Google Analytics regex (tj. wyrażenia regularne) jest niedocenianym zestawem umiejętności.
Jeśli chcesz wykonać jakikolwiek rodzaj filtrowania lub targetowania poza podstawami, dobre uchwycenie regex da ci supermoce Analytics.

Regex daje ci supermoce. – image source
Oczywiście, wyrażenia regularne mają znacznie szersze przypadki użycia niż analityka i marketing. Jednak na potrzeby tego artykułu, zajmiemy się kilkoma taktycznymi przypadkami użycia, które mogą pomóc w spostrzeżeniach użytkowników, organizacji danych, a nawet zaawansowanym targetowaniu i marketingu w wyszukiwarkach.
Na początek jednak, krótko podsumujmy czym są wyrażenia regularne, szczególnie w odniesieniu do Google Analytics.
- Google Analytics RegEx: What is It?
- Google Analytics RegEx Cheat Sheet
- Rurka (|)
- Odwrotny ukośnik (\)
- Karet (^)
- Znak dolara ($)
- Kropka (.)
- Gwiazdka (*)
- Kombinacja kropka – gwiazdka (.*)
- Znak plusa (+)
- Znak zapytania (?)
- Parentezy ()
- Nawiasy kwadratowe ()
- Kreski (-)
- Nawiasy klamrowe ({ })
- Google Analytics RegEx: Konkretne przykłady, których możesz użyć
- Google Analytics RegEx Tips &Błędy, których należy unikać
- Outside of Google Analytics: RegEx for Other Marketing Uses
- Conclusion
Google Analytics RegEx: What is It?
Wyrażenia regularne to specjalne ciągi tekstowe do opisywania wzorców wyszukiwania.
Huh?
W odniesieniu do analityki, wyrażenia regularne pomagają znaleźć, zdefiniować i wydobyć rzeczy. Nawet bardziej szczegółowo, w Google Analytics, mogą one pomóc w tworzeniu bardziej elastycznych definicji dla takich rzeczy jak filtry widoku, cele, segmenty, grupy odbiorców, grupy treści i grupy kanałów.
Podstawowo, są to predefiniowane znaki lub serie znaków, które szeroko lub wąsko pasują i wybierają wzorce w danych analityki cyfrowej. Są one ogólnym narzędziem, które można wykorzystać na wiele sposobów (mnóstwo języków programowania i narzędzi pozwala na regex). Ale w Analytics, będziemy głównie używać ich do dopasowywania wzorców w danych.
Nie jest to tylko przydatne w Analytics, oczywiście. Szczególnie, jeśli jesteś użytkownikiem Google Tag Managera lub jeśli stosujesz skomplikowane targetowanie w swoich testach A/B, będziesz używał wielu regexów. Jak mówi Chris Mercer, założyciel MeasurementMarketing.io:
„Używamy regexu na co dzień. Pomaga nam to jasno zdefiniować wszystko, od kroków lejka w celu Google Analytics, do konkretnych wyzwalaczy w Google Tag Manager.”
Jednakże, jeśli chciałbyś zrobić głębokie nurkowanie i naprawdę nauczyć się wyrażeń regularnych, oto kilka zasobów (nie jest to konieczne dla podstawowych rzeczy w Google Analytics, i prawdopodobnie dla kogoś o większej biegłości technicznej):
- Regular Expressions: The Complete Tutorial
- Mastering Regular Expressions 3rd Edition (Book)
- Learn Regular Expressions the Hard Way
Możesz również uczyć się interaktywnie poprzez coś takiego jak RegexOne lub RegexR, z których oba są fajne. Ale przejdźmy obok tego i przejdźmy przez najczęściej używane znaki regex Google Analytics, więc możesz zacząć to wykorzystywać.
Google Analytics RegEx Cheat Sheet
Spójrz na następujące znaki regex Google Analytics jako rodzaj cheat sheet – prawdopodobnie nie użyjesz ich od razu, ale krótkie przejście przez to, co jesteś w stanie zrobić z regex, pozwoli ci szukać odpowiedzi, gdy będzie to konieczne.
Jeśli chodzi o krótkie podsumowanie, nie znalazłem nic bardziej skondensowanego i trafiającego w punkt niż ten przewodnik:

Bardzo krótki przewodnik po Google Analytics regex – źródło obrazu
Jednakże można zauważyć, że z tym samym jako odniesieniem, jest to trochę niejasne i niejednoznaczne. Przejdźmy więc przez najczęściej używany regex Google Analytics, pokazując jednocześnie odpowiednie przypadki użycia.
Rurka (|)
Gdy chcesz powiedzieć „LUB”, powinieneś użyć rurki (|). Jak w „This | That” co oznaczałoby „This OR That”.
Jeśli jesteś zapalonym użytkownikiem segmentów Google Analytics, jesteś już przyzwyczajony do używania operatorów logicznych OR.
Jest to jedno z prostszych i bardziej powszechnych wyrażeń regularnych używanych w Google Analytics. Ma ono wiele zastosowań, jednak jednym z najczęściej wykorzystywanych może być ustawianie celów. Jeśli masz dwie strony z podziękowaniami z różnymi adresami URL (/thank-you/ i /subscription-confirmed/), ale chcesz śledzić obie z nich jako ukończenie celu, możesz użyć tego wyrażenia regularnego.
Możesz również użyć go w filtrach. Powiedzmy, że chcesz wyświetlić raport zachowania dla dwóch artykułów (na temat Lekcji Content Marketingu i Content Analytics), o adresach URL /content-marketing-analytics/ i /content-marketing-lessons/. Mógłbyś napisać, jako filtr, „content-marketing-analytics|content-marketing-lessons” i otrzymać tylko te artykuły.
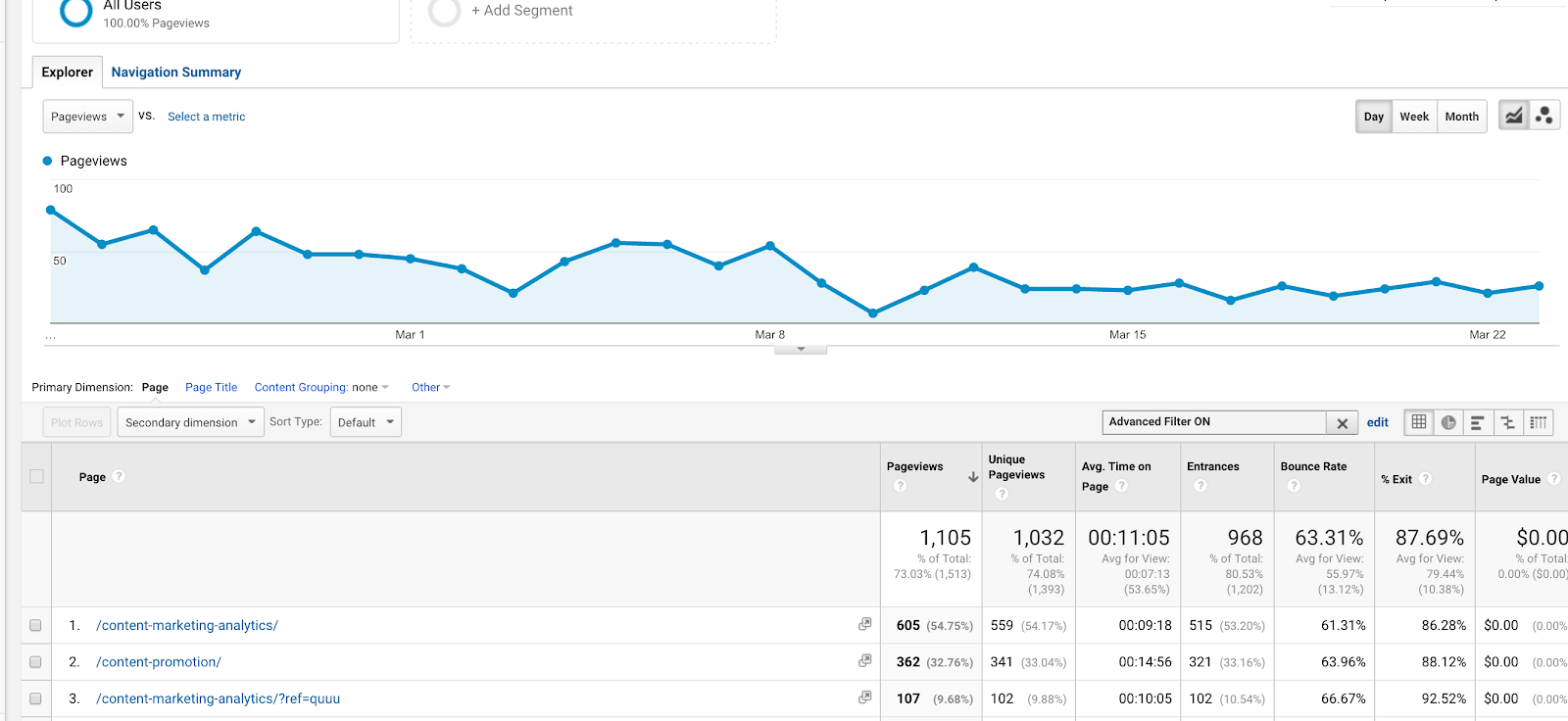
Użycie rury (|) w filtrze w celu uzyskania wyników dla dwóch oddzielnych wpisów na blogu
Odwrotny ukośnik (\)
Odwrotny ukośnik (\) jest kolejnym prostym i często używanym wyrażeniem regularnym w Google Analytics. Oznacza ono „rozważ następny znak jako zwykły tekst, a nie regex.”
Innymi słowy, istnieje wiele wyrażeń regularnych, które pojawiają się w zwykłym tekście, takich jak kropka, znak zapytania i inne, które musimy wyjaśnić, czy mają być odczytywane jako wyrażenia regularne czy zwykły tekst.
Wspólny ciąg zapytania online jest używany, gdy ktoś szuka czegoś w Twojej witrynie. Na przykład, kiedy wyszukuję „zabawki dla małych psów” na stronie petsmart.com, to jest to ciąg zapytania, który się pojawia:
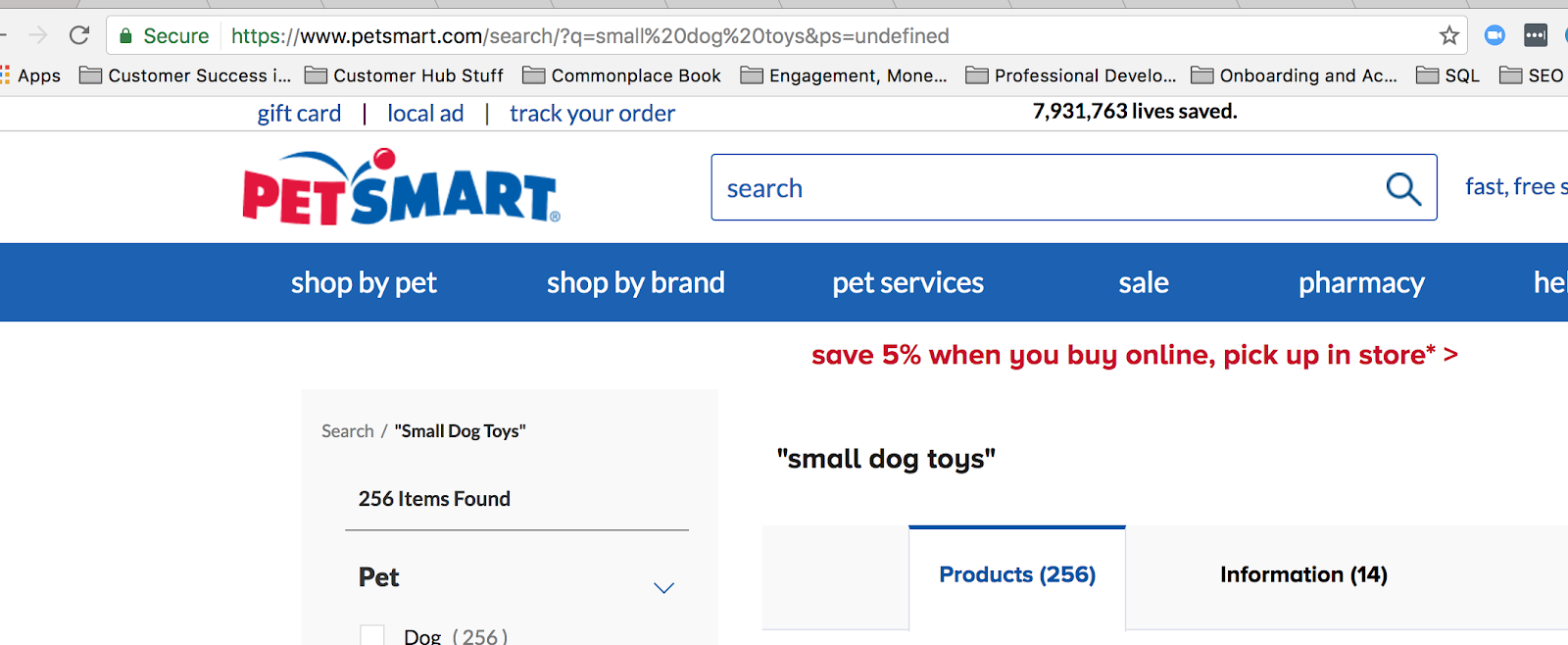
Kiedy używasz wyszukiwania na stronie, tworzysz ciąg zapytania w adresie URL.
Znak zapytania tutaj oznacza, że miało miejsce wyszukiwanie na miejscu, ale znak zapytania jest również powszechnie używanym wyrażeniem regularnym w Google Analytics. Dlatego musimy wyjaśnić przy użyciu odwrotnego ukośnika, że w tym przypadku znak zapytania powinien być odczytywany jako zwykły tekst.
Powiedzmy, że chcemy dopasować wszystkie ciągi zapytań w Google Analytics, które zaczynają się od /search/?q= (ponieważ oznacza to wyszukiwanie). Wtedy, wyrażenie regularne byłoby następujące:
search/?q=
Możesz to sprawdzić używając debuggera takiego jak regex101.com:
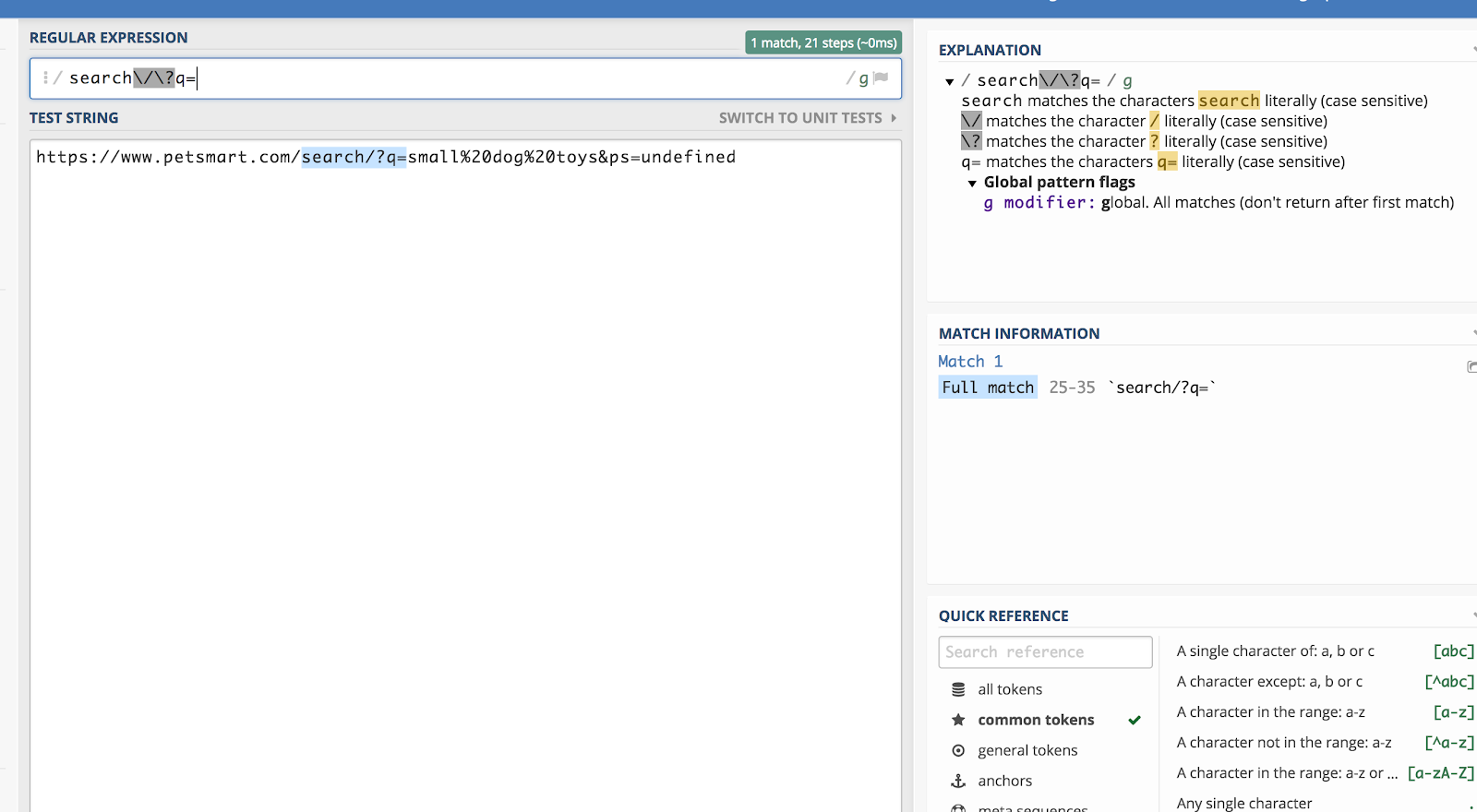
Odwrotny ukośnik (^) „ucieka” od regexu o jeden znak po nim i odczytuje go jako zwykły tekst.
Karet (^)
Karet (^) oznacza, że fraza zaczyna się od czegoś. Jest to ważne, gdy masz frazę, która może pojawić się wszędzie, ale chcesz konkretnie dopasować frazę w punkcie początkowym. Na przykład, spójrz na ten przykład kilku różnych fraz, które zawierają słowa „Mission: successful.”
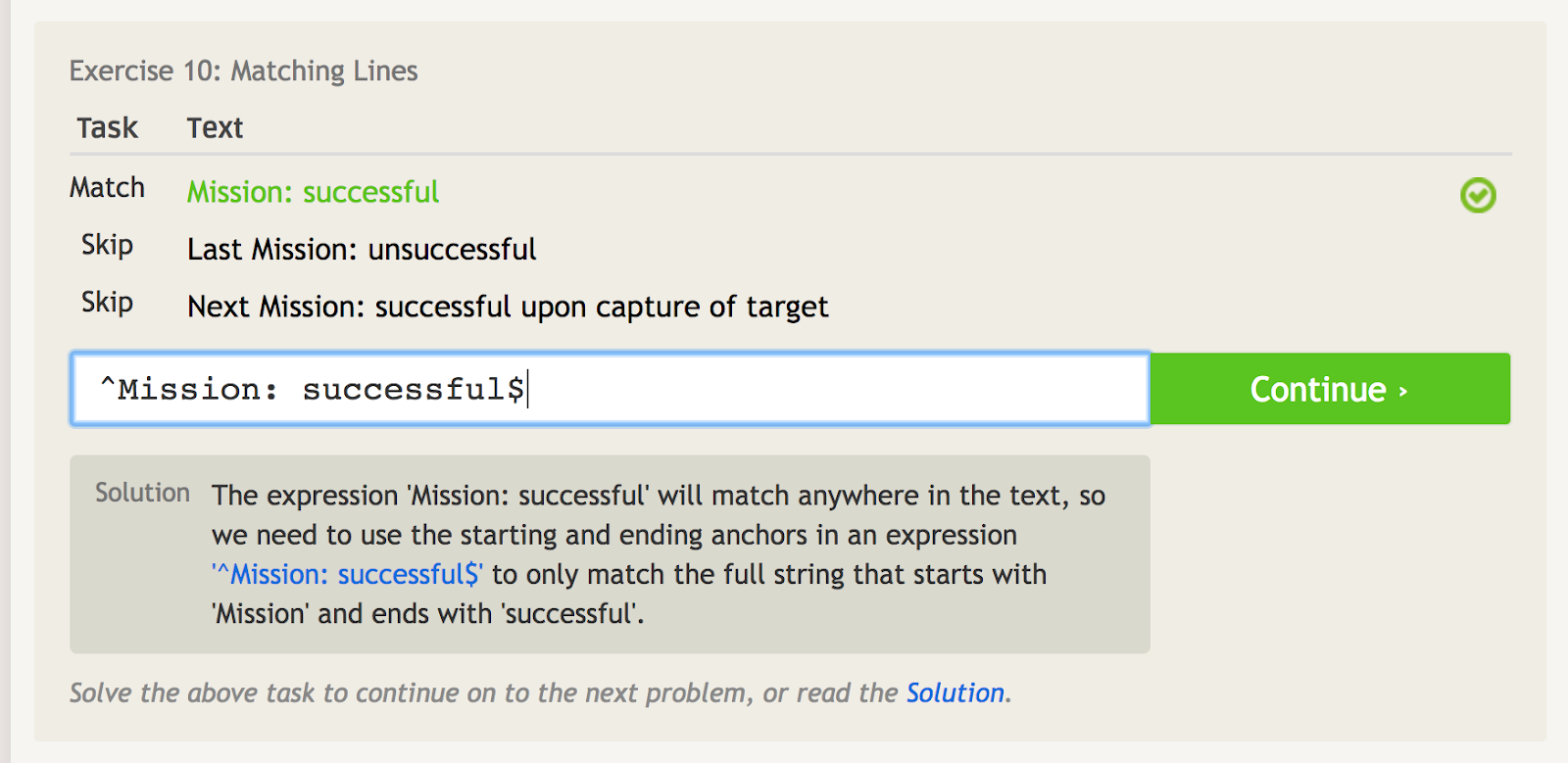
Karetka sygnalizuje kotwicę początkową, więc możemy dopasować wyłącznie pierwszą frazę tutaj.
Powiedzmy, że masz kilka kampanii AdWords, które wszystkie zaczynają się od tej samej frazy (ponieważ jesteś złym planistą na przyszłość):
- Freemium Campaign Final
- On our first Freemium Campaign
- Creative Freemium Campaign offer
- Test Freemium Campaign
Chciałbyś napisać ^Freemium Campaign, aby dopasować pierwszą z nich, a żadnej z pozostałych.
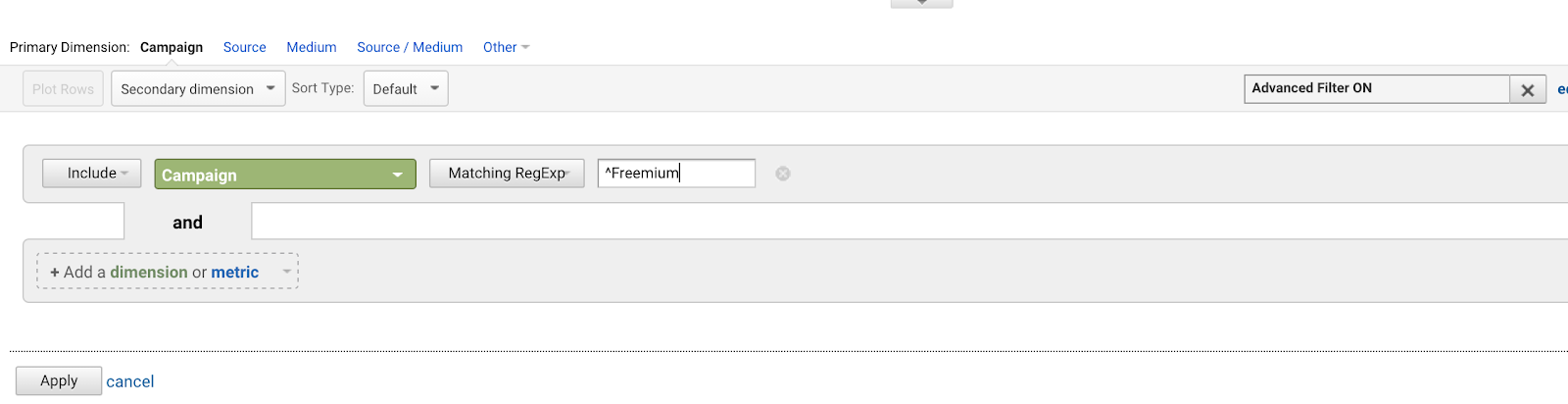
Użycie dewizki (^) dopasowuje ciągi znaków, które zaczynają się od tych znaków
Znak dolara ($)
Znak dolara ($) oznacza, że fraza kończy się na czymś.
Gdy połączysz te dwa elementy, możesz celować w frazy exact match.
Jeśli uruchomiłeś kampanię zatytułowaną „paidacquisitionfb”, a następnie uruchomił jeden o nazwie „paidacquisitionfb-2”, ponieważ nie planujesz dobrze i myśleć, że będziesz miał inne podobnie zatytułowane kampanie (zdarza się cały czas), można wyodrębnić pierwszy pisząc:
^paidacquisitionfb$
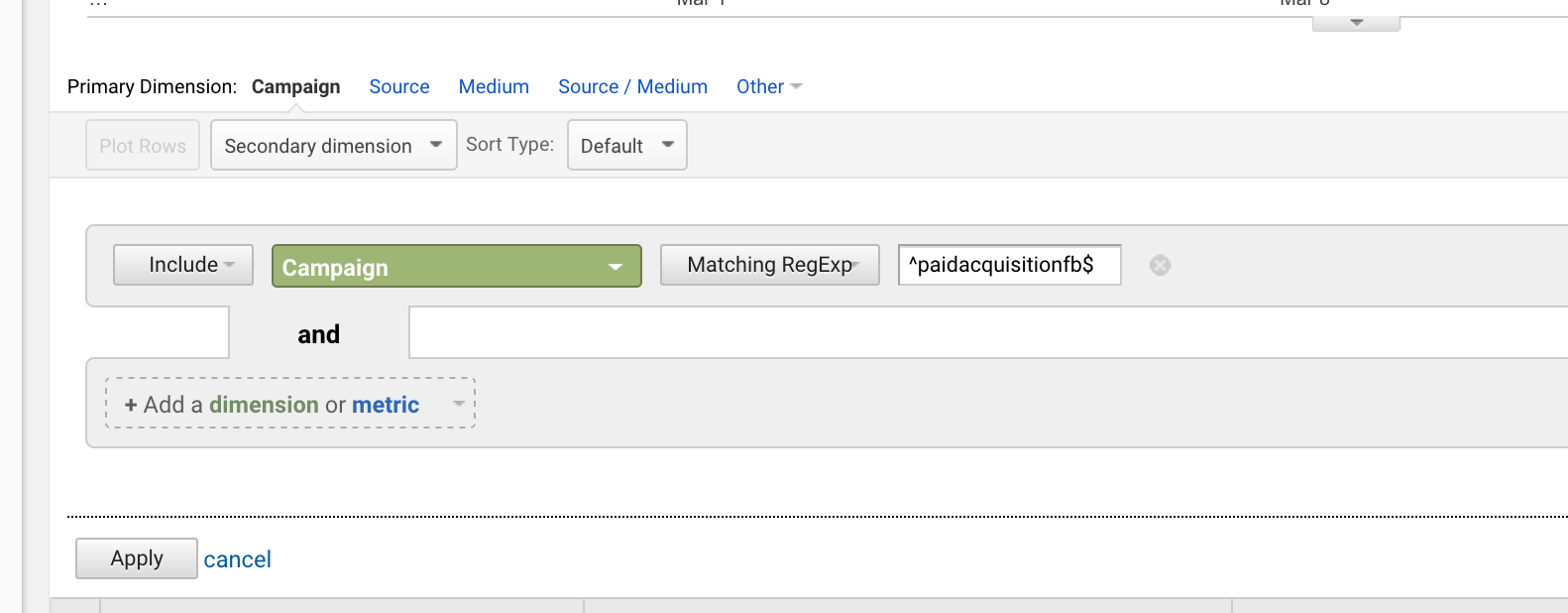
Używanie carett i dolara razem jest bardzo częste.
Jeśli masz tony stron kategorii na swoim blogu, na przykład, i wszystkie kończą się na numerach stron, możesz napisać prosty kawałek Google Analytics regex do wyświetlania tylko stron kategorii bloga (^/page/*/$). To dałoby Ci listę jak:
- /page/1
- /page/2
- /page/3
…i tak dalej.
Kropka (.)
Kropka (.) pasuje do dowolnego znaku, co oznacza wszystko, co można znaleźć na klawiaturze: cyfry, litery, nawet białe znaki. Nie jest super użyteczna sama w sobie, ale jest używana cały czas w połączeniu z innymi wyrażeniami regularnymi, szczególnie z gwiazdką (o tym za chwilę).
Powiedzmy, że chcesz jej użyć samej w sobie, i użyjmy przykładu „ki…”. To pasowałoby do wszystkiego, co zaczyna się od liter K i I, a następnie do dwóch następnych znaków, czymkolwiek one są.
Więc jeśli miałbyś ciąg, który zawierał słowa kill, kind, kiss, kin, kid!, i kit, to pasowałoby do nich wszystkich. Czekaj, co? Tak, dopasowałoby „kit” i „kin” tak długo, jak długo jest po nich spacja (wyłapuje również białe znaki). Podążając za tą logiką, podniósłby również wykrzyknik w „kid!”
Możesz zobaczyć, dlaczego rzeczy stają się niechlujne, jeśli używasz tylko tego.
Tutaj jest ilustracja powyższego przykładu przy użyciu Regex101.com:
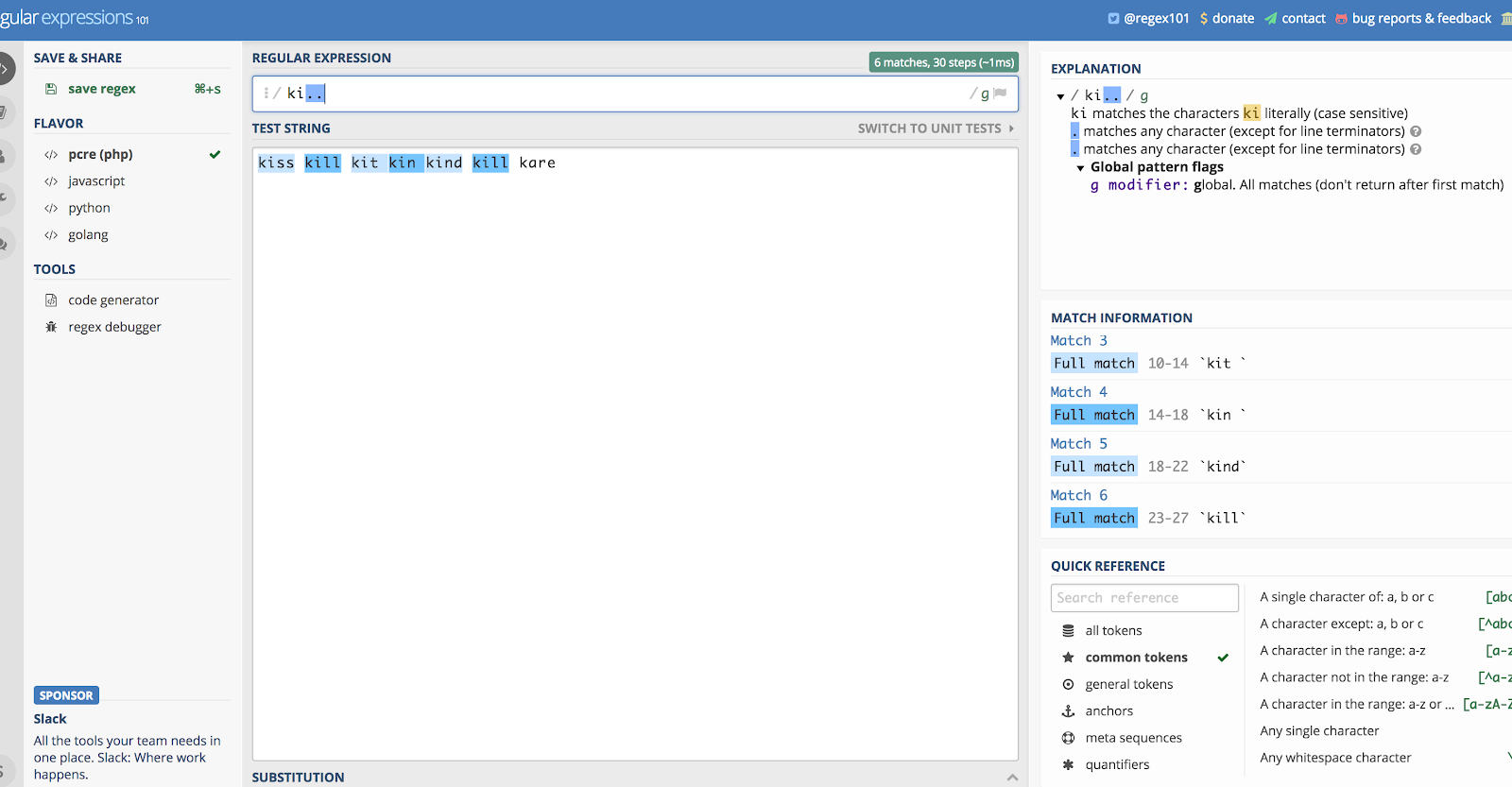
Kropka (.) pasuje do większości rzeczy.
Gwiazdka (*)
Gwiazdka (*) pasuje do zera lub więcej poprzednich elementów. Trochę to mylące, gdy stwierdzasz to w ten sposób, więc po prostu użyję przykładu.
Pamiętasz tę reklamę „wazzup” z Budweisera jakiś czas temu? Byłoby dość trudno zgadnąć, jak ktoś przeliterowałby to wyrażenie, gdyby go szukał (powiedzmy, na YouTube). Ale teoretycznie mógłbyś zawrzeć wszystkie warianty pisowni, robiąc to w następujący sposób:
waz*up
Oto ilustracja, jak to działa w regex101:
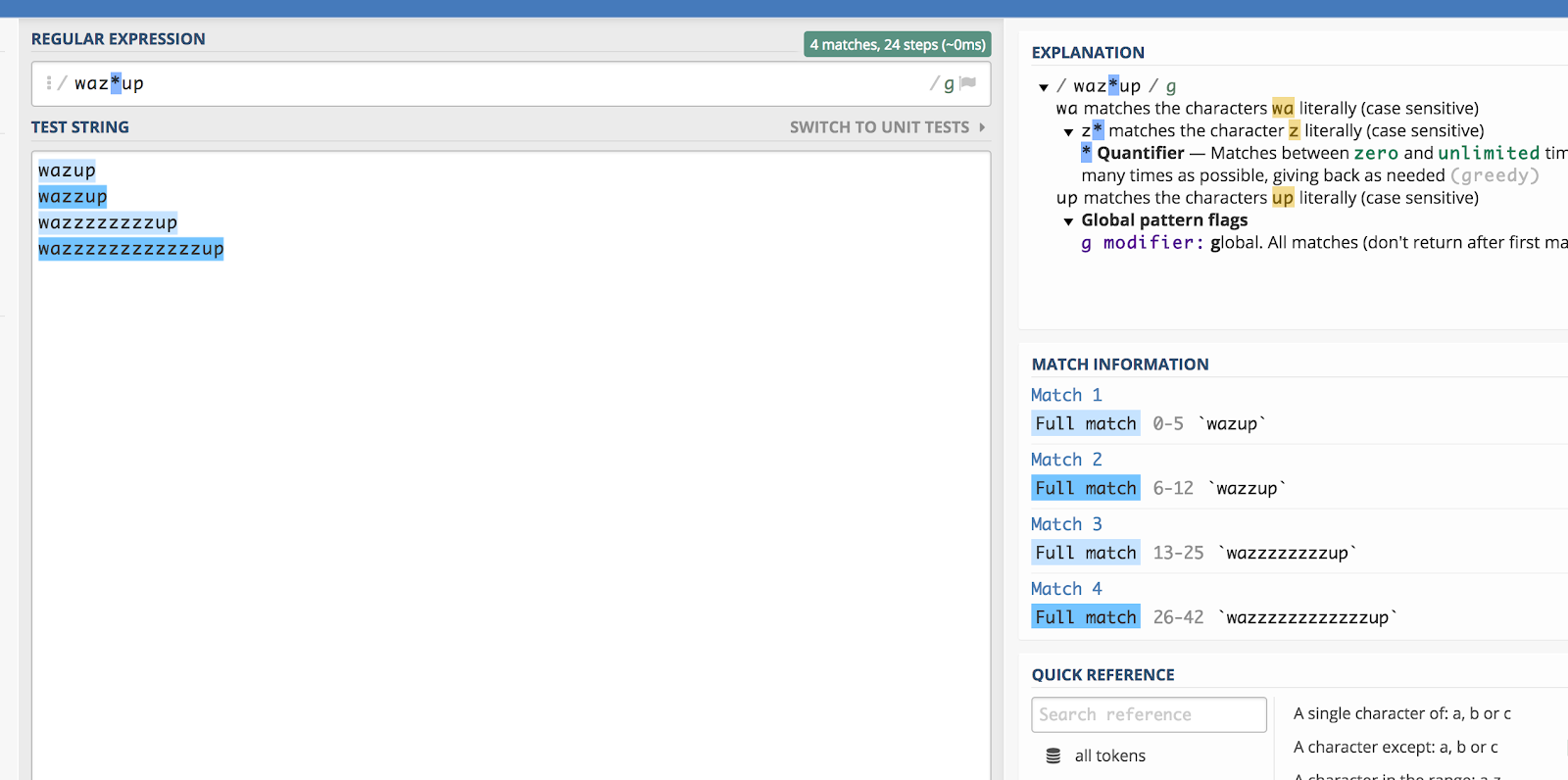
Ogwiazdka (*) pasuje do poprzedniego znaku zero lub więcej razy.
Jeśli chcesz być super dokładny i uwzględniać duże i małe litery, możesz napisać coś takiego:
*
Ale odbiegam od tematu.
Gdzie gwiazdka jest w rzeczywistości najpotężniejsza i częściej używana jest z kropką lub jako część innych kombinacji regex.
Kombinacja kropka – gwiazdka (.*)
Kombinacja kropka – gwiazdka (.*) w zasadzie oznacza anything goes. Jest bardzo często używane.
Używałbyś tego combo, gdy chcesz dopasować cokolwiek w łańcuchu. Ponieważ kropka oznacza dopasowanie dowolnego znaku, a * oznacza dopasowanie zero lub więcej znaków przed nim, to combo jest bardzo potężne.
Przykład: masz kilka różnych typów kont klientów, ale chciałbyś zobaczyć swoje dane dla nich wszystkich. Wszystkie one mają podobne strony, więc twoje strony wyglądają tak:
/klient/pro/login/
/klient/free/login/
/klient/starter/login/
Możesz napisać następujący regex, aby to zrobić:
/klient/.*/login
Zwykle używam tego wyrażenia regex Google Analytics, aby ustawić segmenty dla użytkowników z identyfikatorem użytkownika.
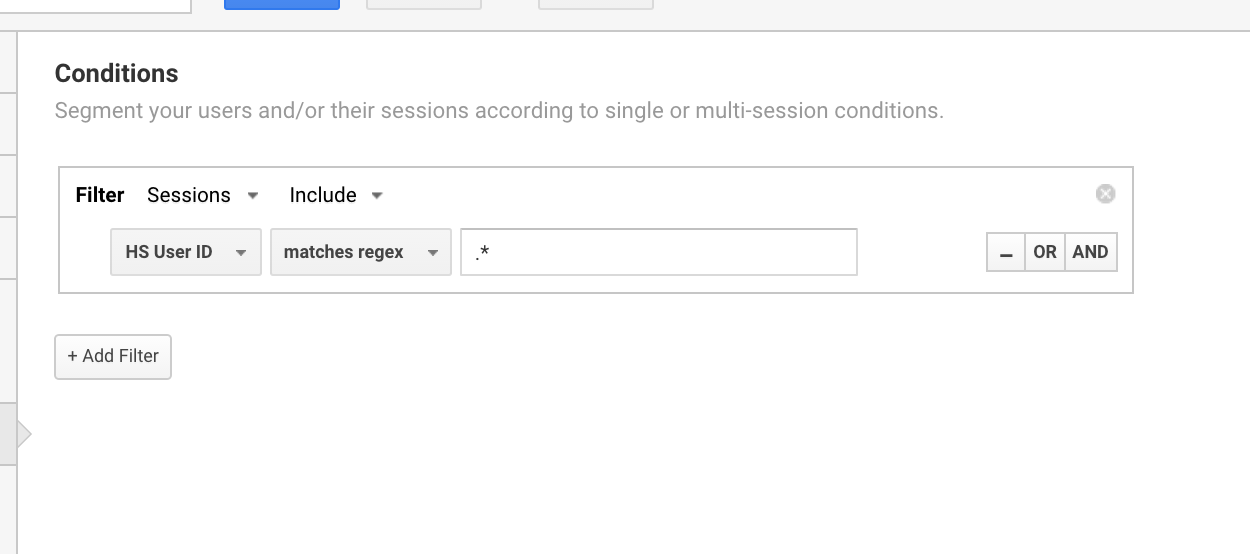
Używanie Google Analytics regex do wyodrębnienia wszystkich sesji, które mają ID użytkownika.
Znak plusa (+)
Znak plusa (+) jest bardzo podobny do *, z wyjątkiem tego, że pasuje do JEDNEGO lub więcej poprzednich znaków. Nie ma wiele więcej niż trzeba powiedzieć na ten temat, tylko to, że jest bardzo nieznacznie różny od gwiazdki. Oto różnica:
Wyobraź sobie, że masz słowa: hello, hhello, i hhhello.
Jeśli napiszesz hh+ello, dopasuje tylko dwa drugie, ale jeśli napiszesz hh*ello, dopasuje je wszystkie.
Małe rozróżnienie. W rzeczywistości, prawie zawsze używam gwiazdki zamiast znaku plus.
Znak zapytania (?)
Znak zapytania (?) jest łatwy. Oznacza on po prostu, że ostatni znak jest option.
Powiedz, że nie obchodzi cię zbytnio, czy słowo jest w liczbie mnogiej, czy nie (jak w przypadku butów). Może to być „but” lub „buty”, a ty chcesz to uchwycić w dowolny sposób. Wtedy możesz napisać „shoes?”
Oto przykład z użyciem mojego imienia. Jeśli ktoś przeliterował to „Alex Birket” podczas wyszukiwania strony, prawdopodobnie nadal chciałbym to zobaczyć. Mogę więc napisać:
Alex Birkett?
Tak to wygląda w regex101.com:
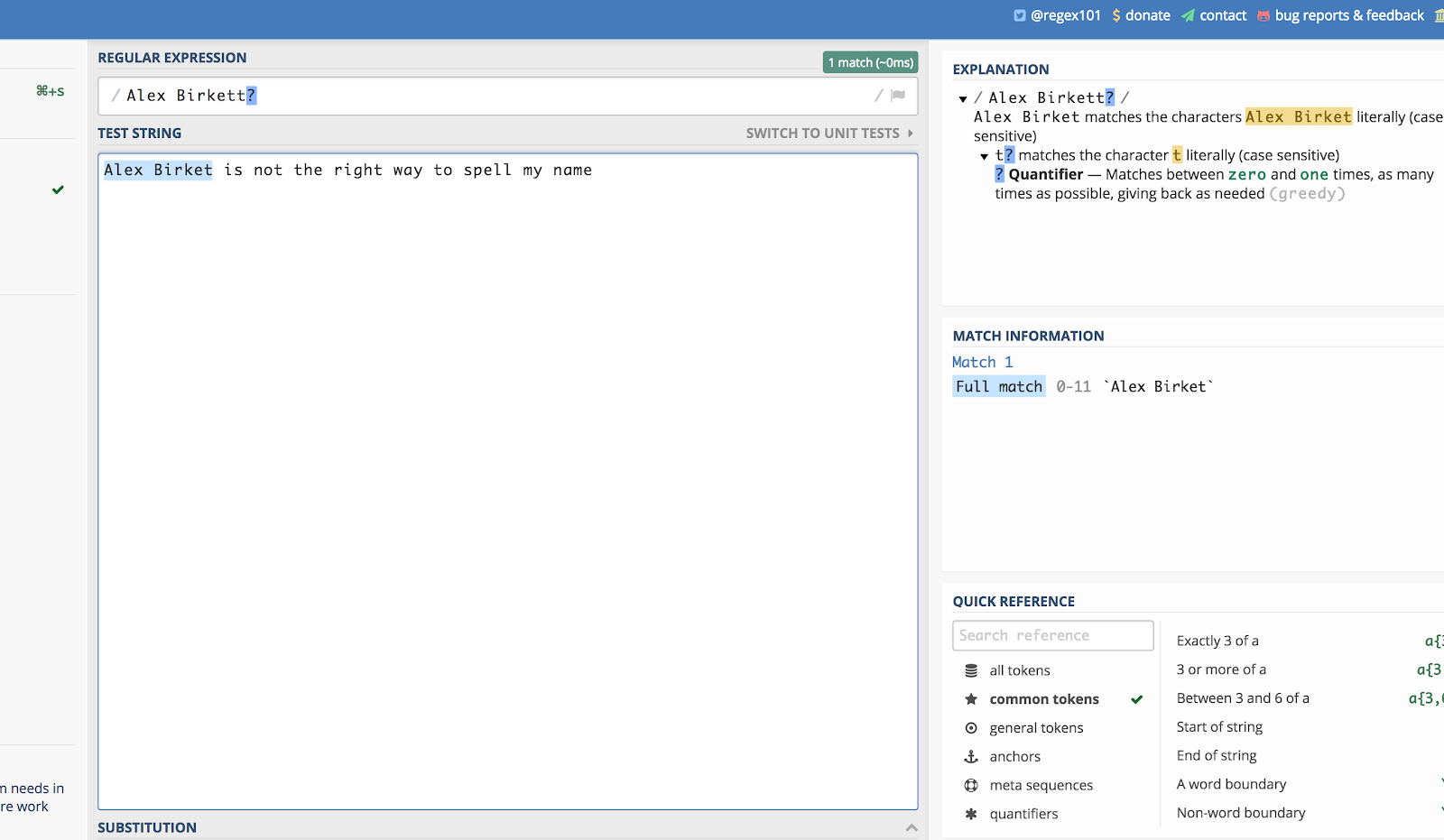
Znak zapytania (?) sprawia, że ostatni znak, który go poprzedza jest opcjonalny.
Parentezy ()
Parentezy działają tak samo jak w matematyce. Mówią ci, abyś ustalił priorytety i wyizolował logikę, która jest w grze wewnątrz nich.
Powiedzmy, że masz firmę SaaS z trzema ofertami i chcesz dopasować wszystkie swoje strony cenowe. Twoje adresy URL są następujące:
site.com/products/meetings/pricing
site.com/products/crm/pricing
site.com/products/email/pricing
Aby złapać wszystkie trzy z nich, możesz użyć wyrażenia regularnego, takiego jak to:
^/products/(meetings|crm|email)/pricing$
Nawiasy kwadratowe ()
Nawiasy kwadratowe () tworzą listę. Jeśli masz trzy łańcuchy, „thing1,” thing 2,” i „thing3,” możesz dopasować je wszystkie pisząc „thing” lub „thing” (więcej o myślnikach za chwilę – są one powszechnie używane z nawiasami kwadratowymi.
Nawiasy kwadratowe mogą być używane do dopasowania kilku iteracji słowa lub łańcucha, jednocześnie wykluczając kilka innych iteracji. Na przykład, jeśli chcesz dopasować „can”, „man” i „fan”, ale nie „dan”, „ran” lub „pan”, możesz użyć następującego regexu, aby to zrobić:
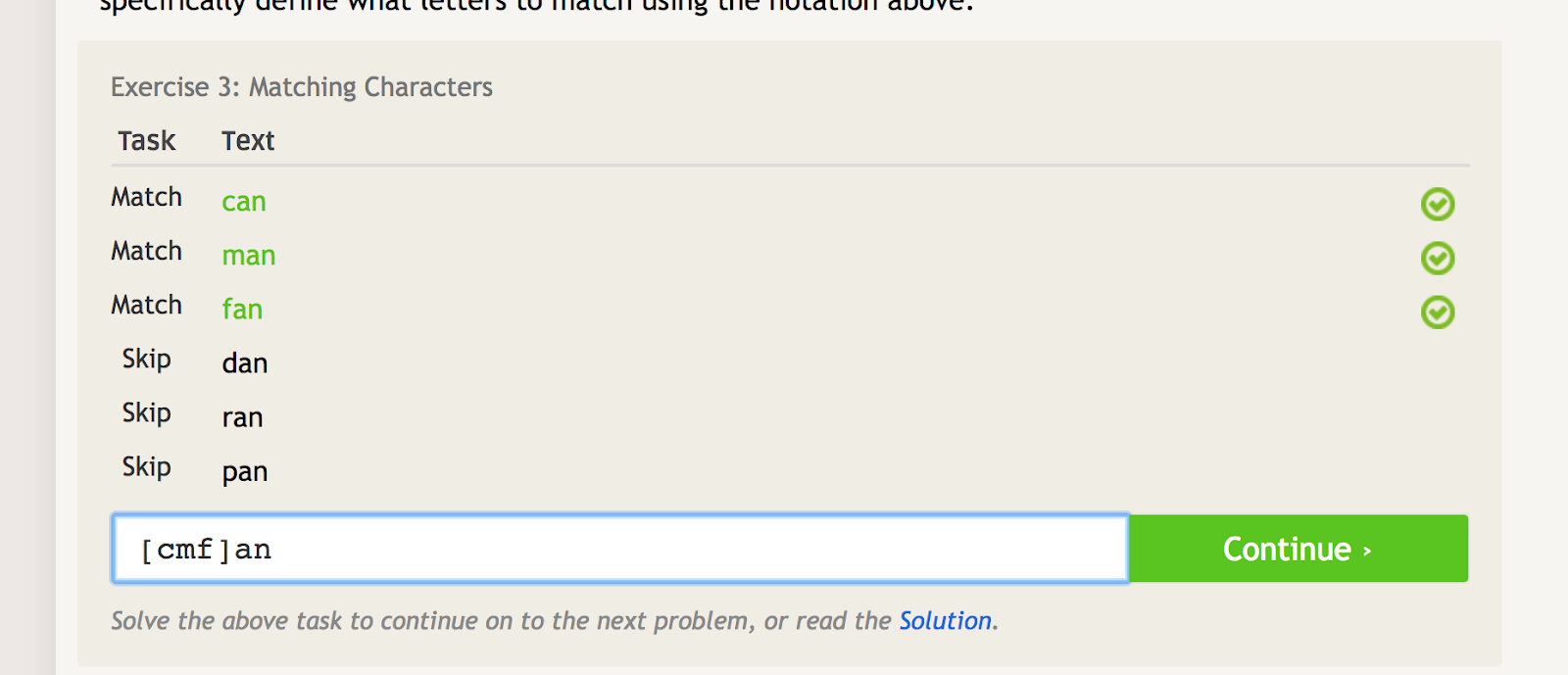
Nawiasy kwadratowe tworzą kilka pasujących warunków w zależności od tego, jakie znaki umieścisz wewnątrz nich. – image source
To jest coś, czego możesz użyć, jeśli masz kilka różnych produktów o podobnych nazwach, takich jak „shoes1,” shoes3,” i „shoes5.” Możesz dopasować te, i nic więcej, używając „shoes”
Kreski (-)
Kreski (-) działają w celu tworzenia liniowych list elementów.
Jak w, kiedy używasz nawiasów kwadratowych, nie musisz po prostu wymieniać wszystkiego, jeśli występuje liniowo. Więc jeśli chcesz dopasować ciąg liczb, gdzie ostatni może być cokolwiek od zera do dziewięciu, można napisać to:
1234
Albo, można napisać znacznie prostsze:
1234
To działa dla liter, jak również. Wyobraźmy sobie, że masz kategorię strony, która kończy się na dwóch losowych literach. Coś w tym stylu:
/page-aa/
Możesz dopasować wszystkie z nich pisząc:
/page-*/
Możesz zobaczyć przykład tego na regex101 tutaj:
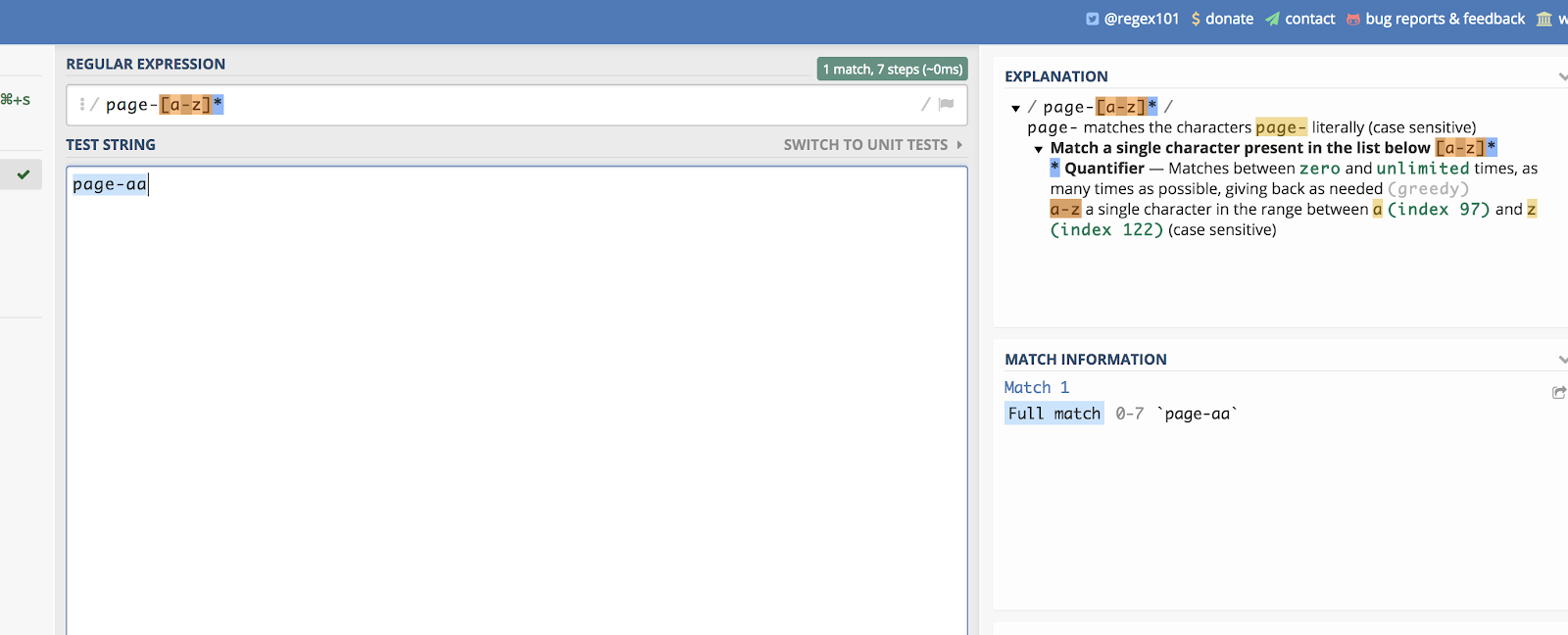
Kreski pomagają w tworzeniu liniowej listy do dopasowania.
Nawiasy klamrowe ({ })
Nawiasy klamrowe ({}) mówią ci, ile razy powtórzyć ostatni element.
Na przykład, jeśli chcesz dopasować tylko „wazzzzup,” możesz użyć „waz{4}up”.
Ale jeśli chcesz dopasować „wazzzzzup,” i „wazzzup,” ale nie „wazup,” możesz użyć „waz{3,5}up”. Jest to w zasadzie powiedzenie, aby dopasować znak „z” nie mniej niż 3 razy, ale nie więcej niż 5 razy.
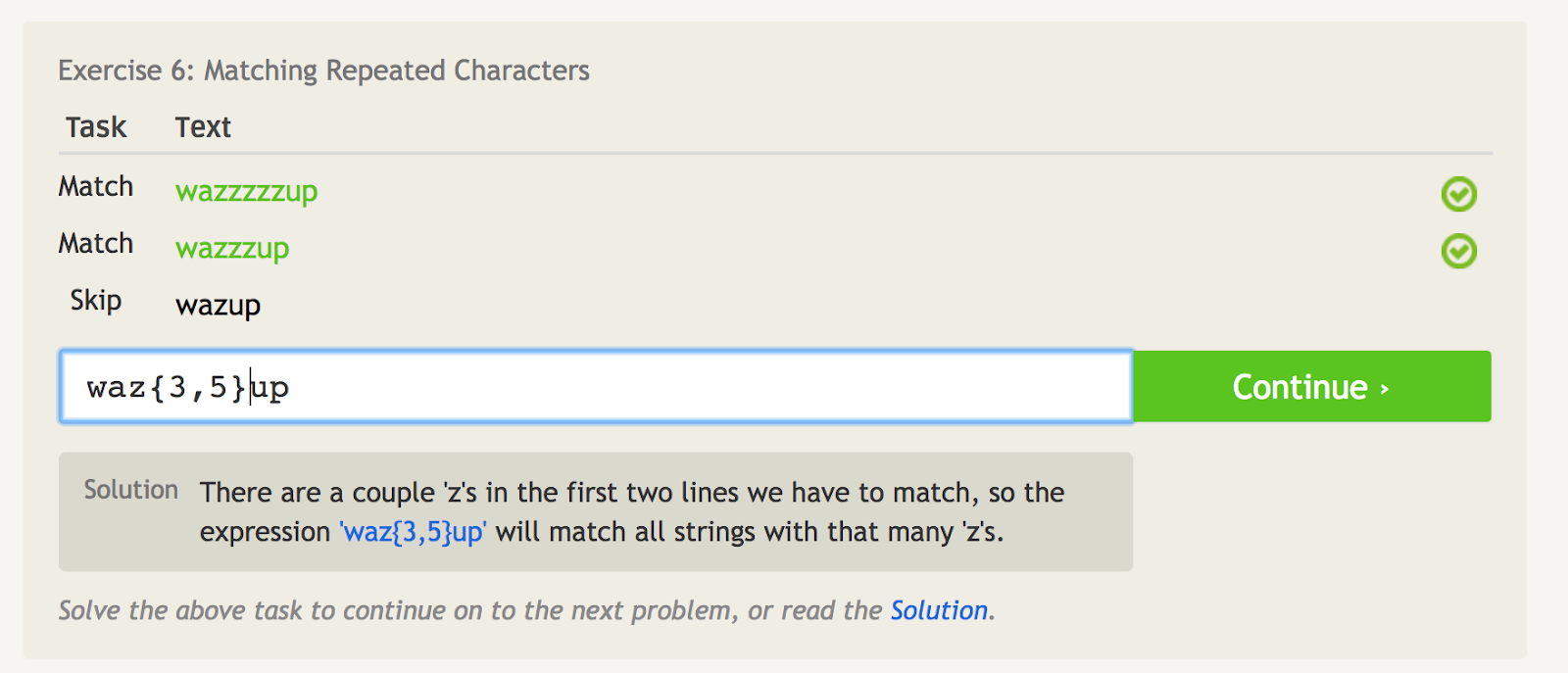
Nawiasy klamrowe mówią, ile razy powtórzyć ostatni element. – image source
Naprawdę nie używałem tego wyrażenia regularnego zbyt często w Google Analytics, ale częstym przypadkiem użycia może być kod pocztowy. Zazwyczaj pierwsze dwa znaki są takie same w mieście (78- dla Austin, TX, na przykład). Można więc dopasować dowolny kod pocztowy Austin, TX pisząc:
78{3}
To mówi, że ostatnie trzy litery mogą być dowolną losową liczbą od zera do dziewięciu.
Google Analytics RegEx: Konkretne przykłady, których możesz użyć
Jednym z najczęstszych przypadków użycia regex w Google Analytics jest tworzenie filtrów. Przejdźmy przez trzy przykłady, jeden prosty i jeden nieco bardziej skomplikowany.
Pierwszy, przykład zainspirowany świetnym postem na Search Engine Land przez Jenny Halasz.
Powiedzmy, że masz bałagan w architekturze strony, ale chcesz spojrzeć na wszystkie posty z pewnym podkatalogiem. Może to być cokolwiek, powiedzmy kategoria witryny lub typ zawartości. W tym przykładzie, szukamy kategorii na stronie dla /music/, ale tylko w trzecim podkatalogu. W tym przypadku możesz napisać ^/.*/.*/music/.* i to da ci ten raport.

Ten Google Analytics regex pokaże ci tylko /music/ w trzecim podkatalogu. – image source
Na pierwszy rzut oka wygląda to zagmatwanie – ale po nauczeniu się, co oznaczają te wyrażenia regularne, jest to całkiem proste. Zasadniczo, po prostu mówimy GA, aby dopasował stronę docelową, która zaczyna się od (^) ukośnika, następnie dowolnych znaków (.*), następnie ukośnika, następnie dowolnych znaków (.*), następnie ukośnika, a następnie muzyki.
LawnStarter używa podobnej taktyki do raportowania. Ich strategia polega na tworzeniu treści specyficznych dla miasta w podfolderach stron miejskich, używając następującego formatu:
https://www.lawnstarter.com/{{ transakcyjna strona miasta }}/{ informacyjny fragment treści }}
W celu odfiltrowania treści z lejków konwersji i raportowania ruchu, używają następującego regex, według założyciela Ryana Farleya.
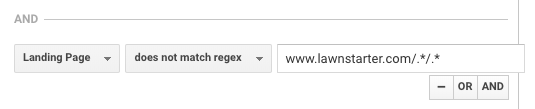
Ten regex pomaga LawnStarter dopasować treść specyficzną dla miasta w ich witrynie.
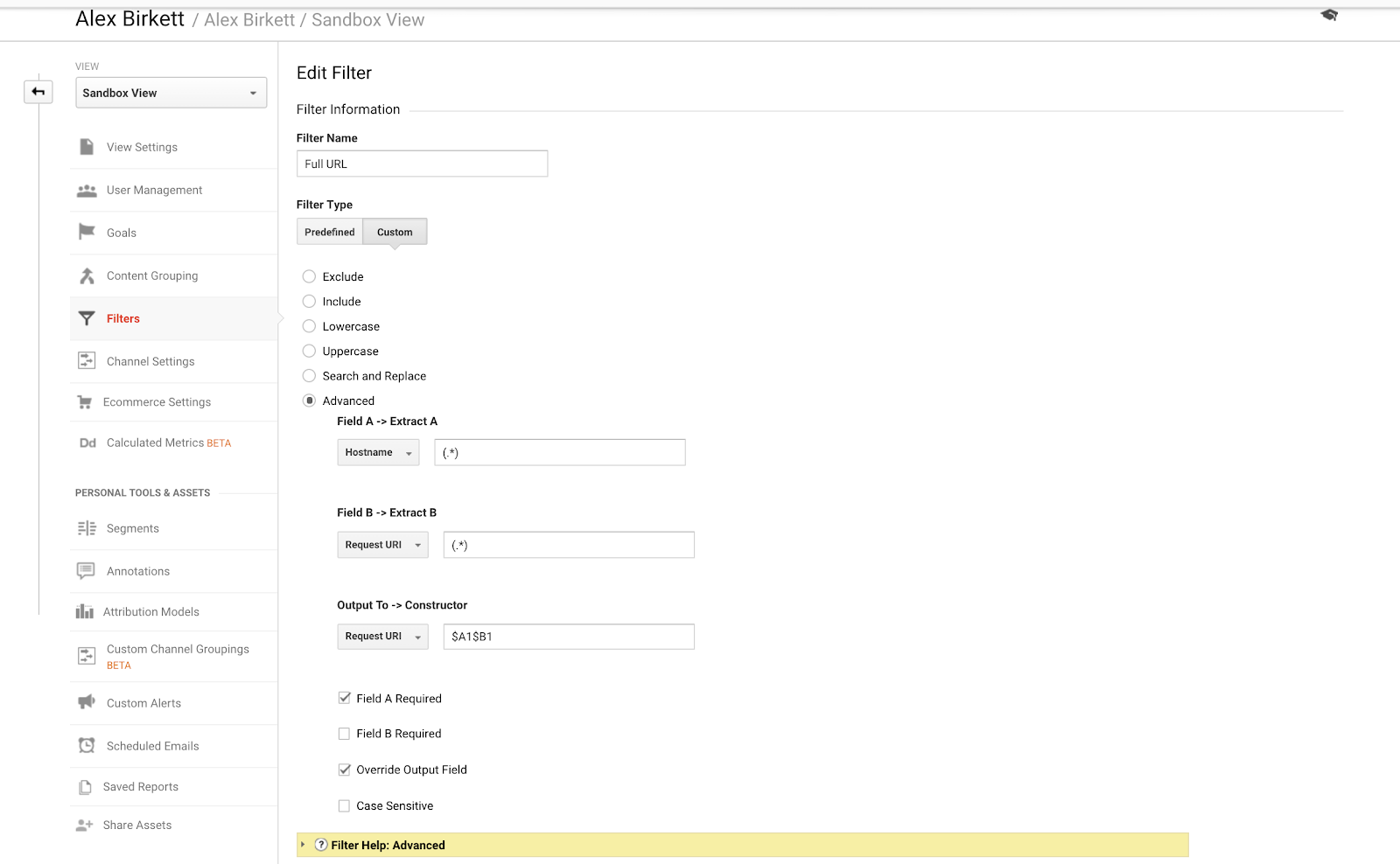
Po drugie, przejdźmy przez to, jak skonfigurować filtr dla jednego z widoków Google Analytics. Jest prawdopodobne, że będziesz miał specjalisty wdrożeniowego, który robi to – ale jeśli nie, zawsze mierzyć dwa razy i ciąć raz tutaj. Łatwo jest zepsuć te rzeczy (co jest również powodem, dla którego powinieneś skonfigurować swoje konto Google Analytics z widokiem piaskownicy, aby najpierw wypróbować różne rzeczy).
Aby skonfigurować filtry, przejdź do Admin > Filtry > Dodaj filtr.
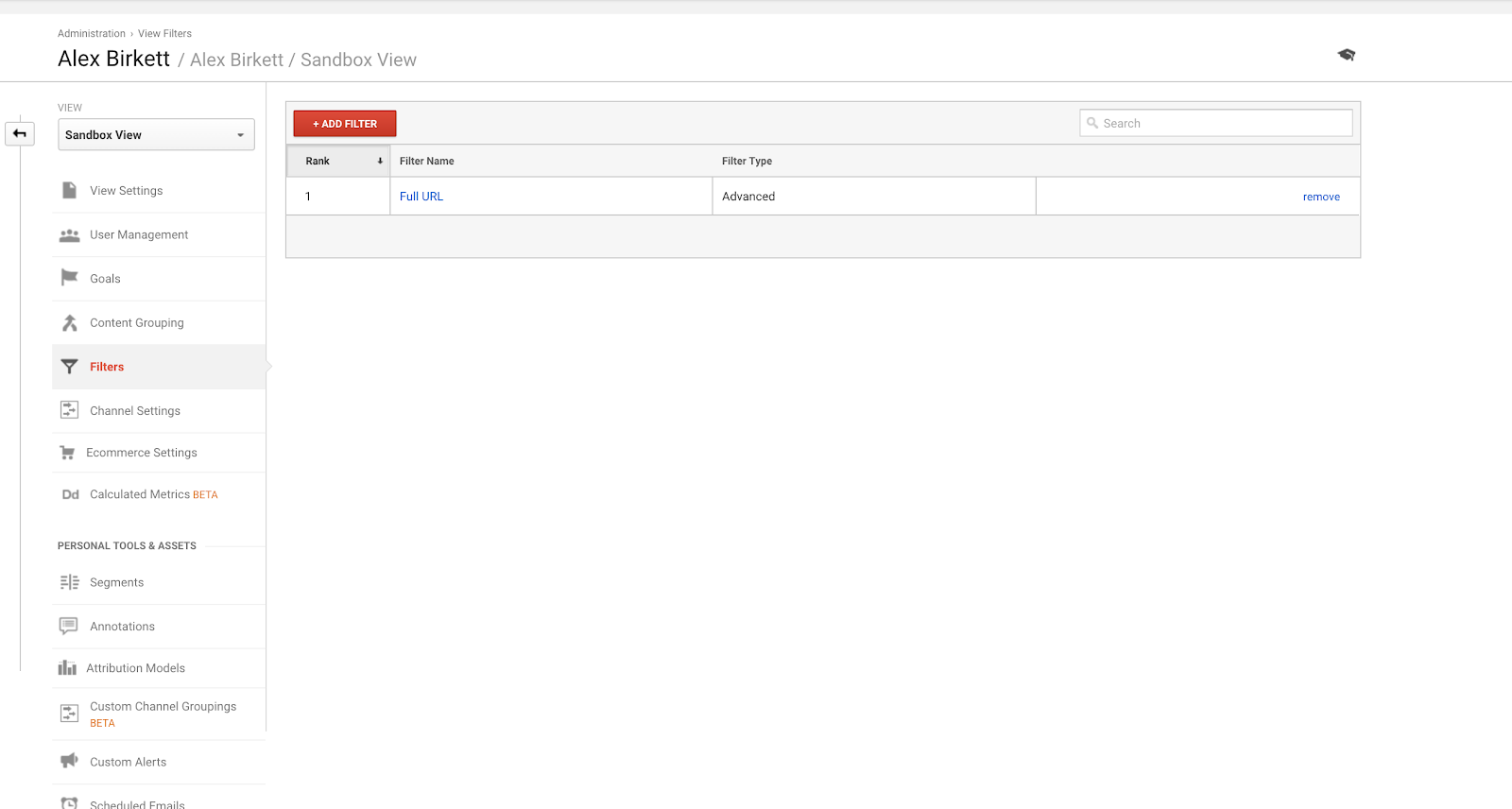
Najczęściej używanym filtrem w Google Analytics jest prawdopodobnie wykluczenie ruchu z własnego adresu(ów) IP.
Dla wielu, możesz to ustawić w prosty sposób, ponieważ masz tylko jeden adres IP. W przypadku większych firm, możesz mieć szereg IP i możesz łatwiej skonfigurować wykluczenia za pomocą Google Analytics regex.
Na przykład, jeśli napiszesz 63.212.171.1, wykluczy to wszystkie adresy IP od 63.212.171.1 do 63.212.171.9.
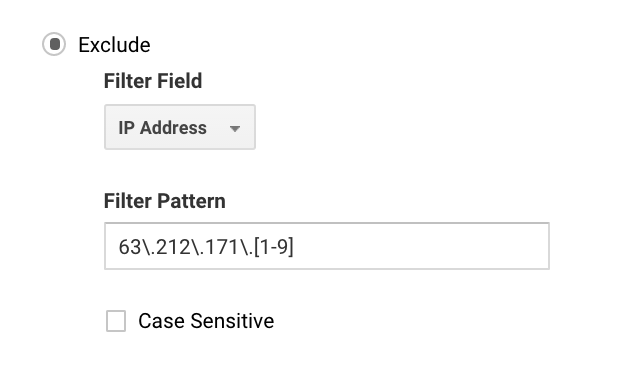
Ten Google Analytics regex wyklucza kilka adresów IP.
Inną rzeczą, którą możesz zrobić z Google Analytics regex, jest ustawienie filtrów do czyszczenia parametrów zapytania.
To może być zarówno irytujące, jak i problematyczne dla twojej analizy danych.
Złamane parametry zapytań mogą być denerwujące. – image source
To będzie zależało od tego, jak wygląda twoja konkretna sytuacja, ale istnieje kilka różnych sposobów, w jakie możesz użyć regex, aby to wyczyścić (uwaga: możesz to również zrobić w Google Tag Manager lub Excel, w zależności od zakresu problemu. Więcej na ten temat tutaj).
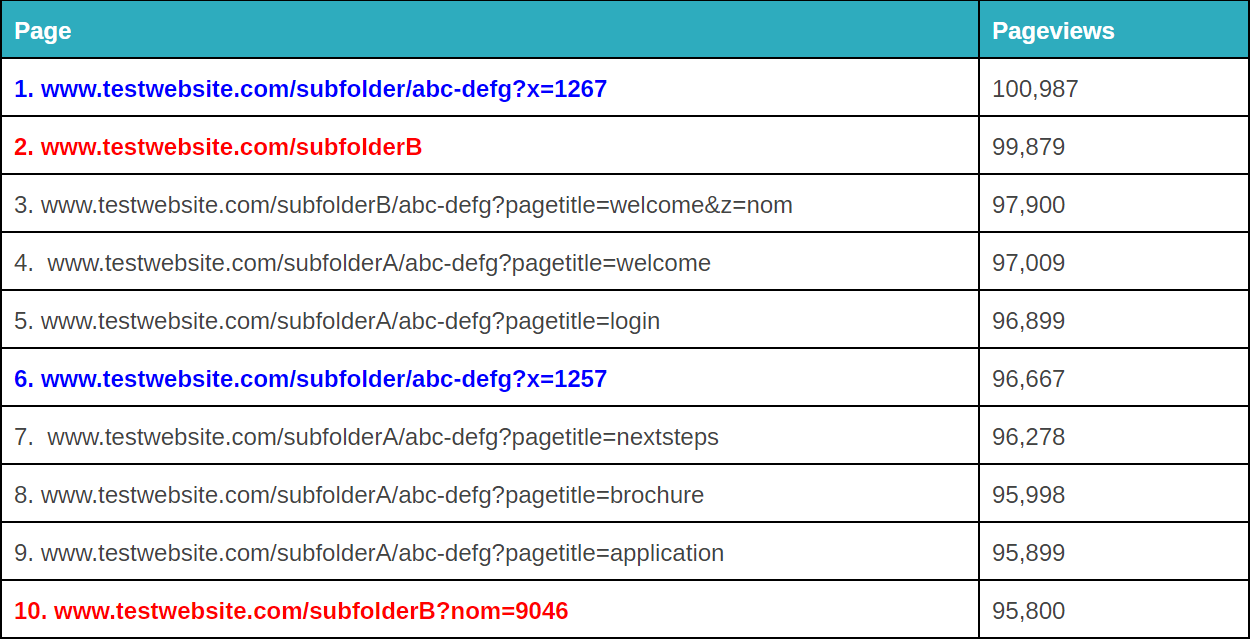
Na koniec, porozmawiajmy o jednym przykładzie, którego możemy użyć, aby lepiej zorganizować nasze śledzenie subdomen. Jeśli masz wiele domen lub subdomen, możliwe jest, że będziesz miał zduplikowane adresy URL, chyba że ustawisz filtr, aby poprzedzić swoją nazwę hosta do URi żądania. Innymi słowy, możesz mieć adresy URL:
- site.com/about
- blog.site.com/about
Reprezentują one dwie różne strony (jedna to strona o Twojej firmie, a druga to sekcja o Twoim blogu). Ale obie będą widoczne w Google Analytics jako /about, chyba że ustawisz następujący filtr (używając wyrażeń regularnych Google Analytics z kombinacją kropka-asterisk):
To dość proste, aby skonfigurować ten podstawowy filtr GA. – image source
Właściwie już omówiliśmy, jak skonfigurować te filtry dość dogłębnie w poprzednim poście KlientBoost na temat śledzenia domen i subdomen.
Google Analytics RegEx Tips &Błędy, których należy unikać
Wyrażenia regularne są jedną z tych rzeczy, które po prostu trzeba ćwiczyć i pobrudzić sobie ręce, aby się nauczyć. Jako takie, będziesz popełniać błędy.
To jest najważniejsza wskazówka, naprawdę: wypróbuj rzeczy i zobacz, czy działają. Wymieniłem mnóstwo zasobów w tym poście, jak przetestować swój regex, od regex101.com do regexbuddy.com. Zanurz palce w i użyj tych zasobów.
Jednakże, z pewnym foresite i heurystyką, możesz nauczyć się szybciej i złapać więcej błędów.
Jedną rzeczą, której naprawdę należy się nauczyć, jest to, jak „uciec” w regex (rozmawialiśmy o tym z backslash). Leho Kraav, CTO w CXL Institute, ujmuje to tak:
„Powiedziałbym „naucz się o prawidłowej ucieczce rzeczy” – łatwo jest uzyskać niedopasowanie, gdy znaki są takie same, ale ich znaczenie jest inne w zależności od tego, czy są ucieczką, czy nie.”
Na przykład, jeśli twoje zapytanie ma znak zapytania, to jest to również wyrażenie regularne, więc musisz to wyjaśnić za pomocą odwrotnego ukośnika. Chris Mercer, założyciel MeasurementMarketing.io, mówi również, że nie uczenie się tej zdolności jest jednym z największych błędów, które widzi początkujących robiących:
„Najczęstszym błędem, który widzimy z początkującymi używającymi regex jest zapominanie o „ucieczce” symboli regex. Na przykład, jeśli szukasz stron, które pasują do regexa „thankyou/?success=yes”, to nie zadziała. Sam „?” jest symbolem regex i musi być dezaktywowany przez użycie „znaku ucieczki” (znaku ” „). W tym przypadku „thankyou/?success=yes” będzie działać.”
Inna wskazówka? Utrzymuj to w prostocie. Ludzie próbują komplikować rzeczy (sprawdź najbardziej skomplikowany regex, jaki kiedykolwiek widziałeś, napisany przez Leho, tutaj), ale wyrażenia regularne są „chciwe” i będą pasować tak bardzo, jak tylko mogą. Google Analytics opublikował na blogu post z poradami i wyjaśnił to w ten sposób:
„Jeśli musisz napisać wyrażenie, aby dopasować „nowe wizyty”, a jedyne opcje, które będą dopasowane do są „nowe wizyty” i „powtarzające się wizyty”, tylko słowo „nowe” jest wystarczająco dobre.
Będą pasować do wszystkiego, co może, chyba że zmusisz ich nie do. Jeśli twoje wyrażenie to „wizyty”, to będzie pasować do „nowych wizyt” i „powtórnych wizyt”. Po tym wszystkim, oba zawierały wyrażenie „wizyty”. Aby uczynić je mniej chciwymi, musisz uczynić je bardziej konkretnymi.”
Zaczynaj więc powoli, zachowaj prostotę i nie przytłaczaj się złożonością (szansa na błąd koreluje w tym przypadku ze złożonością).
Mercer również powtarza ten punkt, radząc, aby podejmować rzeczy stopniowo:
„Kiedy po raz pierwszy zaczynasz, skup się na tym, aby stać się dobrym… potem lepszym. Łatwo jest przytłoczyć się wszystkimi możliwościami, jakie oferuje regex, ale jeśli zaczniesz od podstaw, takich jak opanowanie symbolu „lub” (” | „), szybko nabierzesz doświadczenia i zaczniesz zdawać sobie sprawę z tego, co jest możliwe z regexem.”
Ostatnia wskazówka ode mnie: naucz się Google’ować rzeczy. To jest prawdziwe dla każdego programowania, ale szczególnie dla wyrażeń regularnych. Będziesz zapominać rzeczy, a jeśli nie piszesz regex codziennie, nie ma sensu zapamiętywać wszystkiego. Naucz się sprawdzać rzeczy i znajdować odpowiedzi na to, co próbujesz zrobić.
Outside of Google Analytics: RegEx for Other Marketing Uses
Regex jest również czymś, na co wszyscy praktycy SEO powinni zwrócić uwagę. Po pierwsze, oczywiście, ponieważ SEO i analityka cyfrowa (np. Google Analytics) są ze sobą nierozerwalnie splecione. Po drugie, ponieważ niektóre z tych samych wyrażeń dopasowujących, które piszemy w celu filtrowania i dopasowywania znaków na naszych danych Google Analytics, mogą być również używane w ekstrakcji danych dla taktyki SEO.
Innymi słowy, wyrażenia regularne są ważne dla web scrapingu.
W przypadku web scrapingu i SEO, będziesz zazwyczaj pracował poprzez język programowania, taki jak Python, ale zasady są takie same.
Jak na przykład, możesz zeskrobać cały pogrubiony tekst na stronie używając tego:
<strong>(+)</strong>
Albo jak wspomniano w tym artykule SEJ, jeśli ktoś skrobał ESPN dla wszystkich autorów, mógłby napisać to:
„felietonista”:”(.*?)”
W celu zachowania spójności i zdrowego rozsądku, nie będę się zagłębiał w zaawansowany web scraping. Wystarczy wiedzieć, że regex jest ważny również w tej dziedzinie. Jednakże, jeśli chciałbyś dowiedzieć się więcej, proponuję następujące źródła:
- Web Scraping with Regular Expressions
- Scraping with Regular Expressions (Stanford)
- How to Use Regex for SEO & Website Data Extraction
Wyrażenia regularne pomagają również w pracy z danymi SEO, poza zwykłym skrobaniem sieci. Na przykład, możesz użyć regex, aby jeszcze bardziej dostosować sposób korzystania z Screaming Frog.
Jenny Halasz podał dobry przykład użycia regex do czyszczenia danych w poście Search Engine Land:
„Na przykład, powiedzmy, że masz listę adresów URL i musisz rozbić je tylko na TLD (Top Level Domain).
Możesz użyć prostego find/replace dla http i www, ale jak łatwo wywalić wszystkie nazwy plików? Mógłbyś usunąć je wszystkie ręcznie, ale to jest bolesne. Używając prostego regex wildcard (/*), możesz usunąć ukośnik i wszystko, co po nim następuje.”
Możemy mówić bez końca o wyrażeniach regularnych dla SEO i web scrapingu, ale po prostu połączę się z kilkoma dobrymi zasobami na wypadek, gdybyś chciał dowiedzieć się więcej (jest to bardzo wszechstronny język, w końcu, z wieloma przypadkami użycia poza analityką):
- How Regular Expression Affects SEO
- 5 Powerful Awesome Htaccess Redirect Tricks
- How to Use Regular Expression for Report Segmentation
Conclusion
Google Analytics regex to naprawdę coś, co powinien znać każdy analityk, nawet jeśli nie fantazjujesz o sobie jako o techniku. Poza tym, znajomość niektórych wyrażeń regularnych (lub przynajmniej tego, jak szukać odpowiedzi i stosować je do właściwych problemów) może pomóc marketerom w różnych działaniach.
Przypominam, że nie jest to bardzo powszechny zestaw umiejętności, więc prawdopodobnie zaimponujesz niektórym kolegom swoimi nowo odkrytymi technicznymi umiejętnościami marketingowymi.
Więc zachęcam cię, zacznij się uczyć, a co ważniejsze, po prostu zacznij ćwiczyć używanie wyrażeń regularnych. Nie są one aż tak straszne.