Google Analytics regex (ou seja, expressões regulares) é um conjunto de habilidades subvalorizadas.
Se você quiser fazer qualquer tipo de filtragem ou segmentação além do básico, uma boa aderência ao regex lhe dará superpoderes analíticos.

Regex dá-lhe superpoderes. – fonte da imagem
De facto, as expressões regulares têm casos de uso muito mais amplo do que a análise e o marketing. Mas para os propósitos deste artigo, vamos cobrir alguns casos de uso tático que poderiam ajudá-lo com as percepções do usuário, organização de dados e até mesmo casos de uso avançado de targeting e marketing em mecanismos de busca.
Mas primeiro, vamos resumir brevemente o que são expressões regulares, especificamente em relação ao Google Analytics.
- Google Analytics RegEx: O que é isso?
- Google Analytics RegEx Cheat Sheet
- Pipe (|)
- Backslash (\)
- Caret (^)
- Sinal de dólar ($)
- Ponto (.)
- Asterisco (*)
- Combinação de ponto asterisco (.*)
- Sinal de Plus (+)
- Ponto de interrogação (?)
- Parênteses ()
- Squadrar parênteses ()
- Dashes (-)
- Curly brackets ({ })
- Google Analytics RegEx: Exemplos específicos que você pode usar
- Google Analytics RegEx Tips & Erros a evitar
- Fora do Google Analytics: RegEx para outros usos de marketing
- Conclusão
Google Analytics RegEx: O que é isso?
Expressões regulares são cadeias de texto especiais para descrever padrões de pesquisa.
Huh?
Em relação à análise, expressões regulares ajudam a encontrar, definir e extrair coisas. Ainda mais especificamente, com o Google Analytics, elas podem ajudá-lo a criar definições mais flexíveis para coisas como filtros de visualização, objetivos, segmentos, públicos, grupos de conteúdo e agrupamentos de canais.
Basicamente, elas são caracteres predefinidos ou uma série de caracteres que combinam de forma ampla ou estreita e selecionam padrões em seus dados analíticos digitais. Eles são uma ferramenta geral que pode ser usada de muitas maneiras (toneladas de linguagens de programação e ferramentas permitem regex). Mas em Analytics, vamos usá-los principalmente para combinar padrões em dados.
Não é útil apenas em Analytics, é claro. Especialmente, se você é um usuário do Google Tag Manager ou se você está executando um targeting complicado nos seus testes A/B, você estará usando um monte de regex. Como Chris Mercer, fundador da MeasurementMarketing.io, diz:
“Usamos o regex diariamente. Ele nos ajuda a definir claramente tudo desde passos de funil em um objetivo do Google Analytics, até um gatilho específico no Google Tag Manager”
No entanto, se você gostaria de fazer um mergulho profundo e realmente aprender expressões regulares, aqui estão alguns recursos (não necessários para coisas básicas no Google Analytics, e provavelmente para alguém de proeza mais técnica):
- Expressões Regulares: O Tutorial Completo
- Masterização de Expressões Regulares 3ª Edição (Livro)
- Aprenda Expressões Regulares da Maneira Difícil
Você também pode aprender interativamente através de algo como RegexOne ou RegexR, ambos são legais. Mas vamos ultrapassar isso e caminhar através dos caracteres regex mais usados no Google Analytics, para que você possa começar a usar isto.
Google Analytics RegEx Cheat Sheet
Leia os seguintes caracteres regex do Google Analytics como uma espécie de folha de respostas – você provavelmente não vai usá-los de imediato, mas rever brevemente o que você é capaz de fazer com o regex vai permitir que você procure a resposta quando for necessário.
Para um breve resumo, não encontrei nada mais condensado e directo do que este guia:

Um guia muito breve do Google Analytics regex – fonte da imagem
No entanto, pode ver que, só com isso como referência, é um pouco vago e ambíguo. Então vamos caminhar através do Google Analytics regex mais comumente usado, mostrando os casos de uso correspondentes.
Pipe (|)
Quando você quer dizer “OU” você deve usar um pipe (|). Como em “This | That” que significaria “This OR That”.
Se você é um ávido usuário dos segmentos do Google Analytics, você já está acostumado a usar operadores lógicos OR.
Esta é uma das expressões regulares mais simples e comuns usadas no Google Analytics. Tem muitas aplicações, embora uma das mais utilizadas possa ser na definição de objectivos. Se você tem duas páginas de agradecimento com URLs distintas (/thank-you/ e /subscription-confirmed/), mas você gostaria de rastrear ambas como uma conclusão de objetivo, você pode usar esta expressão regular.
Você também pode usá-la em filtros. Digamos que você queria ver um relatório de comportamento em dois artigos (sobre Lições de Marketing de Conteúdo e Análise de Conteúdo), com as URLs /content-marketing-analytics/ e /content-marketing-lessons/. Você poderia escrever, como um filtro, “content-marketing-analytics|content-marketing-lessons/” e obter apenas esses artigos.
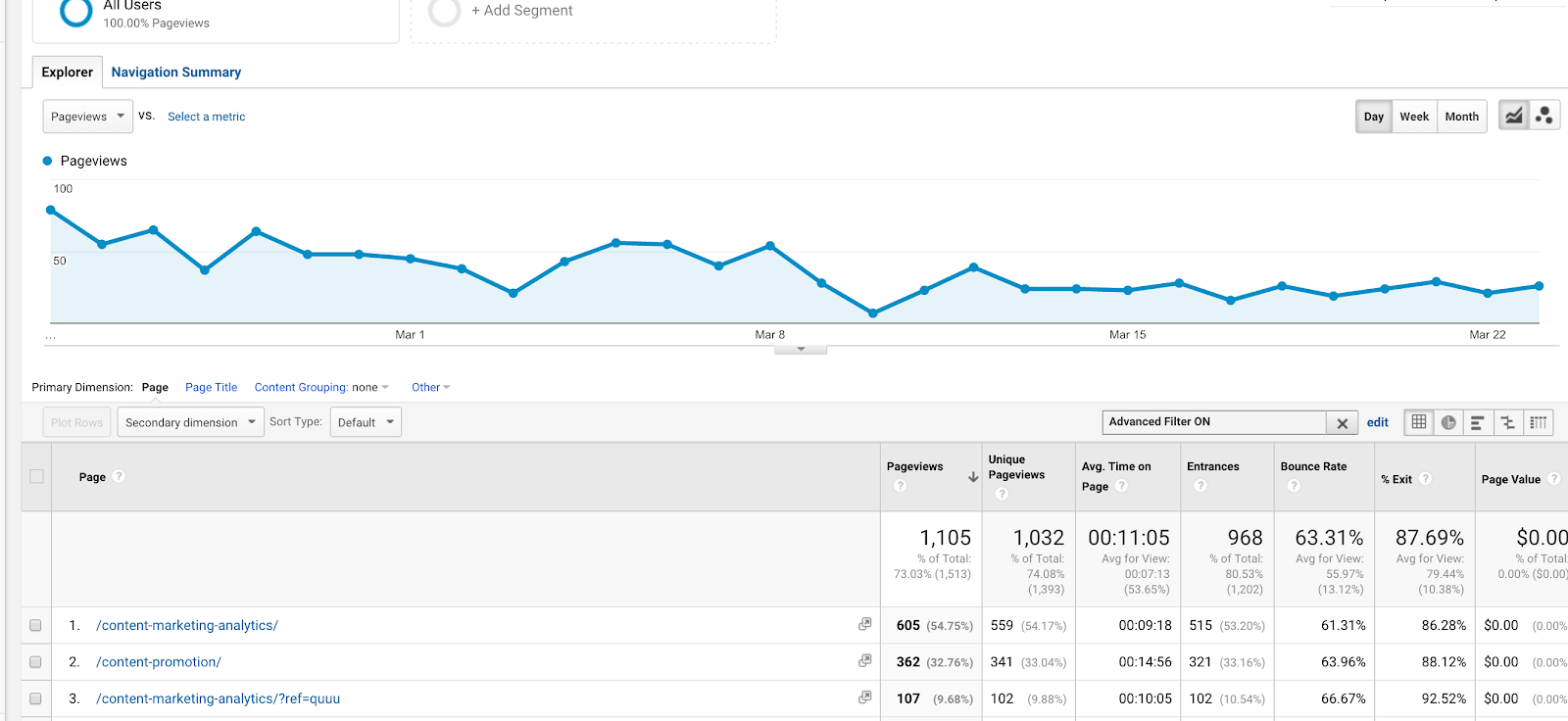
Usar um pipe (|) num filtro para obter resultados para dois artigos separados no blog
Backslash (\)
The backslash (\) é outra expressão simples e comumente usada regularmente no Google Analytics. Significa “considere o próximo caractere em texto simples, e não regex”
Em outras palavras, existem muitas expressões regulares que aparecem em texto simples, como o ponto, ponto de interrogação e outras, que precisamos esclarecer se elas devem ser lidas como expressões regulares ou texto simples.
Uma cadeia de consulta comum online é usada quando alguém procura por algo no seu site. Por exemplo, quando eu procuro por “brinquedos para cães pequenos” em petsmart.com, esta é a cadeia de consulta que surge:
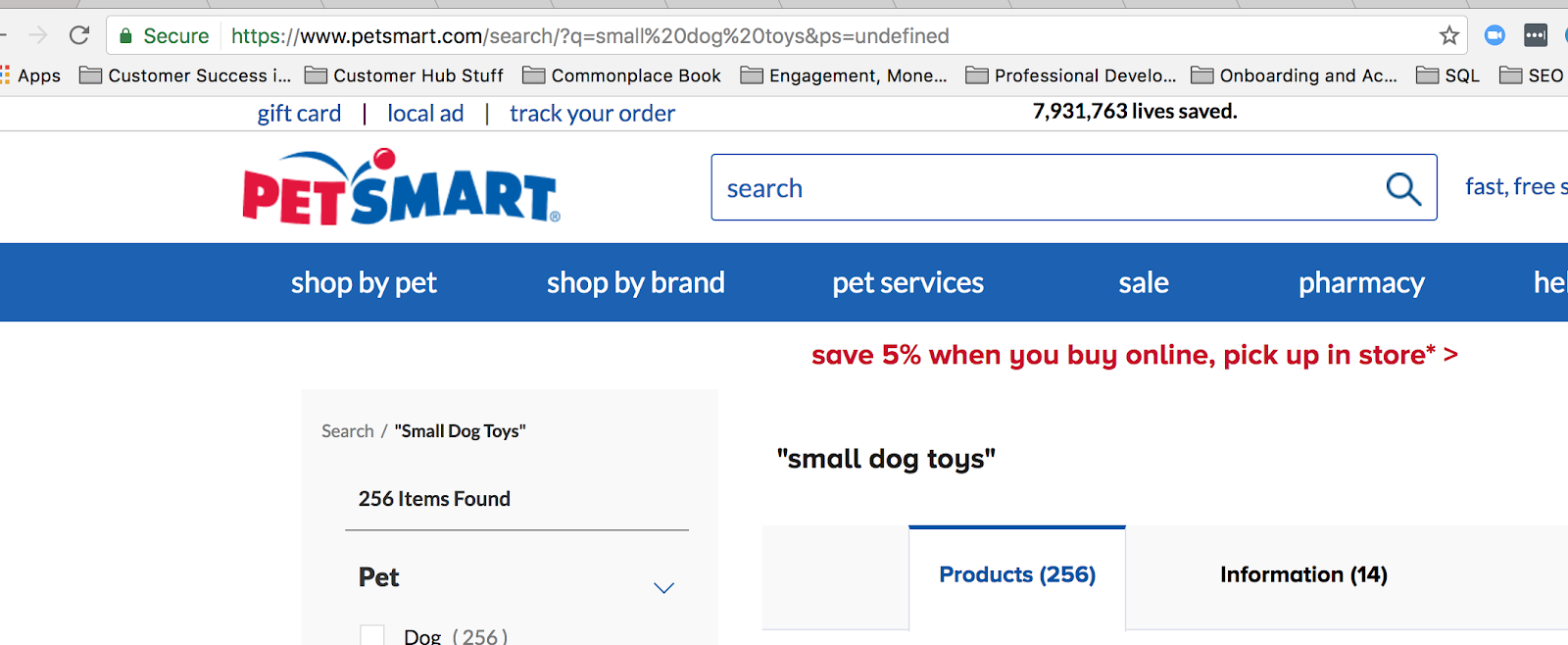
Quando você usa pesquisa no site, você cria uma cadeia de consulta na URL.
O ponto de interrogação aqui significa que uma pesquisa no site ocorreu, mas o ponto de interrogação também é uma expressão comumente usada no Google Analytics. Portanto, temos de esclarecer ao usar uma barra invertida, que neste caso, o ponto de interrogação deve ser lido como texto simples.
Vamos dizer que queremos corresponder todas as cadeias de consulta no Google Analytics que começam com /search/?q= (porque isso significa uma pesquisa). Então, a expressão regular seria:
search\/\?q=
Pode verificar isto usando um debugger como regex101.com:
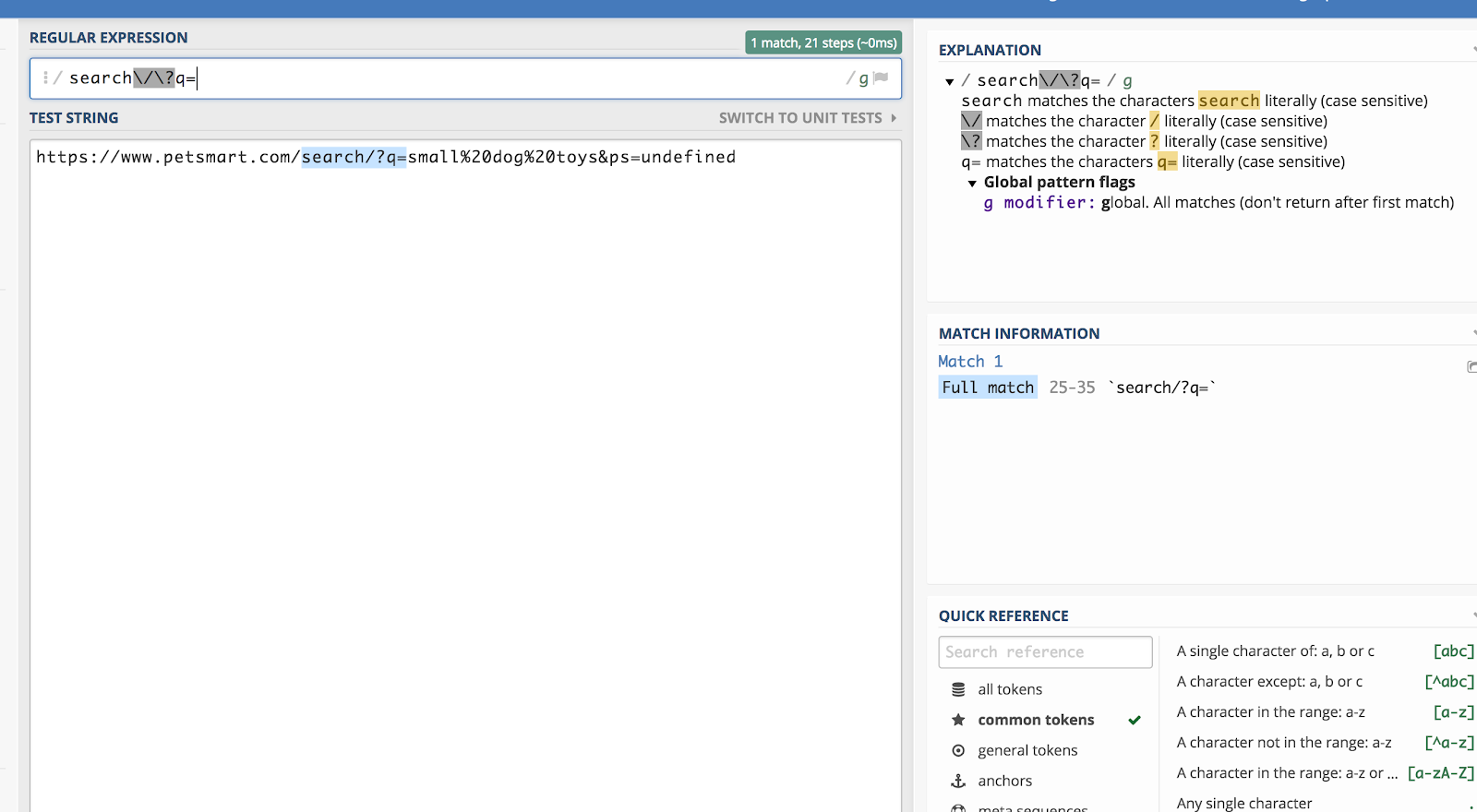
A contrabarra (\) “escapa” do regex para um caractere depois e lê como texto simples.
Caret (^)
Caret (^) significa que uma frase começa com algo. Isto é importante quando você tem uma frase que pode aparecer em qualquer lugar, mas você quer combinar especificamente a frase no ponto de partida. Por exemplo, veja este exemplo de algumas frases diferentes que incluem as palavras “Missão: sucesso”,
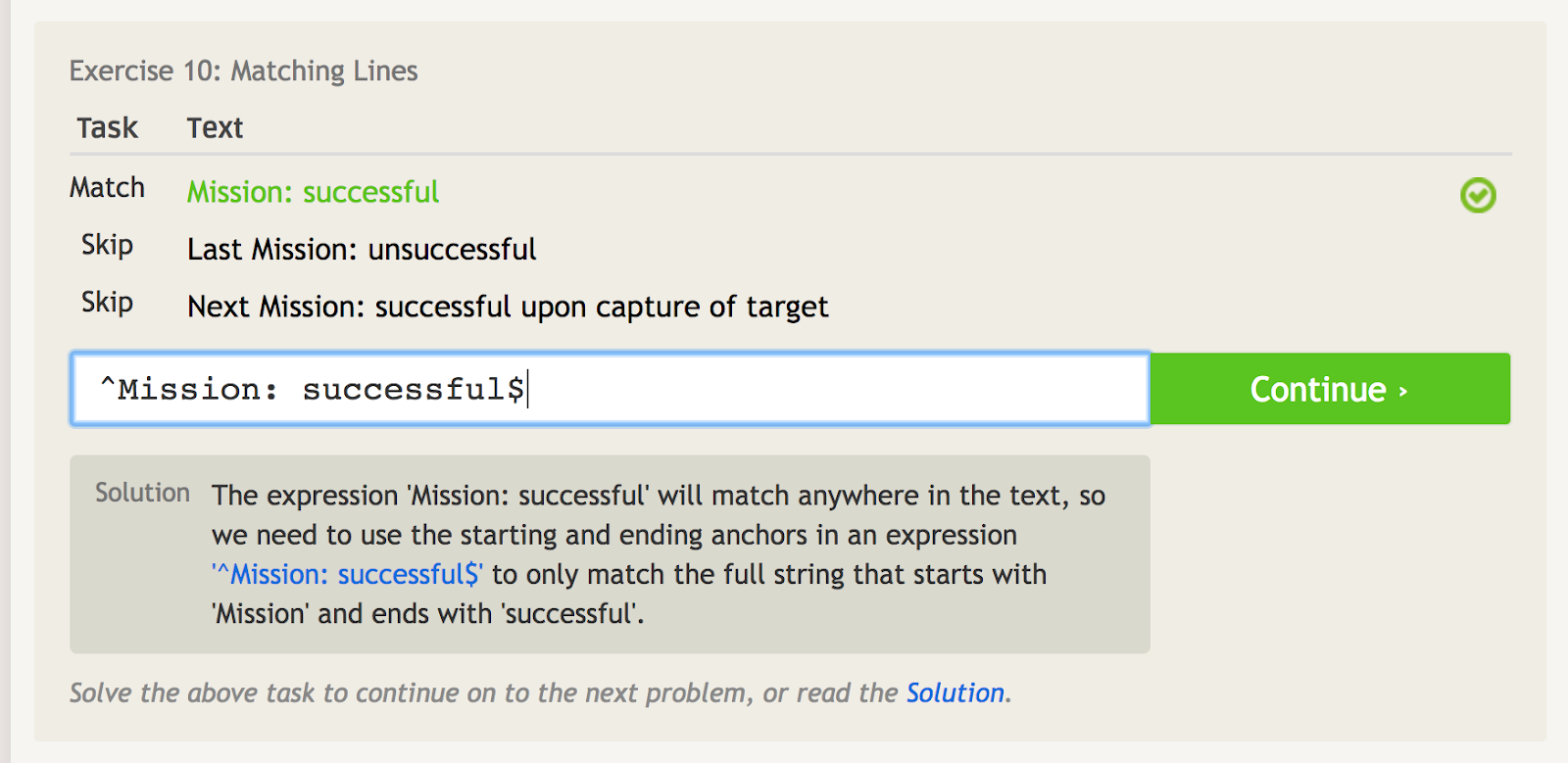
O carpete assinala a âncora de partida, para que possamos corresponder apenas à primeira frase aqui.
Vamos dizer que tem um monte de campanhas AdWords que começam todas com a mesma frase (porque você é um mau planeador para o futuro):
- Freemium Campaign Final
- Nossa primeira Campanha Freemium
- Promoção da Campanha Freemium criativa
- Campanha de teste Freemium
Quer escrever ^Campanha Freemium para igualar a primeira, e nenhuma das outras.
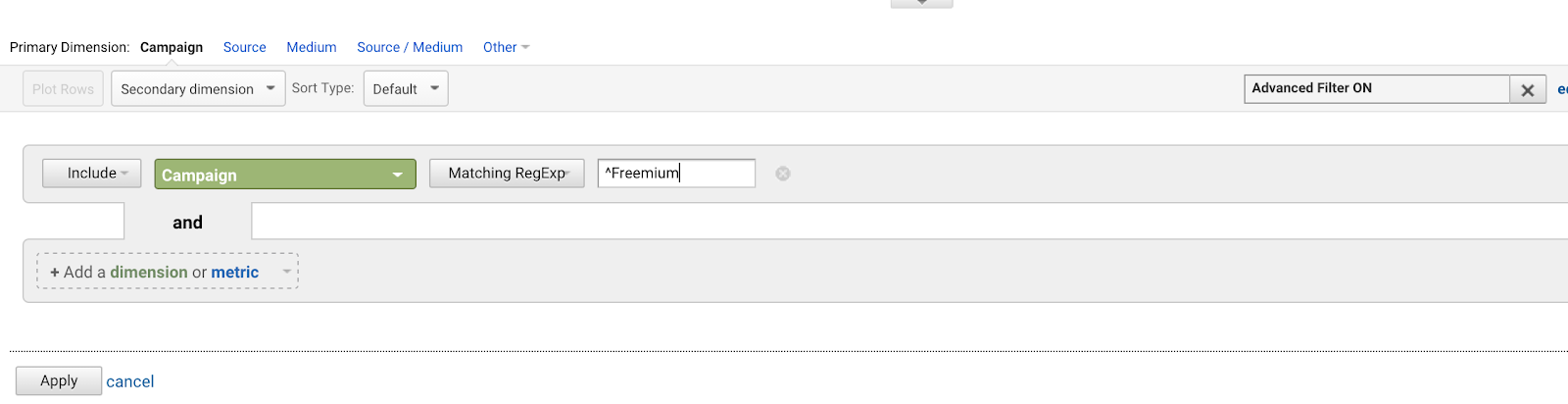
Usar o carpete (^) corresponde a cadeias que começam com aqueles caracteres
Sinal de dólar ($)
Sinal de dólar ($) significa que uma frase termina com algo.
Quando você combina os dois, você pode ter como alvo a frase exata correspondente.
Se você lançou uma campanha intitulada “paidacquisitionfb” e depois lançou uma chamada “paidacquisitionfb-2” porque você não planejou com antecedência e acha que teria outras campanhas com o mesmo título (acontece o tempo todo), você poderia isolar a primeira escrevendo:
^paidacquisitionfb$
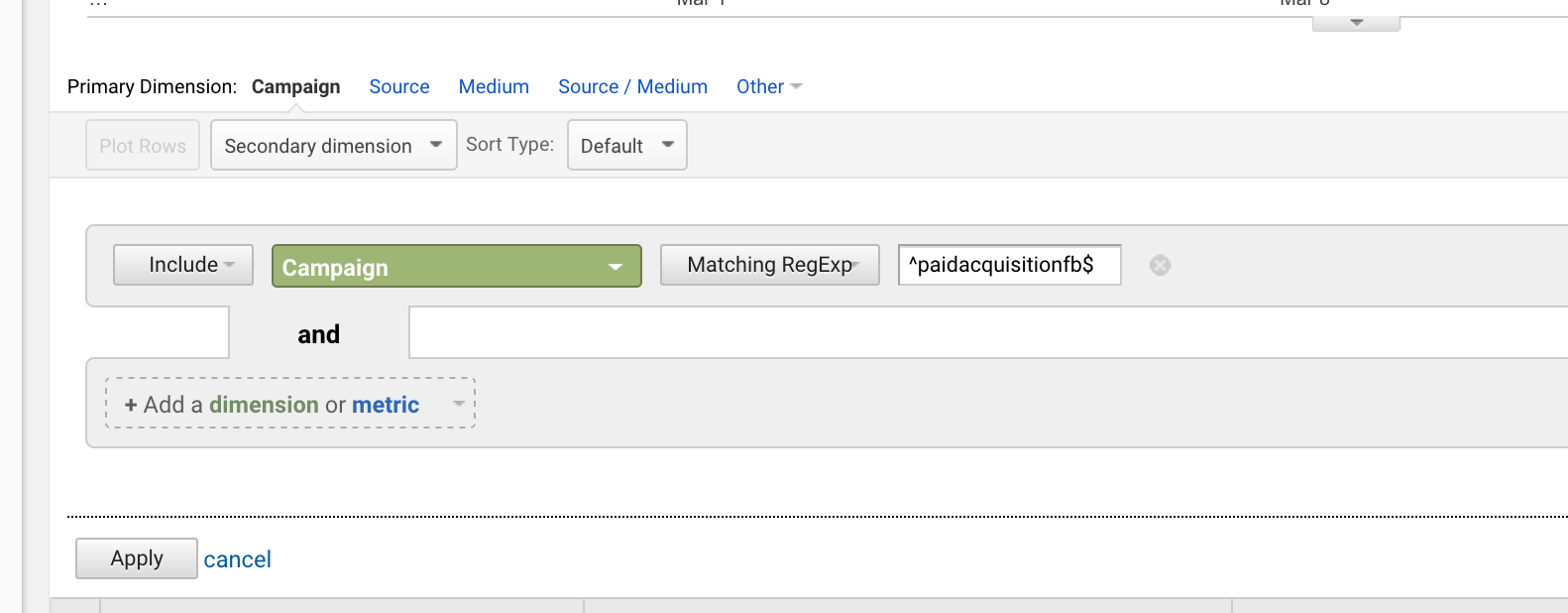
Usar o carett e o dólar juntos é muito comum.
Se você tem toneladas de páginas de categoria no seu blog, por exemplo, e todas elas terminam em um número de página, você pode escrever uma simples peça do Google Analytics regex para ver apenas páginas de categoria do blog (^/page/*/$). Isso lhe daria listas como:
- /página/1
- /página/2
- /página/3
…e assim por diante.
Ponto (.)
Um ponto (.) corresponde a qualquer caractere, o que significa qualquer coisa que você possa encontrar no seu teclado: números, letras, até mesmo espaço em branco. Não é super útil por si só, mas é usado o tempo todo em conjunto com outras expressões regulares, especialmente o asterisco (a seguir).
Vamos dizer que você quer usá-lo por si só, e vamos usar o exemplo “ki…”. Isso combinaria com qualquer coisa que comece com as letras K e eu, e depois os próximos dois caracteres, sejam eles quais forem.
Então se você tivesse uma string que incluísse as palavras kill, kind, kiss, kin, kid!, e kit, combinaria com todos eles. Espera, o quê? Sim, combinaria com “kit” e “kin” desde que haja um espaço depois (também pega no espaço em branco). Seguindo essa lógica, ele também pegaria o ponto de exclamação em “kid!”
Você pode ver porque as coisas ficam confusas se você usar este sozinho.
Aqui está uma ilustração do exemplo acima usando Regex101.com:
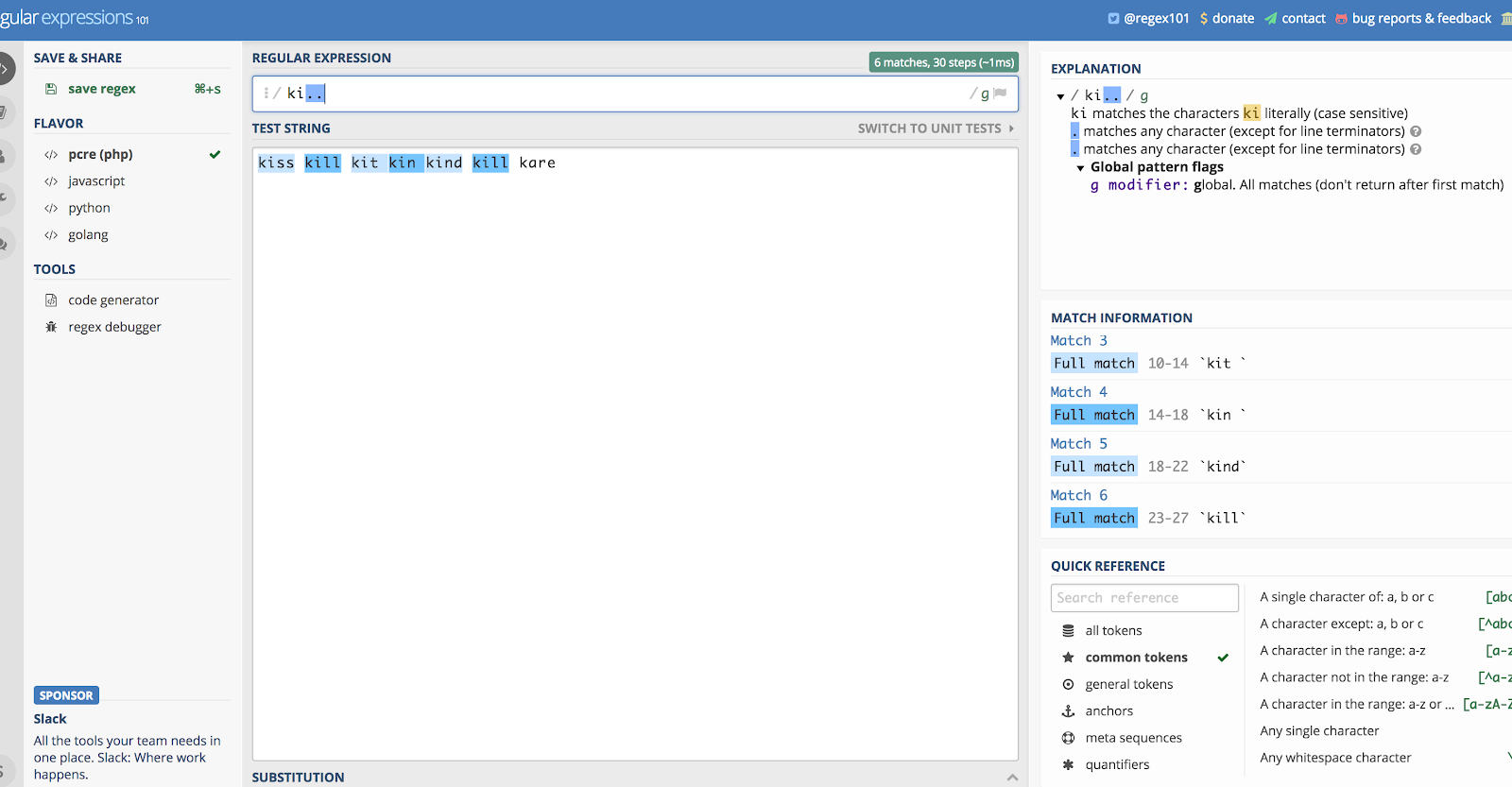
O ponto (.) corresponde a quase tudo.
Asterisco (*)
O asterisco (*) corresponde a zero ou mais dos itens anteriores. Um pouco confuso quando o dizes desta maneira, por isso vou apenas usar um exemplo.
Lembras-te daquele anúncio “wazzup” da Budweiser há algum tempo atrás? Seria muito difícil adivinhar como alguém iria soletrar essa frase se estivesse procurando por ela (digamos, no YouTube). Mas você poderia teoricamente encapsular todas as variações ortográficas fazendo isso:
waz*up
Aqui está uma ilustração de como isso funciona em regex101:
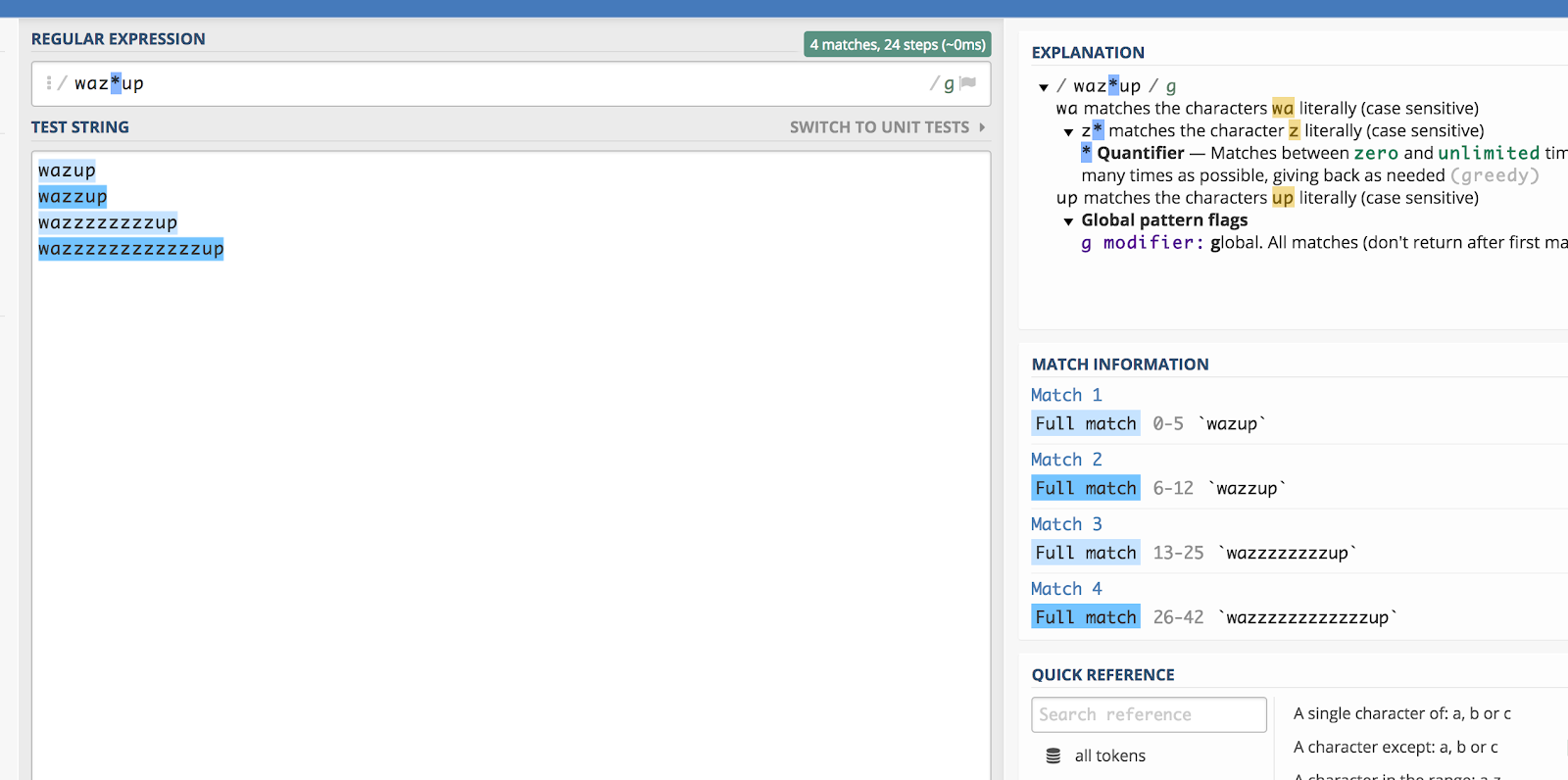
O asterisco (*) corresponde ao zero caracter anterior ou mais vezes.
Se você quiser obter uma super precisão e conta para caracteres maiúsculos e minúsculos, você pode escrever algo como isto:
*
Mas eu divago.
Onde o asterisco é realmente mais poderoso e mais comumente usado é com um ponto ou como parte de outras combinações regex.
Combinação de ponto asterisco (.*)
A combinação de ponto asterisco (.*) basicamente significa que vale tudo. É muito comumente usado.
Você usaria esta combinação quando você quer combinar qualquer coisa em uma string. Como o ponto significa corresponder a qualquer caractere, e o * significa corresponder a zero ou mais caracteres antes dele, este combo é muito poderoso.
Exemplo: você tem vários tipos diferentes de contas de clientes, mas você gostaria de ver seus dados para todos eles. Todas elas têm páginas semelhantes, por isso as suas páginas são algo parecidas com isto:
/customer/pro/login/
/customer/free/login/
/customer/starter/login/
Pode escrever o seguinte regex para fazer isso:
/customer/.*/login
Utilizo normalmente esta expressão regex do Google Analytics para configurar segmentos para utilizadores com um ID de utilizador.
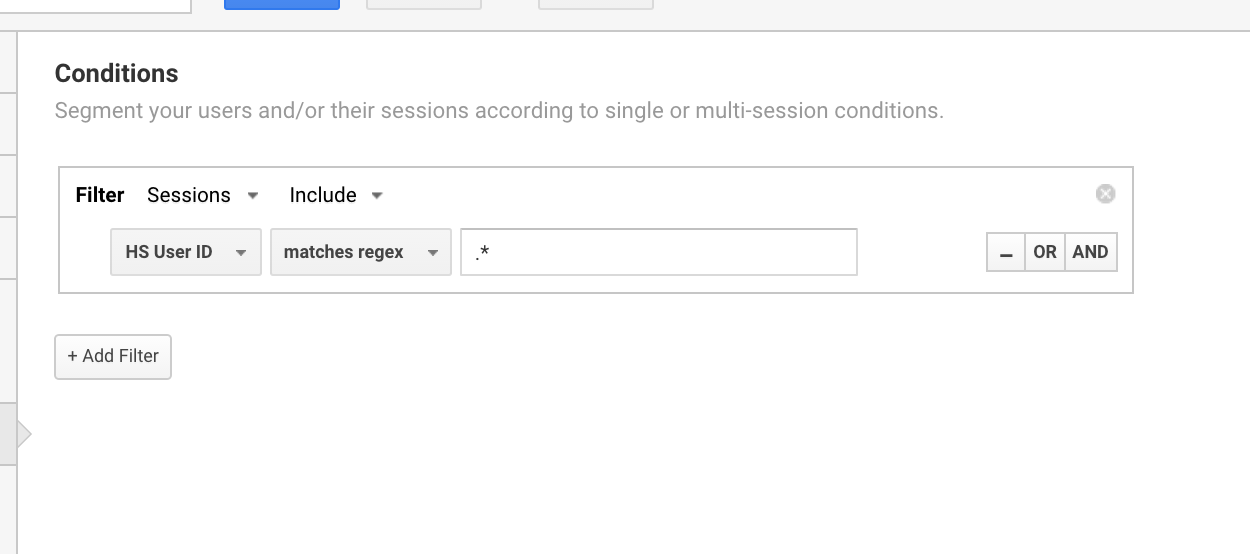
Usar o Google Analytics regex para isolar todas as sessões que têm um ID de utilizador.
Sinal de Plus (+)
O sinal de mais (+) é muito semelhante ao *, excepto que corresponde a UM ou mais dos caracteres anteriores. Não há muito mais do que precisa ser dito neste aqui, apenas que é muito ligeiramente diferente do asterisco. Aqui está a diferença:
Magine you have the words: hello, hhello, and hhhello.
If you write hh+ello it will match only the second two, but if you write hh*ello, it will match all of them.
Minor distinction. Na realidade, eu quase sempre uso o asterisco em vez do sinal de mais.
Ponto de interrogação (?)
O ponto de interrogação (?) é fácil. Significa simplesmente que o último caractere é opção.
Diga que não se importa muito se a palavra é plural ou não (como com sapatos). Pode ser “sapato” ou “sapatos”, e você quer capturá-lo de qualquer maneira. Então, você pode escrever “shoes?”
Aqui está um exemplo usando o meu nome. Se alguém escrevesse “Alex Birket” durante uma busca no site, eu provavelmente ainda gostaria de ver isso. Então eu posso escrever:
Alex Birkett?
Aqui está como fica em regex101.com:
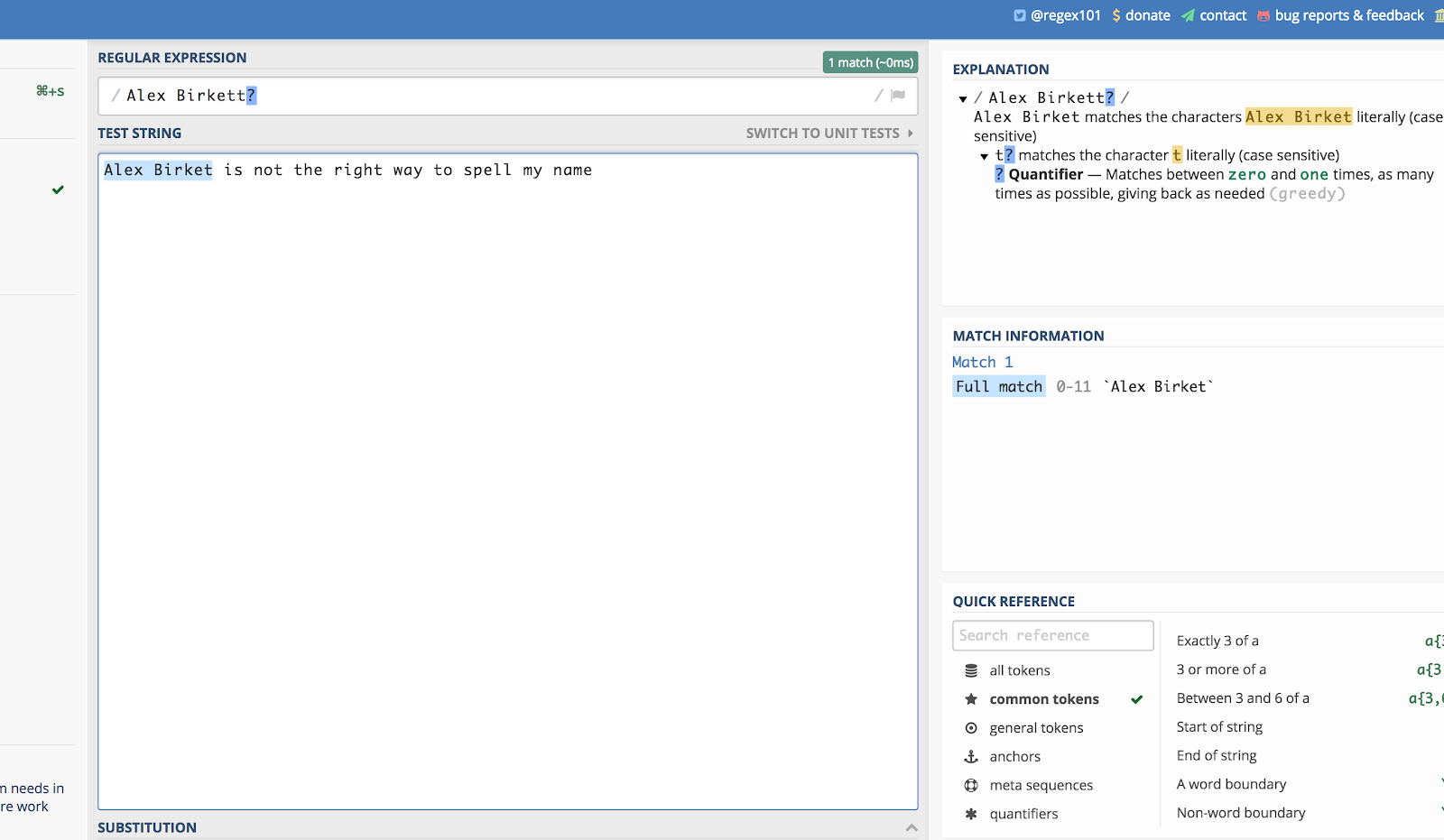
O ponto de interrogação (?) faz com que o último caractere que o precede seja opcional.
Parênteses ()
Parênteses funcionam da mesma forma que funcionam em matemática. Eles dizem-lhe para priorizar e isolar a lógica que está em jogo dentro deles.
Digamos que tem uma empresa SaaS com três ofertas e quer corresponder a todas as suas páginas de preços. As suas URLs são as seguintes:
site.com/products/meetings/pricing
site.com/products/crm/pricing
site.com/products/email/pricing
Para apanhar todos estes três, você poderia usar uma expressão regular como esta:
^/products/(meetings|crm|email)/pricing$
Squadrar parênteses ()
quadrar parênteses () criar uma lista. Se você tem três cadeias, “coisa1”, “coisa 2” e “coisa3”, você poderia combiná-las todas escrevendo “coisa” ou “coisa” (mais em traços em um pouco – eles são comumente usados com colchetes.
Parênteses quadrados podem ser usados para combinar várias iterações de uma palavra ou cadeia, enquanto também exclui várias outras iterações. Por exemplo, se você quiser combinar “can,” “man,” e “fan,” mas não “dan,” “ran,” ou “pan,” você poderia usar o seguinte regex para fazer isso:
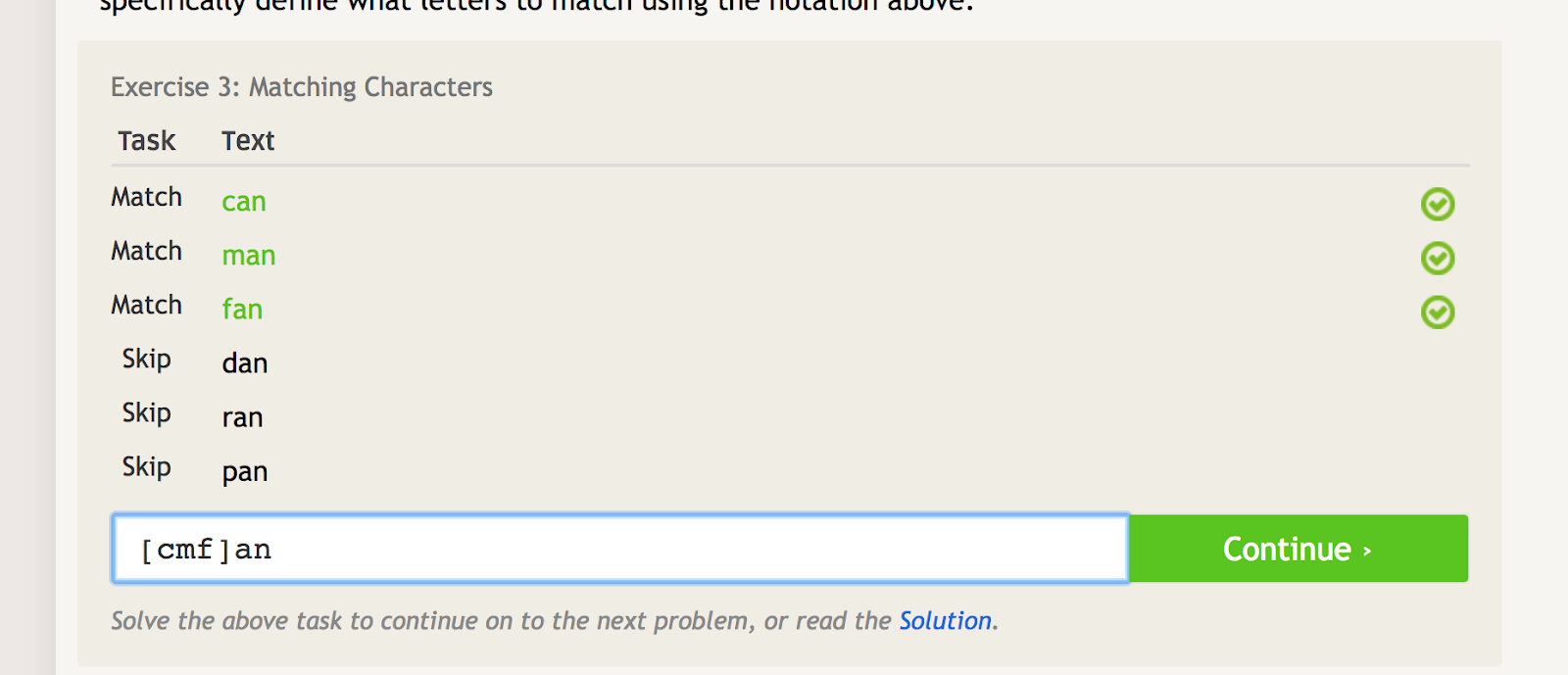
Parênteses rectos criam várias condições de correspondência, dependendo dos caracteres que você colocar dentro deles. – fonte da imagem
>
Isto é algo que pode usar se tiver alguns produtos diferentes com nomes semelhantes, como “shoes1,” shoes3,” e “shoes5,”. Você pode combinar esses, e nada mais, usando “shoes”
Dashes (-)
Dashes (-) funcionam para criar listas lineares de itens.
Como dentro, quando você está usando parênteses rectos, você não tem que simplesmente listar tudo para fora se ocorrer linearmente. Então se você quisesse combinar uma seqüência de números onde o último poderia ser qualquer coisa de zero a nove, você poderia escrever isto:
1234
Or, você poderia escrever o muito mais simples:
1234
Isto funciona para letras, também. Vamos imaginar que você tem uma categoria de página que termina em duas letras aleatórias. Algo assim:
/page-aa/
Você pode combinar todas elas escrevendo:
/page-*/
Você pode ver um exemplo disso em regex101 aqui:
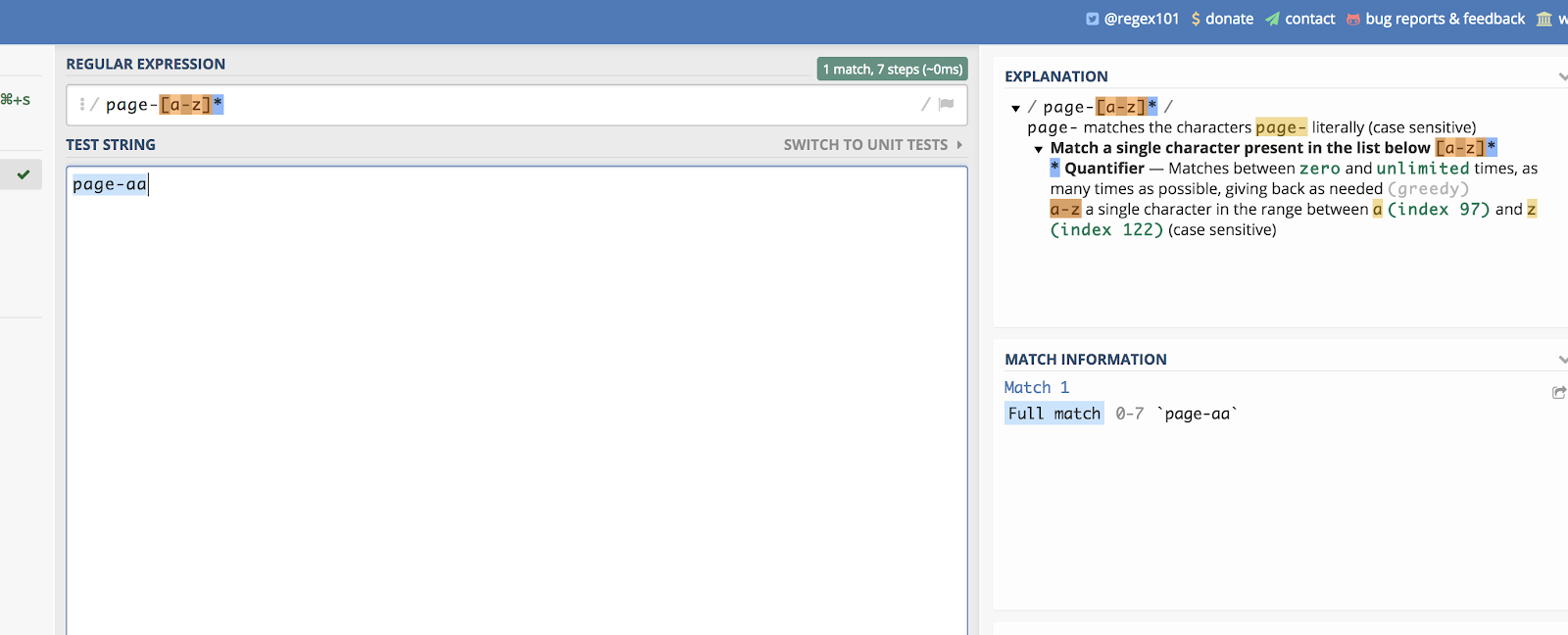
Dashes ajudam a criar uma lista linear para combinar.
Curly brackets ({ })
Curly brackets ({}) diz-lhe quantas vezes deve repetir o último item.
Por exemplo, se você quiser combinar apenas “wazzzzup,” você poderia usar “waz{4}up”.
Mas se você quisesse combinar “wazzzzzup,” e “wazzzup,” mas não “wazup,” você poderia usar “waz{3,5}up”. Isto é basicamente dizer para combinar o caracter “z” não menos de 3 vezes, mas não mais de 5 vezes.
Curly brackets tell you how many times to repeat the last item.Curly brackets tell you how many times to repeat the last item. – fonte da imagem
Eu realmente não tenho usado muito esta expressão regular no Google Analytics, mas um caso de uso comum pode ser para códigos postais. Normalmente, os dois primeiros caracteres são os mesmos numa cidade (78- para Austin, TX, por exemplo). Então você poderia combinar qualquer código postal de Austin, TX escrevendo:
78{3}
Esta diz que as últimas três letras podem ser qualquer número aleatório de zero a nove.
Google Analytics RegEx: Exemplos específicos que você pode usar
Um dos casos mais comuns de uso do Google Analytics regex é para construir filtros. Vamos caminhar por três exemplos, um simples e outro um pouco mais complicado.
Primeiro, um exemplo inspirado por um ótimo post no Search Engine Land de Jenny Halasz.
Vamos dizer que você tem uma arquitetura de site bagunçada, mas você quer olhar para todos os posts com um certo subdiretório. Pode ser qualquer coisa, digamos uma categoria de site ou tipo de conteúdo. Neste exemplo, estamos à procura de uma categoria no site para /music/, mas apenas no terceiro subdirectório. Neste caso, você pode escrever ^/.*/.*/music/.* e ele lhe dará aquele relatório.

Este regex do Google Analytics mostrará apenas /music/ no terceiro subdiretório. – fonte da imagem
Parece confuso num relance – mas depois de aprender o que significam estas expressões regulares, é bastante simples. Basicamente, estamos apenas dizendo à GA para combinar a página de destino que começa com (^) uma barra, depois quaisquer caracteres (.*), depois uma barra, depois quaisquer caracteres (.*), depois uma barra, e depois música.
LawnStarter usa uma tática similar para relatar. Sua estratégia é criar conteúdo específico da cidade em uma subpasta de suas páginas da cidade, usando o seguinte formato:
https://www.lawnstarter.com/{{ página da cidade transacional }}/{{{ peça de conteúdo informativo }}
Para filtrar o conteúdo de funis de conversão e relatórios de tráfego, eles usam o seguinte regex, de acordo com o fundador Ryan Farley.
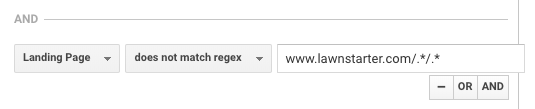
Este regex ajuda o LawnStarter a combinar conteúdo específico da cidade no seu site.
Segundo, vamos caminhar através de como configurar um filtro para uma das suas visualizações do Google Analytics. É provável que você tenha um especialista em implementação que faça isso – mas se não tiver, sempre meça duas vezes e corte uma aqui. É fácil de bagunçar estas coisas (e é também por isso que você deve configurar sua conta do Google Analytics com uma vista sandbox para experimentar as coisas primeiro).
Para configurar filtros, vá para Admin > Filtros > Adicionar filtro.
O filtro mais usado no Google Analytics é provavelmente para excluir tráfego do(s) seu(s) endereço(s) IP.
Para muitos, você pode configurar isso de forma simples, porque você só tem um IP. Para empresas maiores, você pode ter uma série de IPs, e você pode configurar exclusões mais facilmente com o Google Analytics regex.
Por exemplo, se você escreveu 63\.212\.171\., isso excluiria todos os endereços IP de 63.212.171.1 a 63.212.171.9.
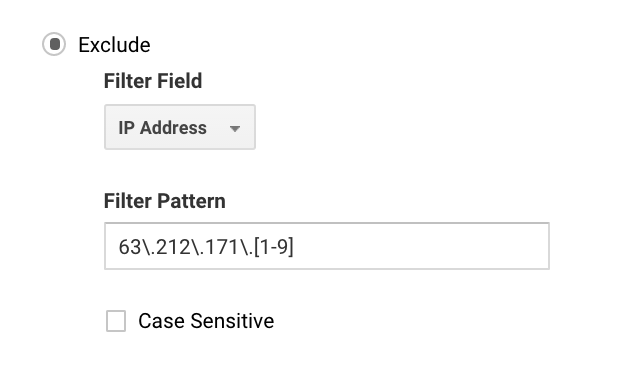
Este Google Analytics regex exclui vários endereços IP.
Outra coisa que você pode fazer com o Google Analytics regex é configurar filtros para limpar os parâmetros da consulta.
Isto pode ser tanto irritante quanto problemático para sua análise de dados.
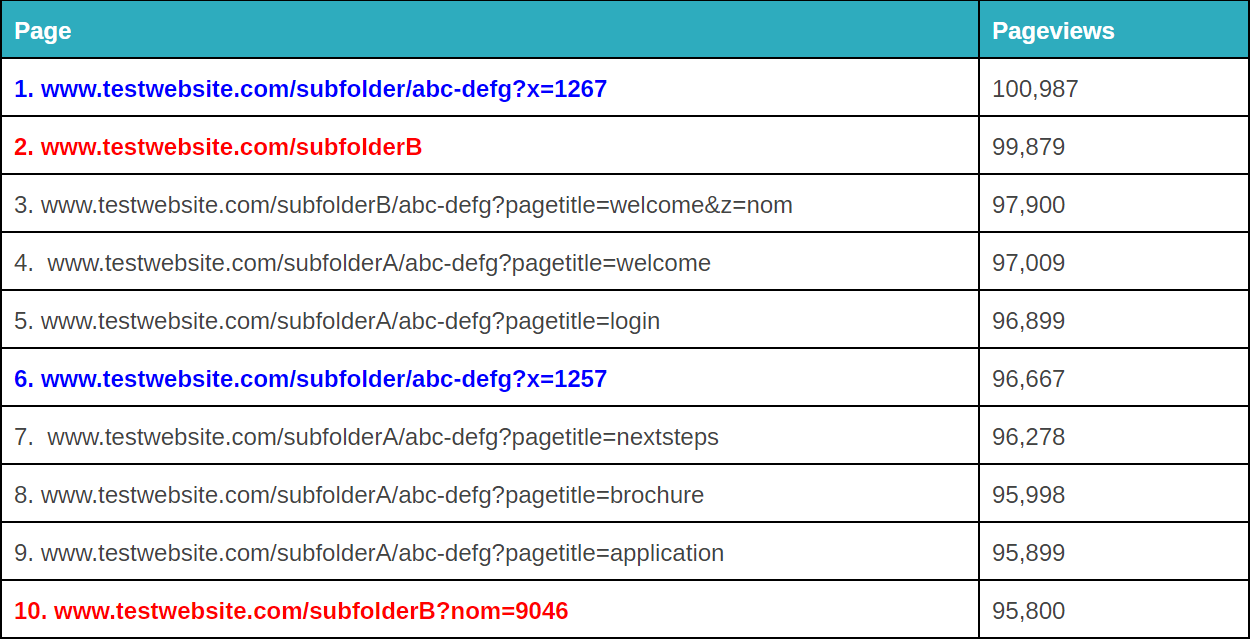
Parâmetros de consulta fraturados podem ser incômodos. – fonte da imagem
Depende de como é a sua situação específica, mas existem algumas maneiras diferentes de usar o regex para limpar isso (nota: você também pode fazer isso no Google Tag Manager ou Excel, dependendo da extensão do problema. Mais sobre isso aqui).
Finalmente, vamos falar sobre um exemplo que podemos usar para organizar melhor nosso rastreamento de subdomínios. Se você tiver vários domínios ou subdomínios, é possível que você tenha URLs duplicadas, a menos que você configure um filtro para pré-pender seu nome de host para o seu pedido URi. Em outras palavras, você pode ter que URLs:
- site.com/about
- blog.site.com/about
Estas representam duas páginas diferentes (uma é uma página sobre sua empresa e a outra é uma seção sobre seu blog). Mas ambas seriam vistas no Google Analytics como /sobretudo, a menos que você configure o seguinte filtro (usando a combinação ponto-asterisco do Google Analytics expressões regulares):
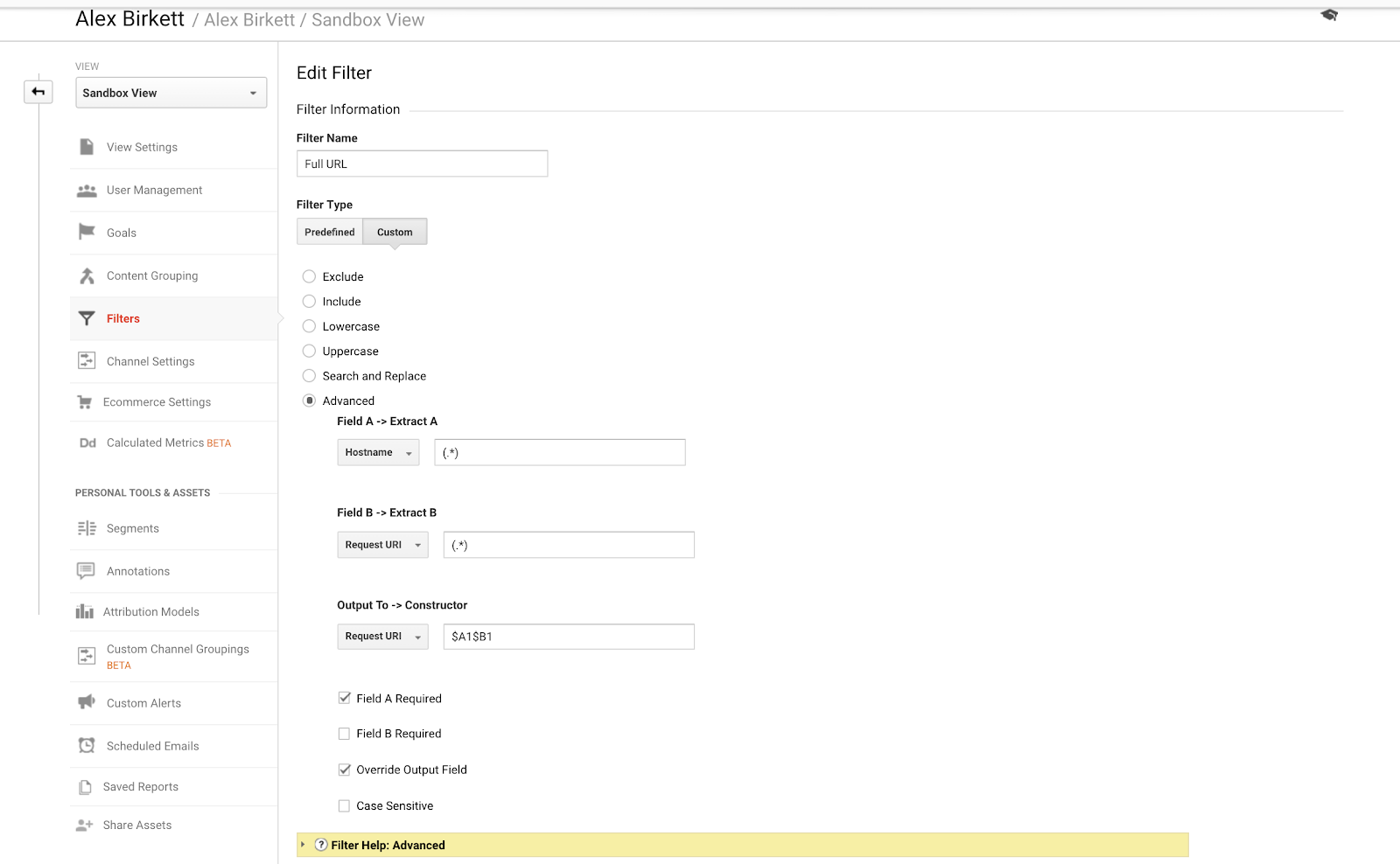
É bastante simples de configurar este filtro GA fundamental. – image source
Na verdade, já abordámos como configurar estes filtros bastante aprofundadamente num post anterior do KlientBoost sobre o rastreio entre domínios e subdomínios.
Google Analytics RegEx Tips & Erros a evitar
Expressões regulares são uma daquelas coisas que só tem de praticar e sujar as mãos para aprender. Como tal, você vai cometer erros.
Essa é a dica mais importante, realmente: experimente as coisas e veja se elas funcionam. Eu listei toneladas de recursos neste post sobre como testar seu regex, do regex101.com para o regexbuddy.com. Mergulhe seus dedos dos pés e use estes recursos.
No entanto, com alguma previsão e heurística, você pode aprender mais rapidamente e pegar mais erros.
Uma coisa a realmente aprender é como “escapar” no regex (nós falamos sobre isso com a barra invertida). Leho Kraav, CTO do CXL Institute, coloca assim:
“Eu diria “aprender sobre como escapar apropriadamente das coisas” – é fácil obter desencontros quando os caracteres são os mesmos, mas seu significado é diferente dependendo se escapou ou não”
Por exemplo, se sua consulta tem um ponto de interrogação, essa também é uma expressão regular, então você precisa deixar isso claro com a barra invertida. Chris Mercer, fundador da MeasurementMarketing.io, também diz que não aprender essa capacidade é um dos maiores erros que ele vê os iniciantes cometerem:
“O erro mais comum que vemos com os iniciantes usando regex é esquecer de “escapar” dos símbolos regex. Por exemplo, se você está procurando páginas que combinam com regex “obrigado/?sucesso=sim”, não vai funcionar. O próprio “?” é um símbolo regex, e precisa ser desativado usando o “escape character” (o “?”). Neste caso, “thankkyou/\?success=yes” funcionaria.”
Outra dica? Mantenha-o simples. As pessoas tentam complicar as coisas (veja o regex mais complicado que você já viu, escrito por Leho, aqui), mas expressões regulares são “gananciosas” e combinam o máximo que podem. O Google Analytics publicou um blog com dicas e explicou assim:
“Se você precisar escrever uma expressão que combine com “novas visitas”, e as únicas opções que você vai comparar são “novas visitas” e “visitas repetidas”, apenas a palavra “novo” é boa o suficiente.
Vão combinar tudo o que puderem, a menos que você os force a não combinar. Se a sua expressão for “visitas”, vai combinar com “novas visitas” e “visitas repetidas”. Afinal de contas, ambos incluíram a expressão “visitas”. Para torná-las menos gananciosas, você tem que torná-las mais específicas”.
Então comece devagar, mantenha simples, e não se sobrecarregue com complexidade (a chance de erro se correlaciona com complexidade neste caso).
Mercer também reitera este ponto, aconselhando a tomar as coisas gradualmente:
“Quando você começar, concentre-se em ficar bom… e depois melhore. É fácil ficar sobrecarregado com todas as diferentes possibilidades que o regex lhe oferece, mas se você apenas começar com o básico, como dominar o símbolo para “ou” (o ” | “) você rapidamente ganha experiência e começa a perceber o que é possível com regex”
Dica final minha: aprenda coisas do Google. Isto é verdade para qualquer programação, mas especialmente para expressões regulares. Você vai esquecer as coisas, e se você não escrever regex diariamente, não vale a pena memorizar tudo. Aprenda a procurar coisas e encontre respostas para o que você está tentando fazer.
Fora do Google Analytics: RegEx para outros usos de marketing
Regex também é algo que todos os praticantes de SEO devem procurar. Primeiro, obviamente, porque SEO e análise digital (por exemplo, Google Analytics) estão inextricavelmente entrelaçados. Segundo, porque algumas das mesmas expressões que escrevemos para filtrar e combinar caracteres nos nossos dados do Google Analytics também podem ser usadas na extracção de dados para tácticas de SEO.
Em outras palavras, expressões regulares são importantes para o “web scraping”.
No caso do “web scraping” e SEO, você normalmente estará a trabalhar através de uma linguagem de programação como Python, mas os princípios são os mesmos.
Como exemplo, você poderia raspar todo o texto em negrito em uma página usando isto:
<strong>(+)</strong>
Or, como mencionado neste artigo do SEJ, se alguém estivesse raspando ESPN para todos os autores, poderia escrever isto:
“colunista”:”(.*?)”
Por uma questão de coesão e sanidade, eu não mergulharei até o fim no raspamento avançado da web. O suficiente para saber que o regex também é importante nesta área. No entanto, se você gostaria de aprender mais, sugiro estas fontes:
- Raspagem da Web com Expressões Regulares
- Raspagem com Expressões Regulares (Stanford)
- Como usar Regex para SEO & Extracção de Dados do Website
Expressões Regulares também o ajudam a trabalhar com os seus dados SEO, para além de simplesmente raspar a Web. Por exemplo, você pode usar regex para personalizar ainda mais como você está usando Screaming Frog.
Jenny Halasz deu um bom exemplo de como usar regex para limpar os dados em um site de busca post:
“Por exemplo, vamos dizer que você tem uma lista de URLs e você precisa dividi-las apenas no TLD (Top Level Domain).
Você pode usar um simples find/replace para http e www, mas como você elimina facilmente todos os nomes de arquivos? Você poderia removê-los todos manualmente, mas isso é uma dor. Usando um simples curinga regex (/*), você pode soltar a barra e tudo o que vem depois.”
Poderíamos falar para sempre sobre expressões regulares para SEO e raspagem da web, mas vou apenas ligar a alguns bons recursos no caso de você querer aprender mais (é uma linguagem muito versátil, afinal de contas, com muitos casos de uso além da análise):
- Como a expressão regular afeta a SEO
- 5 Truques Poderosos de Redirecionamento de Htaccess
- Como usar a expressão regular para segmentação de relatórios
Conclusão
Google Analytics regex é realmente algo que todo analista deve saber, mesmo que você não se preze como técnico. Além disso, conhecer algumas expressões regulares (ou pelo menos como procurar respostas e aplicá-las aos problemas certos) pode ajudar os marqueteiros com várias atividades também.
Apenas dizer que não é um conjunto de habilidades muito comum, então você provavelmente irá impressionar alguns colegas com suas novas habilidades técnicas de marketing.
Então eu peço que você, comece a aprender, e mais importante, apenas comece a praticar usando expressões regulares. Elas não são assim tão assustadoras.