A Google Analytics regex (azaz a reguláris kifejezések) egy alulértékelt készség.
Ha az alapokon túl bármilyen szűrést vagy célzást szeretnél végezni, a regex jó ismerete szuperhatalmat ad az Analyticsnek.

A regex szuperképességeket ad. – kép forrása
A reguláris kifejezéseknek természetesen sokkal szélesebb körű felhasználási lehetőségei vannak, mint az analitika és a marketing. De e cikk céljaira néhány taktikai felhasználási esettel foglalkozunk, amelyek segíthetnek a felhasználók megismerésében, az adatok rendszerezésében, sőt, a fejlett célzás és a keresőmarketing felhasználási eseteiben is.
De először is, foglaljuk össze röviden, hogy mik azok a reguláris kifejezések, konkrétan a Google Analyticshez kapcsolódóan.
- Google Analytics RegEx: Mi az?
- Google Analytics RegEx Cheat Sheet
- Pip (|)
- Backslash (\)
- Caret (^)
- Dollárjel ($)
- Pont (.)
- Sztárjel (*)
- Pont-csillag kombináció (.*)
- Pluszjel (+)
- Kérdőjel (?)
- Kérdőjelek ()
- A szögletes zárójelek ()
- Keresztjelek (-)
- A szögletes zárójelek ({ })
- Google Analytics RegEx: Konkrét példák, amelyeket használhat
- Google Analytics RegEx tippek & Elkerülendő hibák
- A Google Analyticsen kívül: RegEx for Other Marketing Uses
- Conclusion
Google Analytics RegEx: Mi az?
A reguláris kifejezések speciális szöveges karakterláncok a keresési minták leírására.
Huh?
Az analitikával kapcsolatban a reguláris kifejezések segítenek megtalálni, meghatározni és kivonni dolgokat. Még konkrétabban, a Google Analytics esetében segíthetnek rugalmasabb definíciókat létrehozni olyan dolgokhoz, mint a nézetszűrők, célok, szegmensek, közönségek, tartalomcsoportok és csatornacsoportosítások.
Lényegében előre meghatározott karakterek vagy karaktersorozatok, amelyek tágan vagy szűken illeszkednek és kiválasztanak mintákat a digitális analitikai adatokban. Ezek egy általános eszköz, amely sokféleképpen használható (rengeteg programozási nyelv és eszköz lehetővé teszi a regexet). De az Analyticsben elsősorban az adatokban található minták egyeztetésére fogjuk használni őket.
Természetesen nem csak az Analyticsben hasznos. Különösen, ha Google Tag Manager felhasználó vagy, vagy ha bonyolult célzást futtatsz az A/B tesztjeidben, akkor sok regexet fogsz használni. Ahogy Chris Mercer, a MeasurementMarketing.io alapítója mondja:
“Naponta használjuk a regexet. Segít nekünk egyértelműen meghatározni mindent, a Google Analytics célban lévő tölcsérlépésektől kezdve a Google Tag Managerben lévő specifikus triggerekig.”
Ha azonban mélyebbre szeretne merülni és valóban megtanulni a reguláris kifejezéseket, akkor itt van néhány forrás (nem szükséges a Google Analytics alap dolgaihoz, és valószínűleg valakinek, akinek nagyobb technikai jártassága van):
- Reguláris kifejezések: The Complete Tutorial
- Mastering Regular Expressions 3rd Edition (Book)
- Learn Regular Expressions the Hard Way
Interaktívan is tanulhatsz valami olyasmin keresztül, mint a RegexOne vagy a RegexR, mindkettő klassz. De lépjünk túl ezen, és menjünk végig a leggyakrabban használt Google Analytics regex karaktereken, hogy elkezdhesd ezt használni.
Google Analytics RegEx Cheat Sheet
Nézd a következő Google Analytics regex karaktereket egyfajta puskaként – valószínűleg nem fogod azonnal használni őket, de ha röviden átnézed, mire vagy képes a regexekkel, akkor szükség esetén megkeresheted a választ.
A rövid összefoglalóhoz nem találtam ennél az útmutatónál tömörebbet és lényegre törőbbet:

A very brief guide to Google Analytics regex – image source
Mégis láthatod, hogy önmagában ezzel a hivatkozással kissé homályos és kétértelmű. Menjünk tehát végig a leggyakrabban használt Google Analytics regexeken, miközben bemutatjuk a megfelelő felhasználási eseteket.
Pip (|)
Ha azt szeretnénk mondani, hogy “VAGY”, akkor pipát (|) kell használnunk. Mint a “This | That”, ami azt jelentené, hogy “This OR That”.
Ha Ön a Google Analytics szegmensek lelkes felhasználója, akkor már hozzászokott az OR logikai operátorok használatához.
Ez az egyik legegyszerűbb és leggyakrabban használt reguláris kifejezés a Google Analyticsben. Számos alkalmazása van, bár az egyik leginkább használt talán a célok beállítása során. Ha két különböző URL-című köszönőoldala van (/thank-you/ és /subscription-confirmed/), de mindkettőt szeretné nyomon követni célkitöltésként, akkor használhatja ezt a szabályos kifejezést.
Szűrőkben is használhatja. Tegyük fel, hogy két cikk (a Tartalommarketing-leckékről és a Tartalomelemzésről) viselkedési jelentését szeretné megtekinteni, a /content-marketing-analytics/ és a /content-marketing-lessons/ URL-címekkel. Szűrőként beírhatná, hogy “content-marketing-analytics|content-marketing-lessons”, és csak ezeket a cikkeket kapná meg.
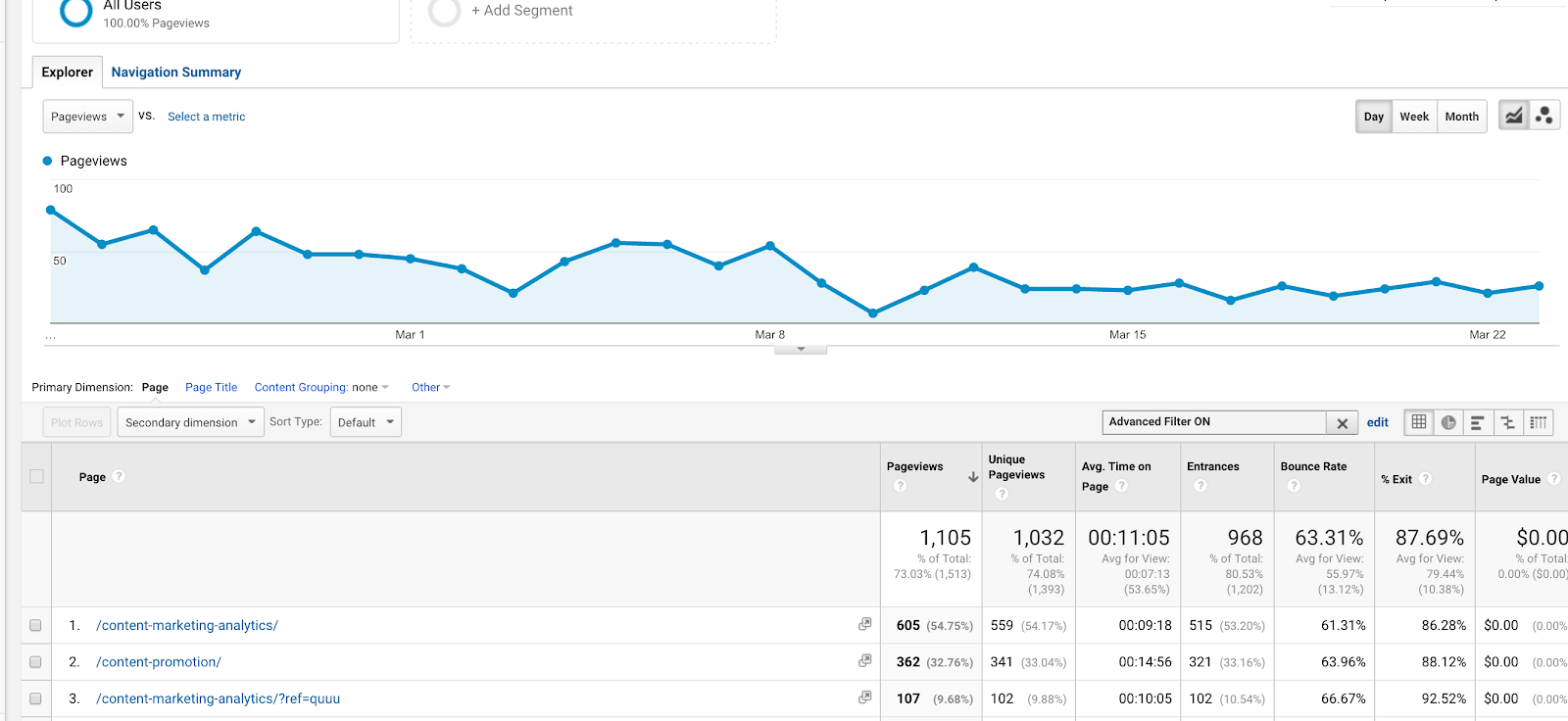
Pipa (|) használata egy szűrőben, hogy két külön blogbejegyzésre vonatkozó eredményeket kapjon
Backslash (\)
A backslash (\) egy másik egyszerű és gyakran használt reguláris kifejezés a Google Analyticsben. Azt jelenti, hogy “tekintsük a következő karaktert egyszerű szövegnek, és ne regexnek.”
Más szóval, sok olyan reguláris kifejezés van, amely egyszerű szövegben jelenik meg, mint például a pont, a kérdőjel és mások, amelyekről tisztáznunk kell, hogy reguláris kifejezésként vagy egyszerű szövegként kell-e olvasni őket.
Egy gyakori online lekérdezési karakterláncot akkor használnak, amikor valaki keres valamit az Ön webhelyén. Ha például a petsmart.com oldalon a “kis kutyajátékok” kifejezésre keresek, ez a lekérdezési karakterlánc jelenik meg:
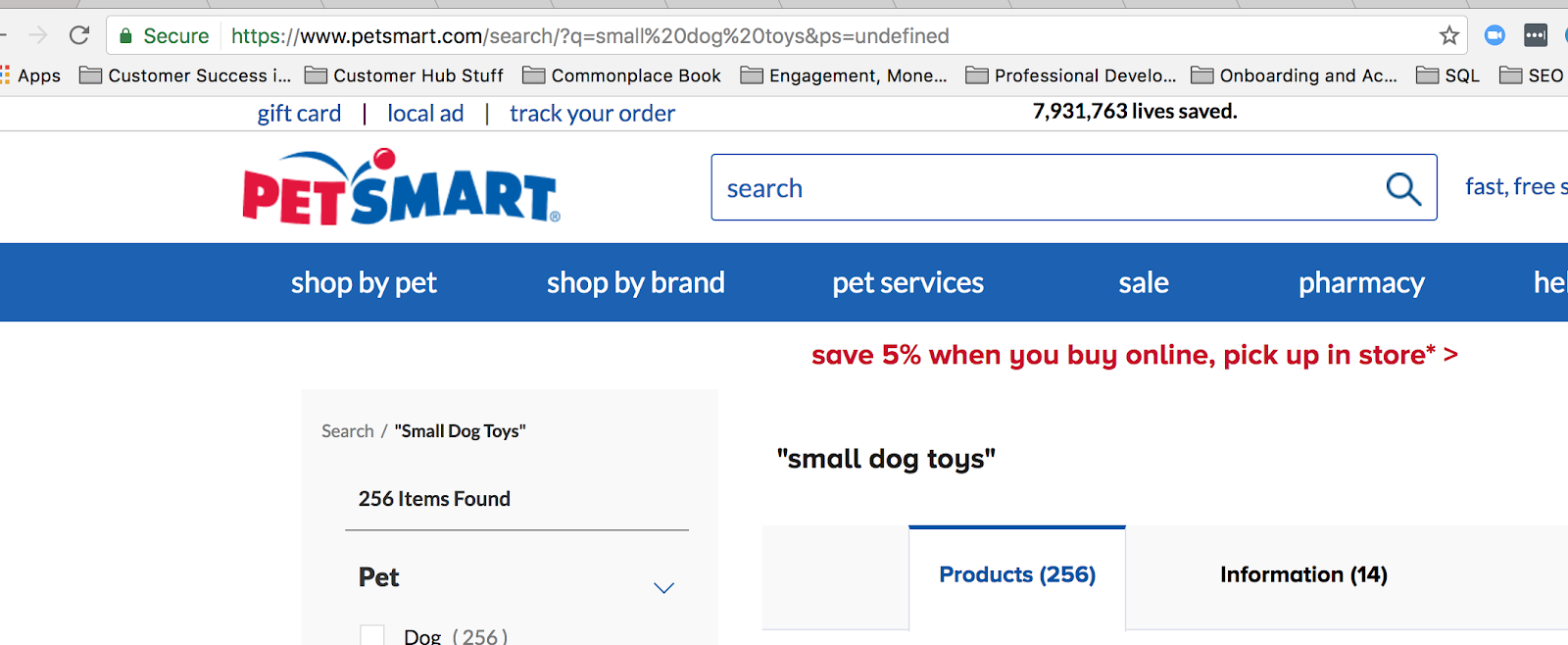
Az URL-ben egy lekérdezési karakterláncot hoz létre.
A kérdőjel itt azt jelzi, hogy helyszíni keresés történt, de a kérdőjel a Google Analyticsben is gyakran használt reguláris kifejezés. Ezért a backslash használatakor tisztáznunk kell, hogy ebben az esetben a kérdőjelet egyszerű szövegként kell olvasni.
Tegyük fel, hogy a Google Analyticsben minden olyan lekérdezési karakterláncot meg akarunk találni, amely /search/?q= kezdetű (mert ez keresést jelent). Ekkor a reguláris kifejezés a következő lenne:
search\/\?q=
Ezt ellenőrizheti egy olyan hibakeresővel, mint a regex101.com:
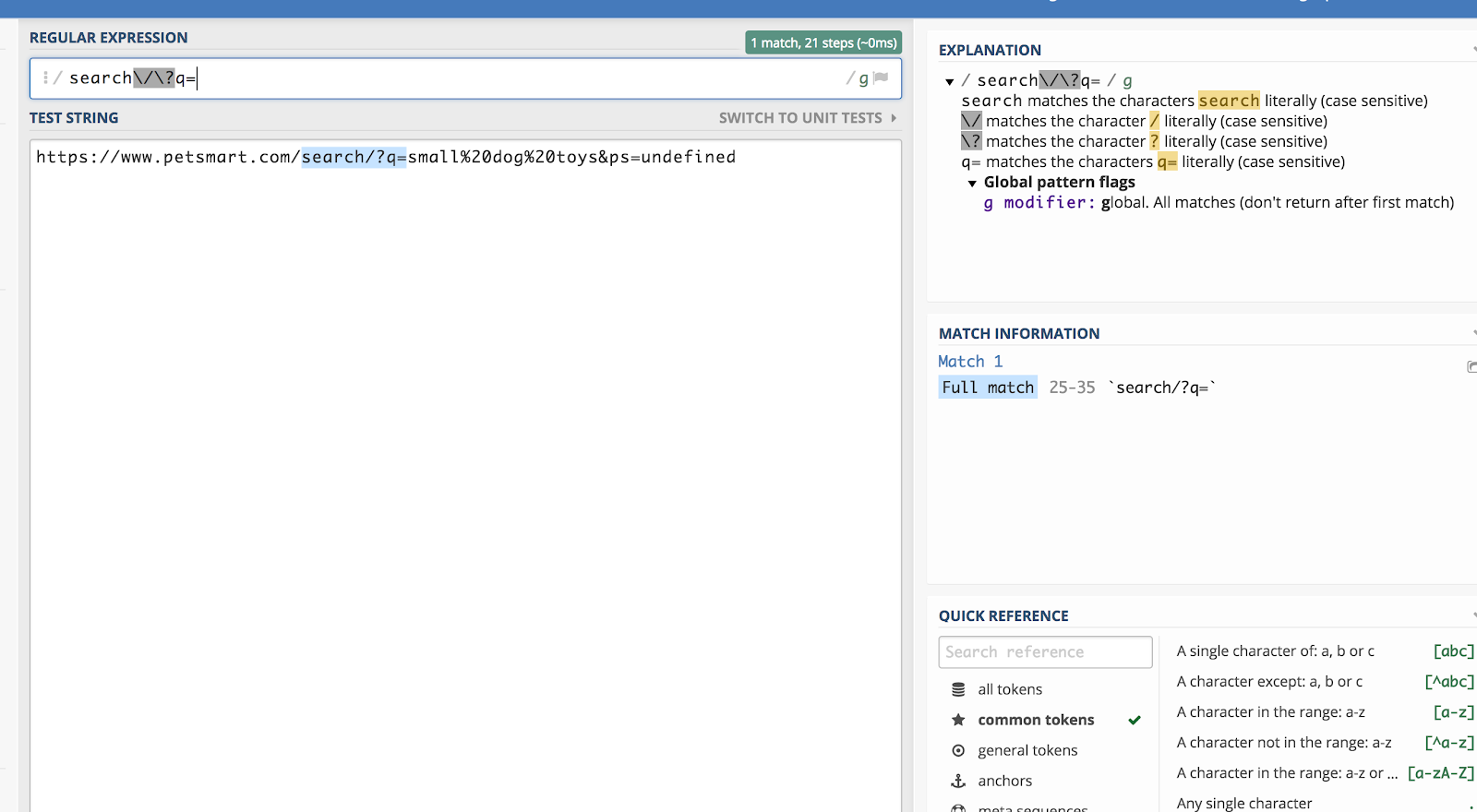
A backslash (\) utána egy karakterrel “menekül” a regexből, és egyszerű szövegként olvassa be.
Caret (^)
Caret (^) azt jelenti, hogy a kifejezés valamivel kezdődik. Ez akkor fontos, ha van egy olyan kifejezés, amely bárhol előfordulhat, de kifejezetten a kezdőpontjánál akarjuk megtalálni a kifejezést. Nézze meg például ezt a példát, amely néhány különböző kifejezést tartalmaz, amelyek a “Küldetés: sikeres.”
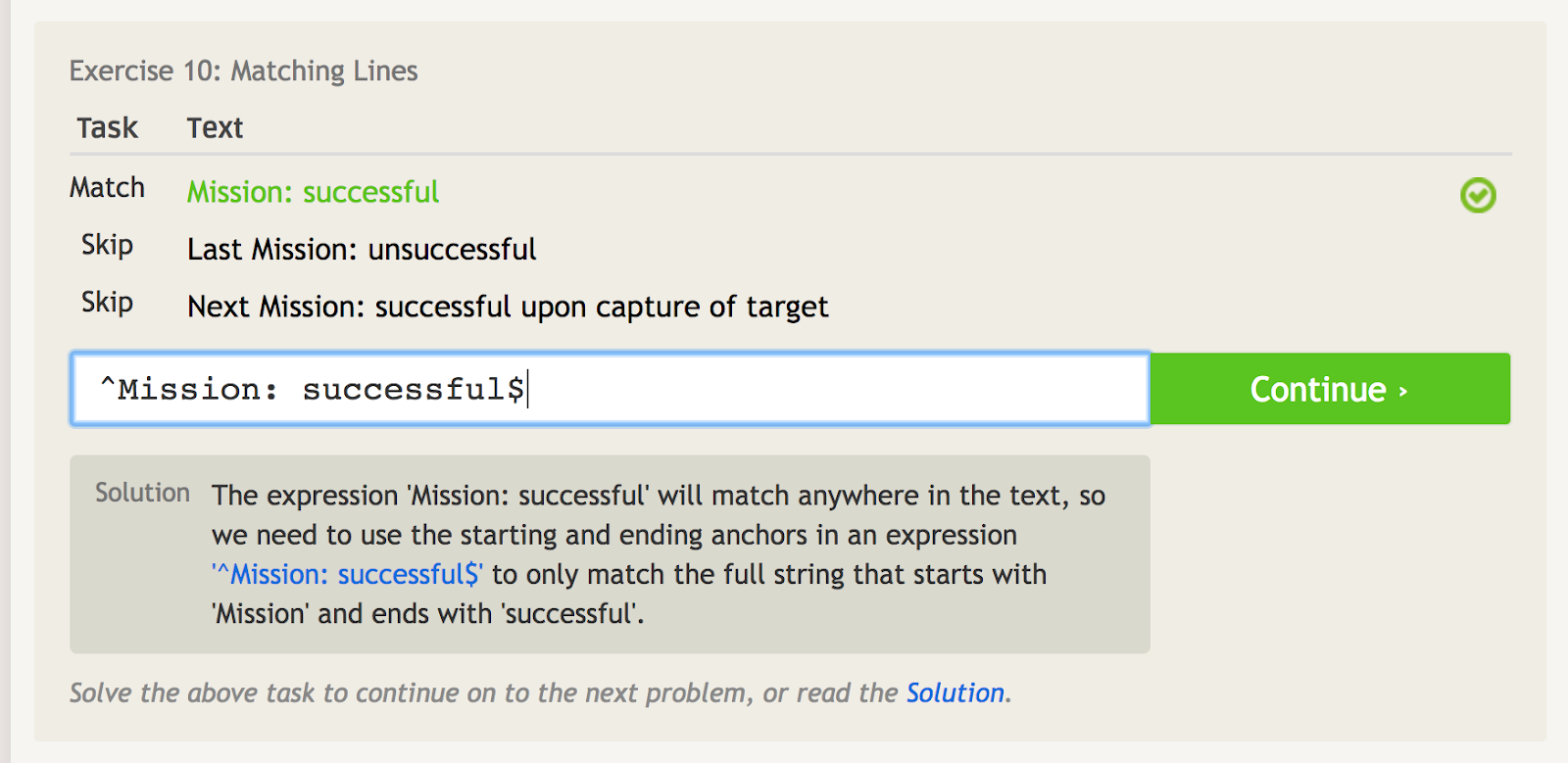
A caret a kezdő horgonyt jelzi, így itt kizárólag az első kifejezést tudjuk megfeleltetni.
Tegyük fel, hogy van egy csomó AdWords-kampányod, amelyek mind ugyanazzal a kifejezéssel kezdődnek (mert rossz tervező vagy a jövőre nézve):
- Freemium kampány végleges
- Első Freemium kampányunk
- Kreatív Freemium kampány ajánlat
- Teszt Freemium kampány
Az elsőhöz ^Freemium kampányt akarsz írni, és a többihez nem.
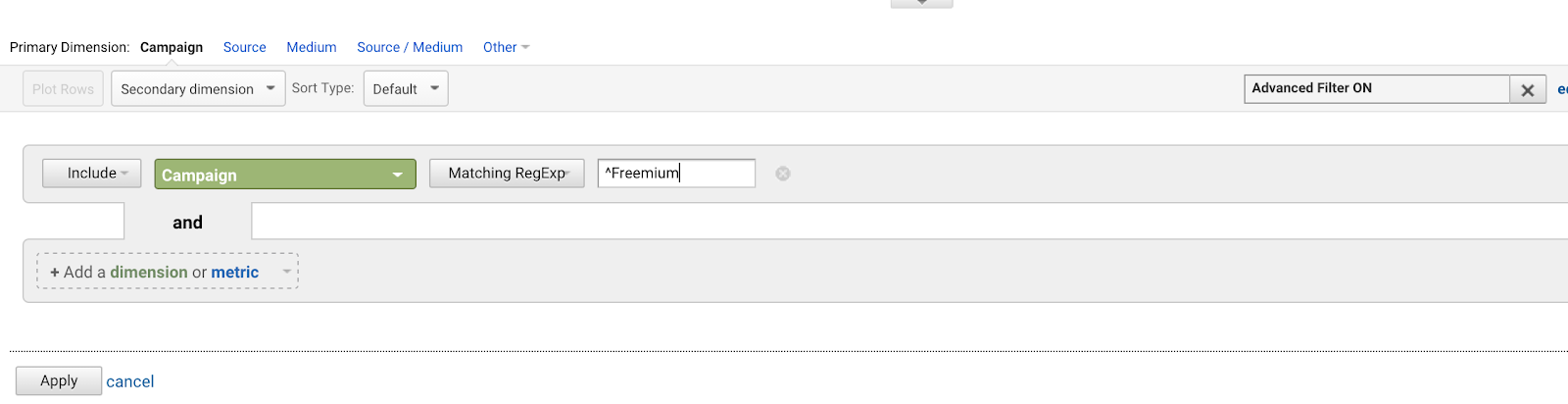
A pontjel (^) használata olyan karakterláncokra illeszkedik, amelyek ezekkel a karakterekkel kezdődnek
Dollárjel ($)
A dollárjel ($) azt jelenti, hogy a kifejezés valamivel végződik.
A kettő kombinálásával pontos egyezést érhet el.
Ha elindítottál egy kampányt “paidacquisitionfb” címmel, majd később elindítottál egy másikat “paidacquisitionfb-2” címmel, mert nem terveztél jól előre, és úgy gondoltad, hogy más hasonló című kampányaid is lesznek (ez gyakran előfordul), akkor elszigetelheted az elsőt, ha azt írod:
^paidacquisitionfb$
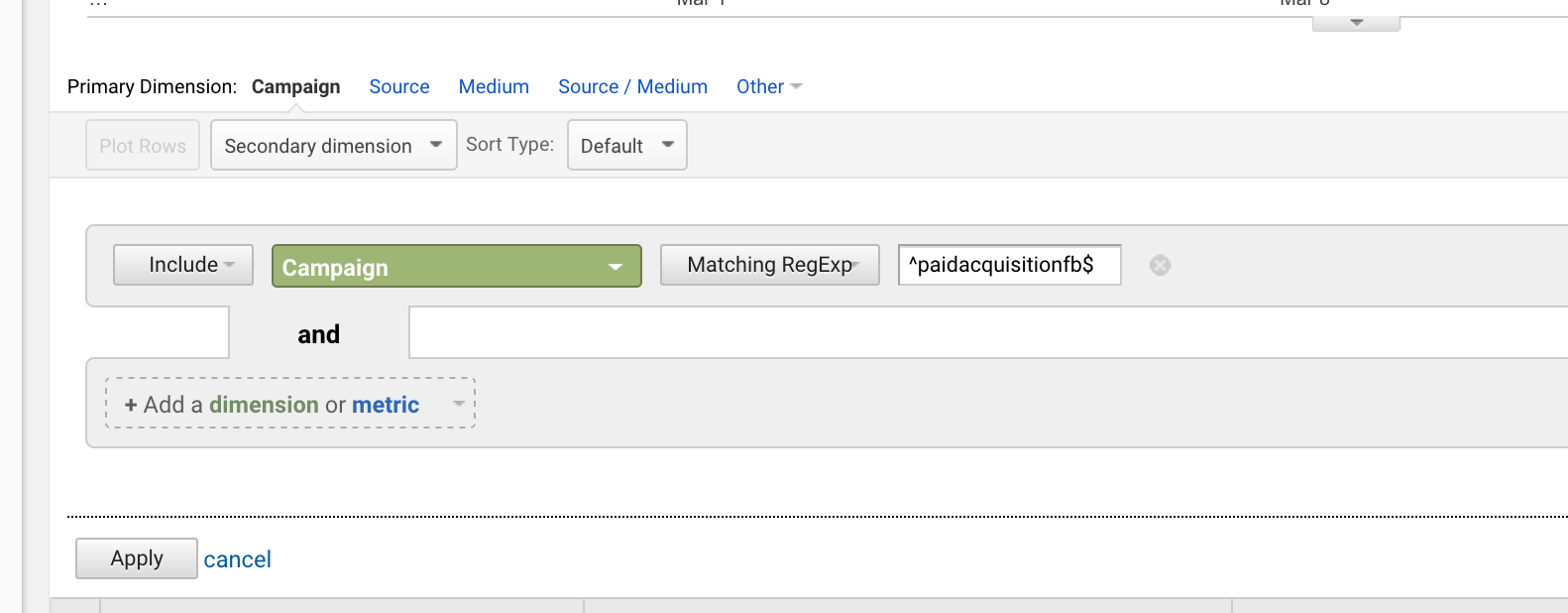
A carett és a dollár együttes használata nagyon gyakori.
Ha például rengeteg kategóriaoldal van a blogodon, és mindegyik oldalszámra végződik, írhatsz egy egyszerű Google Analytics regexet, hogy csak a blog kategóriaoldalakat (^/page/*/$) nézd meg. Ez olyan listákat eredményezne, mint:
- /page/1
- /page/2
- /page/3
…és így tovább.
Pont (.)
A pont (.) bármelyik karakterrel egyezik, ami bármit jelent, ami a billentyűzeten megtalálható: számokat, betűket, még szóközöket is. Önmagában nem szuper hasznos, de állandóan használják más reguláris kifejezésekkel együtt, különösen a csillaggal (következik).
Tegyük fel, hogy önmagában akarjuk használni, és használjuk a “ki..” példát. Ez mindenre illik, ami a K és az I betűkkel kezdődik, majd a következő két karakterre, bármi legyen is az.
Ha tehát lenne egy olyan karakterláncod, amely a kill, kind, kiss, kin, kid! és kit szavakat tartalmazná, akkor mindegyikkel egyezne. Várj, micsoda? Igen, a “kit”-re és a “kin”-re illeszkedne, amíg van utána szóköz (a szóközöket is felveszi). Ezt a logikát követve a “kid!”-ben lévő felkiáltójelet is felvenné.
Láthatod, miért lesz kusza a helyzet, ha csak ezt használod.
Íme a fenti példa illusztrációja a Regex101 használatával.com:
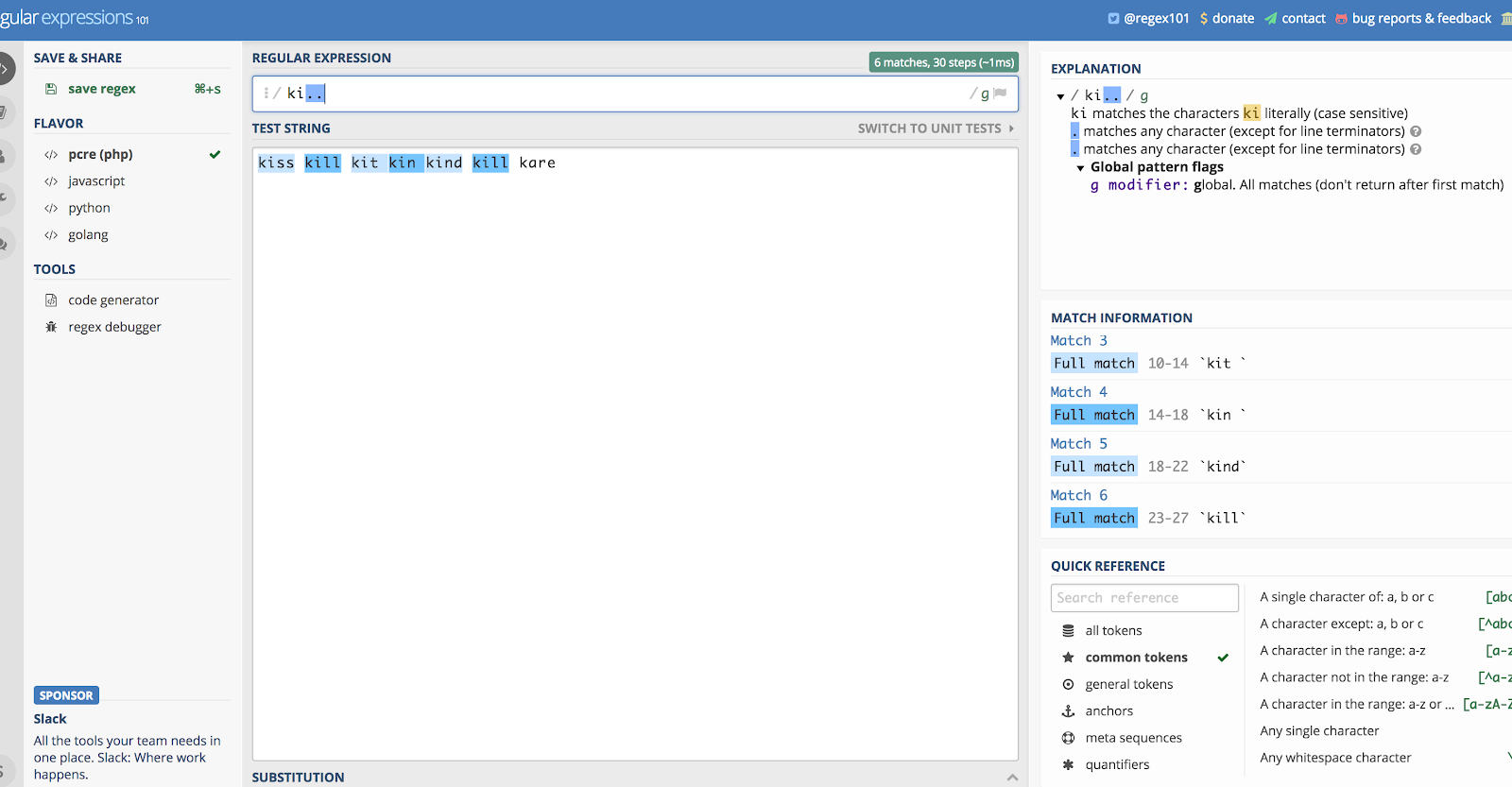
A pont (.) szinte mindenre illik.
Sztárjel (*)
A csillag (*) az előző elemek közül nullára vagy többre illik. Kissé zavaró, ha így fogalmazol, ezért csak egy példát használok.
Emlékszel arra a “wazzup” reklámra a Budweiser-től nemrég? Elég nehéz lenne kitalálni, hogyan írná valaki ezt a kifejezést, ha rákeresne (mondjuk a YouTube-on). De elméletileg az összes helyesírási variációt össze lehetne foglalni a következő módon:
waz*up
Itt egy illusztráció, hogyan működik ez a regex101-ben:
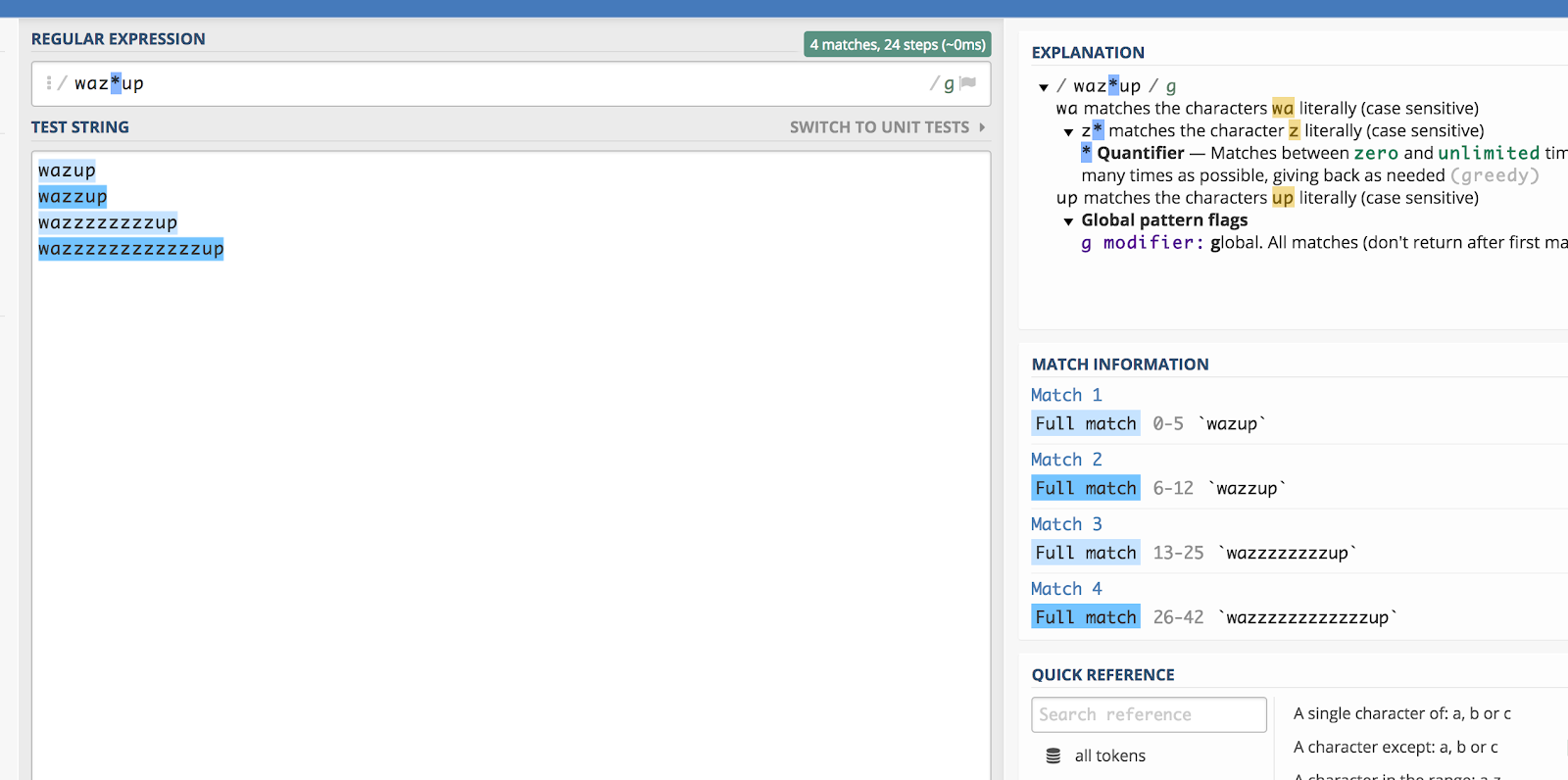
A csillag (*) nulla vagy több alkalommal egyezik az előző karakterrel.
Ha szuperpontos akarsz lenni, és figyelembe akarod venni a kis- és nagybetűket, akkor valami ilyesmit írhatsz:
*
De elkalandoztam.
Ahol a csillag valójában a legerősebb és leggyakrabban használt, az a ponttal együtt vagy más regex kombinációk részeként.
Pont-csillag kombináció (.*)
A pont-csillag kombináció (.*) alapvetően azt jelenti, hogy bármit lehet. Nagyon gyakran használják.
Ezt a kombinációt akkor használod, ha egy karakterláncban bármit meg akarsz találni. Mivel a pont azt jelenti, hogy bármilyen karakterrel egyezik, a * pedig azt, hogy az előtte lévő nulla vagy több karakterrel egyezik, ez a kombináció nagyon erős.
Példa: Több különböző típusú ügyfélszámlája van, de szeretné látni az összes adatát. Mindegyiknek hasonló oldalai vannak, így az oldalai valahogy így néznek ki:
/ügyfél/pro/bejelentkezés/
/ügyfél/free/bejelentkezés/
/ügyfél/starter/bejelentkezés/
Ezért a következő regexet írhatja:
/ügyfél/.*/bejelentkezés
Ezt a Google Analytics regex-kifejezést általában a felhasználói azonosítóval rendelkező felhasználók szegmenseinek létrehozására használom.
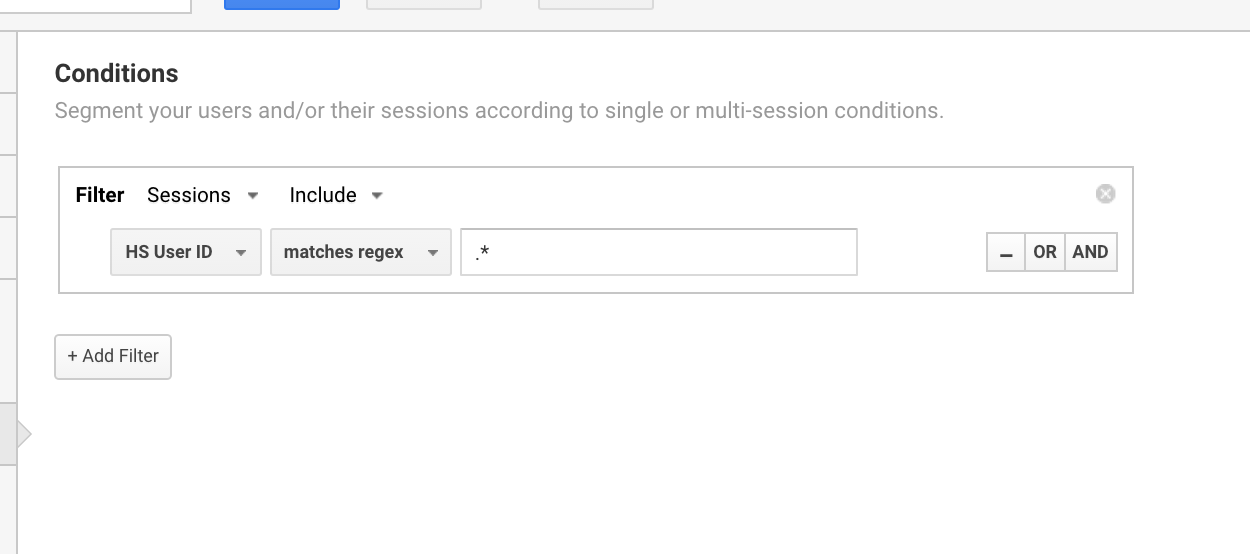
A Google Analytics regexének használata a felhasználói azonosítóval rendelkező összes munkamenet elkülönítésére.
Pluszjel (+)
A pluszjel (+) nagyon hasonlít a *-hoz, azzal a különbséggel, hogy az előző karakterek közül EGY vagy több karakterrel egyezik. Erről nem kell többet mondani, csak annyit, hogy nagyon kis mértékben különbözik a csillagtól. Íme a különbség:
Képzeld el, hogy vannak a következő szavak: hello, hhello és hhhello.
Ha azt írod, hogy hh+ello, akkor csak a második kettőre fog illeszkedni, de ha azt írod, hogy hh*ello, akkor mindegyikre.
Kisebb különbség. A valóságban szinte mindig a csillagot használom a pluszjel helyett.
Kérdőjel (?)
A kérdőjel (?) egyszerű. Egyszerűen azt jelenti, hogy az utolsó karakter lehetőség.
Tegyük fel, hogy nem nagyon érdekel, hogy a szó többes számban van-e vagy sem (mint a cipő esetében). Lehet “cipő” vagy “cipők”, és mindkét esetben meg akarod ragozni. Akkor írhatod, hogy “cipő?”
Itt egy példa a nevemmel. Ha valaki egy webhelykeresés során “Alex Birket”-nek írná, valószínűleg akkor is látni szeretném. Tehát írhatom:
Alex Birkett?
Íme, így néz ki a regex101.com-ban:
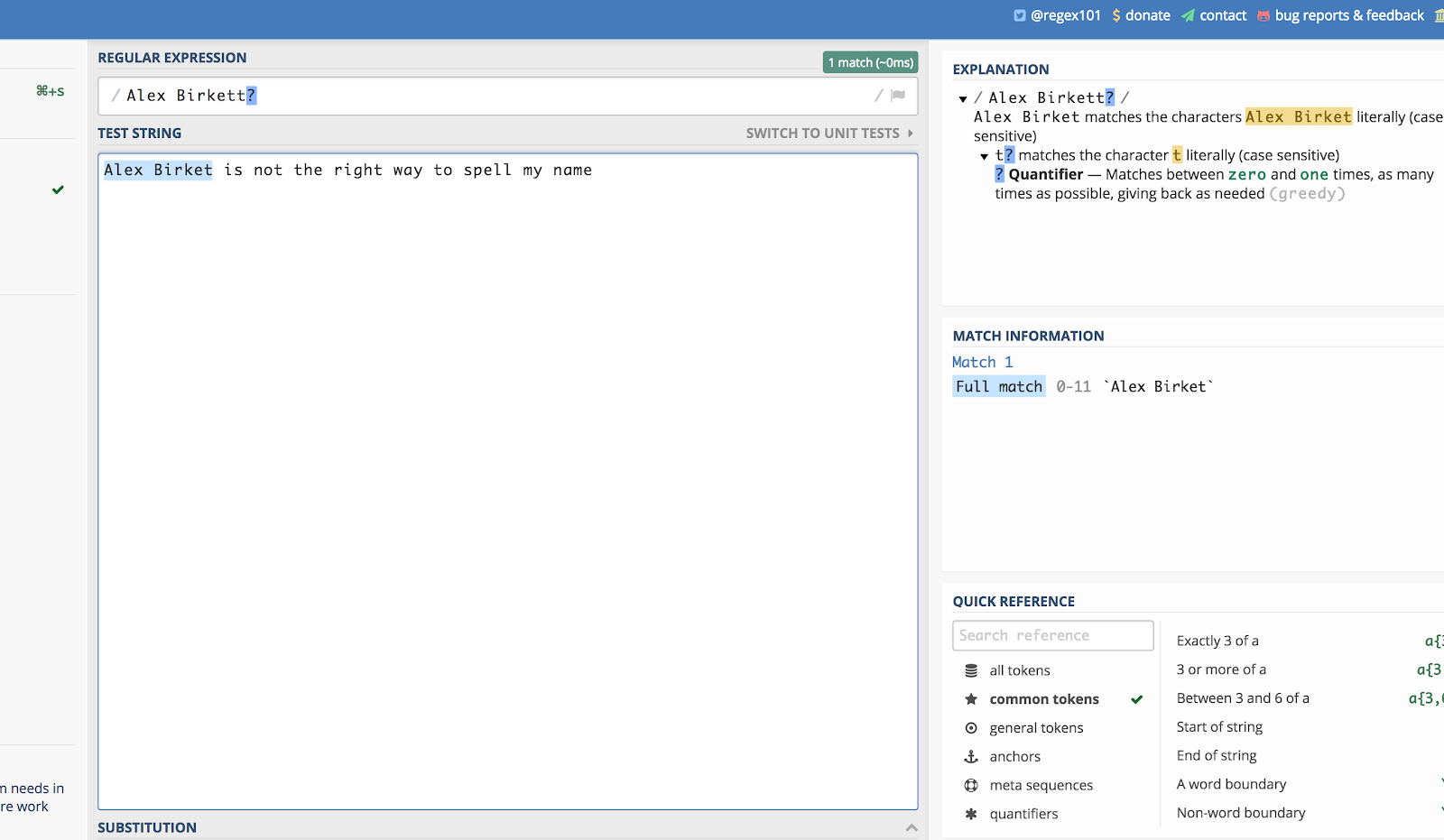
A kérdőjel (?) azt jelenti, hogy az azt megelőző utolsó karakter opcionális.
Kérdőjelek ()
A kérdőjelek ugyanúgy működnek, mint a matematikában. Azt mondják, hogy rangsorolja és elkülöníti a bennük rejlő logikát.
Tegyük fel, hogy van egy SaaS-vállalata három ajánlattal, és az összes árképző oldalát össze akarja egyeztetni. Az URL címei a következők:
site.com/products/meetings/pricing
site.com/products/crm/pricing
site.com/products/email/pricing
Azért, hogy mindhármat elkapd, használhatsz egy ilyen reguláris kifejezést:
^/products/(meetings|crm|email)/pricing$
A szögletes zárójelek ()
A szögletes () zárójelek listát hoznak létre. Ha van három karakterlánc: “dolog1”, “dolog2” és “dolog3”, akkor mindegyiket egybevethetjük a “dolog” vagy “dolog” írásmóddal (a kötőjelekről majd később – ezeket általában szögletes zárójelekkel együtt használjuk.
A szögletes zárójeleket használhatjuk egy szó vagy karakterlánc több ismétlődésének egybevetésére, miközben több más ismétlődést is kizárunk. Ha például a “can”, “man” és “fan” szavakra szeretnénk illeszkedni, de a “dan”, “ran” és “pan” szavakra nem, akkor a következő regexet használhatjuk erre:
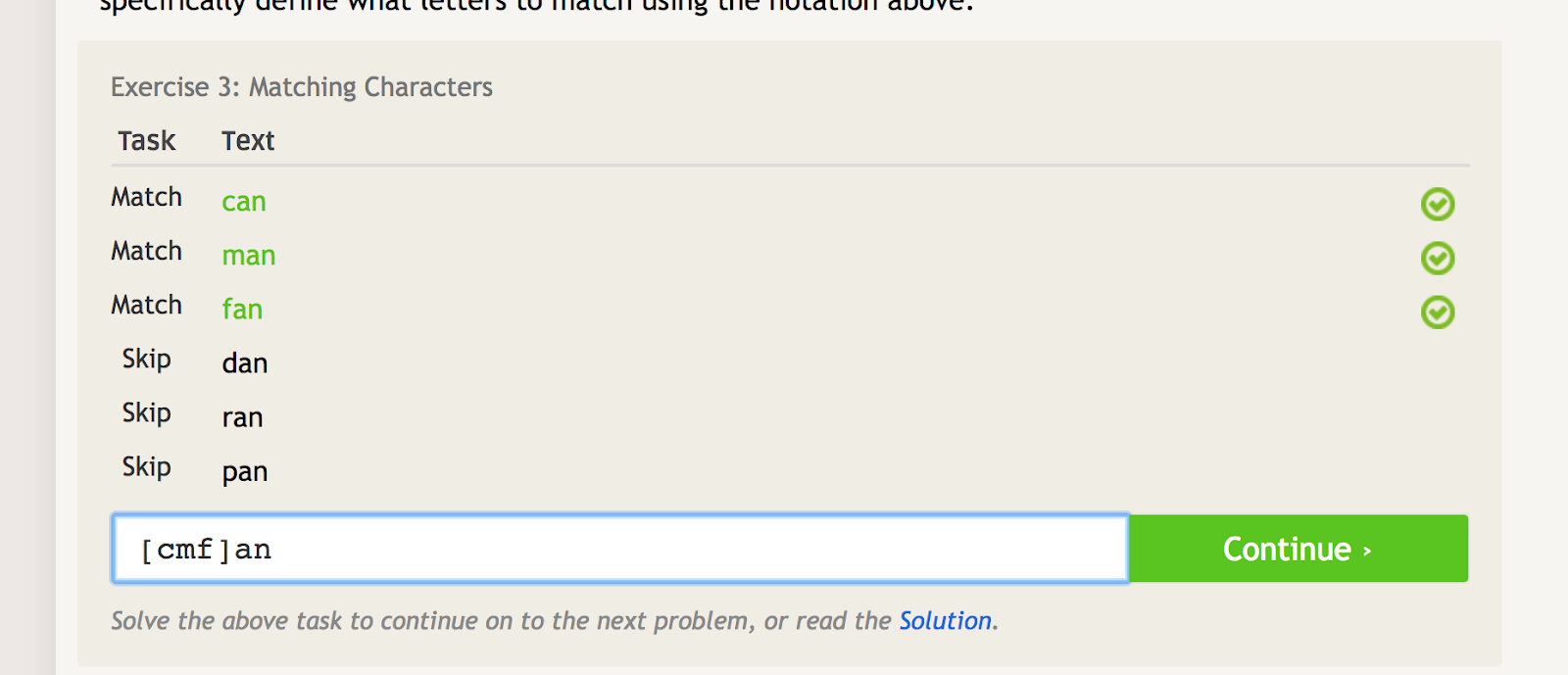
A szögletes zárójelek több illeszkedési feltételt hoznak létre, attól függően, hogy milyen karaktereket tesz bele. – kép forrása
Ezt akkor használhatja, ha több különböző, hasonló nevű terméke van, például “cipő1”, “cipő3” és “cipő5”. Ezeknek, és semmi másnak nem tudsz megfeleltetni, a “cipő”
Keresztjelek (-)
Keresztjelek (-) segítségével lineáris tétellistákat hozhatsz létre.
A szögletes zárójelek használatakor nem kell egyszerűen mindent felsorolnod, ha lineárisan fordul elő. Tehát ha egy olyan számsorozatot akarsz megfeleltetni, ahol az utolsó szám lehet bármi nullától kilencig, akkor ezt írhatod:
1234
Vagy írhatod a sokkal egyszerűbb:
1234
Ez működik a betűk esetében is. Képzeljük el, hogy van egy oldalkategóriád, amely két véletlenszerű betűre végződik. Valami ilyesmi:
/page-aa/
Az összes ilyen betűnek megfelelhetsz, ha azt írod:
/page-*/
Egy példát erre a regex101-en itt láthatsz:
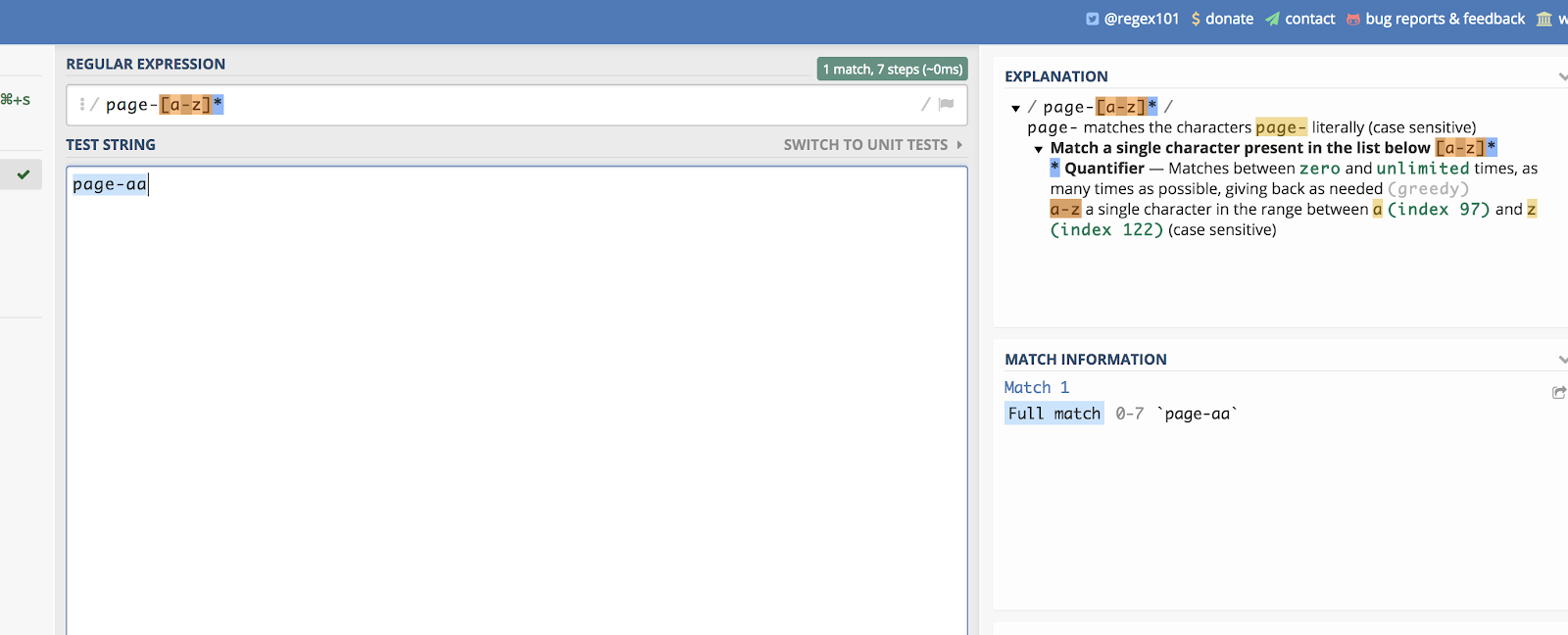
A kötőjelek segítségével lineáris listát hozhatsz létre a megfeleltetéshez.
A szögletes zárójelek ({ })
A szögletes zárójelek ({}) megmondják, hányszor kell megismételni az utolsó elemet.
Ha például csak a “wazzzzzzup”-ra akarsz egyezni, akkor használhatod a “waz{4}up”-ot.
De ha a “wazzzzzzup”-ra és a “wazzzzup”-ra akarsz egyezni, de a “wazup”-ra nem, akkor használhatod a “waz{3,5}up”-ot. Ez lényegében azt jelenti, hogy a “z” karaktert legalább háromszor, de legfeljebb ötször kell megfeleltetni.
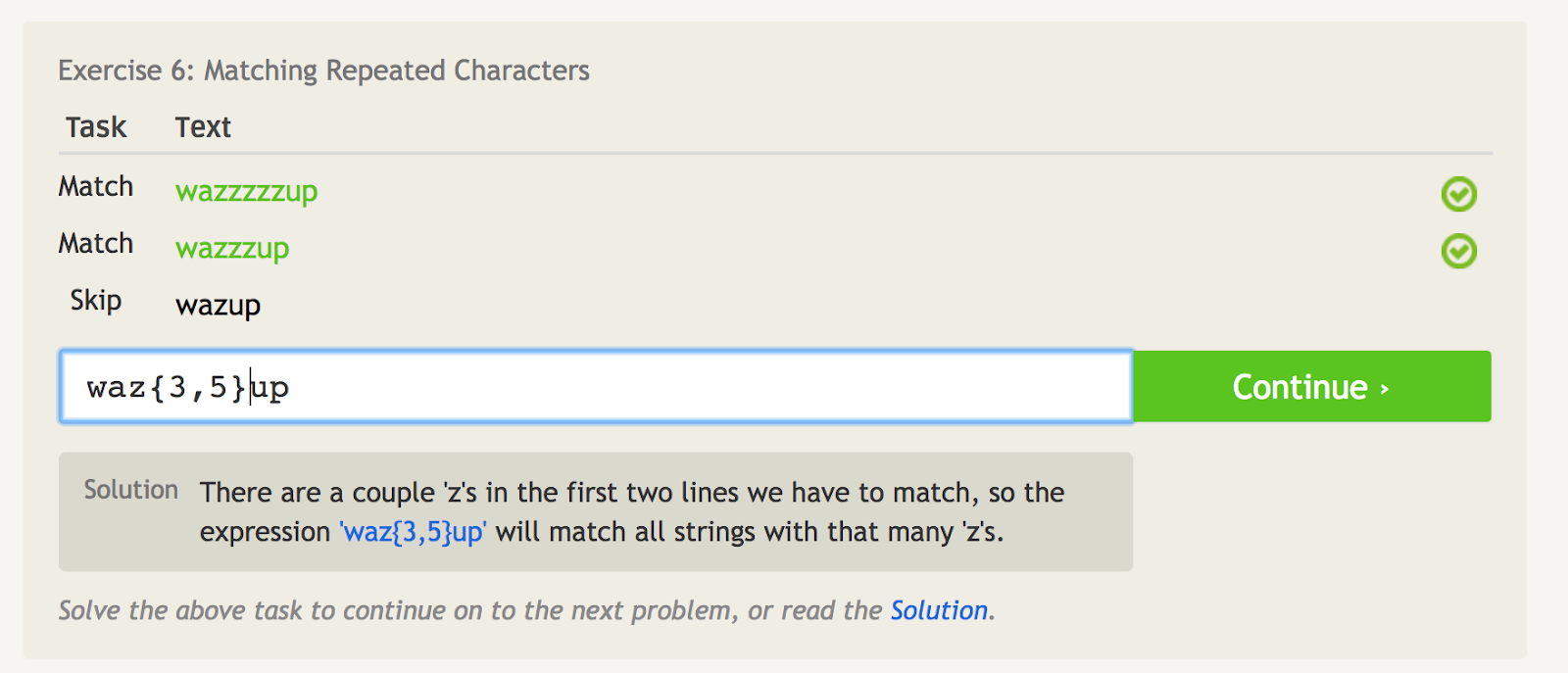
A szögletes zárójelek megmondják, hányszor kell megismételni az utolsó elemet. – kép forrása
Nem igazán sokat használtam ezt a reguláris kifejezést a Google Analyticsben, de egy gyakori felhasználási eset lehet az irányítószámok esetében. Általában az első két karakter azonos egy városban (78- például Austin, TX esetében). Tehát bármelyik Austin, TX irányítószámnak megfelelhet, ha azt írja:
78{3}
Ez azt mondja, hogy az utolsó három betű bármilyen véletlenszerű szám lehet nullától kilencig.
Google Analytics RegEx: Konkrét példák, amelyeket használhat
A Google Analytics egyik leggyakoribb regex felhasználási esete a szűrők kiépítése. Vegyünk végig három példát, egy egyszerűt és egy kicsit bonyolultabbat.
Először egy példa, amelyet Jenny Halasz nagyszerű bejegyzése ihletett a Search Engine Land-en.
Tegyük fel, hogy van egy kusza webhely-architektúránk, de szeretnénk megnézni az összes olyan bejegyzést, amely egy bizonyos alkönyvtárhoz tartozik. Ez lehet bármi, mondjuk egy webhelykategória vagy tartalomtípus. Ebben a példában az oldalon a /music/ kategóriát keressük, de csak a harmadik alkönyvtárban. Ebben az esetben beírhatjuk, hogy ^/.*/.*/music/.*, és akkor megkapjuk ezt a jelentést.

Ez a Google Analytics regex csak a /music/-t mutatja meg a harmadik alkönyvtárban. – image source
Ez első pillantásra zavarosnak tűnik – de miután megtanulta, mit jelentenek ezek a reguláris kifejezések, elég egyszerű. Alapvetően csak azt mondjuk a GA-nak, hogy olyan leszállóoldalt keressen, amelyik (^), majd bármelyik karaktert (.*), majd egy perjelet, majd bármelyik karaktert (.*), majd egy perjelet, majd egy perjelet és végül a zenét kezdi.
A LawnStarter hasonló taktikát használ a jelentéskészítéshez. Stratégiájuk az, hogy város-specifikus tartalmat hoznak létre aa városi oldalaik egy almappájában, a következő formátumban:
https://www.lawnstarter.com/{{{ tranzakciós városi oldal }}/{{információs tartalmi darab }}
A konverziós tölcsérek és a forgalmi jelentések tartalmának kiszűrésére az alapító Ryan Farley szerint a következő regexet használják.
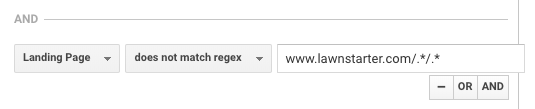
Ez a regex segít a LawnStarter-nek abban, hogy a város-specifikus tartalmakkal egyeztessenek az oldalukon.
Másodszor, nézzük meg, hogyan állíthatunk be egy szűrőt a Google Analytics egyik nézetéhez. Valószínű, hogy van egy megvalósítási szakembere, aki ezt elvégzi – de ha nem, akkor itt mindig kétszer mérj, egyszer vágj. Könnyű elrontani ezeket a dolgokat (ezért is érdemes a Google Analytics-fiókját egy homokozó nézettel beállítani, hogy először kipróbálhassa a dolgokat).
A szűrők beállításához menjen az Admin > Szűrők > Szűrő hozzáadása menüpontba.
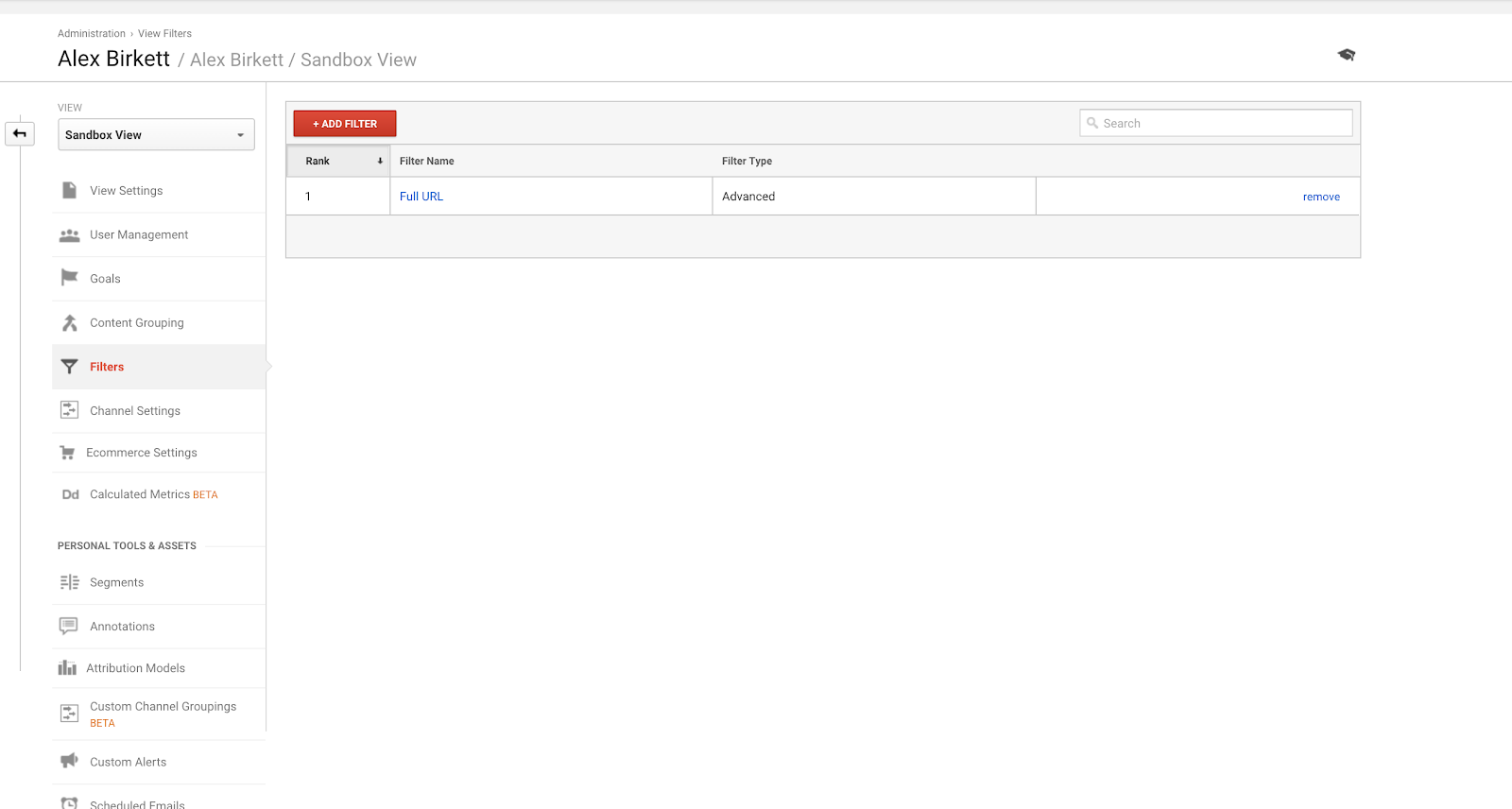
A Google Analyticsben leggyakrabban használt szűrő valószínűleg a saját IP-cím(ek) forgalmának kizárása.
Ezt sokak számára egyszerűen beállíthatja, hiszen csak egy IP-vel rendelkezik. Nagyobb cégeknél előfordulhat, hogy több IP-címmel rendelkezik, és a Google Analytics regexével könnyebben beállíthatja a kizárásokat.
Ha például azt írja, hogy 63\.212\.171\., akkor ez kizárja a 63.212.171.1 és 63.212.171.9 közötti összes IP-címet.
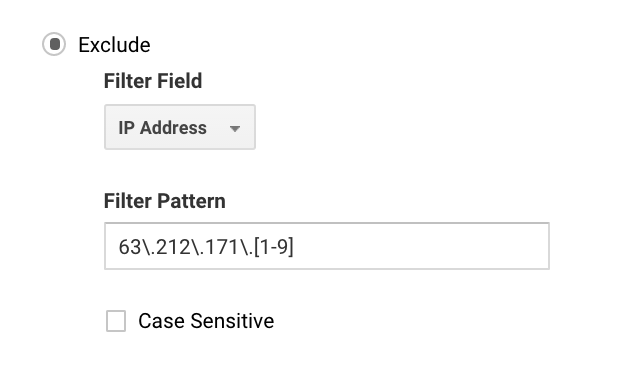
Ez a Google Analytics regex több IP-címet kizár.
Egy másik dolog, amit a Google Analytics regex segítségével tehet, az a lekérdezési paraméterek tisztítására szolgáló szűrők beállítása.
Ez bosszantó és problémás lehet az adatelemzés szempontjából.
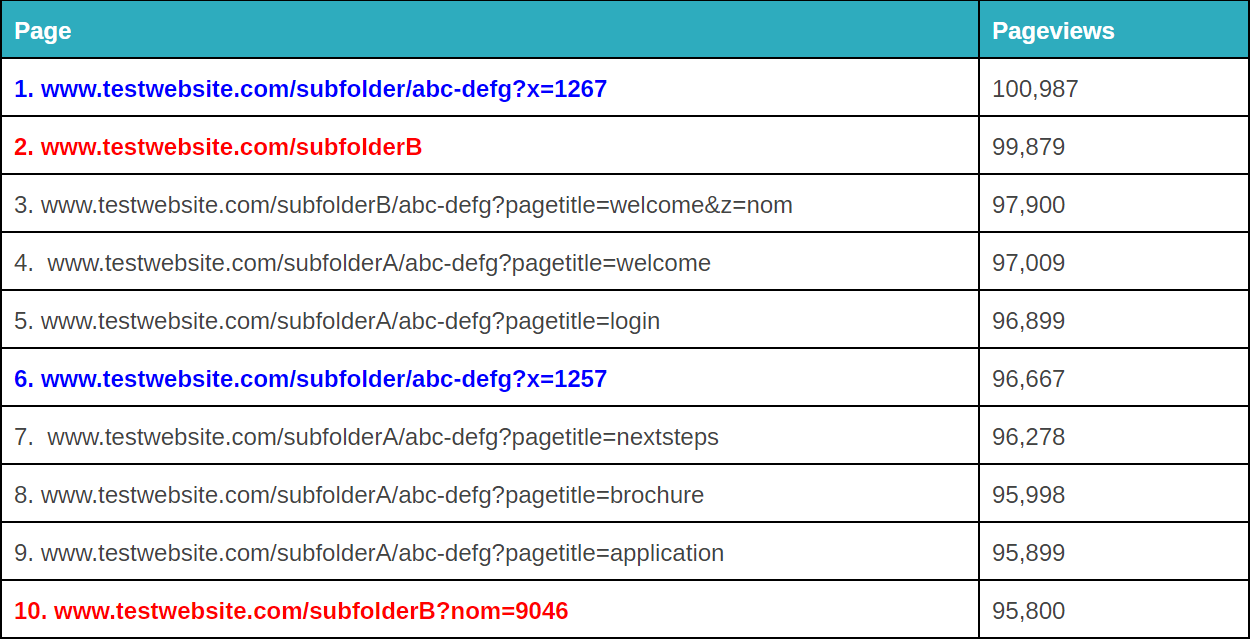
A töredezett lekérdezési paraméterek bosszantóak lehetnek. – kép forrása
Az attól függ, hogy milyen az Ön konkrét helyzete, de van néhány különböző módja annak, hogy a regex segítségével megtisztítsa ezt (megjegyzés: a probléma mértékétől függően ezt a Google Tag Managerben vagy az Excelben is megteheti. Erről bővebben itt).
Végezetül beszéljünk egy példáról, amellyel jobban megszervezhetjük az aldomain-követést. Ha több domainnel vagy aldomainnel rendelkezik, lehetséges, hogy duplikált URL-jei lesznek, hacsak nem állít be egy szűrőt, amely a hostnevét előtagolja a kérés URi-jéhez. Más szóval, előfordulhat, hogy az URL-ek:
- site.com/about
- blog.site.com/about
Ezek két különböző oldalt képviselnek (az egyik egy oldal a cégedről, a másik pedig a blogod about része). De mindkettő /about-ként jelenne meg a Google Analyticsben, hacsak nem állítod be a következő szűrőt (pont-aszteriszk kombinációval Google Analytics reguláris kifejezésekkel):
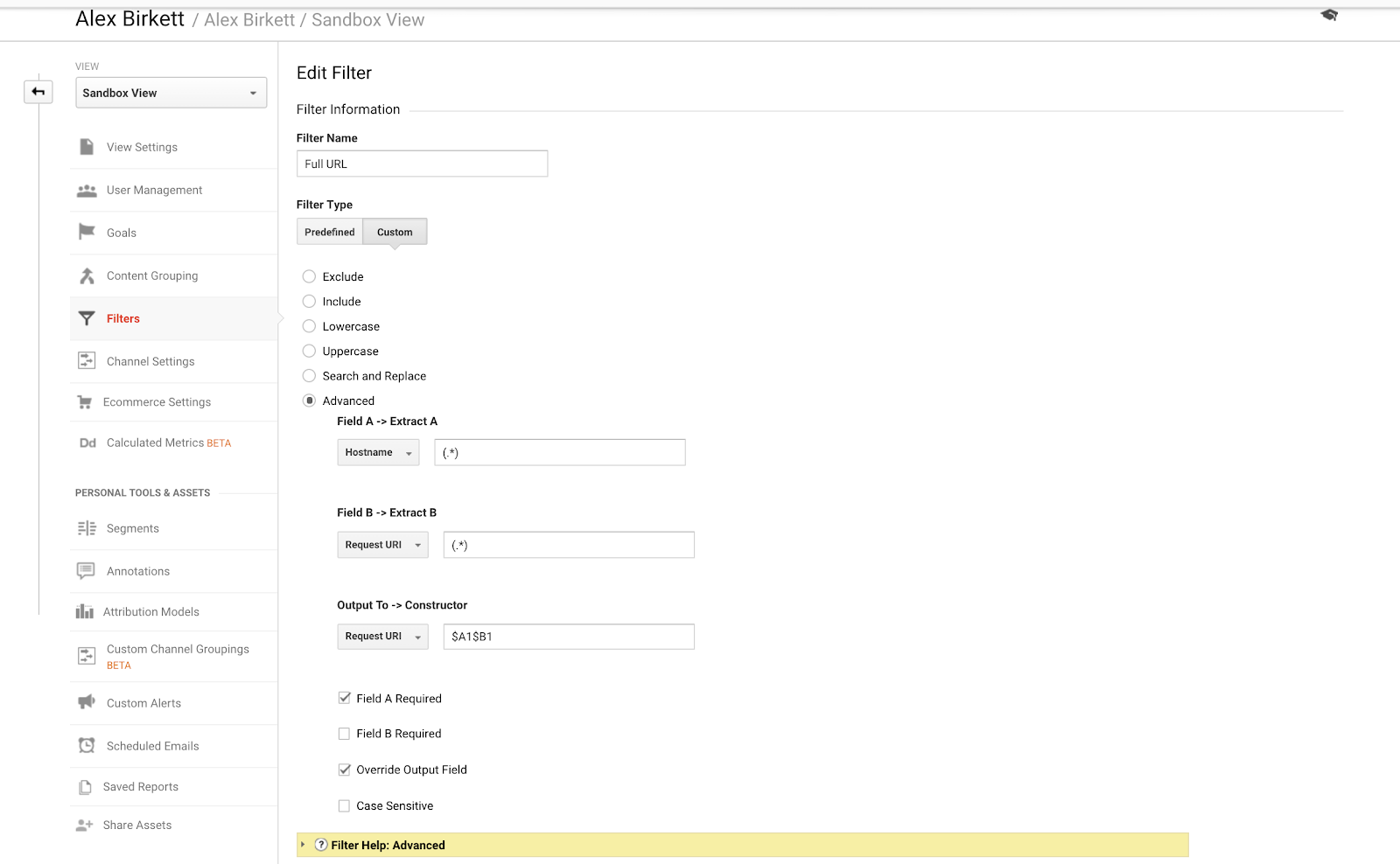
Meglehetősen egyszerű beállítani ezt az alapvető GA-szűrőt. – kép forrása
Ezeknek a szűrőknek a beállításával valójában már elég alaposan foglalkoztunk egy korábbi KlientBoost bejegyzésben a domain- és aldomain-közi nyomon követésről.
Google Analytics RegEx tippek & Elkerülendő hibák
A szabályos kifejezések egyike azoknak a dolgoknak, amelyeket csak gyakorolni kell, és be kell piszkolni a kezünket, hogy megtanuljuk. Mint ilyen, hibákat fogsz elkövetni.
Ez a legfontosabb tipp, tényleg: próbáld ki a dolgokat, és nézd meg, hogy működnek-e. Ebben a bejegyzésben rengeteg forrást felsoroltam a regex teszteléséhez, a regex101.com-tól a regexbuddy.com-ig. Mártózz meg, és használd ezeket az erőforrásokat.
Mindenesetre némi előzménnyel és heurisztikával gyorsabban tanulhatsz, és több hibát is észrevehetsz.
Az egyik dolog, amit tényleg meg kell tanulnod, az a regexben való “menekülés” (erről már beszéltünk a backslash-sel kapcsolatban). Leho Kraav, a CXL Institute technológiai igazgatója ezt így fogalmazza meg:
“Én azt mondanám, hogy “tanuljuk meg a dolgok megfelelő escapelését” – könnyen előfordulhat, hogy a karakterek nem egyeznek, amikor a karakterek ugyanolyanok, de a jelentésük más attól függően, hogy escapeltek-e vagy sem.”
Ha például a lekérdezésedben kérdőjel van, az is egy reguláris kifejezés, így ezt egyértelművé kell tenned a backlash-el. Chris Mercer, a MeasurementMarketing.io alapítója szerint is az egyik legnagyobb hiba, amit a kezdőknél lát, hogy nem tanulják meg ezt a képességet:
“A leggyakoribb hiba, amit a regexet használó kezdőknél látunk, hogy elfelejtik a regex szimbólumok “menekítését”. Ha például olyan oldalakat keresünk, amelyek megfelelnek a “thankyou/?success=yes” regexnek, akkor ez nem fog működni. Maga a “?” egy regex szimbólum, és a “menekülő karakter” (a ” \ “. Ebben az esetben a “thankyou/\?success=yes” működne.”
Még egy tipp? Maradjon egyszerű. Az emberek megpróbálják bonyolítani a dolgokat (nézd meg a legbonyolultabb regexet, amit valaha láttál, amit Leho írt, itt), de a reguláris kifejezések “mohók”, és annyi mindent egyeznek, amennyit csak tudnak. A Google Analytics kiadott egy blogbejegyzést a tippekről, és ezt így magyarázta el:
“Ha olyan kifejezést kell írnod, amely megfelel az “új látogatások” kifejezésnek, és az egyetlen lehetőség, amellyel egyezni fogsz, az “új látogatások” és az “ismételt látogatások”, akkor elég az “új” szó.”
Mindenre egyezni fognak, amire csak tudnak, hacsak nem kényszeríted őket, hogy ne tegyék. Ha a kifejezésed a “látogatások”, akkor egyezni fog az “új látogatások” és az “ismételt látogatások” kifejezéssel. Végül is mindkettő tartalmazta a “visits” kifejezést. Ahhoz, hogy kevésbé mohók legyenek, specifikusabbá kell tenned őket.”
Szóval kezdd lassan, tartsd egyszerűnek, és ne terheld túl magad a komplexitással (a hiba esélye ebben az esetben a komplexitással korrelál).
Mercer is megismétli ezt a pontot, azt tanácsolva, hogy fokozatosan haladj a dolgokkal:
“Amikor először kezded, koncentrálj arra, hogy jó legyél… aztán egyre jobb. Könnyű túlterhelni magunkat a regex által kínált sokféle lehetőséggel, de ha csak az alapokkal kezdjük, például a “vagy” szimbólum (a ” | “) elsajátításával, akkor gyorsan tapasztalatot szerzünk, és elkezdjük felismerni, hogy mi mindenre képes a regex.”
Az utolsó tipp tőlem: tanuljunk meg Google-olni dolgokat. Ez minden programozásra igaz, de különösen a reguláris kifejezésekre. El fogsz felejteni dolgokat, és ha nem írsz regexet naponta, akkor nem igazán van értelme mindent megjegyezni. Tanulj meg utánanézni a dolgoknak, és találd meg a választ arra, amit tenni akarsz.
A Google Analyticsen kívül: RegEx for Other Marketing Uses
A regex is olyasmi, amivel minden SEO-szakembernek érdemes foglalkoznia. Először is nyilvánvalóan azért, mert a SEO és a digitális analitika (pl. Google Analytics) elválaszthatatlanul összefonódik. Másodszor, mert néhány ugyanolyan illeszkedő kifejezés, amelyet a Google Analytics-adataink karaktereinek szűrésére és egyeztetésére írunk, a SEO-taktikákhoz való adatszerzés során is használható.
Más szóval, a reguláris kifejezések fontosak a webkaparáshoz.
A webkaparás és a SEO esetében általában egy olyan programozási nyelven keresztül dolgozunk, mint a Python, de az elvek ugyanazok.
Példaként az összes félkövérrel szedett szöveget lekaparhatnád egy oldalon, ha ezt használnád:
<strong>(+)</strong>
Vagy ahogy ebben a SEJ cikkben említettük, ha az összes szerző ESPN-jét kaparnád, ezt írhatnád:
“columnist”:”(.*?)”
Az összetartás és a józanság kedvéért nem merülök bele a fejlett webes kaparásba. Elég, ha csak annyit tudok, hogy a regex ezen a területen is fontos. Ha azonban többet szeretne megtudni, ajánlom ezeket a forrásokat:
- Web Scraping with Regular Expressions
- Scraping with Regular Expressions (Stanford)
- How to Use Regex for SEO & Website Data Extraction
A szabályos kifejezések a SEO-adatokkal való munkát is segítik, túl az egyszerű webkaparáson. Például a regex segítségével tovább testre szabhatod a Screaming Frog használatának módját.
Jenny Halasz egy jó példát adott a regex használatára az adatok megtisztítására egy Search Engine Land bejegyzésben:
“Tegyük fel például, hogy van egy URL-ekből álló listád, és csak a TLD (Top Level Domain) szerint kell lebontanod őket.
A http és www esetében használhatsz egy egyszerű keresést/helyettesítést, de hogyan tudod egyszerűen kiütni az összes fájlnevet? Kézzel is eltávolíthatod az összeset, de az elég macerás. Egy egyszerű regex wildcard (/*) használatával elhagyhatja a slash-t és mindent, ami utána következik.”
A végtelenségig beszélhetnénk a reguláris kifejezésekről a SEO-hoz és a webkaparáshoz, de most csak néhány jó forrásra hivatkozom, ha többet szeretnél tanulni (végül is ez egy nagyon sokoldalú nyelv, amelynek számos felhasználási területe van az analitikán túl is):
- How Regular Expression Affects SEO
- 5 Powerful Awesome Awesome Htaccess Redirect Tricks
- How to Use Regular Expression for Report Segmentation
Conclusion
A Google Analytics regexet tényleg minden elemzőnek ismernie kell, még akkor is, ha nem tartja magát műszaki szakembernek. Ezen túlmenően, néhány reguláris kifejezés ismerete (vagy legalábbis az, hogy hogyan keressük a válaszokat és hogyan alkalmazzuk őket a megfelelő problémákra) a marketingeseknek is segíthet különböző tevékenységekben.
Csak mondom, ez nem egy nagyon elterjedt készség, így valószínűleg lenyűgözni fogsz néhány kollégát az újonnan szerzett technikai marketing készségeiddel.
Szóval arra kérlek, kezdj el tanulni, és ami még fontosabb, egyszerűen kezdd el gyakorolni a reguláris kifejezések használatát. Nem is olyan ijesztőek.