Google Analytics regex (d.w.z. reguliere expressies) is een ondergewaardeerde vaardigheid.
Als u een soort filtering of targeting wilt doen die verder gaat dan de basis, zal een goede greep op regex u Analytics superkrachten geven.

Regex geeft je superkrachten. – image source
Natuurlijk hebben reguliere expressies veel bredere toepassingsmogelijkheden dan analyse en marketing. Maar voor de doeleinden van dit artikel zullen we enkele tactische gebruikssituaties behandelen die u kunnen helpen met gebruikersinzichten, gegevensorganisatie en zelfs geavanceerde targeting en zoekmachinemarketinggebruikssituaties.
Maar laten we eerst kort samenvatten wat reguliere expressies zijn, specifiek in relatie tot Google Analytics.
- Google Analytics RegEx: Wat is het?
- Google Analytics RegEx Cheat Sheet
- Pipe (|)
- Backslash (\)
- Caret (^)
- Dollarteken ($)
- Dot (.)
- Asterisk (*)
- Dot-sterisk-combinatie (.*)
- Plusteken (+)
- Vraagteken (?)
- Parentheses ()
- Haakjes ()
- Streepjes (-)
- Curly brackets ({ })
- Google Analytics RegEx: Specifieke voorbeelden die u kunt gebruiken
- Google Analytics RegEx Tips & Te vermijden fouten
- Naast Google Analytics: RegEx voor andere marketingdoeleinden
- Conclusie
Google Analytics RegEx: Wat is het?
Reguliere expressies zijn speciale tekstreeksen voor het beschrijven van zoekpatronen.
Hoezo?
In relatie tot analytics helpen reguliere expressies u bij het vinden, definiëren en extraheren van zaken. Nog specifieker, met Google Analytics, kunnen ze u helpen flexibelere definities te maken voor zaken als weergavefilters, doelen, segmenten, doelgroepen, inhoudsgroepen en kanaalgroeperingen.
Basically, they are predefined characters or a series of characters that broadly or narrowly matches and selects patterns in your digital analytics data. Het is een algemeen hulpmiddel dat op vele manieren kan worden gebruikt (tal van programmeertalen en tools maken regex mogelijk). Maar in Analytics, gaan we ze vooral gebruiken om patronen in gegevens te matchen.
Het is niet alleen nuttig in Analytics, natuurlijk. Vooral als je een Google Tag Manager gebruiker bent of als je ingewikkelde targeting op je A/B tests uitvoert, zul je veel regex gebruiken. Zoals Chris Mercer, oprichter van MeasurementMarketing.io, zegt:
“We gebruiken regex dagelijks. Het helpt ons om alles duidelijk te definiëren, van trechterstappen in een Google Analytics-doel, tot specifieke triggers in Google Tag Manager.”
Als u echter een diepe duik wilt nemen en echt wilt leren wat reguliere expressies zijn, vindt u hier een paar bronnen (niet noodzakelijk voor basisdingen in Google Analytics, en waarschijnlijk voor iemand met meer technische bekwaamheid):
- Reguliere expressies: The Complete Tutorial
- Mastering Regular Expressions 3rd Edition (Boek)
- Learn Regular Expressions the Hard Way
Je kunt ook interactief leren via iets als RegexOne of RegexR, die beide cool zijn. Maar laten we dat achter ons laten en de meest gebruikte Google Analytics regex-tekens doorlopen, zodat u dit kunt gaan gebruiken.
Google Analytics RegEx Cheat Sheet
Bekijk de volgende Google Analytics regex-tekens als een soort spiekbriefje – u zult ze waarschijnlijk niet meteen gebruiken, maar als u kort doorneemt waartoe u in staat bent met regex, kunt u naar het antwoord zoeken wanneer dat nodig is.
Voor een korte samenvatting heb ik niets gevonden dat meer beknopt en to the point is dan deze gids:

Een zeer beknopte gids voor Google Analytics regex – beeldbron
Hoewel, je kunt zien dat, met dat alleen als referentie, het een beetje vaag en dubbelzinnig is. Laten we daarom de meest gebruikte Google Analytics regex doorlopen en de bijbehorende use-cases laten zien.
Pipe (|)
Wanneer u “OF” wilt zeggen, moet u een pipe (|) gebruiken. Zoals in “This | That”, wat zou betekenen “Dit OF Dat”.
Als u een fervent gebruiker bent van Google Analytics-segmenten, bent u al gewend aan het gebruik van logische OR-operatoren.
Dit is een van de eenvoudigere en meer gebruikelijke reguliere expressies die in Google Analytics worden gebruikt. Het heeft vele toepassingen, hoewel een van de meest gebruikte zou kunnen zijn bij het opzetten van doelen. Als je twee bedankpagina’s hebt met verschillende URL’s (/thank-you/ en /subscription-confirmed/), maar je wilt ze beide bijhouden als een doel voltooiing, dan kun je deze reguliere expressie gebruiken.
Je kunt het ook gebruiken in filters. Stel dat je een gedragsrapport wilt zien over twee artikelen (over Content Marketing Lessen en Content Analytics), met de URLs /content-marketing-analytics/ en /content-marketing-lessons/. U zou als filter kunnen schrijven “content-marketing-analytics|content-marketing-lessons” en alleen die artikelen krijgen.
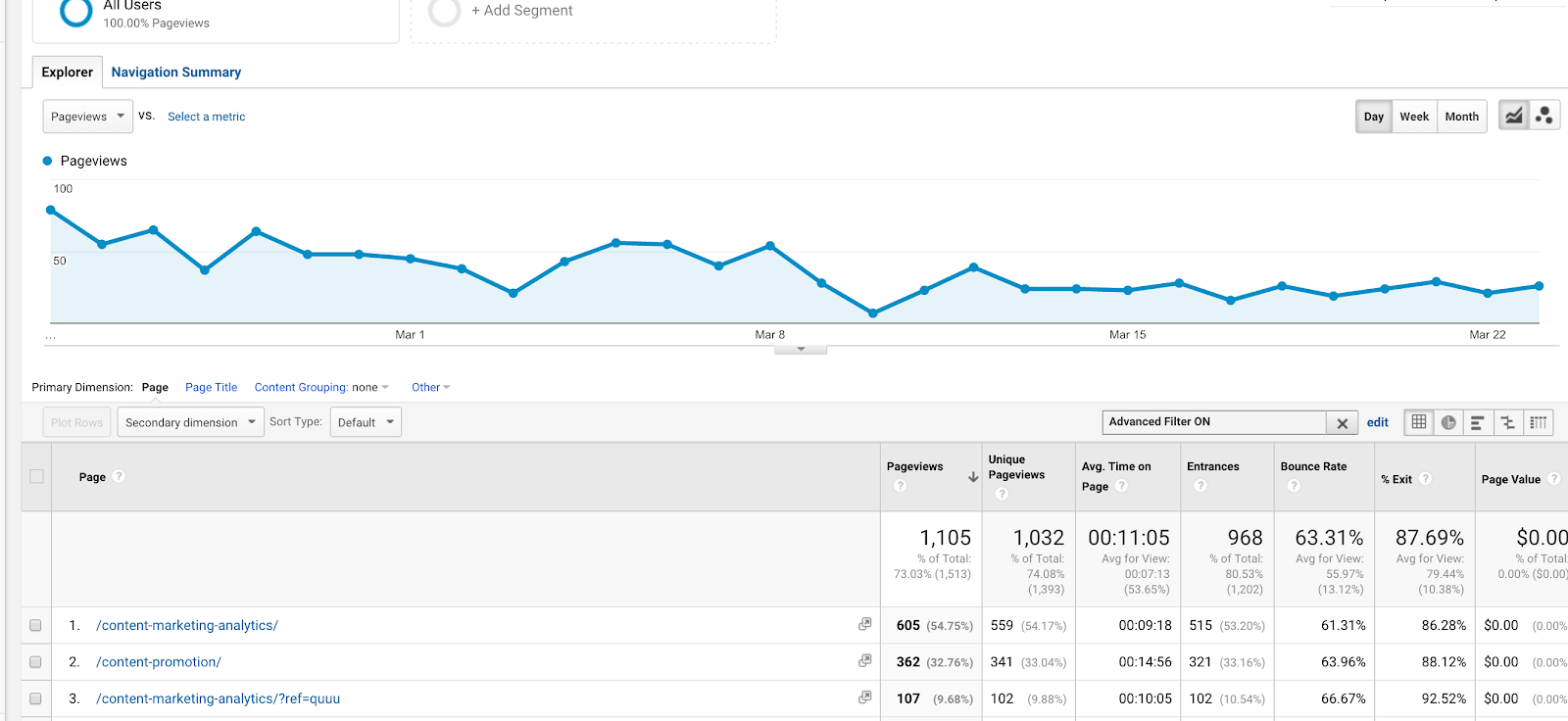
Een pijp (|) in een filter gebruiken om resultaten voor twee afzonderlijke blogberichten te krijgen
Backslash (\)
De backslash (\) is een andere rechttoe rechtaan en veelgebruikte reguliere expressie in Google Analytics. Het betekent “beschouw het volgende teken als gewone tekst en niet als regex.”
Met andere woorden, er zijn veel reguliere uitdrukkingen die in gewone tekst voorkomen, zoals de punt, het vraagteken en andere, waarvan we moeten verduidelijken of ze moeten worden gelezen als reguliere uitdrukkingen of als gewone tekst.
Een veelgebruikte querystring online wordt gebruikt wanneer iemand naar iets op uw site zoekt. Als ik bijvoorbeeld op petsmart.com zoek naar “klein hondenspeelgoed”, is dit de querystring die naar voren komt:
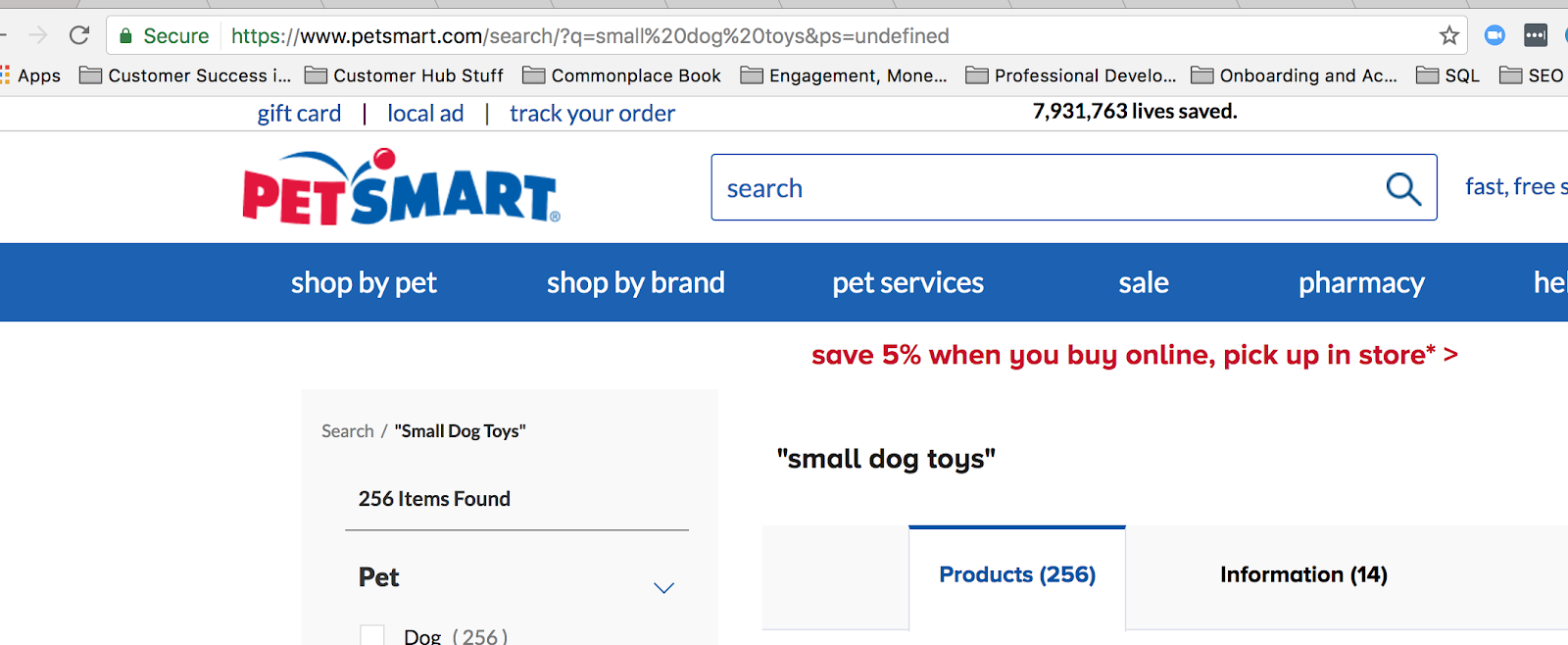
Wanneer u site-zoeken gebruikt, maakt u een querystring in de URL.
Het vraagteken hier geeft aan dat er een on-site zoekopdracht heeft plaatsgevonden, maar het vraagteken is ook een veelgebruikte reguliere expressie in Google Analytics. Daarom moeten we bij het gebruik van een backslash verduidelijken dat in dit geval het vraagteken moet worden gelezen als platte tekst.
Laten we zeggen dat we willen overeenkomen met alle query strings in Google Analytics die beginnen met /search/?q= (want dat betekent een zoekopdracht). Dan zou de reguliere expressie zijn:
search/?q=
U kunt dit controleren met een debugger zoals regex101.com:
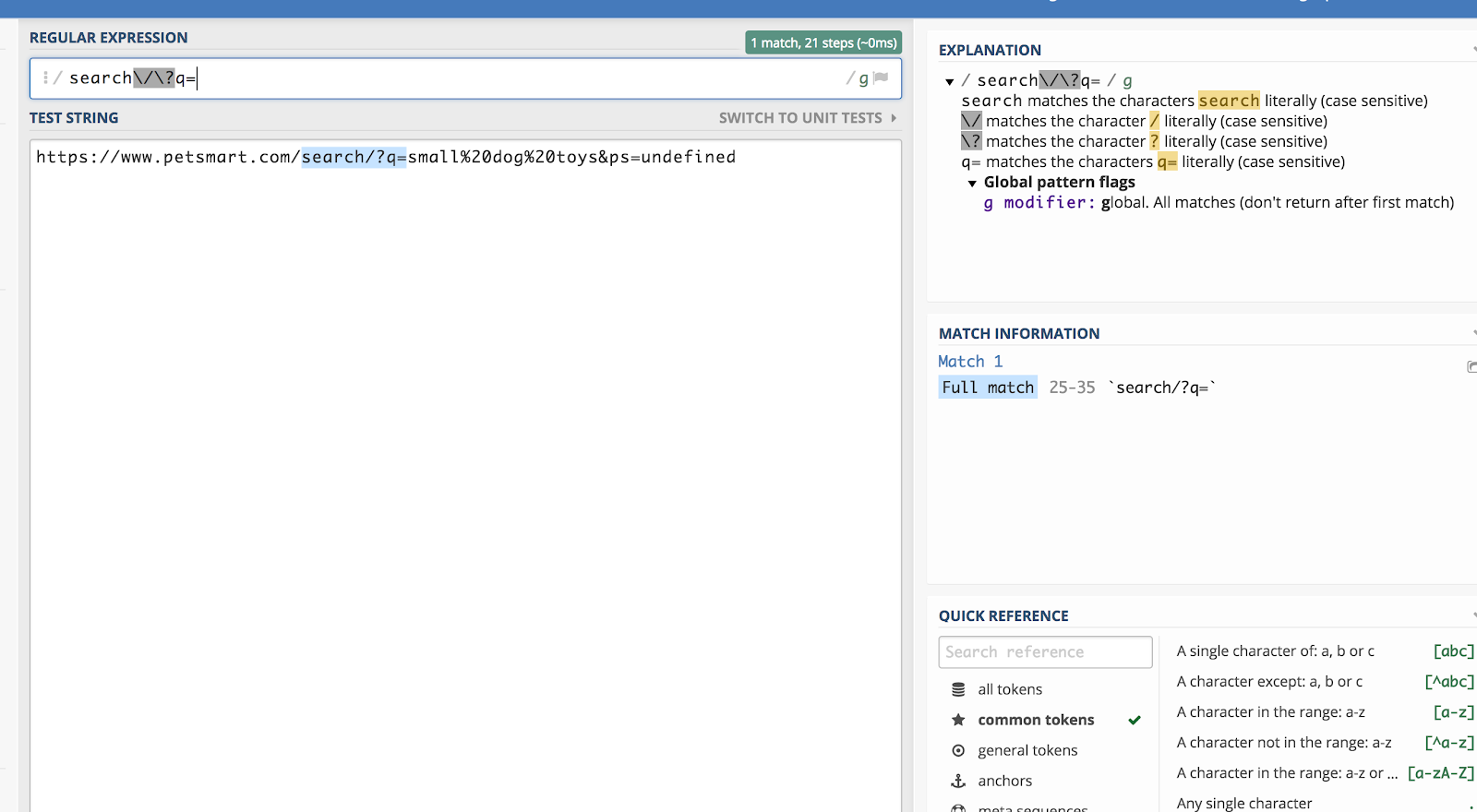
De backslash (^) “ontsnapt” uit de regex voor een karakter erna en leest het als platte tekst.
Caret (^)
Caret (^) betekent dat een zin met iets begint. Dit is belangrijk wanneer je een zin hebt die overal zou kunnen voorkomen, maar je wilt specifiek overeenkomen met de zin op het beginpunt. Kijk bijvoorbeeld eens naar dit voorbeeld van een paar verschillende zinsdelen die de woorden “Missie: geslaagd” bevatten.”
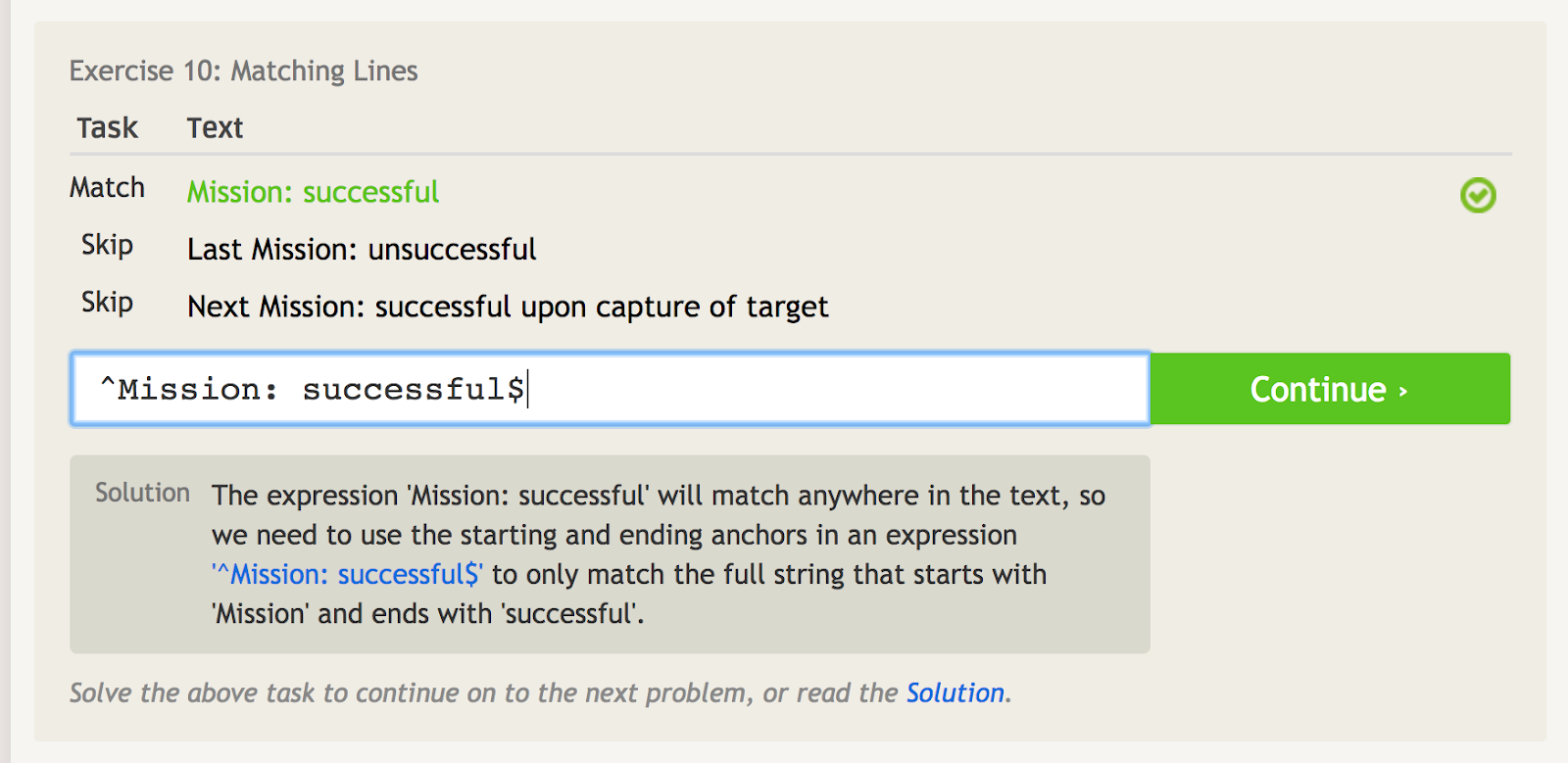
De caret geeft het startanker aan, zodat we alleen met het eerste zinsdeel kunnen overeenkomen.
Stel dat u een heleboel AdWords-campagnes hebt die allemaal met dezelfde zin beginnen (omdat u een slechte planner bent voor de toekomst):
- Freemium Campagne Definitief
- Onze eerste Freemium Campagne
- Creatieve Freemium Campagne aanbieding
- Test Freemium Campagne
Je zou ^Freemium Campagne willen schrijven om overeen te komen met de eerste, en geen van de anderen.
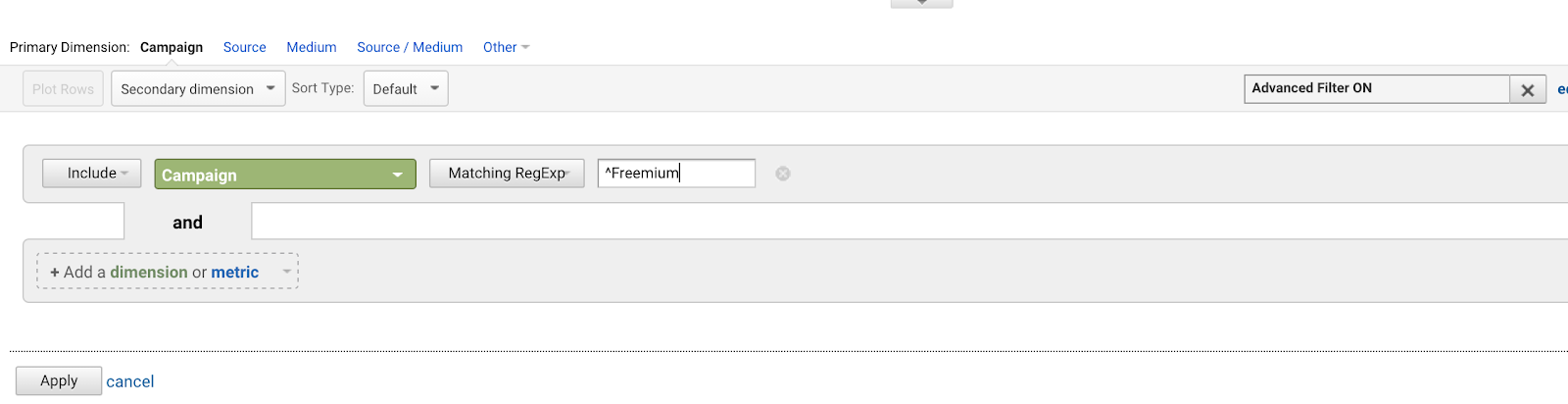
Het gebruik van het teken (^) komt overeen met tekenreeksen die met deze tekens beginnen
Dollarteken ($)
Dollarteken ($) betekent dat een woordgroep met iets eindigt.
Wanneer u de twee combineert, kunt u zich richten op exact overeenkomende woordgroepen.
Als u gestart met een campagne met de titel “paidacquisitionfb” en vervolgens later gestart met een genaamd “paidacquisitionfb-2”, omdat je niet goed van plan vooruit en denk dat je zou hebben andere campagnes met dezelfde titel (gebeurt de hele tijd), kon je isoleren de eerste door te schrijven:
^paidacquisitionfb$
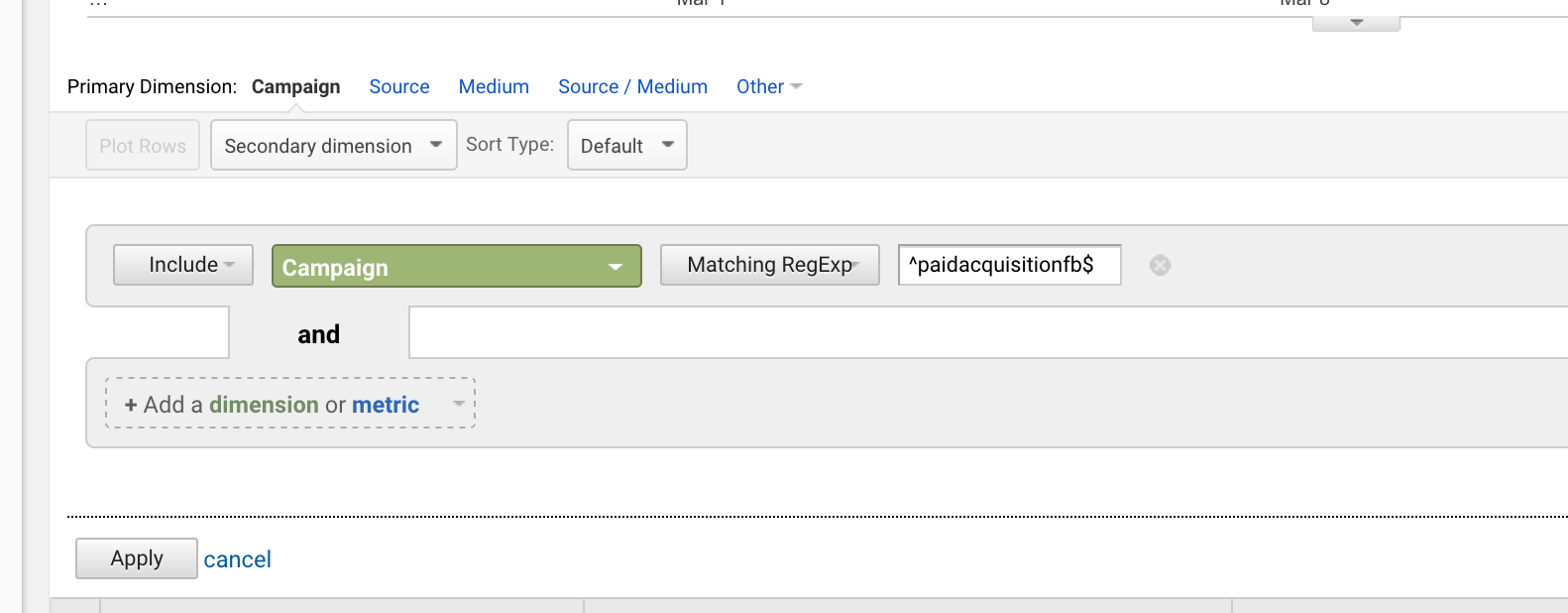
Het gebruik van de carett en de dollar samen is heel gebruikelijk.
Als je bijvoorbeeld tonnen categoriepagina’s op je blog hebt, en ze eindigen allemaal op een paginanummer, dan kun je een simpel stukje Google Analytics regex schrijven om alleen blogcategoriepagina’s (^/page/*/$) weer te geven. Dit zou u lijsten geven als:
- /page/1
- /page/2
- /page/3
…enzovoort.
Dot (.)
Een dot (.) komt overeen met elk teken, wat alles betekent wat u op uw toetsenbord kunt vinden: cijfers, letters, zelfs spaties. Het is op zichzelf niet erg nuttig, maar het wordt vaak gebruikt in combinatie met andere reguliere expressies, vooral de asterisk (komt hierna).
Laten we zeggen dat u het alleen wilt gebruiken, en laten we het voorbeeld “ki..” gebruiken. Dat zou overeenkomen met alles dat begint met de letters K en I, en dan de volgende twee tekens, wat ze ook zijn.
Dus als je een tekenreeks had met de woorden kill, kind, kiss, kin, kid!, en kit, zou het met ze allemaal overeenkomen. Wacht, wat? Ja, het zou overeenkomen met “kit” en “kin” zolang er een spatie achter staat (het pikt ook de spaties op). Als je die logica volgt, zou het ook het uitroepteken in “kid!” oppikken.
Je ziet waarom het rommelig wordt als je deze alleen gebruikt.
Hier is een illustratie van het bovenstaande voorbeeld met Regex101.com:
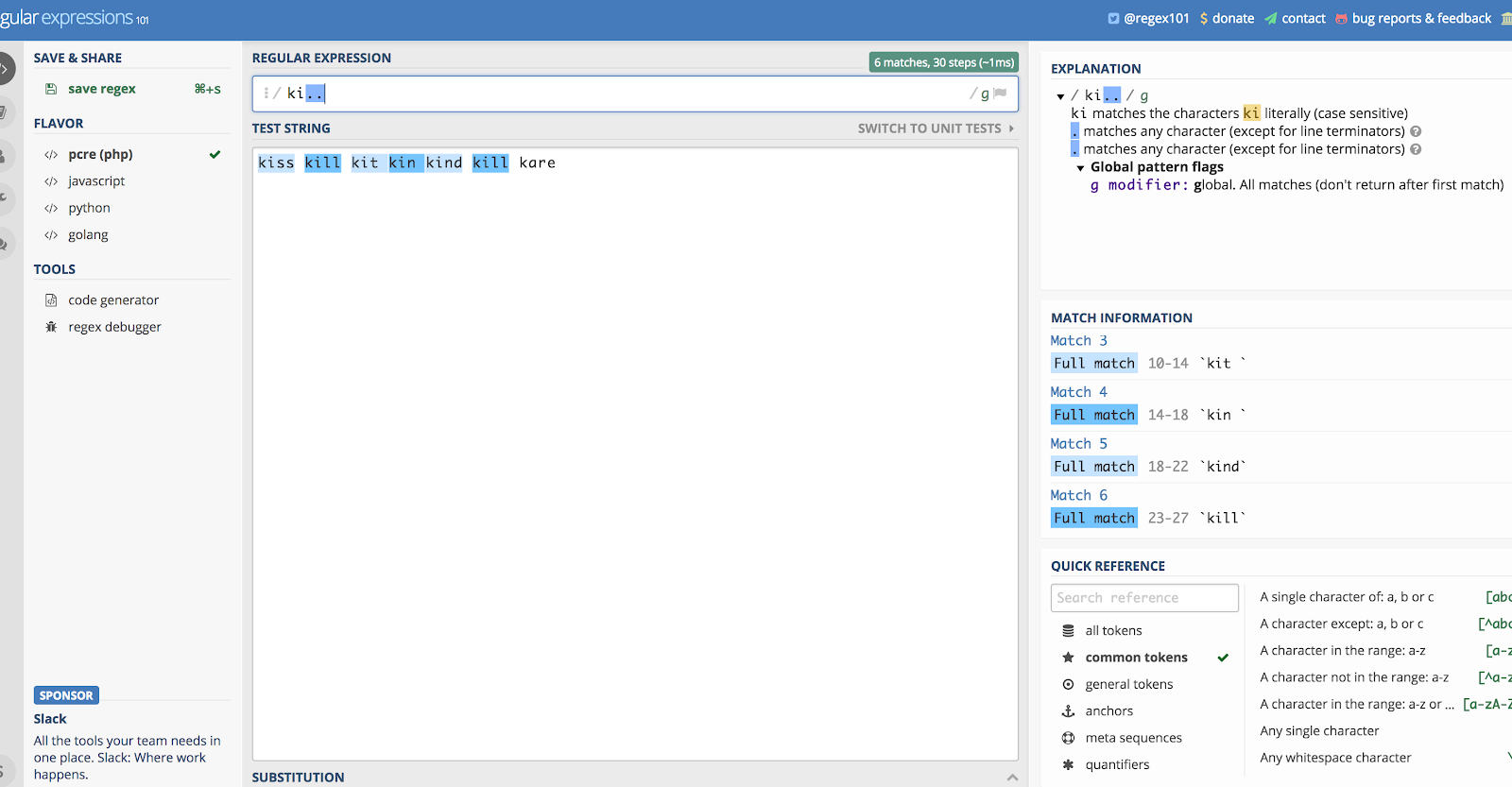
De punt (.) komt overeen met bijna alles.
Asterisk (*)
De asterisk (*) komt overeen met nul of meer van de vorige items. Beetje verwarrend als je het zo stelt, dus ik zal een voorbeeld gebruiken.
Herinner je je die “wazzup” reclame van Budweiser van een tijdje geleden? Het zou vrij moeilijk zijn om te raden hoe iemand die zin zou spellen als hij ernaar zou zoeken (bijvoorbeeld op YouTube). Maar je zou theoretisch alle spellingsvariaties kunnen inkapselen door dit te doen:
waz*up
Hier volgt een illustratie van hoe dat uitwerkt in regex101:
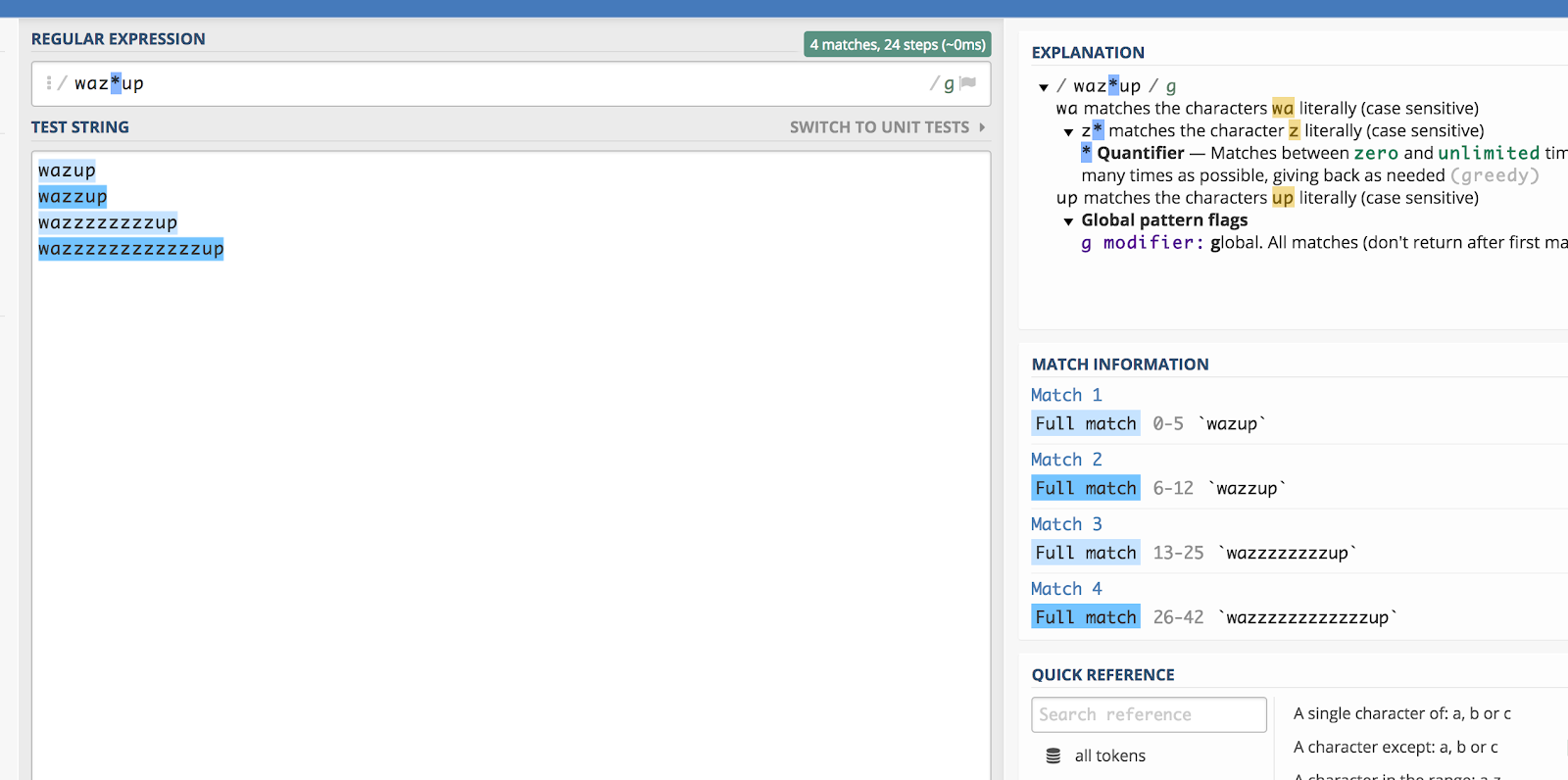
De asterisk (*) komt nul of meer keer overeen met het vorige teken.
Als u supernauwkeurig wilt zijn en rekening wilt houden met hoofdletters en kleine letters, kunt u iets als dit schrijven:
*
Maar ik dwaal af.
Waar de asterisk eigenlijk het krachtigst is en vaker wordt gebruikt, is met een punt of als onderdeel van andere regex-combinaties.
Dot-sterisk-combinatie (.*)
De punt-sterisk-combinatie (.*) betekent eigenlijk dat alles kan. Het wordt heel vaak gebruikt.
U zou deze combinatie gebruiken als u wilt overeenkomen met alles in een tekenreeks. Omdat de punt elk teken betekent, en de * betekent nul of meer tekens ervoor, is deze combinatie zeer krachtig.
Voorbeeld: u hebt verschillende soorten klantaccounts, maar u wilt uw gegevens voor al die accounts zien. Ze hebben allemaal vergelijkbare pagina’s, dus uw pagina’s zien er ongeveer zo uit:
/customer/pro/login/
/customer/free/login/
/customer/starter/login/
U kunt de volgende regex schrijven om dat te doen:
/customer/.*/login
Ik gebruik deze Google Analytics regex expressie vaak om segmenten in te stellen voor gebruikers met een gebruikers-ID.
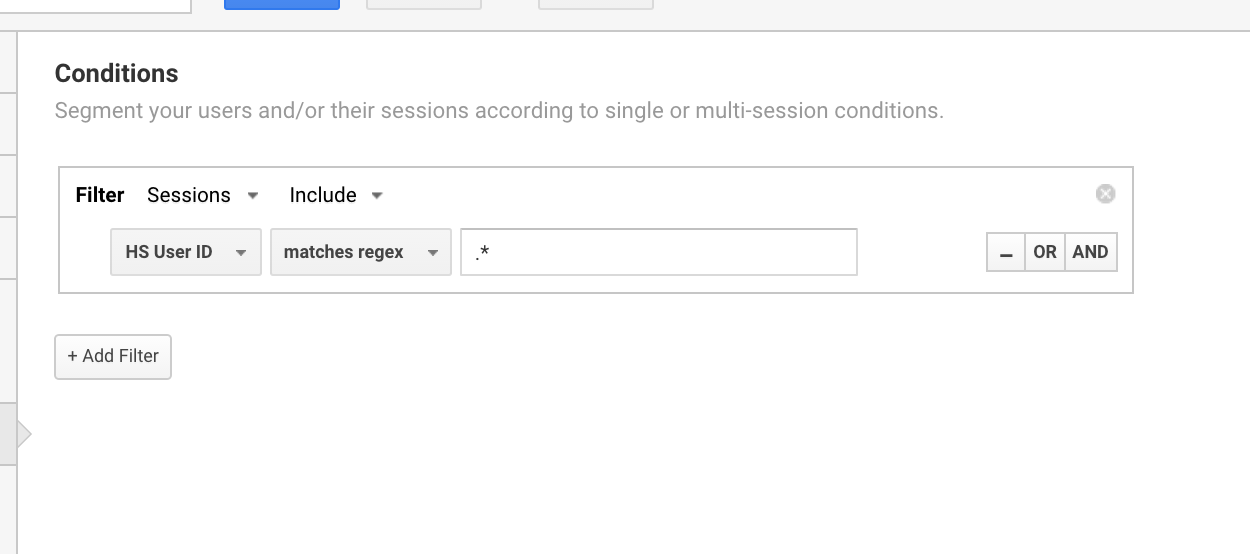
Google Analytics regex gebruiken om alle sessies te isoleren die een gebruikers-ID hebben.
Plusteken (+)
Het plusteken (+) lijkt erg op de *, behalve dat het overeenkomt met ÉÉN of meer van de vorige tekens. Hier hoeft niet veel meer over gezegd te worden, alleen dat het heel iets anders is dan de asterisk. Hier is het verschil:
Stel je voor je hebt de woorden: hallo, hhello, en hhhello.
Als je hh+ello schrijft, zal het alleen overeenkomen met de tweede twee, maar als je hh*ello schrijft, zal het met allemaal overeenkomen.
Minor onderscheid. In werkelijkheid gebruik ik bijna altijd het sterretje in plaats van het plusteken.
Vraagteken (?)
Het vraagteken (?) is een makkelijke. Het betekent gewoon dat het laatste teken een optie is.
Zeg dat het u niet veel kan schelen of het woord meervoud is of niet (zoals bij schoenen). Het kan “schoen” of “schoenen” zijn, en je wilt het in beide gevallen vastleggen. Dan kun je schrijven “schoenen?”
Hier een voorbeeld met mijn naam. Als iemand tijdens het zoeken op de site de spelling “Alex Birket” zou gebruiken, zou ik die waarschijnlijk toch willen zien. Dus ik kan schrijven:
Alex Birkett?
Hier ziet het er zo uit in regex101.com:
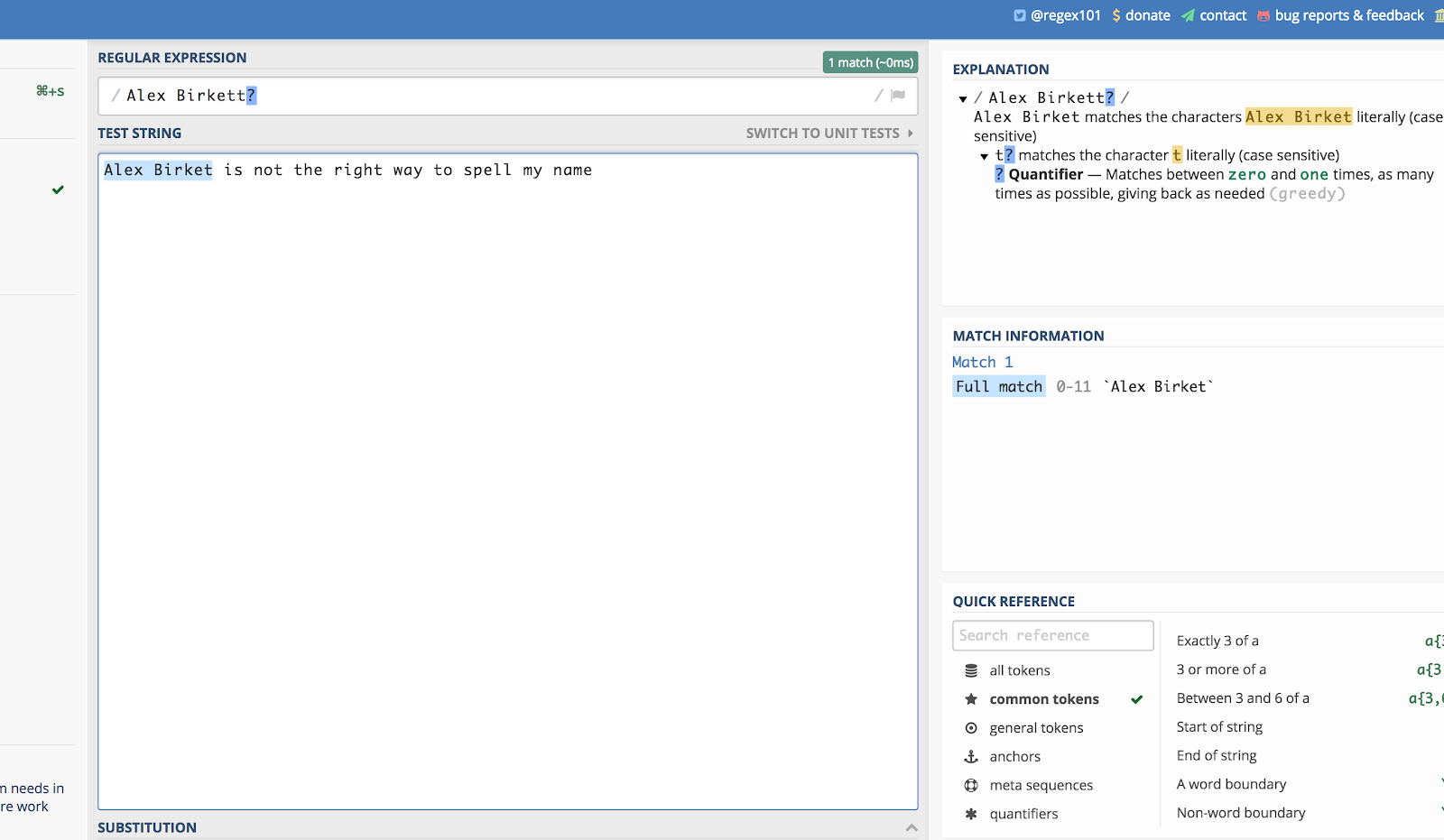
Het vraagteken (?) maakt het zo dat het laatste teken dat eraan voorafgaat optioneel is.
Parentheses ()
Parentheses werken op dezelfde manier als in de wiskunde. Ze vertellen u om prioriteiten te stellen en de logica te isoleren die binnen hen in het spel is.
Laten we zeggen dat u een SaaS-bedrijf hebt met drie aanbiedingen en u wilt al uw prijspagina’s op elkaar afstemmen. Uw URL’s zijn als volgt:
site.com/products/meetings/pricing
site.com/products/crm/pricing
site.com/products/email/pricing
Om deze alle drie te pakken te krijgen, zou u een reguliere expressie als deze kunnen gebruiken:
^/products/(meetings|crm|email)/pricing$
Haakjes ()
Haakjes () maken een lijst. Als je drie strings hebt, “ding1,” ding2,” en “ding3,” kun je ze allemaal vergelijken door “ding” of “ding” te schrijven (meer over streepjes straks – ze worden vaak gebruikt met vierkante haakjes.
Zuizige haakjes kunnen worden gebruikt om verschillende iteraties van een woord of string te vergelijken, terwijl ze ook verschillende andere iteraties uitsluiten. Als je bijvoorbeeld “can”, “man” en “fan” wilt gebruiken, maar niet “dan”, “ran” of “pan”, dan kun je de volgende regex gebruiken om dat te doen:
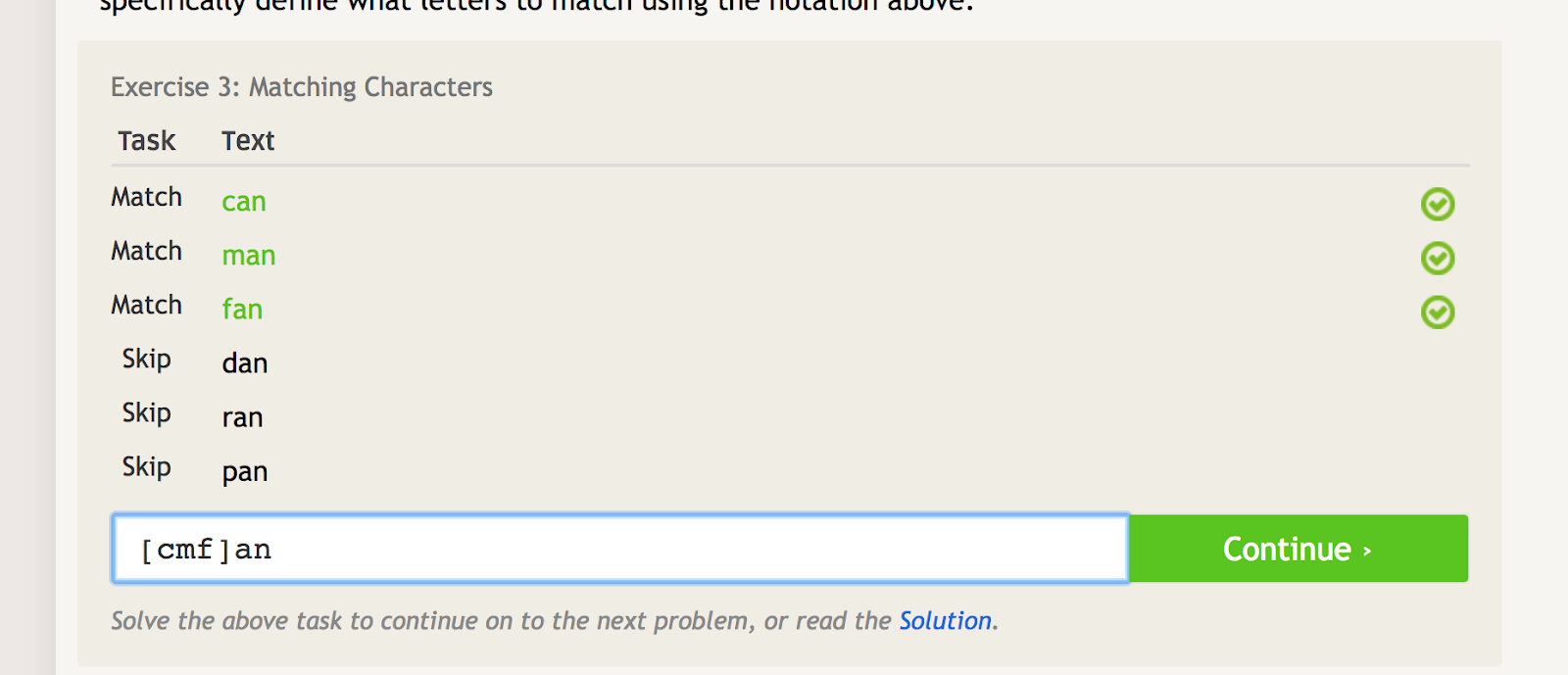
Door middel van vierkante haakjes kunnen verschillende voorwaarden worden ingesteld, afhankelijk van de tekens die u erin zet. – image source
Dit kunt u gebruiken als u een aantal verschillende producten hebt met vergelijkbare namen, zoals “shoes1,” shoes3,” en “shoes5.” U zou die kunnen vergelijken, en niets anders, met “schoenen”
Streepjes (-)
Streepjes (-) werken om lineaire lijsten van items te maken.
Zoals in, wanneer u vierkante haken gebruikt, hoeft u niet eenvoudigweg alles op te sommen als het lineair voorkomt. Dus als u een reeks getallen wilt vergelijken waarvan het laatste getal van nul tot en met negen kan zijn, kunt u dit schrijven:
1234
Of u kunt het veel eenvoudiger schrijven:
1234
Dit werkt ook voor letters. Stel u heeft een pagina categorie die eindigt op twee willekeurige letters. Zoiets als dit:
/page-aa/
Die kunt u allemaal matchen door te schrijven:
/page-*/
U kunt hier een voorbeeld zien op regex101:
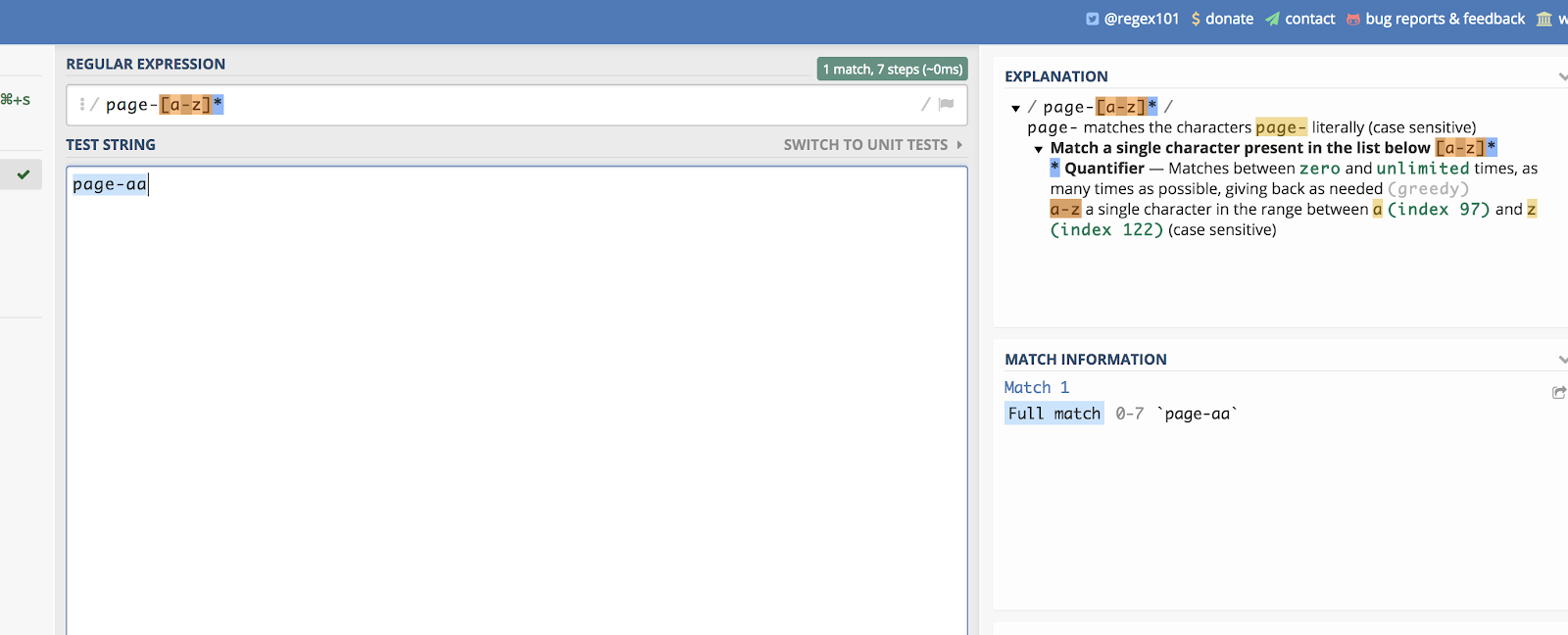
Dashen helpen u een lineaire lijst te maken om te matchen.
Curly brackets ({ })
Curly brackets ({}) vertellen u hoe vaak u het laatste item moet herhalen.
Als u bijvoorbeeld alleen “wazzzzup” wilt, kunt u “waz{4}up” gebruiken.
Maar als u “wazzzzzup,” en “wazzzup,” maar niet “wazup” wilt, kunt u “waz{3,5}up” gebruiken. Dit komt erop neer dat u het teken “z” niet minder dan 3 keer, maar niet meer dan 5 keer wilt laten overeenkomen.
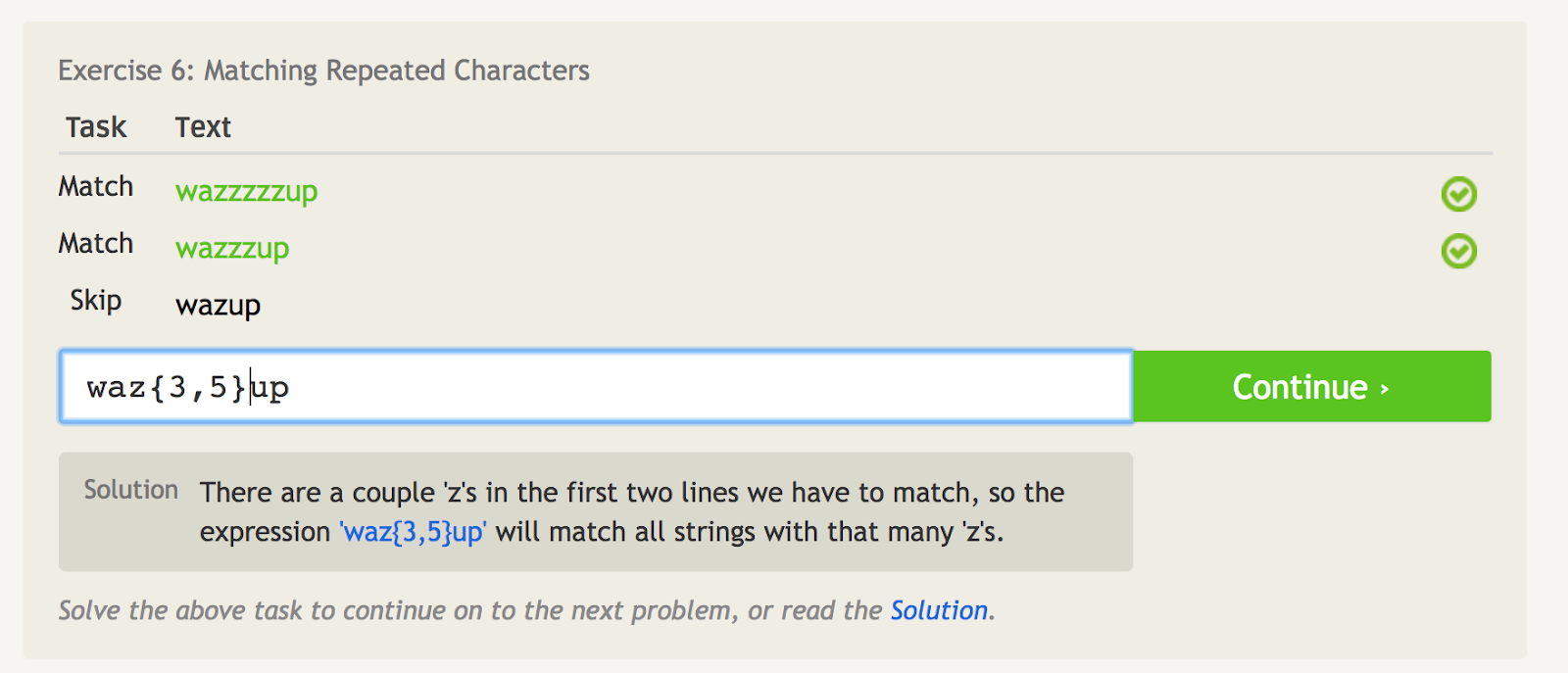
Krullende haakjes vertellen u hoe vaak u het laatste item moet herhalen. – afbeeldingsbron
Ik heb deze reguliere uitdrukking niet echt veel gebruikt in Google Analytics, maar een veelgebruikt geval zou kunnen zijn voor postcodes. Meestal zijn de eerste twee tekens hetzelfde in een stad (78- voor Austin, TX, bijvoorbeeld). U kunt dus elke postcode in Austin TX matchen door te schrijven:
78{3}
Dit zegt dat de laatste drie letters elk willekeurig getal van nul tot negen kan zijn.
Google Analytics RegEx: Specifieke voorbeelden die u kunt gebruiken
Eén van de meest voorkomende Google Analytics regex use cases is het bouwen van filters. Laten we drie voorbeelden doorlopen, een eenvoudige en een iets ingewikkelder.
Eerst een voorbeeld geïnspireerd door een geweldige post op Search Engine Land door Jenny Halasz.
Stel dat je een rommelige site-architectuur hebt, maar je wilt kijken naar alle berichten met een bepaalde subdirectory. Dat kan van alles zijn, bijvoorbeeld een site categorie of type inhoud. In dit voorbeeld zoeken we naar een categorie op de site voor /music/, maar alleen in de derde subdirectory. In dit geval kunt u ^/.*/.*/music/.* schrijven en het zal u dat rapport geven.

Deze Google Analytics regex zal u alleen /music/ in de derde subdirectory laten zien. – image source
Het ziet er op het eerste gezicht verwarrend uit – maar nadat u hebt geleerd wat deze reguliere expressies betekenen, is het vrij eenvoudig. In principe vertellen we GA gewoon om landingspagina te matchen die begint met (^) een schuine streep, dan alle tekens (.*), dan een schuine streep, dan alle tekens (.*), dan een schuine streep, en dan muziek.
LawnStarter gebruikt een vergelijkbare tactiek voor rapportage. Hun strategie is om stadsspecifieke inhoud te maken in een submap van hun stadspagina’s, met het volgende formaat:
https://www.lawnstarter.com/{{ transactionele stadspagina }}/{{informatief inhoudsstuk }}
Om de inhoud uit conversietrechters en verkeersrapportage te filteren, gebruiken ze de volgende regex, volgens oprichter Ryan Farley.
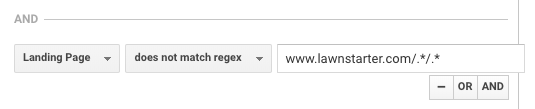
Deze regex helpt LawnStarter bij het matchen van stadsspecifieke inhoud op hun site.
Op de tweede plaats laten we eens zien hoe u een filter kunt instellen voor een van uw Google Analytics-weergaven. Het is waarschijnlijk dat je een implementatie specialist hebt die dit doet-maar zo niet, meet altijd twee keer en knip een keer hier. Het is gemakkelijk om deze dingen te verknoeien (dat is ook de reden waarom u uw Google Analytics-account moet instellen met een zandbakweergave om dingen eerst uit te proberen).
Om filters in te stellen, gaat u naar Admin > Filters > Filter toevoegen.
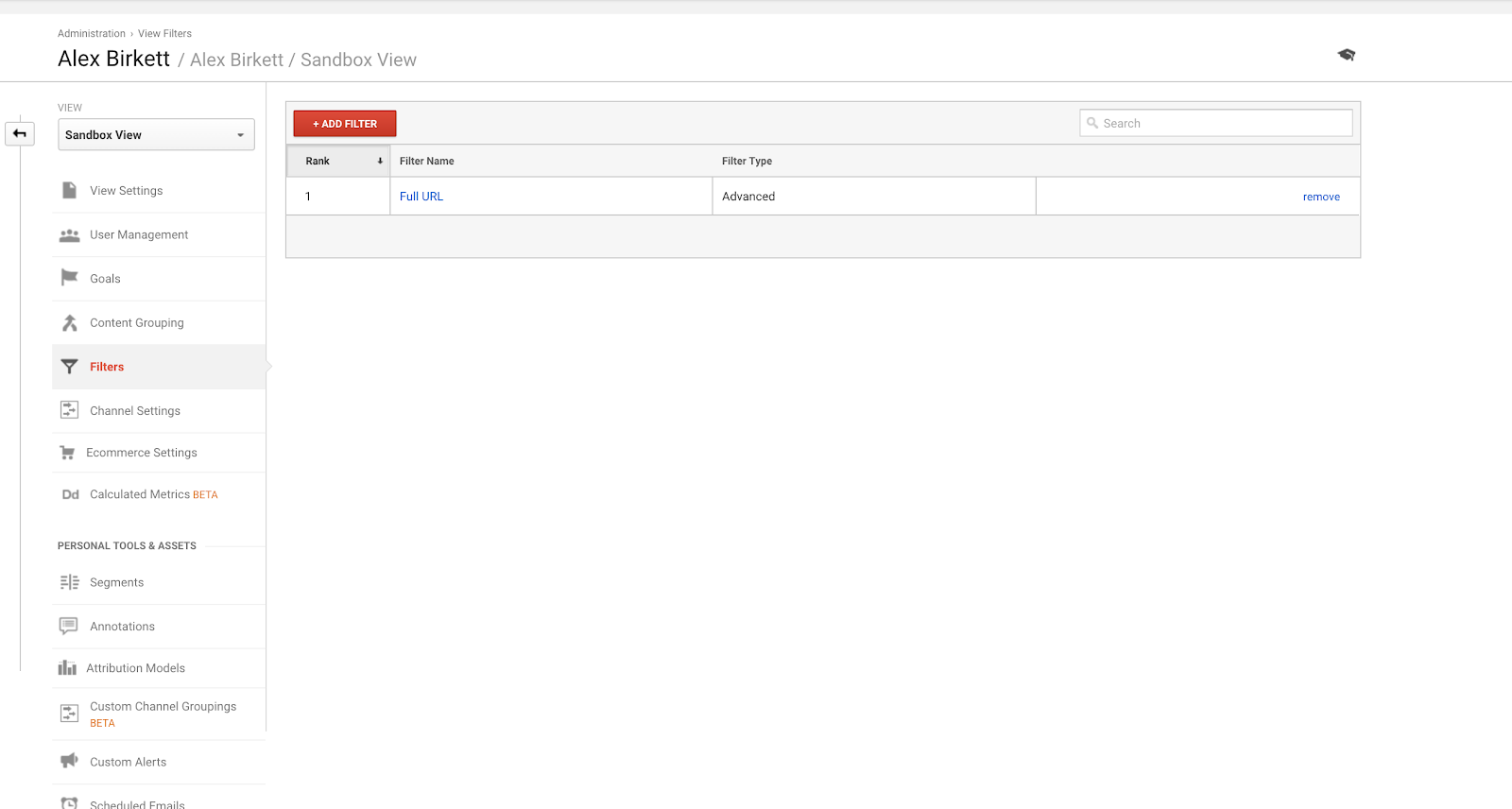
Het meest gebruikte filter in Google Analytics is waarschijnlijk om verkeer van uw eigen IP-adres(sen) uit te sluiten.
Voor velen kunt u dit eenvoudig instellen, omdat u maar één IP-adres hebt. Voor grotere bedrijven heeft u misschien een reeks IP’s, en kunt u gemakkelijker uitsluitingen instellen met Google Analytics regex.
Als u bijvoorbeeld 63.212.171.171 zou schrijven, zou dat alle IP-adressen uitsluiten van 63.212.171.1 tot 63.212.171.9.
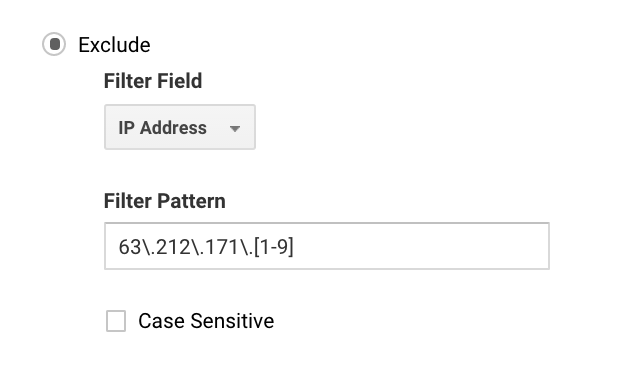
Deze Google Analytics regex sluit meerdere IP-adressen uit.
Een ander ding dat u kunt doen met Google Analytics regex is filters instellen om queryparameters op te schonen.
Dit kan zowel vervelend als problematisch zijn voor uw gegevensanalyse.
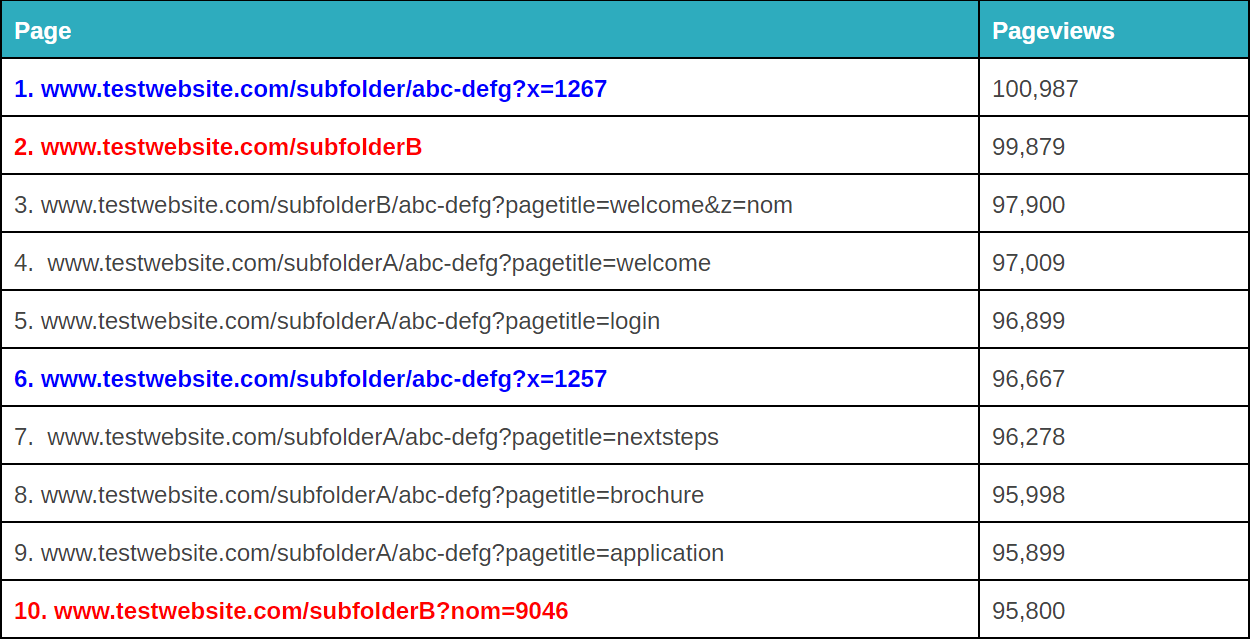
Gefractioneerde queryparameters kunnen vervelend zijn. – image source
Het zal afhangen van hoe uw specifieke situatie is, maar er zijn een paar verschillende manieren waarop u regex kunt gebruiken om dat op te ruimen (opmerking: u kunt dit ook doen in Google Tag Manager of Excel, afhankelijk van de omvang van het probleem. Meer daarover hier).
Laten we het tot slot hebben over een voorbeeld dat we kunnen gebruiken om onze subdomeintracking beter te organiseren. Als je meerdere domeinen of subdomeinen hebt, is het mogelijk dat je dubbele URL’s hebt, tenzij je een filter instelt om je hostnaam aan je URi verzoek toe te voegen. Met andere woorden, u zou twee URL’s kunnen hebben:
- site.com/about
- blog.site.com/about
Deze vertegenwoordigen twee verschillende pagina’s (de ene is een pagina over uw bedrijf en de andere is een about sectie voor uw blog). Maar ze zouden allebei in Google Analytics worden gezien als /about, tenzij u het volgende filter instelt (met behulp van dot-asterisk-combinatie Google Analytics reguliere expressies):
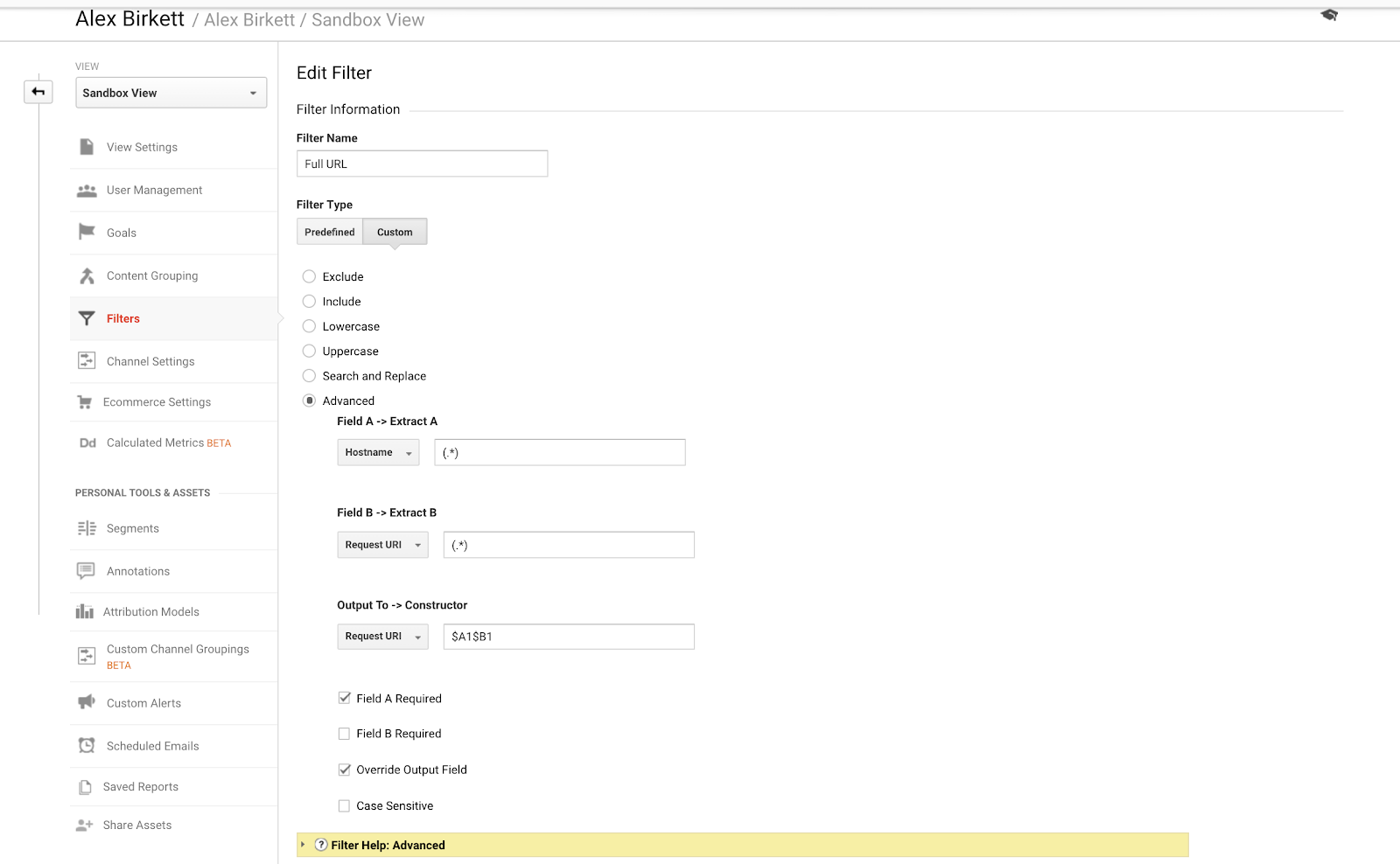
Het is vrij eenvoudig om dit fundamentele GA-filter in te stellen. – image source
We hebben in een eerdere KlientBoost-publicatie over cross-domain en subdomain tracking al uitvoerig besproken hoe u deze filters kunt instellen.
Google Analytics RegEx Tips & Te vermijden fouten
Reguliere expressies zijn een van die dingen die je gewoon moet oefenen en waarvoor je je handen vies moet maken om ze te leren. Als zodanig zul je fouten maken.
Dat is eigenlijk de belangrijkste tip: probeer dingen uit en kijk of ze werken. Ik heb een lijst van tonnen bronnen in dit bericht over hoe je je regex te testen, van regex101.com naar regexbuddy.com. Dompel je tenen erin en gebruik deze bronnen.
Maar met wat voorkennis en heuristiek, kun je sneller leren en meer fouten opmerken.
Eén ding om echt te leren is hoe je moet “escapen” in regex (we hebben het hier over gehad met de backslash). Leho Kraav, CTO bij CXL Institute, formuleert het als volgt:
“Ik zou zeggen “leer over het op de juiste manier escapen van dingen” – het is gemakkelijk om mismatches te krijgen wanneer de tekens hetzelfde zijn, maar hun betekenis anders is, afhankelijk van het al dan niet escapen.”
Als uw query bijvoorbeeld een vraagteken bevat, is dat ook een reguliere expressie, dus u moet dat duidelijk maken met de backslash. Chris Mercer, oprichter van MeasurementMarketing.io, zegt ook dat het niet leren van deze mogelijkheid een van de grootste fouten is die hij beginners ziet maken:
“De meest voorkomende fout die we zien bij beginners die regex gebruiken, is dat ze vergeten regex-symbolen te “escapen”. Als je bijvoorbeeld zoekt naar pagina’s die overeenkomen met regex “thankyou/?success=yes”, dan zal dat niet werken. De “?” zelf is een regex symbool, en moet gedeactiveerd worden door het “escape karakter” te gebruiken (de ” “. In dit geval zou “thankyou/key?succes=yes” werken.”
Een andere tip? Hou het simpel. Mensen proberen het ingewikkeld te maken (bekijk hier de meest ingewikkelde regex die je ooit hebt gezien, geschreven door Leho), maar reguliere expressies zijn “hebzuchtig” en zullen zoveel mogelijk overeenkomen als ze kunnen. Google Analytics heeft een blog met tips gepubliceerd en legt het als volgt uit:
“Als u een expressie moet schrijven om overeen te komen met “nieuwe bezoeken” en de enige opties waarmee u overeenkomt zijn “nieuwe bezoeken” en “herhalingsbezoeken”, is alleen het woord “nieuw” goed genoeg.
Ze komen overeen met alles wat ze maar kunnen, tenzij u ze dwingt dat niet te doen. Als uw uitdrukking “bezoeken” is, zal het overeenkomen met “nieuwe bezoeken” en “herhalingsbezoeken”. Ze bevatten immers allebei de uitdrukking “bezoeken”. Om ze minder gulzig te maken, moet je ze specifieker maken.”
Dus begin langzaam, houd het simpel, en overstelp jezelf niet met complexiteit (de kans op fouten correleert in dit geval met complexiteit).
Mercer herhaalt dit punt ook, en adviseert om dingen geleidelijk aan te doen:
“Als je voor het eerst begint, concentreer je dan op goed worden… en word dan beter. Het is gemakkelijk om overweldigd te raken door alle verschillende mogelijkheden die regex je biedt, maar als je gewoon met de basis begint, zoals het onder de knie krijgen van het symbool voor “of” (de ” | “), krijg je snel ervaring en begin je te beseffen wat er allemaal mogelijk is met regex.”
Eindtip van mij: leer om dingen te Googlen. Dit geldt voor elke programmering, maar vooral voor reguliere expressies. Je gaat dingen vergeten, en als je niet dagelijks regex schrijft, heeft het niet echt zin om alles uit je hoofd te leren. Leer om dingen op te zoeken en antwoorden te vinden op wat u probeert te doen.
Naast Google Analytics: RegEx voor andere marketingdoeleinden
Regex is ook iets waar alle SEO’ers zich in zouden moeten verdiepen. Ten eerste, natuurlijk, omdat SEO en digitale analyse (bijv. Google Analytics) onlosmakelijk met elkaar zijn verweven. Ten tweede omdat sommige van dezelfde overeenkomende expressies die we schrijven om tekens op onze Google Analytics-gegevens te filteren en te matchen, ook kunnen worden gebruikt bij gegevensextractie voor SEO-tactieken.
Met andere woorden, reguliere expressies zijn belangrijk voor web scraping.
In het geval van web scraping en SEO, zul je meestal werken via een programmeertaal zoals Python, maar de principes zijn hetzelfde.
Als voorbeeld zou je alle vetgedrukte tekst op een pagina kunnen schrapen door dit te gebruiken:
<strong>(+)</strong>
Of zoals vermeld in dit SEJ-artikel, als je ESPN voor alle auteurs zou schrapen, zou je dit kunnen schrijven:
“columnist”:”(.*?)”
Omwille van de samenhang en gezond verstand zal ik me niet helemaal verdiepen in geavanceerde webschrapping. Het volstaat te weten dat regex ook op dit gebied belangrijk is. Als u echter meer wilt leren, raad ik u deze bronnen aan:
- Web Scraping with Regular Expressions
- Scraping with Regular Expressions (Stanford)
- Hoe Regex te gebruiken voor SEO & Website Data Extraction
Reguliere expressies helpen u ook om met uw SEO-gegevens te werken, verder dan alleen het web schrapen. U kunt bijvoorbeeld regex gebruiken om verder aan te passen hoe u Screaming Frog gebruikt.
Jenny Halasz gaf een goed voorbeeld van het gebruik van regex om gegevens op te schonen in een Search Engine Land post:
“Laten we bijvoorbeeld zeggen dat je een lijst met URL’s hebt en je moet ze opsplitsen in alleen de TLD (Top Level Domain).
U kunt een eenvoudige find/replace gebruiken voor http en www, maar hoe kunt u eenvoudig alle bestandsnamen verwijderen? Je zou ze allemaal handmatig kunnen verwijderen, maar dat is lastig. Door een simpel regex wildcard (/*) te gebruiken, kun je de slash en alles wat er achter komt laten vallen.”
We zouden het eeuwig kunnen hebben over reguliere expressies voor SEO en web scraping, maar ik zal alleen maar linken naar een aantal goede bronnen voor het geval u meer wilt leren (het is tenslotte een zeer veelzijdige taal, met veel gebruikssituaties buiten analytische doeleinden):
- Hoe reguliere expressie SEO beïnvloedt
- 5 Geweldige Htaccess Redirect Tricks
- Hoe reguliere expressie te gebruiken voor rapportsegmentatie
Conclusie
Google Analytics regex is echt iets dat elke analist zou moeten weten, zelfs als je jezelf niet als technisch beschouwt. Buiten dat, het kennen van een aantal reguliere expressies (of op zijn minst hoe te zoeken naar antwoorden en ze toe te passen op de juiste problemen) kan marketeers ook helpen met verschillende activiteiten.
Just zeggen, het is niet een heel gebruikelijke vaardigheden, dus je zult waarschijnlijk indruk maken op een aantal collega’s met je pas ontdekte technische marketing vaardigheden.
Dus ik dring er bij u op aan, begin te leren, en nog belangrijker, begin gewoon te oefenen met het gebruik van reguliere expressies. Zo eng zijn ze niet.