Di Altexsoft.
La fidelizzazione dei clienti è uno dei pilastri della crescita primaria per i prodotti con un modello di business basato su abbonamento. La concorrenza è dura nel mercato SaaS dove i clienti sono liberi di scegliere tra molti fornitori anche all’interno di una categoria di prodotti. Diverse esperienze negative – o anche una sola – e un cliente può abbandonare. E se frotte di clienti insoddisfatti abbandonano a ritmo serrato, sia le perdite materiali che i danni alla reputazione sarebbero enormi.
Per questo articolo, abbiamo contattato gli esperti di HubSpot e ScienceSoft per discutere su come le aziende SaaS gestiscono il problema dell’abbandono dei clienti con la modellazione predittiva. Scoprirete approcci e best practice per risolvere questo problema. Discuteremo la raccolta di dati sulla relazione del cliente con un marchio, le caratteristiche del comportamento del cliente che si correlano maggiormente con il churn ed esploreremo la logica dietro la selezione dei modelli di machine learning più performanti.
- Che cos’è il customer churn?
- Impatto del customer churn sulle aziende
- Casi d’uso per la previsione del churn dei clienti
- Identificare i clienti a rischio con il machine learning: il problem-solving a colpo d’occhio
- Prevedere il churn dei clienti con il machine learning
- Comprendere un problema e un obiettivo finale
- Raccolta dati
- Preparazione e pre-elaborazione dei dati
- Modellazione e test
- Deployment e monitoraggio
- Conclusione
Che cos’è il customer churn?
Il customer churn (o customer attrition) è la tendenza dei clienti ad abbandonare un marchio e smettere di essere clienti paganti di una particolare azienda. La percentuale di clienti che smettono di usare i prodotti o i servizi di un’azienda durante un particolare periodo di tempo è chiamata tasso di abbandono (attrito) dei clienti. Uno dei modi per calcolare il churn rate è quello di dividere il numero di clienti persi durante un dato intervallo di tempo per il numero di clienti acquisiti, e poi moltiplicare questo numero per il 100 per cento. Per esempio, se avete ottenuto 150 clienti e ne avete persi tre il mese scorso, allora il vostro churn rate mensile è del 2 per cento.
Il churn rate è un indicatore di salute per le aziende i cui clienti sono abbonati e pagano per servizi su base ricorrente, nota il capo del dipartimento di analisi dei dati di ScienceSoft Alex Bekker, “I clienti optano per un prodotto o un servizio per un periodo particolare, che può essere piuttosto breve – diciamo, un mese. Così, un cliente rimane aperto per offerte più interessanti o vantaggiose. Inoltre, ogni volta che il loro impegno attuale finisce, i clienti hanno la possibilità di ripensarci e scegliere di non continuare con l’azienda. Naturalmente, un po’ di churn naturale è inevitabile, e la cifra varia da industria a industria. Ma avere una cifra di churn più alta di quella è un chiaro segno che un’azienda sta facendo qualcosa di sbagliato.”
Ci sono molte cose che i marchi possono sbagliare, dall’onboarding complicato quando ai clienti non vengono date informazioni facili da capire sull’uso del prodotto e le sue capacità alla scarsa comunicazione, per esempio la mancanza di feedback o le risposte ritardate alle domande. Un’altra situazione: I clienti di lunga data possono sentirsi non apprezzati perché non ricevono tanti bonus come i nuovi.
In generale, è l’esperienza complessiva del cliente che definisce la percezione del marchio e influenza il modo in cui i clienti riconoscono il rapporto qualità-prezzo dei prodotti o servizi che usano.
La realtà è che anche i clienti fedeli non tollerano un marchio se hanno avuto uno o più problemi con esso. Per esempio, il 59 per cento degli intervistati statunitensi al sondaggio di PricewaterhouseCoopers (PwC) ha notato che dirà addio a un marchio dopo diverse esperienze negative, e il 17 per cento di loro dopo una sola esperienza negativa.
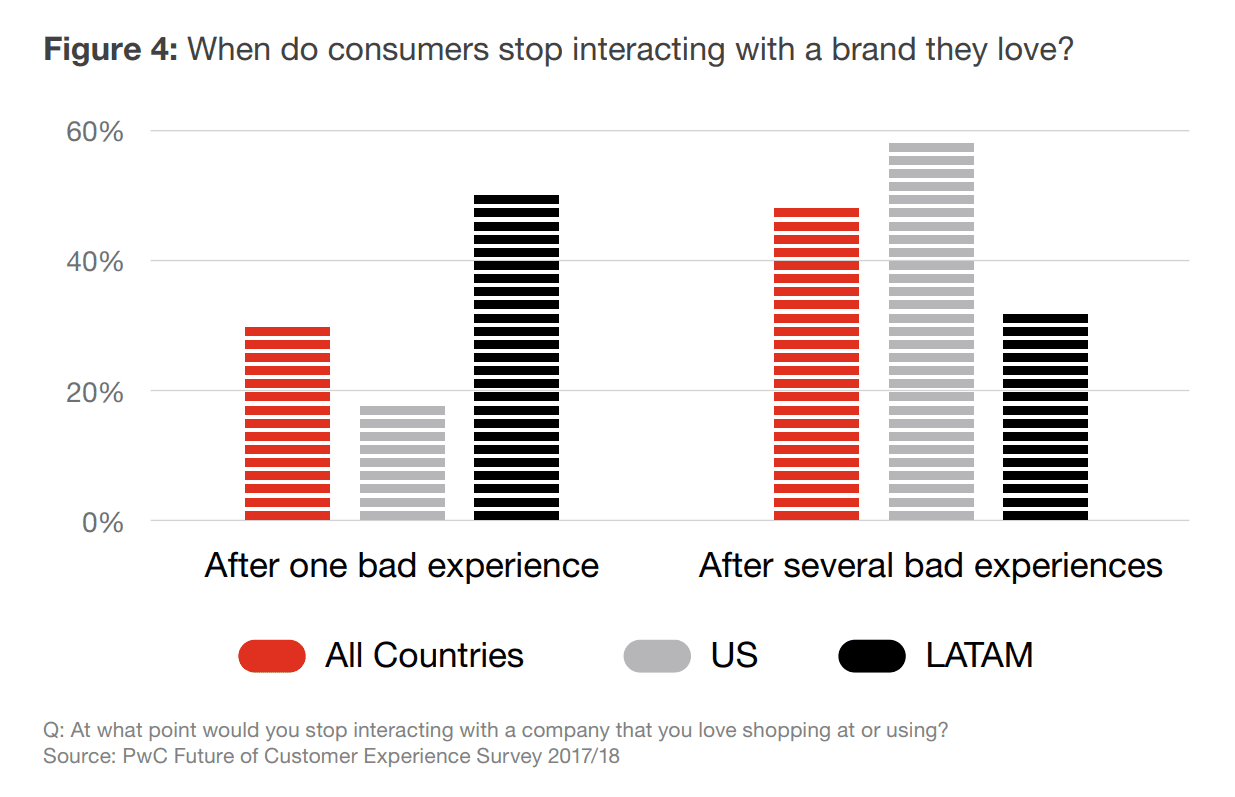
Le esperienze negative possono allontanare anche i clienti fedeli. Fonte: PwC
Impatto del customer churn sulle aziende
Bene, il churn è brutto. Ma come influisce esattamente sulle performance aziendali nel lungo periodo?
Non sottovalutare l’impatto di una percentuale anche minima di churn, dice Michael Redbord, direttore generale di Service Hub presso HubSpot. “In un business basato sull’abbonamento, anche un piccolo tasso di churn mensile/trimestrale si comporrà rapidamente nel tempo. Solo l’1% di churn mensile si traduce in quasi il 12% di churn annuale. Dato che è molto più costoso acquisire un nuovo cliente che mantenerne uno esistente, le aziende con alti tassi di abbandono si troveranno rapidamente in un buco finanziario in quanto devono dedicare sempre più risorse all’acquisizione di nuovi clienti.”
Molti sondaggi che si concentrano sui costi di acquisizione e conservazione dei clienti sono disponibili online. Secondo questa di Invesp, società di ottimizzazione del tasso di conversione, ottenere un nuovo cliente può costare fino a cinque volte di più che mantenere un cliente esistente.
I tassi di abbandono sono correlati alle entrate perse e all’aumento delle spese di acquisizione. Inoltre, giocano un ruolo più sfumato nel potenziale di crescita di un’azienda, continua Michael, “Gli acquirenti di oggi non sono timidi nel condividere le loro esperienze con i fornitori attraverso canali come siti di recensioni e social media, così come le reti peer-to-peer. HubSpot Research ha scoperto che il 49% degli acquirenti ha riferito di aver condiviso un’esperienza avuta con un’azienda sui social media. In un mondo di erosione della fiducia nelle aziende, il passaparola gioca un ruolo più critico che mai nel processo di acquisto. Dallo stesso studio di HubSpot Research, il 55% degli acquirenti non si fida più come una volta delle aziende da cui compra, il 65% non si fida dei comunicati stampa delle aziende, il 69% non si fida delle pubblicità e il 71% non si fida degli annunci sponsorizzati sui social network.”

Un’occhiata allo stato della fiducia dei clienti verso le aziende. Fonte: HubSpot Research Trust Survey
L’esperto conclude che le aziende con alti tassi di abbandono non solo non riescono a mantenere le loro relazioni con gli ex clienti, ma danneggiano anche i loro futuri sforzi di acquisizione creando un passaparola negativo sui loro prodotti.
Il fornitore di soluzioni di analisi conversazionale CallMiner ha intervistato 1000 adulti per sapere perché e come interagiscono con le aziende. L’indagine ha rivelato che le aziende statunitensi perdono circa 136 miliardi di dollari all’anno a causa dell’abbandono dei clienti. Per di più, i comportamenti aziendali che hanno portato i clienti a tagliare i legami con i marchi avrebbero potuto essere corretti.
Casi d’uso per la previsione del churn dei clienti
Come abbiamo detto prima, il churn rate è uno degli indicatori di performance critici per le aziende in abbonamento. Il modello di business dell’abbonamento – aperto per la prima volta dagli editori di libri inglesi nel 17° secolo – è molto popolare tra i moderni fornitori di servizi. Diamo una rapida occhiata a queste aziende:
I servizi di musica e video in streaming sono probabilmente i più comunemente associati al modello di business in abbonamento (Netflix, YouTube, Apple Music, Google Play, Spotify, Hulu, Amazon Video, Deezer, ecc).
Media. La presenza digitale è un must tra la stampa, così le aziende di notizie offrono ai lettori abbonamenti digitali oltre a quelli cartacei (Bloomberg, The Guardian, Financial Times, The New York Times, Medium ecc.).
Aziende di telecomunicazioni (via cavo o wireless). Queste aziende possono fornire una gamma completa di prodotti e servizi, tra cui rete wireless, internet, TV, telefono cellulare e servizi di telefonia domestica (AT&T, Sprint, Verizon, Cox Communications, ecc.) Alcuni sono specializzati nelle telecomunicazioni mobili (China Mobile, Vodafone, T-Mobile, ecc.).
Software as a service providers. L’adozione di software in cloud-hosted sta crescendo. Secondo Gartner, il mercato SaaS rimane il più grande segmento del mercato del cloud. Il suo fatturato dovrebbe crescere del 17,8% e raggiungere 85,1 miliardi di dollari nel 2019. La gamma di prodotti dei fornitori SaaS è ampia: editing grafico e video (Adobe Creative Cloud, Canva), contabilità (Sage 50cloud, FreshBooks), eCommerce (BigCommerce, Shopify), email marketing (MailChimp, Zoho Campaigns), e molti altri.
Questi tipi di aziende possono utilizzare il churn rate per misurare l’efficacia delle operazioni trasversali e della gestione dei prodotti.
Identificare i clienti a rischio con il machine learning: il problem-solving a colpo d’occhio
Le aziende che monitorano costantemente il modo in cui le persone si impegnano con i prodotti, incoraggiano i clienti a condividere opinioni e risolvono prontamente i loro problemi hanno maggiori opportunità di mantenere relazioni reciprocamente vantaggiose con i clienti.
E ora immaginate un’azienda che ha raccolto i dati dei clienti per un po’, in modo da poterli utilizzare per identificare i modelli di comportamento dei potenziali churners, segmentare questi clienti a rischio e adottare azioni appropriate per riconquistare la loro fiducia. Quelli che seguono un approccio proattivo alla gestione del churn dei clienti usano l’analitica predittiva. Questo è uno dei quattro tipi di analisi che comporta la previsione della probabilità di risultati, eventi o valori futuri analizzando i dati attuali e storici. L’analitica predittiva utilizza varie tecniche statistiche, come il data mining (riconoscimento dei modelli) e l’apprendimento automatico (ML).
“L’unica debolezza del monitoraggio del churn reale è che serve solo come indicatore in ritardo della scarsa esperienza del cliente, che è dove un modello di churn predittivo diventa estremamente prezioso”, nota Michael Redbord di HubSpot.
La caratteristica principale del machine learning è costruire sistemi capaci di trovare modelli nei dati, imparando da essi senza programmazione esplicita. Nel contesto della previsione del churn dei clienti, si tratta di caratteristiche di comportamento online che indicano la diminuzione della soddisfazione del cliente dall’utilizzo dei servizi/prodotti dell’azienda.
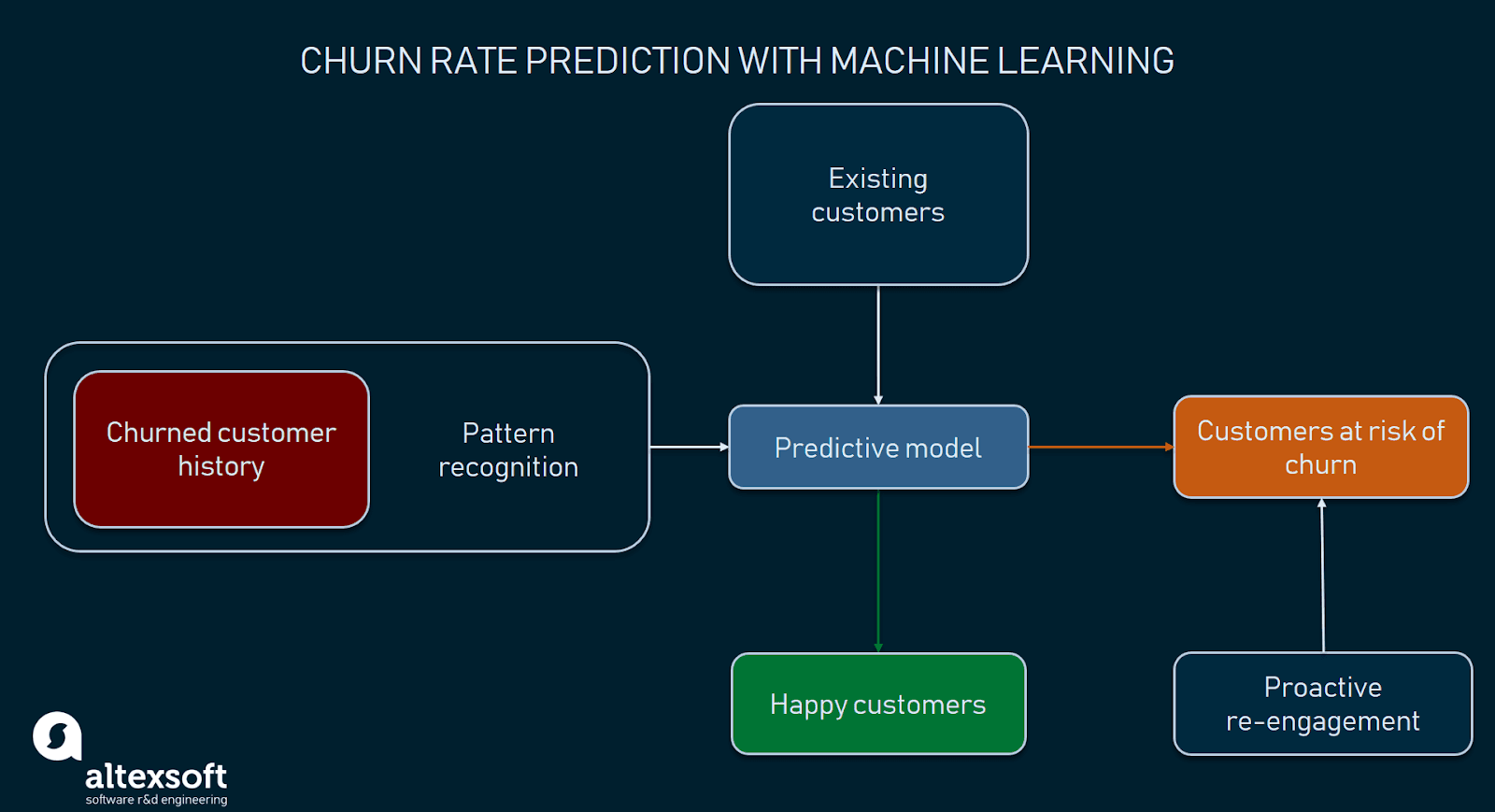
Rilevare i clienti a rischio di churn aiuta a prendere misure in anticipo
Anche Alex Bekker di ScienceSoft sottolinea l’importanza del machine learning per una gestione proattiva del churn: “Per quanto riguarda l’identificazione dei potenziali churners, gli algoritmi di apprendimento automatico possono fare un grande lavoro qui. Essi rivelano alcuni modelli di comportamento condivisi di quei clienti che hanno già lasciato l’azienda. Poi, gli algoritmi di ML controllano il comportamento dei clienti attuali rispetto a tali modelli e segnalano se scoprono potenziali churners.”
Le aziende basate sugli abbonamenti sfruttano ML per l’analisi predittiva per scoprire quali utenti attuali non sono pienamente soddisfatti dei loro servizi e affrontare i loro problemi quando non è troppo tardi: “Identificare i clienti a rischio di abbandono già 11 mesi prima del loro rinnovo permette al nostro team di successo di coinvolgere questi clienti, capire i loro punti deboli e, con loro, mettere insieme un piano a lungo termine incentrato sull’aiutare il cliente a realizzare il valore del servizio che ha acquistato”, spiega Michael.
I casi d’uso della modellazione predittiva di abbandono vanno oltre l’impegno proattivo con i potenziali clienti che abbandonano e la selezione di azioni di ritenzione efficaci. Secondo Redbord, il software basato su ML permette ai responsabili del successo dei clienti di definire quali clienti dovrebbero contattare. In altre parole, i dipendenti possono essere sicuri di parlare con i clienti giusti al momento giusto.
Le vendite, il successo dei clienti e i team di marketing possono anche utilizzare la conoscenza dall’analisi dei dati per allineare le loro azioni. “Per esempio, se un cliente mostra segni di rischio di abbandono, probabilmente non è un buon momento per le vendite di raggiungere con informazioni sui servizi aggiuntivi a cui il cliente potrebbe essere interessato. Piuttosto, quell’impegno dovrebbe essere con il CSM in modo che possano aiutare il cliente a ri-impegnarsi e vedere il valore nei prodotti che hanno attualmente. Come le vendite, il marketing può impegnarsi con i clienti in modo diverso a seconda della loro attuale indicazione di rischio di abbandono: Per esempio, i clienti non a rischio churn sono candidati migliori per partecipare a un case study rispetto a un cliente che è attualmente a rischio churn”, spiega l’esperto di HubSpot. In generale, la strategia di interazione con i clienti dovrebbe essere basata sull’etica e sul senso del tempo. E l’utilizzo del machine learning per l’analisi dei dati dei clienti può portare intuizioni per alimentare questa strategia.
Prevedere il churn dei clienti con il machine learning
Ma come iniziare a lavorare con la previsione del churn rate? Quali dati sono necessari? E quali sono i passi per l’implementazione?
Come per qualsiasi compito di apprendimento automatico, gli specialisti della scienza dei dati hanno prima bisogno di dati con cui lavorare. A seconda dell’obiettivo, i ricercatori definiscono quali dati devono raccogliere. Successivamente, i dati selezionati vengono preparati, preprocessati e trasformati in una forma adatta alla costruzione di modelli di apprendimento automatico. Trovare i metodi giusti per addestrare le macchine, mettere a punto i modelli e selezionare i migliori esecutori è un’altra parte significativa del lavoro. Una volta scelto un modello che fa previsioni con la massima accuratezza, può essere messo in produzione.
La portata complessiva del lavoro che i data scientist svolgono per costruire sistemi alimentati da ML in grado di prevedere l’attrito dei clienti può assomigliare a quanto segue:
- Comprensione di un problema e dell’obiettivo finale
- Raccolta dei dati
- Preparazione e pre-elaborazione dei dati
- Modellazione e test
- Spiegamento e monitoraggio del modello
Se vuoi sapere cosa succede durante queste fasi, leggi il nostro articolo sulla struttura del progetto di machine learning. Ora scopriamo come completare ognuna di queste fasi nel contesto della previsione del churn.
Comprendere un problema e un obiettivo finale
È importante capire quali approfondimenti si devono ottenere dall’analisi. In breve, bisogna decidere quale domanda porre e di conseguenza quale tipo di problema di machine learning risolvere: classificazione o regressione. Sembra complicato, ma abbiate pazienza.
Classificazione. L’obiettivo della classificazione è quello di determinare a quale classe o categoria appartiene un punto dati (cliente nel nostro caso). Per i problemi di classificazione, gli scienziati dei dati userebbero dati storici con variabili target predefinite AKA etichette (churner/non-churner) – risposte che devono essere previste – per addestrare un algoritmo. Con la classificazione, le aziende possono rispondere alle seguenti domande:
- Questo cliente si disfa o no?
- Un cliente rinnova il suo abbonamento?
- Un utente fa un downgrade di un piano tariffario?
- C’è qualche segno di comportamento insolito del cliente?
La quarta domanda sui segni di comportamento atipico rappresenta un tipo di problema di classificazione chiamato rilevamento delle anomalie. Il rilevamento delle anomalie riguarda l’identificazione di outlier – punti di dati che si discostano significativamente dal resto dei dati.
Regressione. La previsione di abbandono dei clienti può anche essere formulata come un compito di regressione. L’analisi di regressione è una tecnica statistica per stimare la relazione tra una variabile obiettivo e altri valori di dati che influenzano la variabile obiettivo, espressi in valori continui. Se questo è troppo difficile – il risultato della regressione è sempre un qualche numero, mentre la classificazione suggerisce sempre una categoria. Inoltre, l’analisi di regressione permette di stimare quante variabili diverse nei dati influenzano una variabile obiettivo. Con la regressione, le aziende possono prevedere in quale periodo di tempo è probabile che un cliente specifico si ritiri o ricevere una stima delle probabilità di ritiro per cliente.
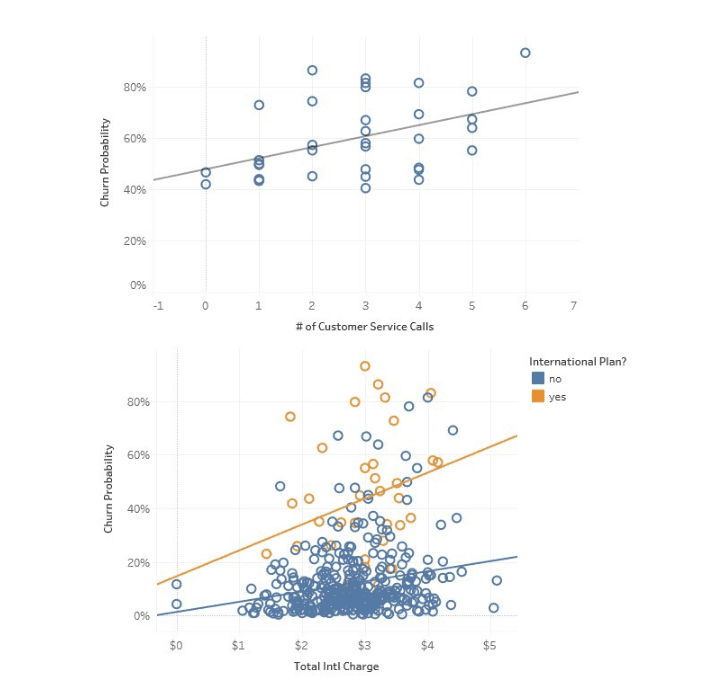
Questo è l’esempio di regressione logistica usato per prevedere la probabilità di abbandono nelle telecomunicazioni da Towards Data Science. Qui, la visualizzazione mostra come il numero di chiamate di servizio e l’uso di piani internazionali siano correlati al churn
Raccolta dati
Identificazione delle fonti di dati. Una volta identificati i tipi di approfondimenti da cercare, è possibile decidere quali fonti di dati sono necessarie per un’ulteriore modellazione predittiva. Ipotizziamo le fonti di dati più comuni che potete usare per prevedere il churn:
- Sistemi CRM (inclusi i record di vendita e di supporto clienti)
- Servizi di analisi (es, Google Analytics, AWStats, CrazyEgg)
- Feedback sui social media e piattaforme di recensioni
- Feedback fornito su richiesta per la vostra organizzazione, ecc.
Ovviamente, la lista può essere più o meno lunga a seconda del settore.
Preparazione e pre-elaborazione dei dati
I dati storici che sono stati selezionati per risolvere il problema devono essere trasformati in un formato adatto al machine learning. Poiché le prestazioni del modello e quindi la qualità delle intuizioni ricevute dipendono dalla qualità dei dati, l’obiettivo primario è quello di assicurarsi che tutti i punti di dati siano presentati utilizzando la stessa logica, e che l’insieme dei dati sia privo di incongruenze. In precedenza abbiamo scritto un articolo sulle tecniche di base per la preparazione del dataset, quindi sentitevi liberi di controllarlo se volete saperne di più sull’argomento.
Ingegneria delle caratteristiche, estrazione e selezione. L’ingegneria delle caratteristiche è una parte molto importante della preparazione dei dataset. Durante il processo, gli scienziati dei dati creano un insieme di attributi (caratteristiche di input) che rappresentano vari modelli di comportamento relativi al livello di impegno del cliente con un servizio o un prodotto. In senso lato, le caratteristiche sono caratteristiche misurabili delle osservazioni che un modello di ML prende in considerazione per prevedere i risultati (nel nostro caso la decisione riguarda la probabilità di abbandono).
Anche se le caratteristiche di comportamento sono specifiche per ogni settore, gli approcci per identificare i clienti a rischio sono universali, nota Alex: “Un’azienda cerca modelli di comportamento specifici che rivelano i potenziali abbandoni”. I dati demografici dei clienti e le caratteristiche di supporto funzionano per qualsiasi settore. Il comportamento dell’utente e le caratteristiche contestuali, a loro volta, sono tipiche per il modello di business SaaS:
- caratteristiche demografiche del cliente che contengono informazioni di base su un cliente (ad esempio, età, livello di istruzione, posizione, reddito)
- caratteristiche del comportamento dell’utente che descrivono come una persona utilizza un servizio o un prodotto (ad esempio, fase del ciclo di vita, numero di volte che accedono ai loro account, lunghezza della sessione attiva, ora del giorno in cui un prodotto viene utilizzato attivamente, funzioni o moduli utilizzati, azioni, valore monetario)
- caratteristiche di supporto che caratterizzano le interazioni con l’assistenza clienti (ad es, le query inviate, il numero di interazioni, la storia dei punteggi di soddisfazione dei clienti)
- caratteristiche contestuali che rappresentano altre informazioni contestuali su un cliente.
Gli specialisti di HubSpot cercano di capire “cosa fa un cliente di successo” utilizzando metriche come i visitatori del sito web, i lead generati e gli accordi creati. Il direttore generale di Service Hub Michael Redbord dice: “Non tracciamo solo i dati di utilizzo (ad esempio, la pubblicazione di un post sul blog, la modifica del valore chiuso previsto di un affare o l’invio di un’e-mail) ma i dati di risultato (ad esempio, il numero di clic su un’e-mail, il numero di visualizzazioni su un post sul blog, il valore in dollari degli affari chiusi durante un trimestre). È importante capire non solo come i vostri clienti stanno usando il vostro prodotto, ma quali risultati stanno vedendo. Se i clienti non stanno generando valore dal prodotto, di solito vediamo un aumento della probabilità di abbandono”.
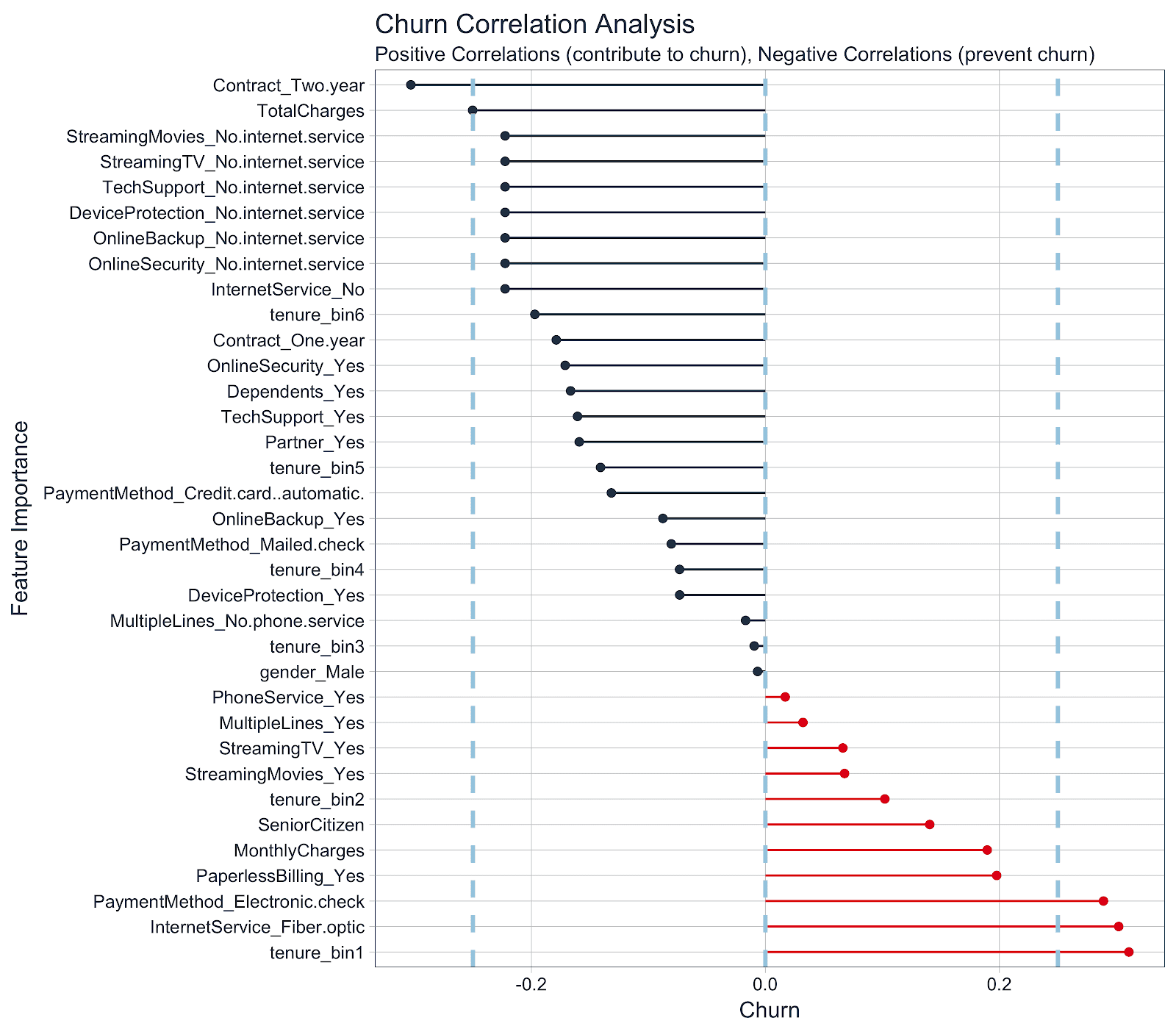
Come diversi comportamenti degli utenti, abbonamenti e caratteristiche demografiche correlano con il churn nei servizi Internet di Matt Dancho per RStudio blog
Ma avere troppi dati non è sempre un bene.
L’estrazione delle caratteristiche mira a ridurre il numero di variabili (attributi) lasciando quelle che rappresentano le informazioni più discriminanti. L’estrazione delle caratteristiche aiuta a ridurre la dimensionalità dei dati (le dimensioni sono colonne con attributi in un set di dati) e ad escludere le informazioni irrilevanti.
Durante la selezione delle caratteristiche, gli specialisti rivedono le caratteristiche precedentemente estratte e definiscono un sottogruppo di esse che è più correlato con il cambiamento di clientela. Come risultato della selezione delle caratteristiche, gli specialisti hanno un set di dati con solo caratteristiche rilevanti.
Metodi. Il capo del dipartimento di analisi dei dati di ScienceSoft Alex Bekker nota che metodi come l’importanza di permutazione, il pacchetto ELI5 Python e SHAP (SHapley Additive exPlanations) possono essere utilizzati per definire le caratteristiche più rilevanti e utili.
Il principio di lavoro di tutti i metodi sta nello spiegare come i modelli fanno le loro previsioni (in base a quali caratteristiche un modello ha fatto una particolare conclusione. Potete leggere di più sull’interpretabilità nel nostro articolo sui progressi e le tendenze dell’IA e della scienza dei dati.
L’importanza della permutazione è uno dei modi di definire l’importanza delle caratteristiche – un impatto che una caratteristica ha sulle previsioni. È calcolato su modelli che sono già stati addestrati. Ecco come si fa l’importanza di permutazione: Uno scienziato dei dati cambia l’ordine dei punti di dati in una singola colonna, alimenta il modello con il dataset risultante e definisce in che misura questo cambiamento diminuisce la sua accuratezza. Le caratteristiche che hanno la maggiore influenza sui risultati sono le più importanti.
Un altro modo per fare l’importanza di permutazione è quello di rimuovere una caratteristica da un set di dati e riqualificare il modello.
L’importanza di permutazione può essere fatta con ELI5 – una libreria Python open source che permette di visualizzare, eseguire il debug dei classificatori ML (algoritmi) e interpretare i loro risultati.
Secondo la documentazione di ELI5, questo metodo funziona meglio su set di dati che non contengono un gran numero di colonne (caratteristiche).
Utilizzando il framework SHAP (SHapley Additive exPlanations), gli specialisti possono interpretare le decisioni di “qualsiasi modello di apprendimento automatico”. SHAP assegna anche a ogni caratteristica un valore di importanza per una particolare previsione.
Segmentazione dei clienti. Le aziende in crescita e quelle che espandono la loro gamma di prodotti di solito segmentano i loro clienti usando caratteristiche precedentemente definite e selezionate. I clienti possono essere divisi in sottogruppi basati sulla loro fase del ciclo di vita, i bisogni, le soluzioni usate, il livello di impegno, il valore monetario o le informazioni di base. Poiché ogni categoria di clienti condivide modelli di comportamento comuni, è possibile aumentare la precisione di previsione attraverso l’uso di modelli ML addestrati specificamente su set di dati che rappresentano ogni segmento.
Per esempio, HubSpot utilizza criteri di segmentazione come persona del cliente, fase del ciclo di vita, prodotti posseduti, regione, lingua e reddito totale dell’account. “Combinazioni di segmenti come questi sono il modo in cui tagliamo la proprietà degli account e definiamo il book of business di un CSM o di un venditore”, dice Michael.
Inoltre, armati della conoscenza del valore del cliente, i dipendenti possono dare priorità alle loro attività di retention.
Dopo la preparazione dei dati, la selezione delle caratteristiche e le fasi di segmentazione dei clienti, arriva il momento di definire quanto tempo ci vorrà per tracciare il comportamento degli utenti prima di fare previsioni.
Selezionare una finestra di osservazione (storia degli eventi del cliente). La modellazione predittiva consiste nell’imparare la relazione tra le osservazioni fatte durante un periodo (finestra) che termina prima di un punto temporale specifico e le previsioni su un periodo che inizia dopo lo stesso punto temporale. Il primo periodo è indicato come osservazione, indipendente, finestra esplicativa, o storia degli eventi del cliente (usiamo l’ultima definizione per chiarezza). Il secondo periodo che segue quello di osservazione è chiamato performance, dipendente, o finestra di risposta. In altre parole, prevediamo gli eventi (un utente abbandona o rimane) in una finestra di performance, in futuro.

È fondamentale definire correttamente la storia degli eventi e le finestre di osservazione
L’ingegnere di machine learning di Spotify, Guilherme Dinis, Jr, nella sua tesi di master, ha studiato il comportamento dei nuovi utenti di Spotify registrati a un piano gratuito per definire se lasciano o rimangono attivi durante la seconda settimana dopo la loro registrazione.
Ha scelto la prima settimana di utilizzo come storia degli eventi. Per classificare gli utenti come churners e utenti attivi Guilherme ha controllato se c’era qualche attività di streaming nella seconda settimana. Se gli utenti hanno continuato ad ascoltare musica, sono stati classificati come non-churners.
“Le ragioni per mantenere le finestre di osservazione e di attivazione relativamente piccole è motivata da studi interni precedenti sulla stessa popolazione di utenti che indicavano un’alta probabilità di churn due settimane dopo la registrazione”, ha spiegato l’ingegnere.
Quindi, per definire la longevità della storia degli eventi e la finestra delle prestazioni, è necessario considerare quando i vostri utenti solitamente churnano. Può essere la seconda settimana, come nell’esempio di Spotify, o può essere l’undicesimo mese di abbonamento annuale. Ma molto probabilmente, non vorrai sapere che questo abbonato rischia di abbandonare tra un mese. Poiché avrete un lasso di tempo molto piccolo per il re-engagement.
Bilanciare il tempo per le osservazioni e le previsioni è in realtà un compito difficile. Per esempio, se una finestra di osservazione è di un mese, allora una finestra di performance per un cliente con un abbonamento annuale sarà di 11 mesi. Sembra che fare una breve cronologia degli eventi e lunghe finestre di performance sarebbe il più vantaggioso per le aziende. Si prende poco tempo per l’osservazione e si ha abbastanza tempo per il re-engagement. Sfortunatamente, non funziona sempre così. Una breve storia degli eventi può non essere sufficiente per fare previsioni affidabili, quindi sperimentare questi parametri può diventare un processo continuo e ripetitivo con i suoi compromessi. Fondamentalmente, si deve definire la storia degli eventi che sarebbe sufficiente per un modello per fare una previsione giustificata, ma ancora, avere abbastanza tempo per affrontare il potenziale churn.
Modellazione e test
L’obiettivo principale di questa fase del progetto è quello di sviluppare un modello di previsione del churn. Gli specialisti di solito addestrano numerosi modelli, li sintonizzano, li valutano e li testano per definire quello che individua i potenziali abbandoni con il livello di precisione desiderato sui dati di formazione.
I modelli classici di apprendimento automatico sono comunemente usati per prevedere l’abbandono dei clienti, per esempio la regressione logistica, gli alberi decisionali, la foresta casuale e altri. Alex Bekker di ScienceSoft suggerisce di usare Random Forest come modello di base, poi “le prestazioni di modelli come XGBoost, LightGBM, o CatBoost possono essere valutate”. Gli scienziati dei dati generalmente usano le prestazioni di un modello di base come una metrica per confrontare l’accuratezza della previsione di algoritmi più complessi.
La regressione logistica è un algoritmo usato per problemi di classificazione binaria. Prevede la probabilità di un evento misurando la relazione tra una variabile dipendente e una o più variabili indipendenti (caratteristiche). Più specificamente, la regressione logistica predice la possibilità che un’istanza (punto dati) appartenga alla categoria predefinita.
Un albero decisionale è un tipo di algoritmo di apprendimento supervisionato (con una variabile obiettivo predefinita). Questo algoritmo divide un campione di dati in due o più insiemi omogenei basati sul differenziatore più significativo nelle variabili di input per fare una previsione. Con ogni divisione, viene generata una parte di un albero. Come risultato, si sviluppa un albero con nodi di decisione e nodi foglia (che sono decisioni o classificazioni). Un albero inizia da un nodo radice – il miglior predittore.
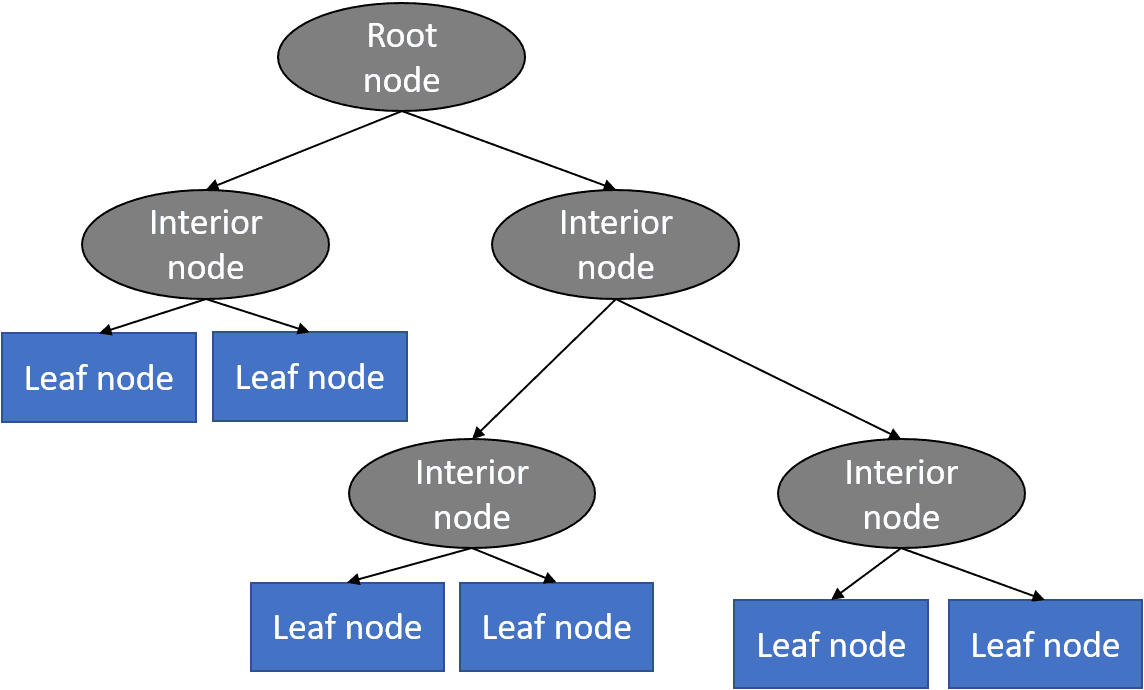
Struttura base dell’albero di decisione. Fonte: Python Machine Learning Tutorial
I risultati di previsione degli alberi di decisione possono essere facilmente interpretati e visualizzati. Anche le persone senza un background analitico o di scienza dei dati possono capire come è apparso un certo risultato. Rispetto ad altri algoritmi, gli alberi decisionali richiedono meno preparazione dei dati, che è anche un vantaggio. Tuttavia, possono essere instabili se sono stati fatti piccoli cambiamenti nei dati. In altre parole, le variazioni nei dati possono portare a generare alberi radicalmente diversi. Per affrontare questo problema, gli scienziati dei dati utilizzano alberi di decisione in un gruppo (AKA ensemble) di cui parleremo in seguito.
Una foresta casuale è un tipo di metodo di apprendimento ensemble che utilizza numerosi alberi di decisione per ottenere una maggiore precisione di previsione e stabilità del modello. Questo metodo si occupa sia di compiti di regressione che di classificazione. Ogni albero classifica un’istanza di dati (o vota per la sua classe) in base agli attributi, e la foresta sceglie la classificazione che ha ricevuto più voti. Nel caso di compiti di regressione, viene presa la media delle decisioni dei diversi alberi.
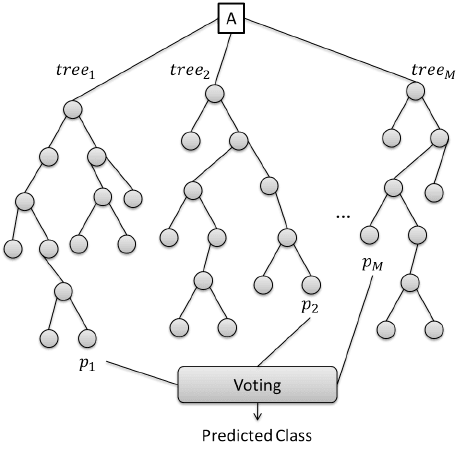
Ecco come Random Forest fa le previsioni. Fonte: ResearchGate
XGBoost è l’implementazione dell’algoritmo degli alberi boosted a gradiente che è comunemente usato per problemi di classificazione e regressione. Gradient boosting è un algoritmo che consiste in un gruppo di modelli più deboli (alberi), che sommano le loro stime per predire una variabile di destinazione con più accuratezza.
Un gruppo di ricercatori dell’Università della Virginia ha studiato i dati di utilizzo delle caratteristiche del software dipendenti dal tempo, come il numero di login e il numero di commenti, per prevedere il churn di un cliente SaaS in un orizzonte temporale di tre mesi. Gli autori hanno confrontato le prestazioni del modello attraverso quattro algoritmi di classificazione, e “il modello XGBoost ha ottenuto i migliori risultati per identificare le caratteristiche di utilizzo del software più importanti e per classificare i clienti come tipo di churn o non rischioso”. La capacità del modello XGBoost di definire le caratteristiche più significative che rappresentano il modo in cui i clienti usano il software SaaS può aiutare i fornitori di servizi a lanciare campagne di marketing più efficaci quando si rivolgono ai potenziali clienti, secondo i ricercatori.
LightGBM è un framework di gradient boosting che utilizza algoritmi di apprendimento basati su alberi. Può essere usato per molti compiti di ML, per esempio, classificazione e classificazione. Secondo la documentazione, alcuni vantaggi di LightGBM sono una maggiore velocità di formazione e una maggiore efficienza, così come una maggiore precisione. Questi algoritmi utilizzano meno memoria e gestiscono grandi volumi di dati – non è consigliabile utilizzarli su set di dati con meno di 10.000 righe. LightGBM supporta anche l’apprendimento parallelo e su GPU (l’uso di unità di elaborazione grafica per l’addestramento di grandi insiemi di dati).
CatBoost è un’altra libreria di gradient boosting su alberi decisionali. Gestisce sia caratteristiche numeriche che categoriche, quindi può essere utilizzato per la classificazione, la regressione, la classificazione e altri compiti di apprendimento automatico. Uno dei vantaggi di CatBoost è che permette di addestrare modelli con CPU e due o più GPU.
Scelta della tecnica. Numerosi fattori possono influenzare il numero di modelli richiesti in produzione e il loro tipo. Anche se il caso di ogni azienda è unico, ma in generale gli approcci alla gestione dei dati dei clienti e le esigenze aziendali hanno un peso. La scelta di una tecnica di predizione può dipendere da:
- Fase del ciclo di vita del cliente. Gli specialisti di HubSpot, per esempio, hanno concluso che la scelta del modello può dipendere dalla fase di interazione tra un cliente e un marchio. “I clienti in fase di onboarding di solito non mostrano le stesse metriche di valore dei clienti che usano HubSpot da più di un anno. Quindi, un modello addestrato su clienti più vecchi di un anno può funzionare davvero bene per quei clienti, ma non essere accurato quando viene applicato ai clienti ancora in fase di onboarding”, spiega Michael di HubSpot.
- La necessità di spiegare l’output. Quando i rappresentanti dell’azienda (ad esempio i responsabili del successo dei clienti) devono capire le ragioni del churn, possono essere utilizzate le cosiddette tecniche white box come alberi decisionali, foresta casuale o regressione logistica. Una maggiore interpretabilità è una delle ragioni principali per cui HubSpot opta per la foresta casuale. A volte è sufficiente rilevare il churn, per esempio quando il management dell’azienda ha bisogno di stimare il budget per il prossimo anno tenendo conto delle possibili perdite dovute al churn dei clienti. In questi casi, modelli meno interpretabili funzionerebbero.
- Cliente persona. Pensate a un’azienda che fornisce numerosi prodotti, ognuno dei quali è stato progettato per una specifica tipologia di utente. Dal momento che diverse personas di clienti possono avere modelli di comportamento tipici, l’utilizzo di modelli dedicati per prevedere la probabilità che essi sfornino sembra ragionevole. Michael Redbord aggiunge: “In un business in crescita, la natura della base di clienti si evolverà, specialmente quando vengono introdotti nuovi prodotti. I modelli costruiti su una serie di clienti potrebbero non funzionare altrettanto bene quando un nuovo personaggio entra nella base clienti. Così, quando abbiamo introdotto una nuova linea di prodotti, abbiamo tipicamente costruito nuovi modelli per prevedere il churn di quei clienti”.
Deployment e monitoraggio
E ora, la fase finale del flusso di lavoro del progetto di previsione del churn. Il modello o i modelli selezionati devono essere messi in produzione. Un modello può essere incorporato in un software esistente o diventare il nucleo di un nuovo programma. Tuttavia, lo scenario deploy-and-forget non funzionerà: Gli scienziati dei dati devono tenere traccia dei livelli di accuratezza di un modello e migliorarlo se necessario.
“Prevedere l’abbandono dei clienti con l’apprendimento automatico e l’intelligenza artificiale è un processo iterativo che non finisce mai. Monitoriamo le prestazioni del modello e regoliamo le caratteristiche come necessario per migliorare l’accuratezza quando i team a contatto con i clienti ci danno un feedback o nuovi dati diventano disponibili. Nel punto di qualsiasi interazione umana – una chiamata di supporto, un CSM QBR, una chiamata di scoperta delle vendite – monitoriamo e registriamo l’interpretazione umana dell’aiuto al cliente, che aumenta i modelli di apprendimento automatico e aumenta l’accuratezza della nostra previsione di salute per ogni cliente”, riassume Michael.
La frequenza con cui le prestazioni di un modello vengono testate dipende da quanto velocemente i dati diventano obsoleti in un’organizzazione.
Conclusione
Il tasso di abbandono è un indicatore di salute per le aziende basate su abbonamento. La capacità di identificare i clienti che non sono soddisfatti delle soluzioni fornite permette alle aziende di conoscere i punti deboli del prodotto o del piano tariffario, i problemi di funzionamento, così come le preferenze e le aspettative dei clienti per ridurre proattivamente le ragioni del churn.
È importante definire le fonti di dati e il periodo di osservazione per avere un quadro completo della storia dell’interazione con i clienti. La selezione delle caratteristiche più significative per un modello influenzerebbe la sua performance predittiva: Più il set di dati è qualitativo, più le previsioni sono precise.
Le aziende con una grande base di clienti e numerose offerte beneficerebbero della segmentazione dei clienti. Il numero e la scelta dei modelli di ML possono anche dipendere dai risultati della segmentazione. Gli scienziati dei dati hanno anche bisogno di monitorare i modelli implementati, e rivedere e adattare le caratteristiche per mantenere il livello desiderato di accuratezza della previsione.
Originale. Ripostata con permesso.
Originale.