Čas čtení:
Diskriminační modely, označované také jako podmíněné modely, jsou třídou modelů používaných ve statistické klasifikaci, zejména v řízeném strojovém učení.
Na rozdíl od generativního modelování, které studuje ze společné pravděpodobnosti P(x,y), diskriminační modelování studuje P(y|x) i.Tj. předpovídá pravděpodobnost y(cíle), když je dáno x(trénovací vzorky).
- Pochopíme to pomocí matematického příkladu:
Předpokládejme, že vstupní data jsou x a množina značek pro x je y. Uvažujme následující 4 datové body:
(x,y) –> {(0,0), (0,0), (1,0), (1,1)}Pro výše uvedená data bude p(x,y) následující:
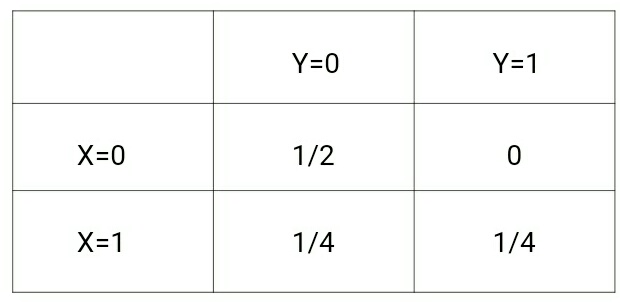
zatímco p(y|x) bude následující:
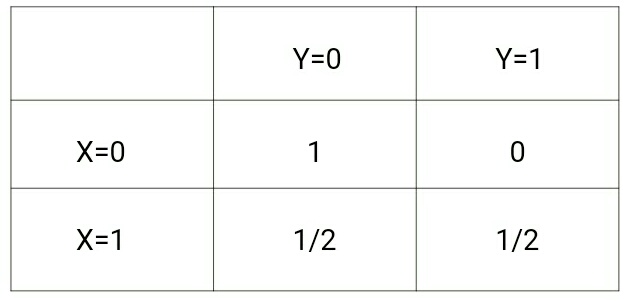
Podíváme-li se na tyto dvě matice, pochopíme rozdíl mezi oběma rozděleními pravděpodobnosti.
Diskriminační algoritmy se tedy snaží naučit p(y|x) přímo z dat a poté se snaží data klasifikovat.
Na druhou stranu generativní algoritmy se snaží naučit p(x,y), které lze později transformovat na p(y|x) a data klasifikovat. Jednou z výhod generativních algoritmů je, že pomocí p(x,y) lze generovat nová data podobná stávajícím datům. Na druhou stranu diskriminační algoritmy obecně podávají lepší výkon v klasifikačních úlohách.
V diskriminačních modelech musíme pro předpověď značky y z trénovacího příkladu x vyhodnotit:
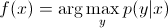
což pouze vybírá, jaká je nejpravděpodobnější třída y vzhledem k x. Je to jako bychom se snažili modelovat rozhodovací hranici mezi třídami. Toto chování je velmi zřetelné u neuronových sítí, kde lze vypočtené váhy považovat za složitě tvarovanou křivku izolující prvky třídy v prostoru.
- zaměřuje se na rozhodovací hranici.
- silnější s množstvím příkladů.
- není určena k použití neoznačených dat.
- pouze úloha s dohledem.
Diskriminační klasifikátory Příklady
Diskriminační modely jsou preferovány v následujících přístupech:
- Logistická regrese
- Skalární vektorový stroj
- Tradiční neuronové sítě
- Vyhledávání nejbližších sousedů
- Podmíněná náhodná pole (CRF)s
Výhody diskriminačního modelu
- Diskriminační modely se používají pro získání lepší přesnosti na trénovacích datech.
- Když jsou trénovací data velká ,bude přesnost pro budoucí data dobrá.
- Když je počet parametrů omezený, diskriminační model se bude snažit optimalizovat předpověď y z x, zatímco generativní model se bude snažit optimalizovat společnou předpověď x a y. Z tohoto důvodu diskriminační modely překonávají generativní modely v úlohách podmíněné predikce.
.