Czas czytania: 30 minut
Modele dyskryminacyjne, określane również jako modele warunkowe, są klasą modeli stosowanych w klasyfikacji statystycznej, w szczególności w nadzorowanym uczeniu maszynowym.
W przeciwieństwie do modelowania generatywnego, które bada na podstawie wspólnego prawdopodobieństwa P(x,y), modelowanie dyskryminacyjne bada P(y|x) i.
- Zrozummy to na przykładzie matematycznym:
Załóżmy, że dane wejściowe to x, a zbiór etykiet dla x to y. Rozważmy następujące 4 punkty danych:
(x,y) –> {(0,0), (0,0), (1,0), (1,1)}Dla powyższych danych, p(x,y) będzie następujące:
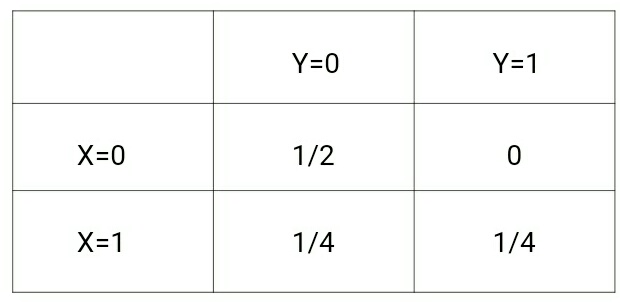
natomiast p(y|x) będzie następujące:
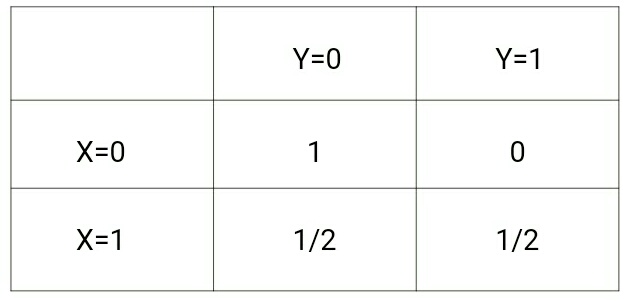
Jeśli spojrzymy na te dwie macierze, zrozumiemy różnicę między tymi dwoma rozkładami prawdopodobieństwa.
Więc algorytmy dyskryminacyjne próbują nauczyć się p(y|x) bezpośrednio z danych, a następnie próbują sklasyfikować dane.
Z drugiej strony, algorytmy generatywne próbują nauczyć się p(x,y), które może być przekształcone w p(y|x) później, aby sklasyfikować dane. Jedną z zalet algorytmów generatywnych jest to, że można użyć p(x,y) do generowania nowych danych podobnych do istniejących danych. Z drugiej strony, algorytmy dyskryminacyjne generalnie dają lepszą wydajność w zadaniach klasyfikacji.
W modelach dyskryminacyjnych, aby przewidzieć etykietę y z przykładu treningowego x, musimy ocenić:
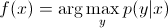
który po prostu wybiera, co jest najbardziej prawdopodobną klasą y biorąc pod uwagę x. To tak, jakbyśmy próbowali modelować granicę decyzji między klasami. Zachowanie to jest bardzo wyraźne w sieciach neuronowych, gdzie obliczone wagi można postrzegać jako krzywą o złożonym kształcie, izolującą elementy klasy w przestrzeni.
- koncentracja na granicy decyzji.
- bardziej wydajne z dużą ilością przykładów.
- nie zaprojektowane do używania nieoznakowanych danych.
- tylko zadanie nadzorowane.
Klasyfikatory dyskryminacyjne Przykłady
Modele dyskryminacyjne są preferowane w następujących podejściach:
- Regresja logistyczna
- Skalarna maszyna wektorowa
- Tradycyjne sieci neuronowe
- Najbliższe wyszukiwanie sąsiadów
- Kondycjonalne pola losowe (CRF)s
Korzyści z modelu dyskryminacyjnego
- Modele dyskryminacyjne są używane do uzyskania lepszej dokładności na danych treningowych.
- Gdy dane treningowe są duże, dokładność dla przyszłych danych będzie dobra.
- Gdy liczba parametrów jest ograniczona, model dyskryminacyjny będzie próbował zoptymalizować przewidywanie y na podstawie x, podczas gdy model generatywny będzie próbował zoptymalizować wspólne przewidywanie x i y. Z tego powodu modele dyskryminacyjne przewyższają modele generatywne w zadaniach przewidywania warunkowego.
.