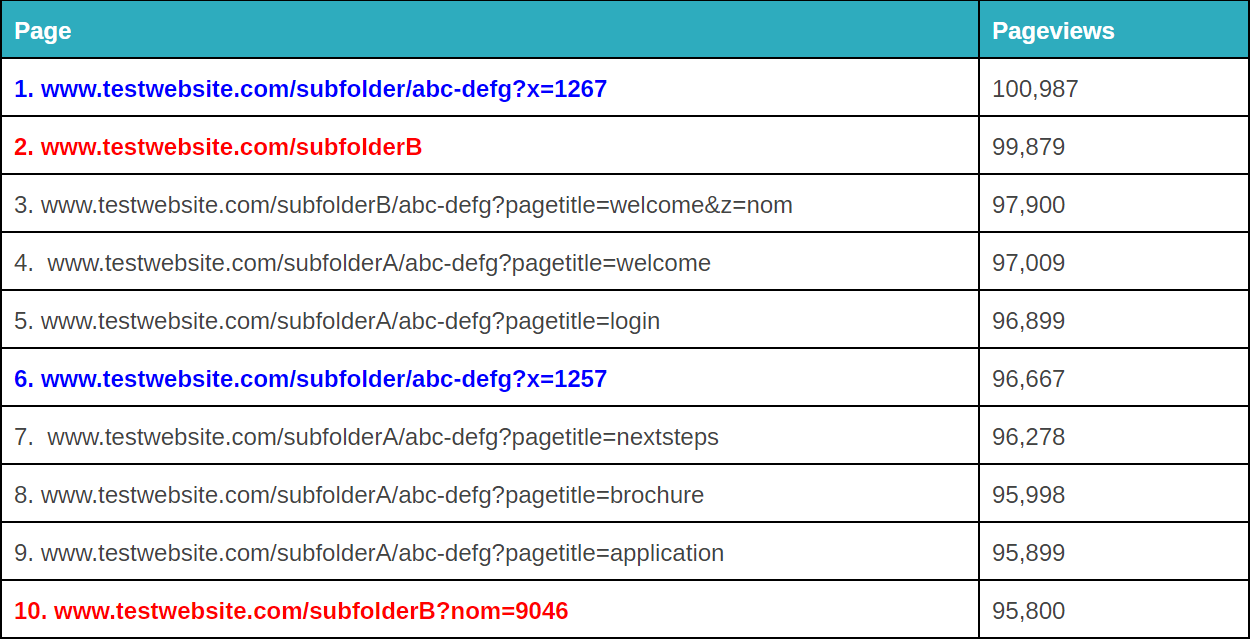
Parametrii de interogare fracturați pot fi enervanți. – sursa imaginii
Depinde de cum este situația dvs. specifică, dar există câteva moduri diferite în care puteți utiliza regex pentru a curăța acest lucru (notă: puteți face acest lucru și în Google Tag Manager sau Excel, în funcție de amploarea problemei. Mai multe despre asta aici).
În cele din urmă, haideți să vorbim despre un exemplu pe care îl putem folosi pentru a ne organiza mai bine urmărirea subdomeniilor. Dacă aveți mai multe domenii sau subdomenii, este posibil să aveți URL-uri duplicate, cu excepția cazului în care configurați un filtru care să preadă numele de gazdă la URi-ul de cerere. Cu alte cuvinte, este posibil să aveți la URL-uri:
- site.com/about
- blog.site.com/about
Acestea reprezintă două pagini diferite (una este o pagină despre compania dvs. și cealaltă este o secțiune despre pentru blogul dvs.). Dar ambele ar fi văzute în Google Analytics ca /about, cu excepția cazului în care configurați următorul filtru (folosind combinația punct-asterisc expresii regulate Google Analytics):
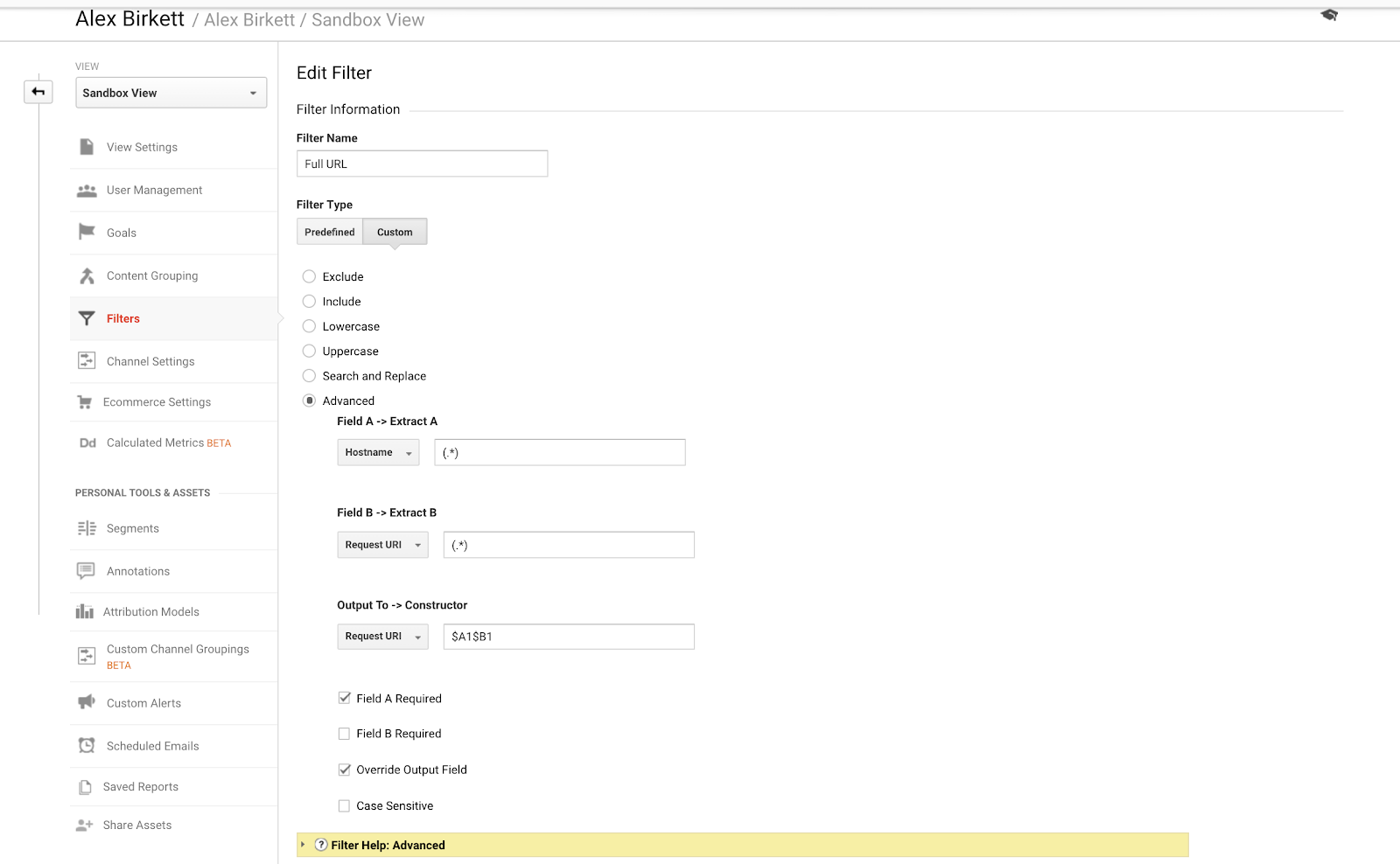
Este destul de simplu să configurați acest lucru acest filtru fundamental GA. – sursa imaginii
De fapt, am acoperit deja cum să configurăm aceste filtre destul de în profunzime într-o postare anterioară KlientBoost despre urmărirea între domenii și subdomenii.
Google Analytics RegEx Tips & Greșeli de evitat
Expresiile regulate sunt unul dintre acele lucruri pe care trebuie doar să le practici și să te murdărești pe mâini pentru a învăța. Ca atare, veți face greșeli.
Acesta este cel mai important sfat, de fapt: încercați lucrurile și vedeți dacă funcționează. Am enumerat o mulțime de resurse în această postare despre cum să vă testați regexul, de la regex101.com la regexbuddy.com. Înmuiați-vă degetele de la picioare și folosiți aceste resurse.
Cu toate acestea, cu ceva previziuni și euristică, puteți învăța mai repede și puteți prinde mai multe greșeli.
Un lucru pe care trebuie să-l învățați cu adevărat este cum să „scăpați” în regex (am vorbit despre acest lucru despre cu backslash). Leho Kraav, CTO la CXL Institute, o spune astfel:
„Aș spune „învățați despre cum să scăpați corect lucrurile” – este ușor să obțineți neconcordanțe atunci când caracterele sunt aceleași, dar semnificația lor este diferită în funcție de faptul că sunt sau nu scăpate.”
De exemplu, dacă interogarea dvs. are un semn de întrebare, acesta este, de asemenea, o expresie regulată, astfel încât trebuie să clarificați acest lucru cu backslash-ul. Chris Mercer, fondatorul MeasurementMarketing.io, spune, de asemenea, că a nu învăța această capacitate este una dintre cele mai mari greșeli pe care vede că le fac începătorii:
„Cea mai frecventă greșeală pe care o vedem la începătorii care folosesc regex este că uită să „scape” simbolurile regex. De exemplu, dacă căutați pagini care se potrivesc cu regex-ul „mulțumesc/?success=yes”, nu va funcționa. Simbolul „?” în sine este un simbol regex și trebuie dezactivat prin utilizarea „caracterului de evadare” (simbolul ” \”. În acest caz, ar funcționa „thankyou/\?success=yes”.”
Un alt sfat? Păstrați-l simplu. Oamenii încearcă să complice lucrurile (consultați cel mai complicat regex pe care l-ați văzut vreodată, scris de Leho, aici), dar expresiile regulate sunt „lacome” și vor potrivi cât de mult pot. Google Analytics a publicat o postare pe blog de sfaturi și a explicat astfel:
„Dacă trebuie să scrieți o expresie pentru a se potrivi cu „vizite noi”, iar singurele opțiuni cu care vă veți potrivi sunt „vizite noi” și „vizite repetate”, doar cuvântul „nou” este suficient de bun.
Se vor potrivi cu tot ceea ce pot, cu excepția cazului în care le forțați să nu o facă. Dacă expresia dvs. este „vizite”, se va potrivi cu „vizite noi” și „vizite repetate”. La urma urmei, ambele au inclus expresia „vizite”. Pentru a le face mai puțin lacome, trebuie să le faceți mai specifice.”
Atunci începeți încet, păstrați lucrurile simple și nu vă copleșiți cu complexitate (șansa de eroare se corelează cu complexitatea în acest caz).
Mercer reiterează, de asemenea, acest punct, sfătuind să luați lucrurile treptat:
„Când începeți, concentrați-vă pe a deveni buni… apoi deveniți mai buni. Este ușor să te lași copleșit de toate posibilitățile diferite pe care ți le oferă regex-ul, dar dacă începi doar cu elementele de bază, cum ar fi stăpânirea simbolului pentru „sau” (simbolul ” | „), dobândești rapid experiență și începi să realizezi ce este posibil cu regex-ul.”
Un ultim sfat din partea mea: învață să cauți lucruri pe Google. Acest lucru este valabil pentru orice programare, dar mai ales pentru expresiile regulate. O să uitați lucruri, iar dacă nu scrieți regex zilnic, nu prea are rost să memorați totul. Învățați să căutați lucruri și să găsiți răspunsuri la ceea ce încercați să faceți.
În afara de Google Analytics: RegEx pentru alte utilizări de marketing
Regexul este, de asemenea, ceva ce toți practicienii SEO ar trebui să analizeze. În primul rând, în mod evident, pentru că SEO și analizele digitale (de exemplu, Google Analytics) sunt inextricabil legate între ele. În al doilea rând, pentru că unele dintre aceleași expresii de potrivire pe care le scriem pentru a filtra și potrivi caracterele din datele noastre Google Analytics pot fi, de asemenea, utilizate în extragerea datelor pentru tacticile SEO.
Cu alte cuvinte, expresiile regulate sunt importante pentru web scraping.
În cazul web scraping-ului și al SEO, veți lucra de obicei prin intermediul unui limbaj de programare precum Python, dar principiile sunt aceleași.
Ca exemplu, ați putea răzui tot textul boldat de pe o pagină folosind acest lucru:
<strong>(+)</strong>
Sau, așa cum se menționează în acest articol din SEJ, dacă se răzuiește ESPN pentru toți autorii, s-ar putea scrie acest lucru:
„columnist”:”(.*?)”
De dragul coeziunii și al sănătății mintale, nu mă voi scufunda până la capăt în răzuirea web avansată. Este suficient să știți că regex-ul este important și în acest domeniu. Cu toate acestea, dacă doriți să aflați mai multe, vă sugerez aceste surse:
- Web Scraping with Regular Expressions
- Scraping with Regular Expressions (Stanford)
- How to Use Regex for SEO & Website Data Extraction
Expresiile regulate vă ajută, de asemenea, să lucrați cu datele SEO, dincolo de simpla răzuire a web-ului. De exemplu, puteți folosi regex pentru a personaliza și mai mult modul în care utilizați Screaming Frog.
Jenny Halasz a dat un bun exemplu de utilizare a regex-ului pentru a curăța datele într-o postare Search Engine Land:
„De exemplu, să spunem că aveți o listă de URL-uri și trebuie să le împărțiți doar în TLD (Top Level Domain).
Puteți folosi o simplă căutare/înlocuire pentru http și www, dar cum puteți elimina cu ușurință toate numele de fișiere? Ați putea să le eliminați pe toate manual, dar asta este o pacoste. Folosind un simplu wildcard regex (/*), puteți renunța la slash și la tot ceea ce vine după el.”
Am putea vorbi la nesfârșit despre expresiile regulate pentru SEO și web scraping, dar voi face doar un link către câteva resurse bune în cazul în care doriți să aflați mai multe (este un limbaj foarte versatil, până la urmă, cu multe cazuri de utilizare dincolo de analiză):
- Cum afectează expresia regulată SEO
- 5 trucuri impresionante și puternice de redirecționare Htaccess
- Cum să folosiți expresia regulată pentru segmentarea rapoartelor
Concluzie
Google Analytics regex este într-adevăr ceva ce fiecare analist ar trebui să știe, chiar dacă nu vă considerați tehnic. Dincolo de asta, cunoașterea unor expresii regulate (sau cel puțin a modului de a căuta răspunsuri și de a le aplica la problemele potrivite) îi poate ajuta și pe specialiștii în marketing în diverse activități.
Să spunem doar că nu este un set de abilități foarte comun, așa că, probabil, veți impresiona unii colegi cu noile dvs. abilități tehnice de marketing.
Așa că vă îndemn, începeți să învățați și, mai important, începeți să exersați folosirea expresiilor regulate. Nu sunt atât de înspăimântătoare.