Google Analytics regex (dvs. regulære udtryk) er et undervurderet færdighedssæt.
Hvis du ønsker at foretage nogen form for filtrering eller målretning ud over det grundlæggende, vil et godt greb om regex give dig Analytics superkræfter.

Regex giver dig superkræfter. – image source
Selvfølgelig har regulære udtryk meget bredere anvendelsesområder end analyse og markedsføring. Men i forbindelse med denne artikel vil vi dække nogle taktiske anvendelsestilfælde, der kan hjælpe dig med brugerindsigt, dataorganisering og endda avancerede målretnings- og søgemaskinemarkedsføringsanvendelsestilfælde.
Men lad os først kort opsummere, hvad regulære udtryk er, specifikt i forhold til Google Analytics.
- Google Analytics RegEx: Hvad er det?
- Google Analytics RegEx Cheat Sheet
- Pipe (|)
- Backslash (\)
- Karet (^)
- Dollartegn ($)
- Punkt (.)
- Asterisk (*)
- Punkt-sterisk-kombination (.*)
- Plus-tegn (+)
- Spørgsmålstegn (?)
- Parenteser ()
- Firkantede parenteser ()
- Trykstreger (-)
- Krumme parenteser ({ })
- Google Analytics RegEx: Specifikke eksempler, du kan bruge
- Google Analytics RegEx Tips & Fejl at undgå
- Udvendigt i Google Analytics: RegEx til andre markedsføringsformål
- Konklusion
Google Analytics RegEx: Hvad er det?
Regulære udtryk er specielle tekststrenge til beskrivelse af søgemønstre.
Hva’?
I relation til analyse hjælper regulære udtryk dig med at finde, definere og udtrække ting. Endnu mere specifikt med Google Analytics kan de hjælpe dig med at oprette mere fleksible definitioner for ting som visningsfiltre, mål, segmenter, målgrupper, indholdsgrupper og kanalgrupperinger.
Helt grundlæggende er de foruddefinerede tegn eller en række tegn, der bredt eller snævert matcher og udvælger mønstre i dine digitale analysedata. De er et generelt værktøj, der kan bruges på mange måder (tonsvis af programmeringssprog og værktøjer tillader regex). Men i Analytics vil vi primært bruge dem til at matche mønstre i data.
Det er selvfølgelig ikke kun nyttigt i Analytics. Især hvis du bruger Google Tag Manager, eller hvis du kører kompliceret målretning på dine A/B-tests, vil du bruge en masse regex. Som Chris Mercer, grundlægger af MeasurementMarketing.io, siger:
“Vi bruger regex på daglig basis. Det hjælper os med at definere alt fra tragttrin-trin i et Google Analytics-mål til en specifik udløser i Google Tag Manager.”
Hvis du imidlertid gerne vil gå i dybden og virkelig lære regulære udtryk, er her et par ressourcer (ikke nødvendigt for grundlæggende ting i Google Analytics, og sandsynligvis for en person med mere tekniske evner):
- Regulære udtryk: The Complete Tutorial
- Mastering Regular Expressions 3rd Edition (Book)
- Learn Regular Expressions the Hard Way
Du kan også lære interaktivt gennem noget som RegexOne eller RegexR, som begge er fede. Men lad os gå forbi det og gennemgå de mest almindeligt anvendte Google Analytics-regex-tegn, så du kan begynde at tage det i brug.
Google Analytics RegEx Cheat Sheet
Se på følgende Google Analytics-regex-tegn som en slags snydeark – du vil sandsynligvis ikke bruge dem med det samme, men ved kort at gennemgå, hvad du er i stand til med regex, kan du søge efter svaret, når det er nødvendigt.
For en kort opsummering har jeg ikke fundet noget mere kondenseret og præcist end denne guide:

En meget kort guide til Google Analytics regex – billedkilde
Du kan dog se, at den alene med den som reference er en smule vag og tvetydig. Så lad os gennemgå de mest almindeligt anvendte Google Analytics-regex og samtidig vise de tilsvarende anvendelsestilfælde.
Pipe (|)
Når du vil sige “OR” skal du bruge et pipe (|). Som i “This | That”, hvilket ville betyde “This OR That”.
Hvis du er en ivrig bruger af Google Analytics-segmenter, er du allerede vant til at bruge logiske OR-operatører.
Dette er et af de enklere og mere almindelige regulære udtryk, der bruges i Google Analytics. Det har mange anvendelsesmuligheder, men en af de mest anvendte er måske, når du opretter mål. Hvis du har to takkesider med forskellige URL’er (/thank-you/ og /subscription-confirmed/), men du gerne vil spore dem begge som en målopfyldelse, kan du bruge dette regulære udtryk.
Du kan også bruge det i filtre. Lad os sige, at du ønsker at få vist en adfærdsrapport om to artikler (om lektioner i indholdsmarkedsføring og indholdsanalyse) med URL’erne /content-marketing-analytics/ og /content-marketing-lessons/. Du kunne skrive som et filter “content-marketing-analytics|content-marketing-lessons” og kun få vist disse artikler.
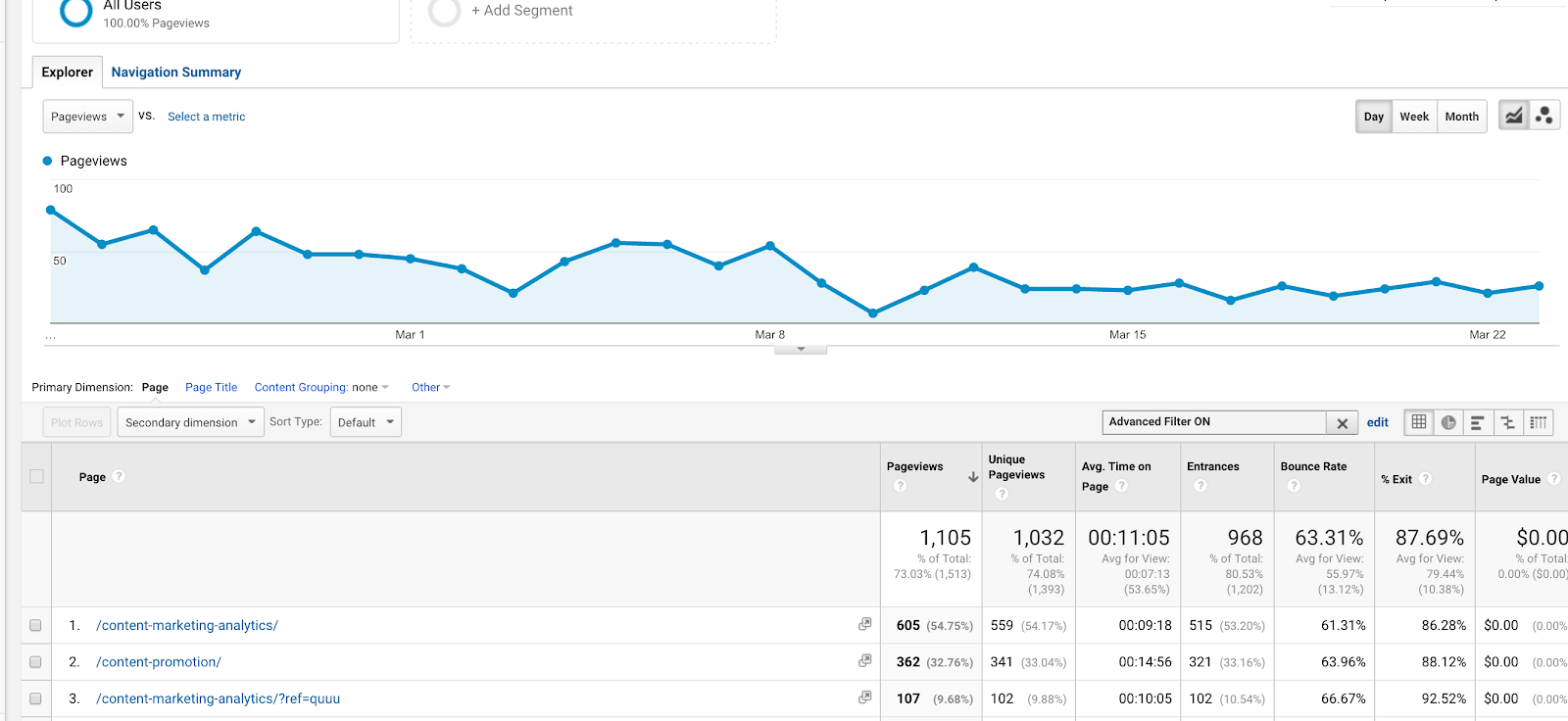
Anvendelse af et rør (|) i et filter for at få resultater for to separate blogindlæg
Backslash (\)
Backslash (\) er et andet ligetil og almindeligt anvendt regulært udtryk i Google Analytics. Det betyder “betragt det næste tegn som almindelig tekst og ikke som regex.”
Med andre ord er der mange regulære udtryk, der forekommer i almindelig tekst, f.eks. punktum, spørgsmålstegn og andre, som vi skal afklare, om de skal læses som regulære udtryk eller almindelig tekst.
En almindelig forespørgselsstreng på nettet bruges, når nogen søger efter noget på dit websted. Når jeg f.eks. søger efter “små hundelegetøj” på petsmart.com, er dette den forespørgselsstreng, der kommer frem:
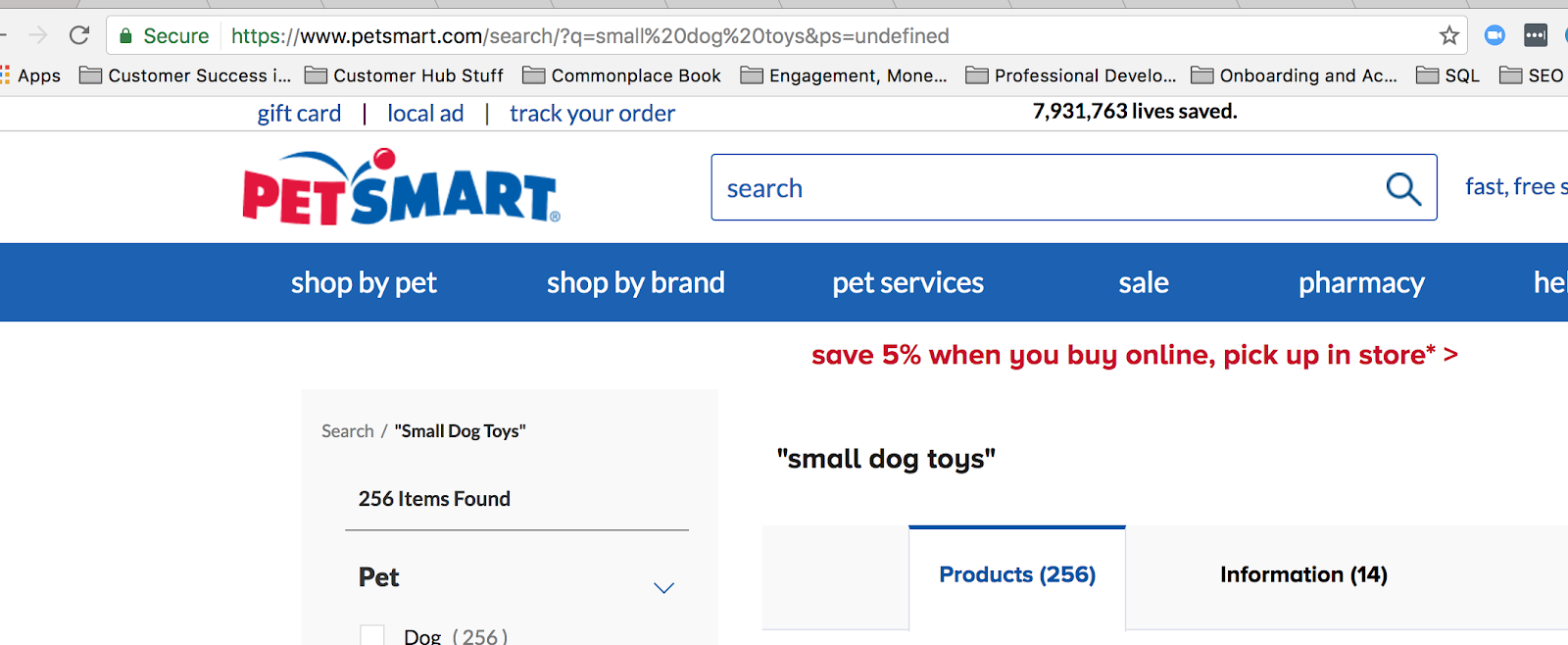
Når du bruger site search, opretter du en forespørgselsstreng i URL’en.
Spørgsmålstegnet her betyder, at der har fundet en søgning sted på stedet, men spørgsmålstegnet er også et almindeligt anvendt regulært udtryk i Google Analytics. Derfor er vi nødt til at præcisere, når vi bruger en backslash, at spørgsmålstegnet i dette tilfælde skal læses som almindelig tekst.
Lad os sige, at vi ønsker at matche alle forespørgselsstrenge i Google Analytics, der starter med /search/?q= (fordi det betyder en søgning). Så ville det regulære udtryk være:
search\/\?q=
Du kan kontrollere dette ved hjælp af en debugger som f.eks. regex101.com:
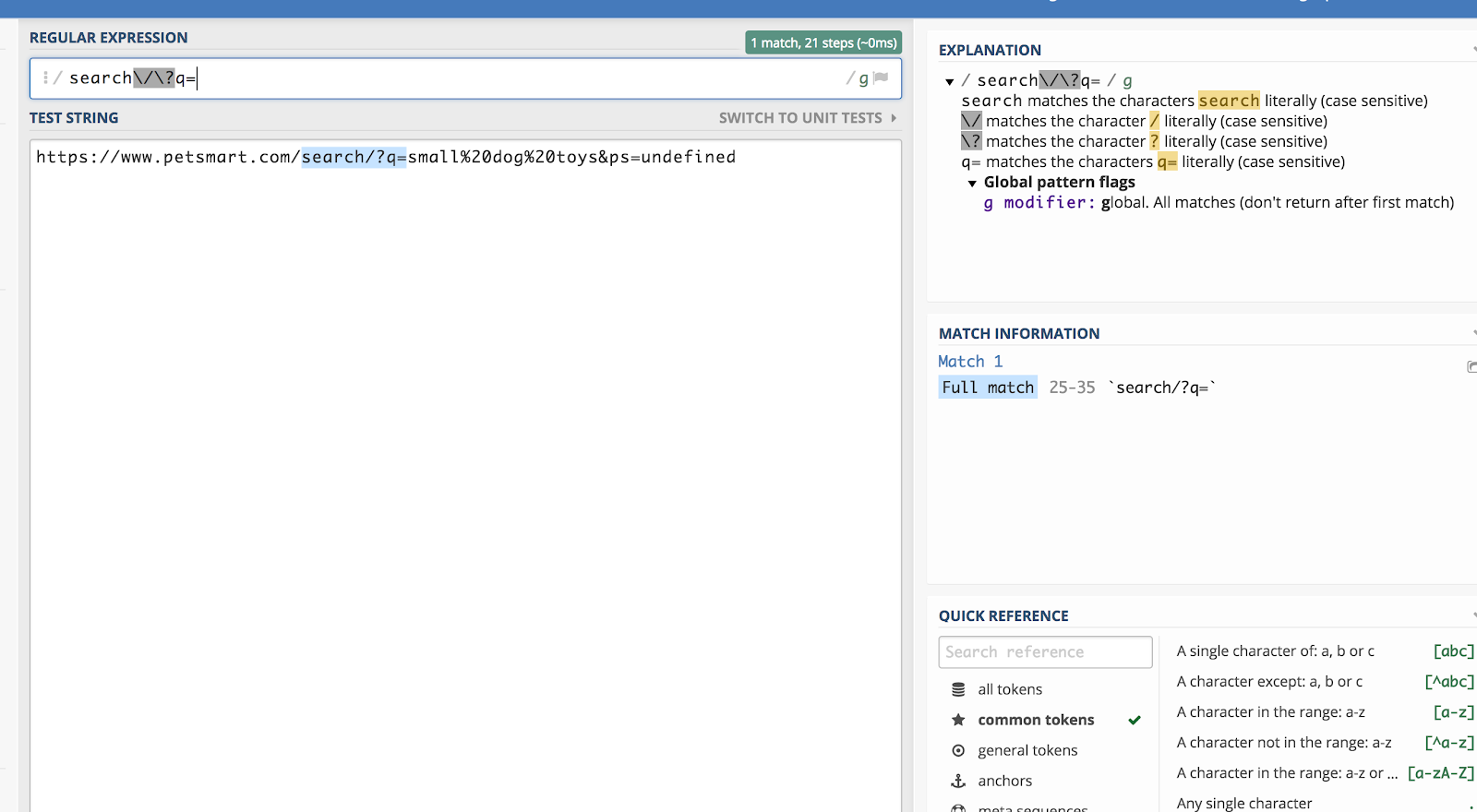
Backslash (\) “undslipper” fra regex for et tegn bagefter og læser det som almindelig tekst.
Karet (^)
Karet (^) betyder, at en sætning begynder med noget. Dette er vigtigt, når du har en sætning, der kan forekomme hvor som helst, men du ønsker at matche sætningen specifikt ved startpunktet. Se f.eks. på dette eksempel med et par forskellige sætninger, der indeholder ordene “Mission: succesfuld.”
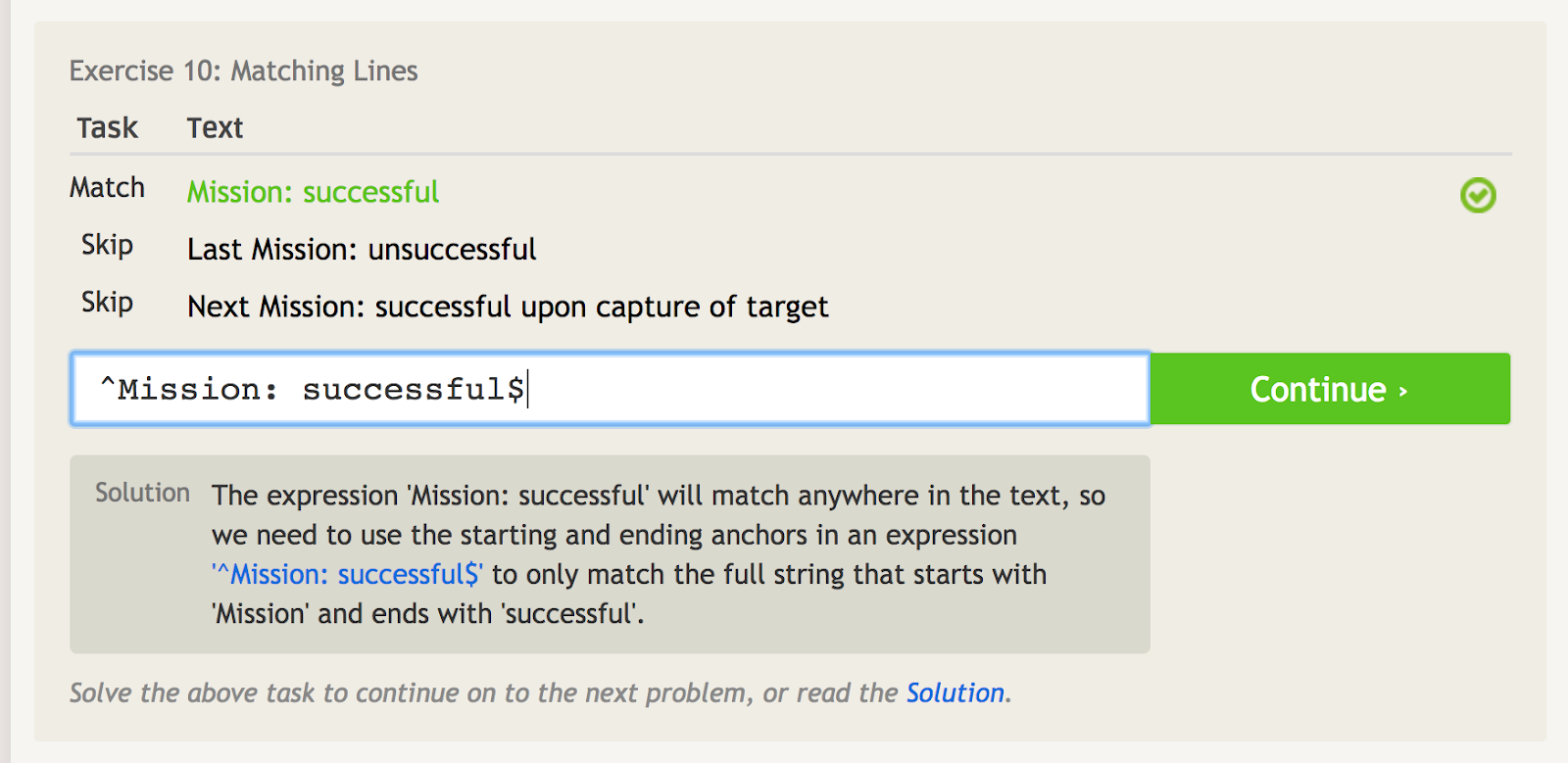
Careten signalerer startankeret, så vi kan udelukkende matche den første sætning her.
Lad os sige, at du har en masse AdWords-kampagner, der alle starter med den samme sætning (fordi du er en dårlig planlægger for fremtiden):
- Freemium Campaign Final
- Vores første Freemium Campaign
- Kreativt Freemium Campaign-tilbud
- Test Freemium Campaign
Du vil gerne skrive ^Freemium Campaign for at matche den første, og ingen af de andre.
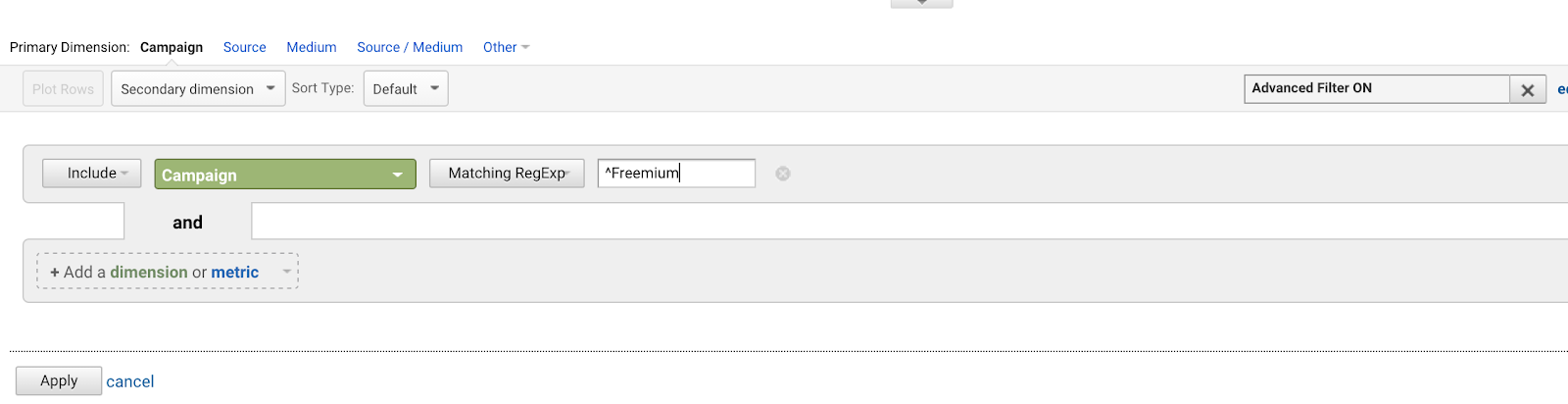
Brug af karet (^) matcher strenge, der starter med disse tegn
Dollartegn ($)
Dollartegn ($) betyder, at en sætning slutter med noget.
Når du kombinerer de to, kan du målrette præcis match-formuleringer.
Hvis du lancerede en kampagne med titlen “paidacquisitionfb” og senere lancerede en kampagne med titlen “paidacquisitionfb-2”, fordi du ikke planlagde godt nok og troede, at du ville have andre kampagner med lignende titler (sker hele tiden), kunne du isolere den første ved at skrive:
^paidacquisitionfb$
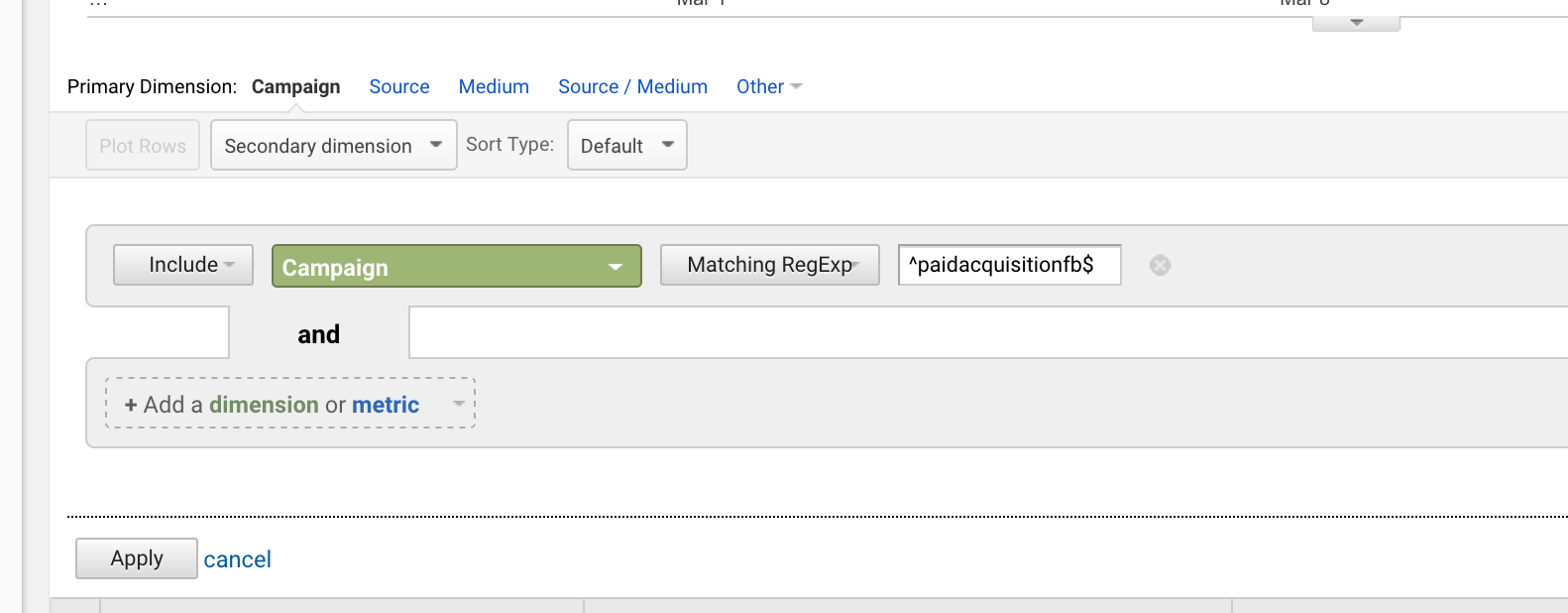
Det er meget almindeligt at bruge carett og dollar sammen.
Hvis du f.eks. har tonsvis af kategorisider på din blog, og de alle ender på et sidetal, kan du skrive et simpelt stykke Google Analytics-regex for kun at få vist blogkategorisider (^/page/*/$). Det ville give dig lister som:
- /page/1
- /page/2
- /page/3
…og så videre.
Punkt (.)
Et punkt (.) matcher et hvilket som helst tegn, hvilket betyder alt, hvad du kan finde på dit tastatur: tal, bogstaver, selv mellemrum. Det er ikke super brugbart i sig selv, men det bruges hele tiden i forbindelse med andre regulære udtryk, især stjernen (kommer nu).
Lad os sige, at du vil bruge det alene, og lad os bruge eksemplet “ki…”. Det ville matche alt, der starter med bogstaverne K og I, og derefter de næste to tegn, uanset hvad de er.
Så hvis du havde en streng, der indeholdt ordene kill, kind, kiss, kin, kid! og kit, ville det matche dem alle. Vent, hvad? Ja, den ville matche “kit” og “kin”, så længe der er et mellemrum bagefter (den samler også op på mellemrum). Ifølge denne logik ville den også opfange udråbstegnet i “kid!”
Du kan se, hvorfor tingene bliver rodet, hvis du bruger denne alene.
Her er en illustration af ovenstående eksempel ved hjælp af Regex101.com:
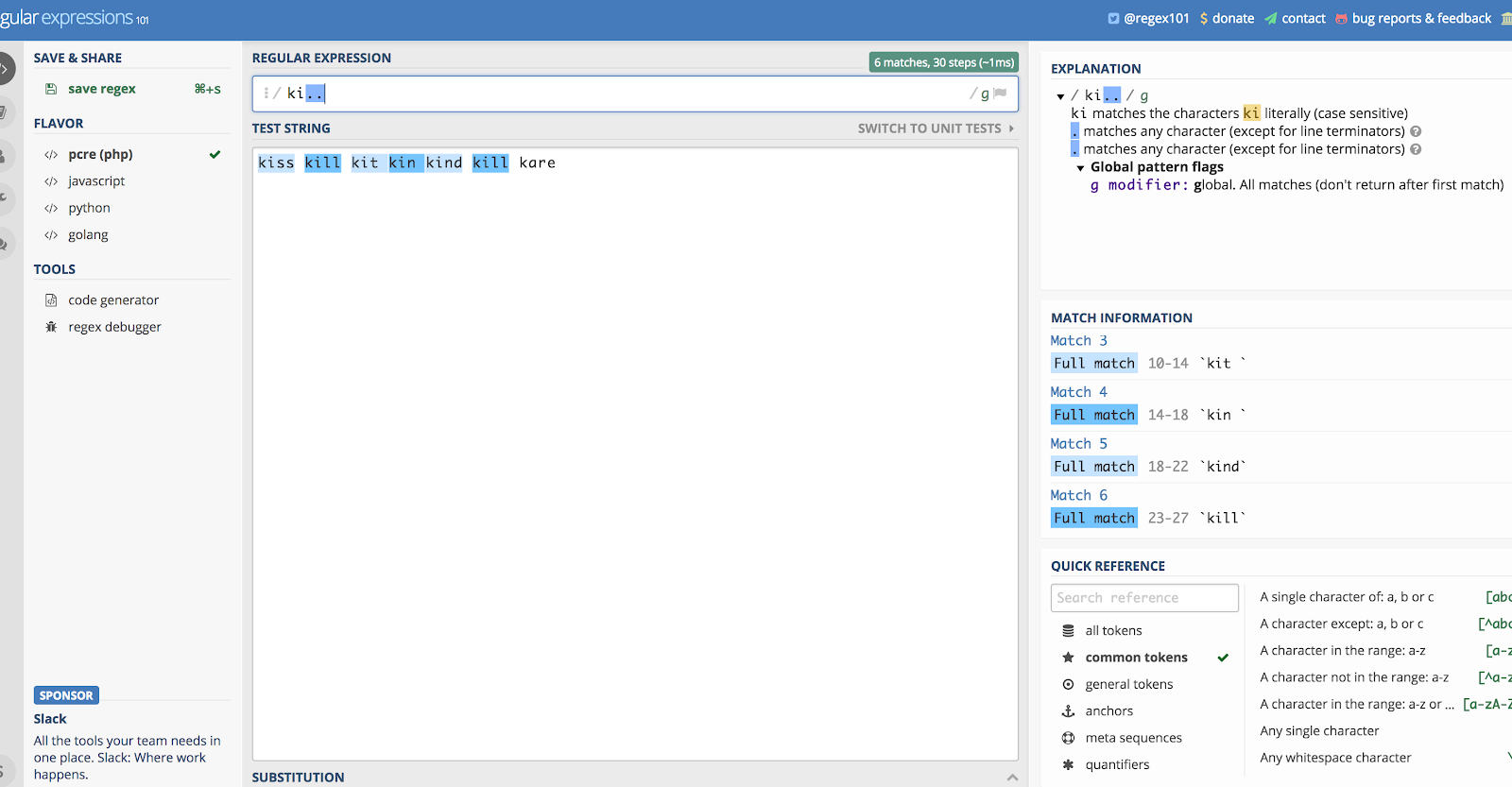
Punktet (.) passer til det meste.
Asterisk (*)
Asterisken (*) passer til nul eller flere af de foregående elementer. Lidt forvirrende, når man siger det på denne måde, så jeg vil bare bruge et eksempel.
Huskede du den der “wazzup”-reklame fra Budweiser for et stykke tid siden? Det ville være ret svært at gætte på, hvordan nogen ville stave den sætning, hvis de søgte efter den (f.eks. på YouTube). Men du kunne teoretisk set indkapsle alle stavevarianter ved at gøre dette:
waz*up
Her er en illustration af, hvordan det fungerer i regex101:
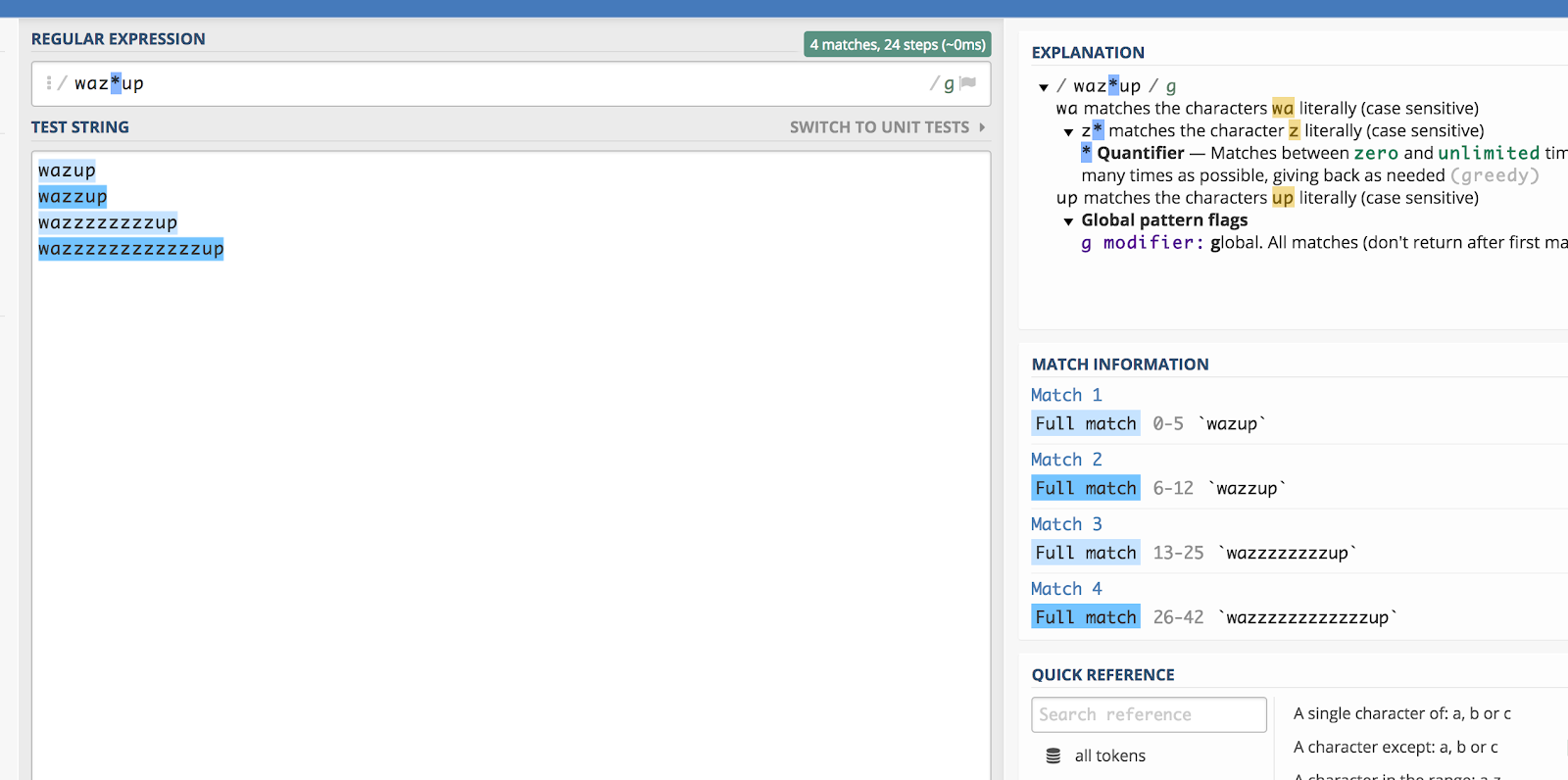
Stjernetegnet (*) passer til det foregående tegn nul eller flere gange.
Hvis du vil være superpræcis og tage højde for store og små bogstaver, kan du skrive noget i stil med dette:
*
Men jeg kommer lidt udenom.
Det sted, hvor stjernen faktisk er mest kraftfuld og mere almindeligt anvendt, er sammen med en prik eller som en del af andre regex-kombinationer.
Punkt-sterisk-kombination (.*)
Punkt-sterisk-kombinationen (.*) betyder i princippet, at alt er tilladt. Den er meget almindeligt anvendt.
Du bruger denne kombination, når du ønsker at matche alt i en streng. Da punktet betyder, at du skal matche et hvilket som helst tegn, og * betyder, at du skal matche nul eller flere tegn før det, er denne kombination meget kraftfuld.
Eksempel: Du har flere forskellige typer af kundekonti, men du vil gerne se dine data for dem alle. De har alle sammen lignende sider, så dine sider ser nogenlunde sådan ud:
/kunde/pro/login/
/kunde/gratis/login/
/kunde/starter/login/
Du kan skrive følgende regex for at gøre det:
/kunde/.*/login
Jeg bruger almindeligvis dette Google Analytics-regex-udtryk til at oprette segmenter for brugere med et bruger-id.
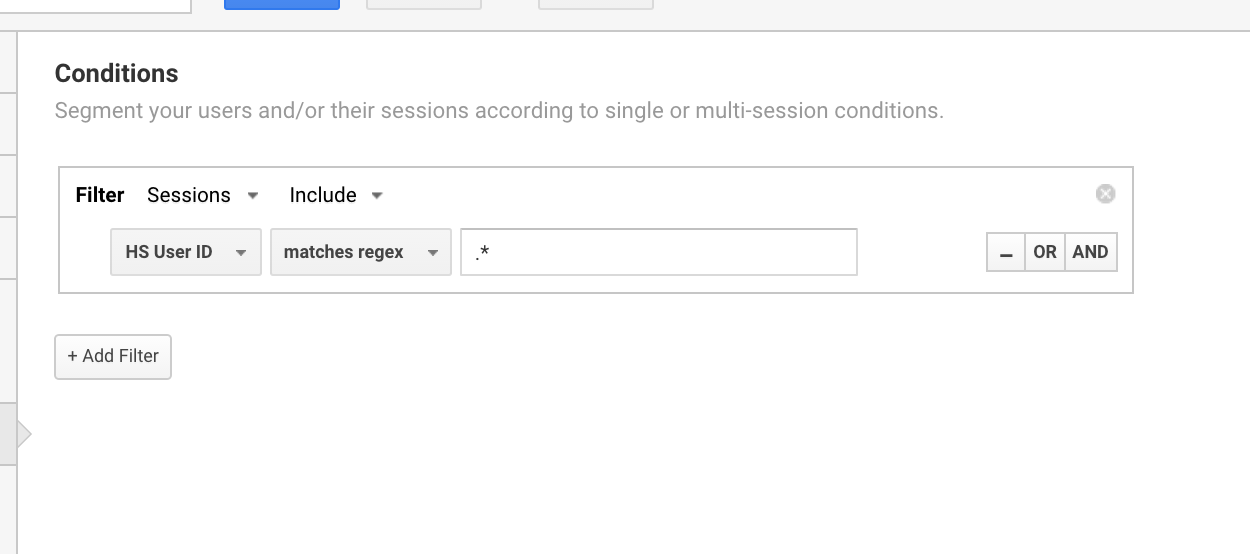
Anvendelse af Google Analytics-regex til at isolere alle sessioner, der har et bruger-id.
Plus-tegn (+)
Plus-tegnet (+) minder meget om *, bortset fra at det matcher ET eller flere af de foregående tegn. Der er ikke meget mere, der behøver at blive sagt om dette, kun at det er meget lidt anderledes end asterisken. Her er forskellen:
Forestil dig, at du har ordene: hello, hhello og hhhello.
Hvis du skriver hh+ello vil det kun matche de to sidstnævnte, men hvis du skriver hh*ello, vil det matche dem alle.
Mindre forskel. I virkeligheden bruger jeg næsten altid stjernen i stedet for plustegnet.
Spørgsmålstegn (?)
Spørgsmålstegnet (?) er en nem sag. Det betyder simpelthen, at det sidste tegn er valgmulighed.
Sig, at du er ligeglad med, om ordet er i flertal eller ej (som med sko). Det kan være “sko” eller “sko”, og du ønsker at opfange det på begge måder. Så kan du skrive “shoes?”
Her er et eksempel med mit navn. Hvis nogen stavede det “Alex Birket” under en søgning på et websted, ville jeg sandsynligvis stadig gerne se det. Så jeg kan skrive:
Alex Birkett?
Sådan ser det ud i regex101.com:
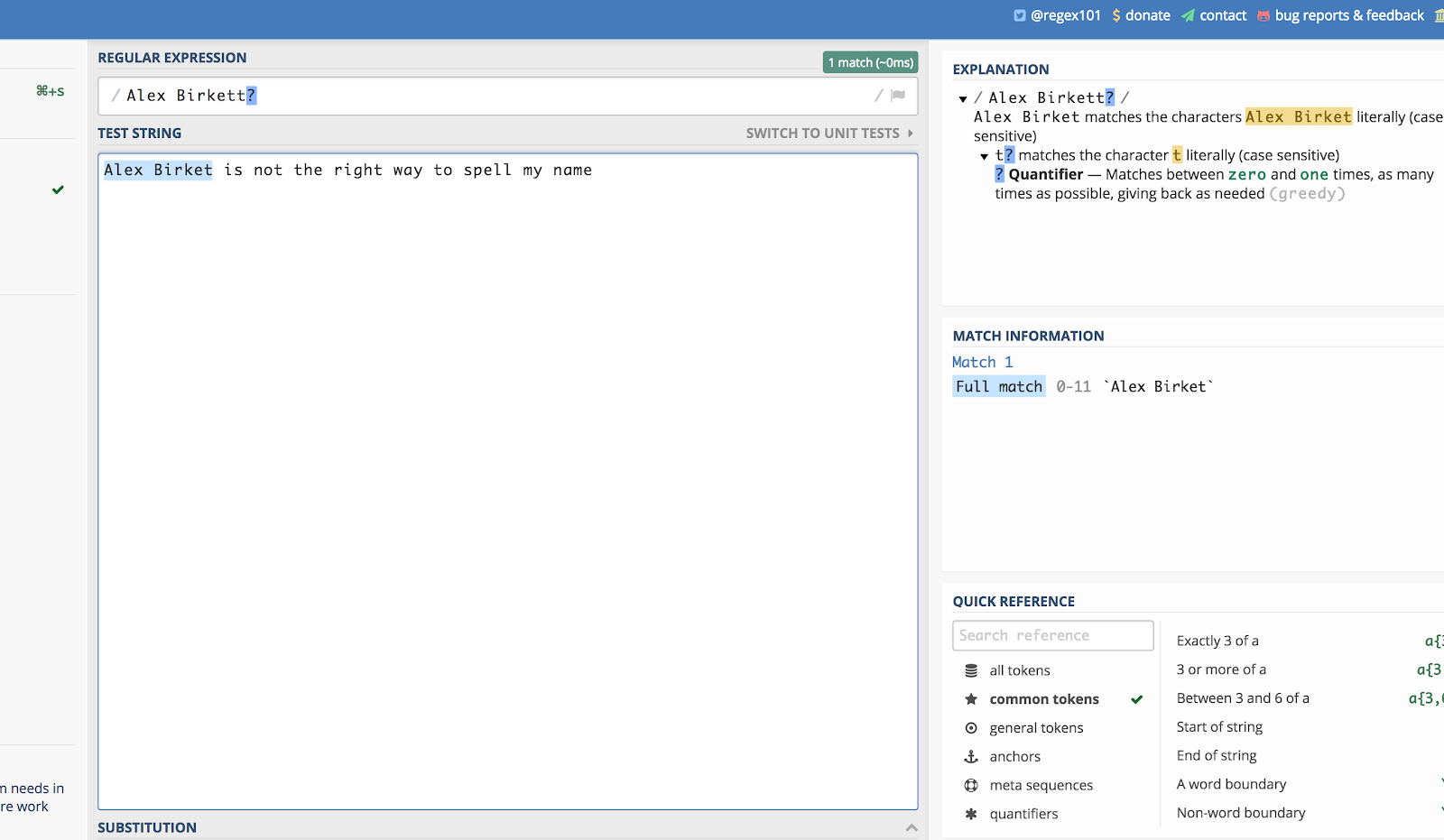
Spørgsmålstegnet (?) gør det sådan, at det sidste tegn, der går forud for det, er valgfrit.
Parenteser ()
Parenteser fungerer på samme måde, som de gør i matematik. De fortæller dig, at du skal prioritere og isolere den logik, som det er på spil inde i dem.
Lad os sige, at du har en SaaS-virksomhed med tre tilbud, og at du ønsker at matche alle dine prissider. Dine URL’er er som følger:
site.com/products/meetings/pricing
site.com/products/crm/pricing
site.com/products/email/pricing
For at fange alle tre kan du bruge et regulært udtryk som dette:
^/products/(meetings|crm|email)/pricing$
Firkantede parenteser ()
Firkantede () parenteser skaber en liste. Hvis du har tre strenge, “ting1”, “ting2” og “ting3”, kan du matche dem alle ved at skrive “ting” eller “ting” (mere om bindestreger om lidt – de bruges ofte sammen med firkantede parenteser.
Firkantede parenteser kan bruges til at matche flere gentagelser af et ord eller en streng, samtidig med at flere andre gentagelser udelukkes. Hvis du f.eks. ønsker at matche “can”, “man” og “fan”, men ikke “dan”, “ran” eller “pan”, kan du bruge følgende regex til det:
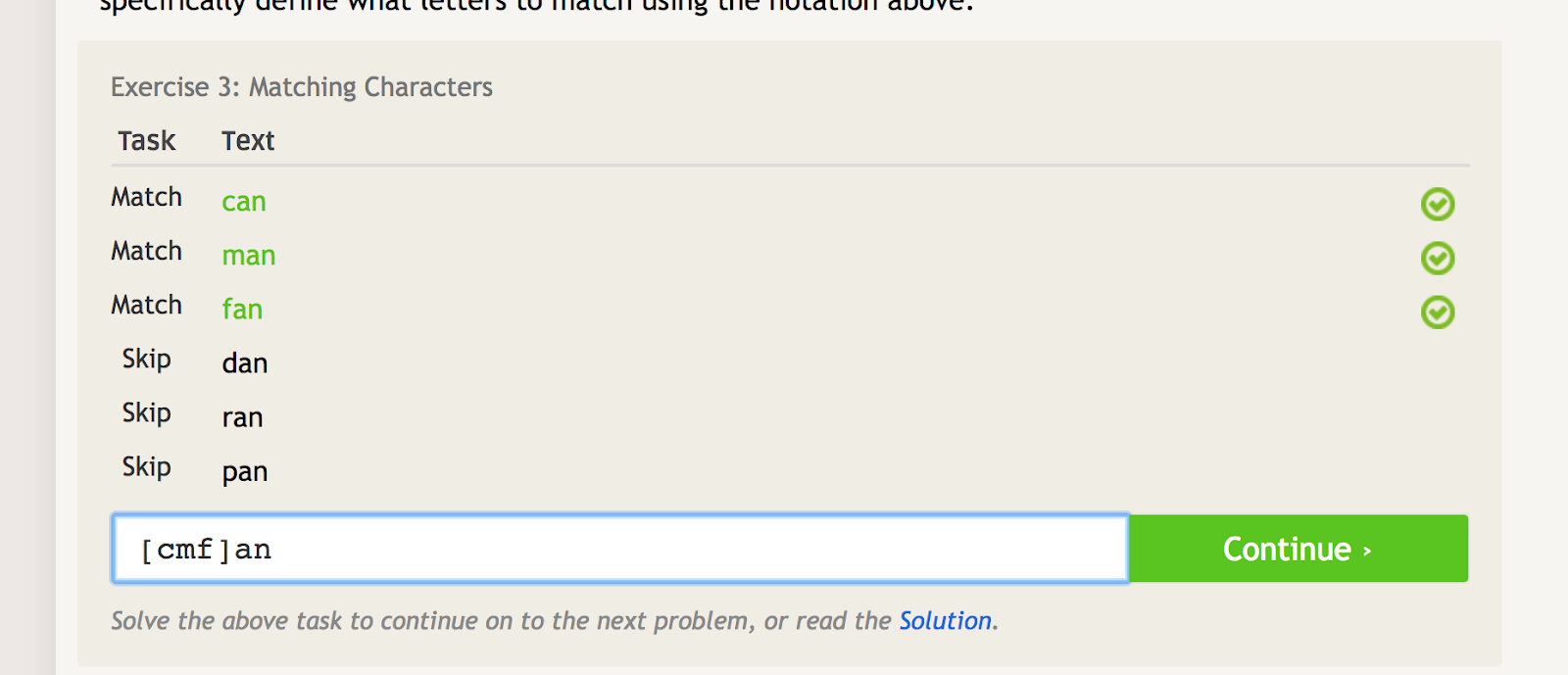
Firkantede parenteser skaber flere matchende betingelser afhængigt af, hvilke tegn du sætter inden for dem. – image source
Dette er noget, du kan bruge, hvis du har et par forskellige produkter med lignende navne, f.eks. “sko1”, “sko3” og “sko5”. Du kan matche disse, og intet andet, ved at bruge “sko”
Trykstreger (-)
Trykstreger (-) fungerer til at skabe lineære lister over elementer.
Som i, når du bruger firkantede parenteser, behøver du ikke bare at liste alting op, hvis det forekommer lineært. Så hvis du vil matche en streng af tal, hvor det sidste tal kan være alt fra nul til ni, kan du skrive dette:
1234
Og du kan skrive det meget enklere:
1234
Dette virker også for bogstaver. Lad os forestille os, at du har en sidekategori, der ender på to tilfældige bogstaver. Noget som dette:
/page-aa/
Du kan matche dem alle ved at skrive:
/page-*/
Du kan se et eksempel på det på regex101 her:
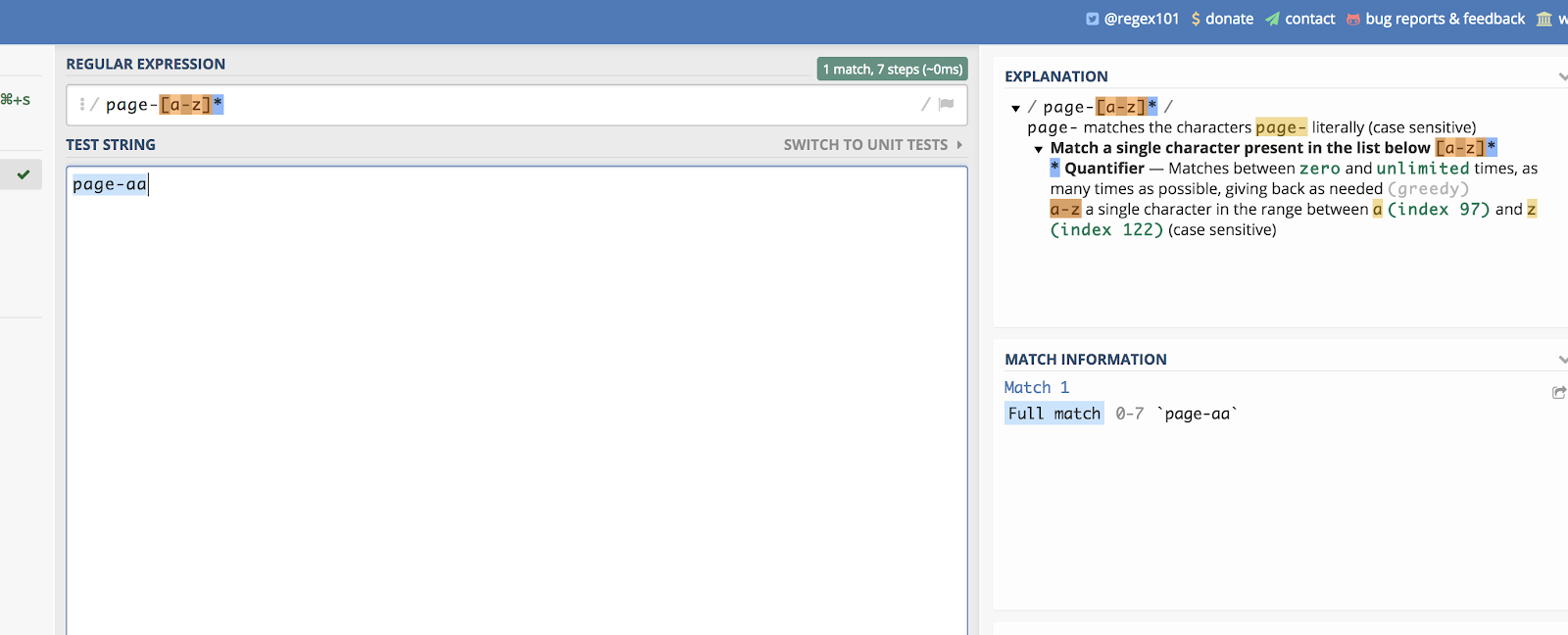
Trykstreger hjælper dig med at skabe en lineær liste til at matche.
Krumme parenteser ({ })
Krumme parenteser ({}) fortæller dig, hvor mange gange du skal gentage det sidste element.
Til eksempel, hvis du kun vil matche “wazzzzzzup”, kan du bruge “waz{4}up”.
Men hvis du vil matche “wazzzzzzzup” og “wazzzup”, men ikke “wazup”, kan du bruge “waz{3,5}up”. Det betyder i bund og grund, at man skal matche tegnet “z” mindst 3 gange, men højst 5 gange.
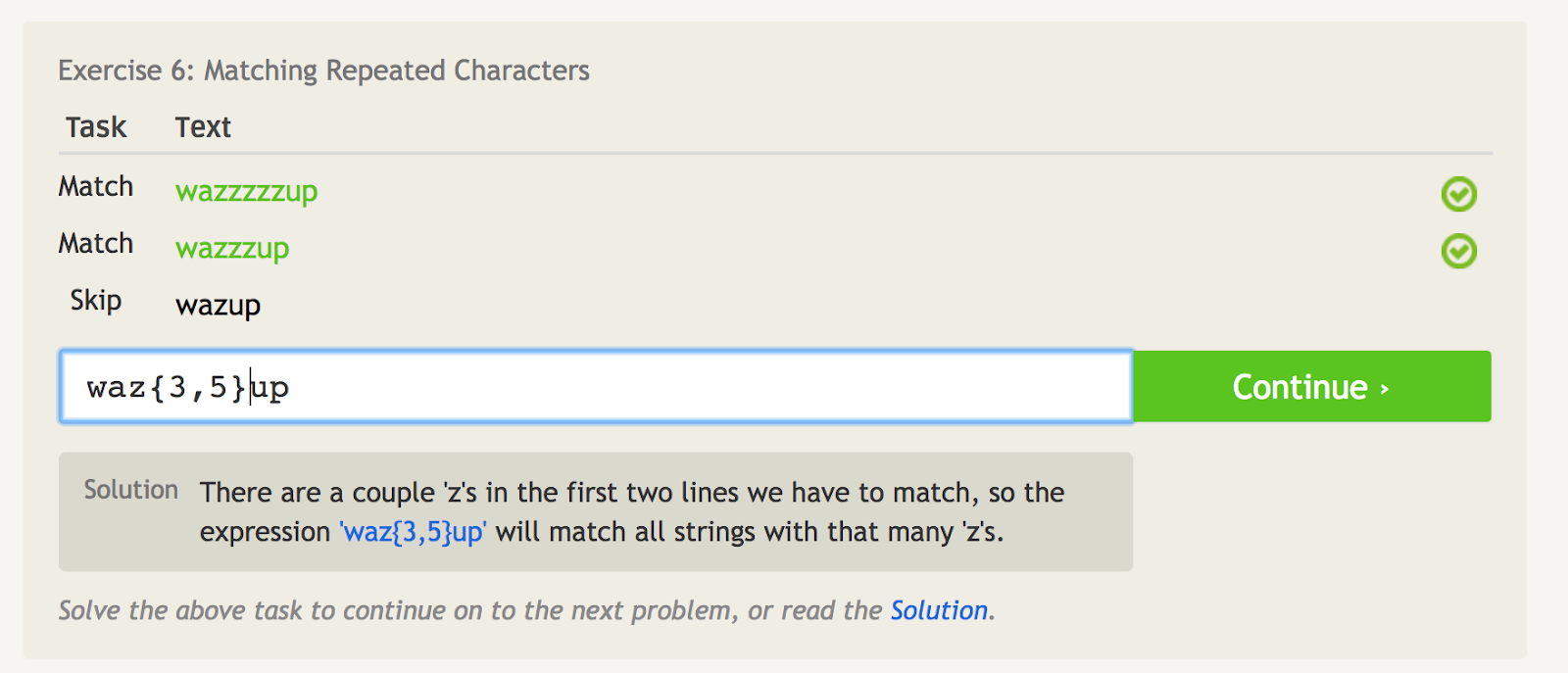
De krøllede parenteser fortæller dig, hvor mange gange du skal gentage det sidste element. – image source
Jeg har ikke rigtig brugt dette regulære udtryk meget i Google Analytics, men et almindeligt anvendelsesområde kunne være for postnumre. Normalt er de to første tegn det samme i en by (78- for Austin, TX, for eksempel). Så du kan matche ethvert Austin, TX-postnummer ved at skrive:
78{3}
Det siger, at de sidste tre bogstaver kan være et vilkårligt tal fra nul til ni.
Google Analytics RegEx: Specifikke eksempler, du kan bruge
Et af de mest almindelige Google Analytics-regex-brugstilfælde er at opbygge filtre. Lad os gennemgå tre eksempler, et enkelt og et lidt mere kompliceret.
Først et eksempel inspireret af et godt indlæg på Search Engine Land af Jenny Halasz.
Lad os sige, at du har en rodet webstedsarkitektur, men du vil gerne se på alle indlæg med en bestemt undermappe. Det kunne være hvad som helst, f.eks. en kategori eller indholdstype for et websted. I dette eksempel leder vi efter en kategori på webstedet for /music/, men kun i den tredje undermappe. I dette tilfælde kan du skrive ^/.*/.*/.*/music/.*, og det vil give dig denne rapport.

Dette Google Analytics-regex viser dig kun /music/ i tredje undermappe. – image source
Det ser umiddelbart forvirrende ud – men når du har lært, hvad disse regulære udtryk betyder, er det ret ligetil. I bund og grund fortæller vi bare GA, at de skal matche landingssider, der starter med (^) en skråstreg, derefter alle tegn (.*), derefter en skråstreg, derefter alle tegn (.*), derefter en skråstreg og derefter musik.
LawnStarter bruger en lignende taktik til rapportering. Deres strategi er at oprette byspecifikt indhold i en undermappe til deres bysider med følgende format:
https://www.lawnstarter.com/{{{transaktionel byside }}/{{informationsindholdsstykke }}
For at filtrere indholdet fra konverteringsfunnel og trafikrapportering bruger de følgende regex, ifølge grundlægger Ryan Farley.
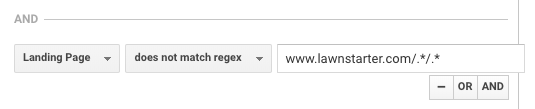
Denne regex hjælper LawnStarter med at matche byspecifikt indhold på deres websted.
For det andet vil vi gennemgå, hvordan du konfigurerer et filter til en af dine Google Analytics-visninger. Det er sandsynligt, at du har en implementeringsspecialist, der gør dette – men hvis ikke, skal du altid måle to gange og skære én gang her. Det er nemt at ødelægge disse ting (hvilket også er grunden til, at du bør oprette din Google Analytics-konto med en sandkassevisning for at afprøve tingene først).
For at opsætte filtre skal du gå til Admin > Filtre > Tilføj filter.
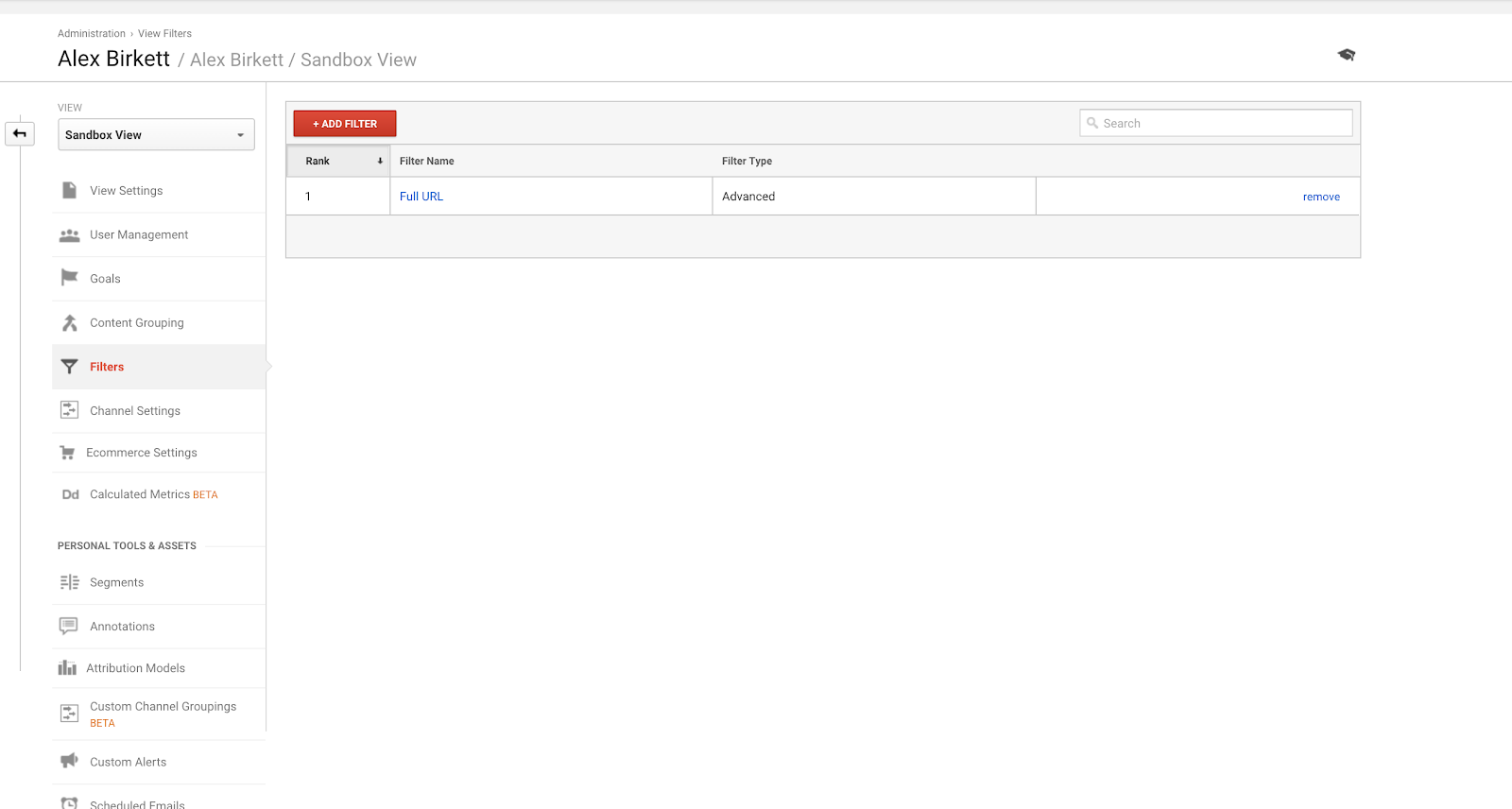
Det mest anvendte filter i Google Analytics er nok at udelukke trafik fra din(e) egen(e) IP-adresse(r).
For mange kan du sætte dette enkelt op, fordi du kun har én IP-adresse. For større virksomheder har du måske en række IP-adresser, og her kan du nemmere opsætte udelukkelser med Google Analytics regex.
For eksempel, hvis du skrev 63\.212\.171\.., ville det udelukke alle IP-adresser fra 63.212.171.1 til 63.212.171.9.
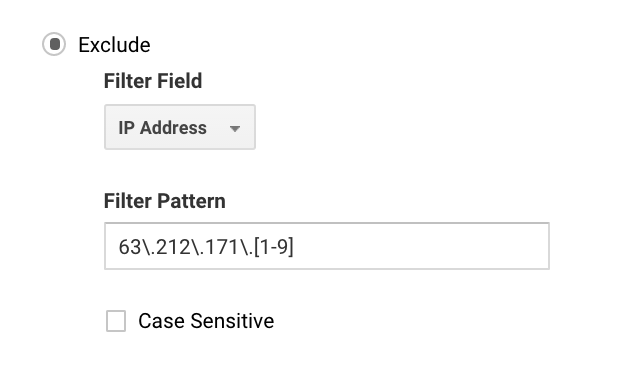
Dette Google Analytics-regex udelukker flere IP-adresser.
En anden ting, du kan gøre med Google Analytics-regex, er at opsætte filtre til at rydde op i forespørgselsparametre.
Det kan være både irriterende og problematisk for din dataanalyse.
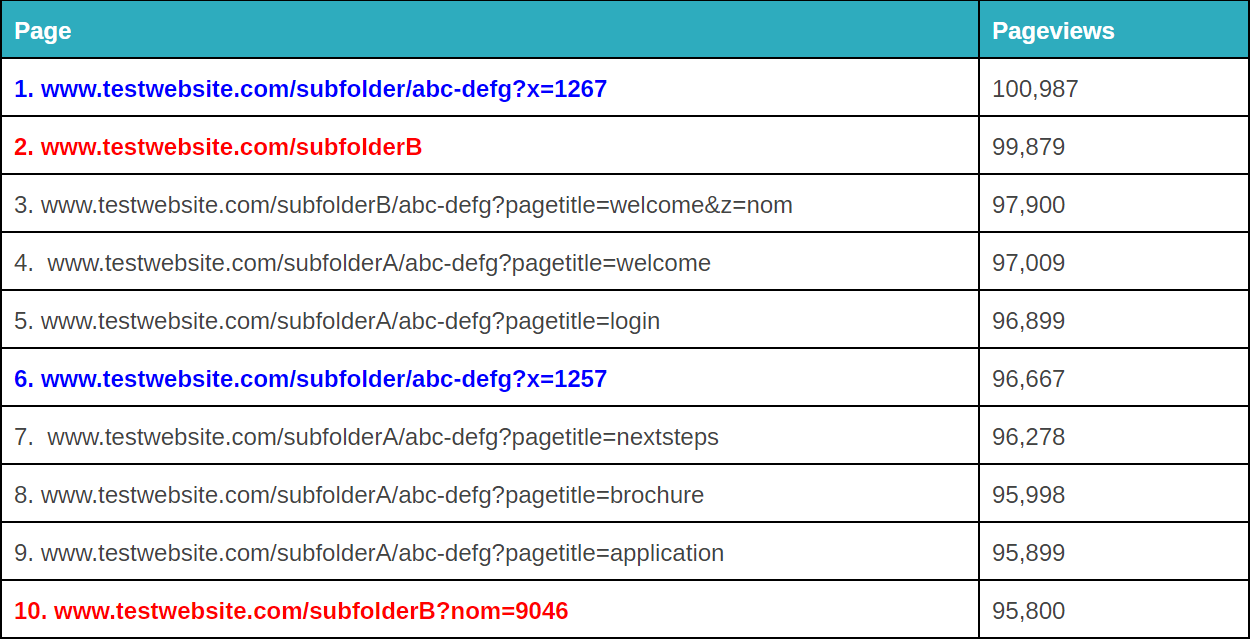
Frakturerede forespørgselsparametre kan være irriterende. – image source
Det afhænger af, hvordan din specifikke situation er, men der er et par forskellige måder, du kan bruge regex til at rydde op i det (bemærk: du kan også gøre dette i Google Tag Manager eller Excel, afhængigt af problemets omfang. Mere om det her).
Lad os endelig tale om et eksempel, som vi kan bruge til bedre at organisere vores sporing af underdomæner. Hvis du har flere domæner eller underdomæner, er det muligt, at du vil have dublerede URL’er, medmindre du opretter et filter til at sætte dit værtsnavn foran dit request URi. Med andre ord kan du have to URL’er:
- site.com/about
- blog.site.com/about
Disse repræsenterer to forskellige sider (den ene er en side om din virksomhed, og den anden er en om-sektion for din blog). Men de ville begge blive set i Google Analytics som /about, medmindre du opstiller følgende filter (ved hjælp af punkt-asterisk-kombination Google Analytics regulære udtryk):
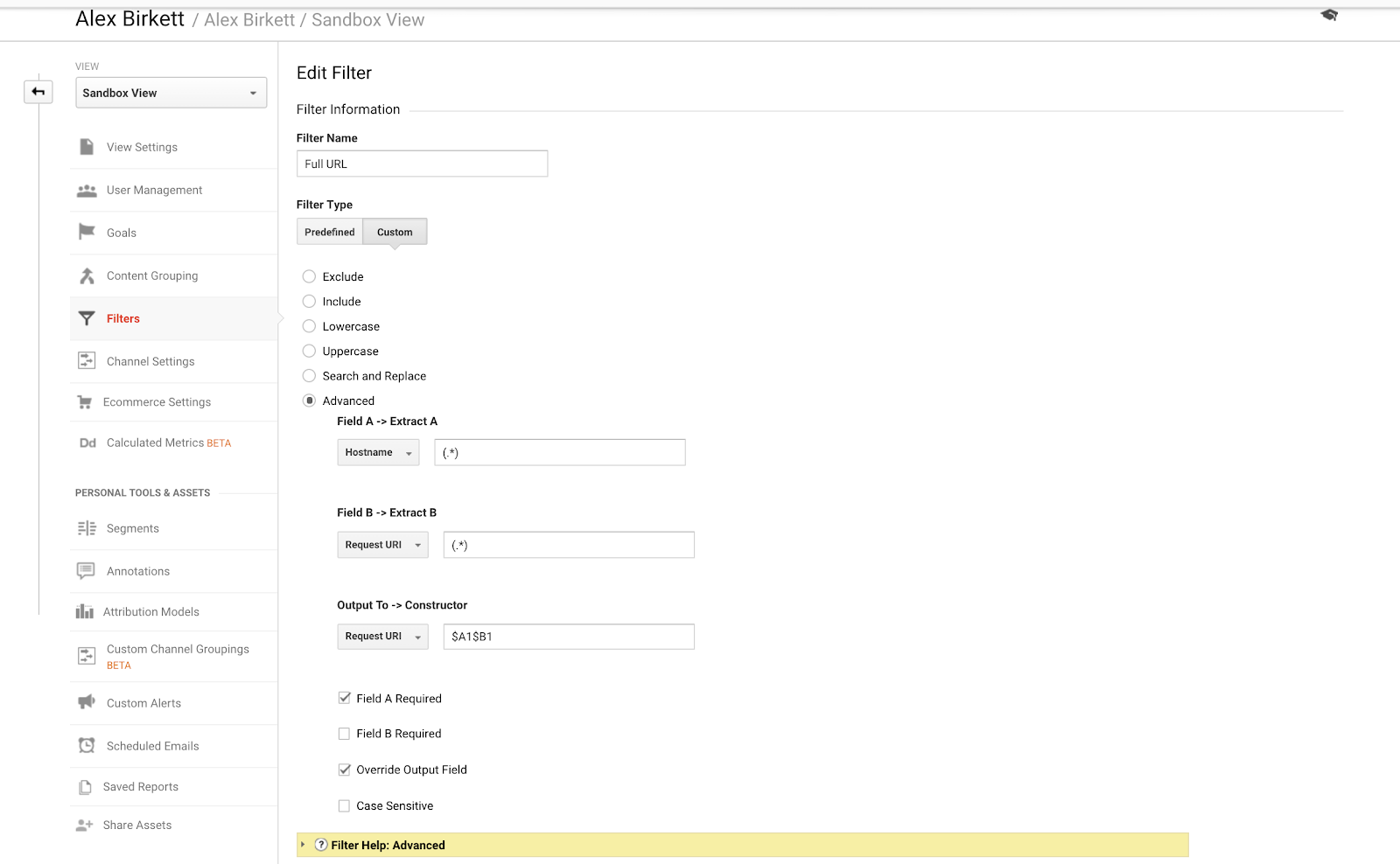
Det er ret enkelt at opsætte dette grundlæggende GA-filter. – billedkilde
Vi har faktisk allerede dækket, hvordan du opsætter disse filtre ret grundigt i et tidligere KlientBoost-indlæg om sporing på tværs af domæner og underdomæner.
Google Analytics RegEx Tips & Fejl at undgå
Regulære udtryk er en af de ting, du bare skal øve dig på og få beskidte hænder for at lære. Som sådan kommer du til at begå fejl.
Det er faktisk det vigtigste tip: Prøv tingene af, og se, om de virker. Jeg har listet tonsvis af ressourcer i dette indlæg om, hvordan du kan teste din regex, fra regex101.com til regexbuddy.com. Dyp tæerne i og brug disse ressourcer.
Men med lidt forhånd og heuristik kan du lære hurtigere og fange flere fejl.
En ting, du virkelig skal lære, er, hvordan man “undslipper” i regex (vi talte om dette om med backslash). Leho Kraav, CTO hos CXL Institute, udtrykker det således:
“Jeg vil sige “lær at lære at escape tingene korrekt” – det er nemt at få fejlmatchninger, når tegnene er de samme, men deres betydning er forskellig, afhængigt af om de er escapet eller ej.”
For eksempel, hvis din forespørgsel har et spørgsmålstegn, er det også et regulært udtryk, så du skal gøre det klart med backlash. Chris Mercer, grundlægger af MeasurementMarketing.io, siger også, at det at undlade at lære denne evne er en af de største fejl, han ser begyndere begå:
“Den mest almindelige fejl, vi ser hos begyndere, der bruger regex, er at de glemmer at “escape” regex-symboler. Hvis du for eksempel leder efter sider, der matcher regex “thankyou/?success=yes”, vil det ikke virke. Selve “?” er et regex-symbol, og skal deaktiveres ved hjælp af “escape-tegnet” (” \ “. I dette tilfælde ville “thankyou/\?success=yes” virke.”
Et andet tip? Hold det simpelt. Folk forsøger at komplicere tingene (se den mest komplicerede regex du nogensinde har set, skrevet af Leho, her), men regulære udtryk er “grådige” og vil matche så meget som muligt. Google Analytics udsendte et blogindlæg med tips og forklarede det sådan her:
“Hvis du skal skrive et udtryk for at matche “nye besøg”, og de eneste muligheder, som du vil matche mod, er “nye besøg” og “gentagne besøg”, er bare ordet “nye” godt nok.
De vil matche alt, hvad de overhovedet kan, medmindre du tvinger dem til at lade være. Hvis dit udtryk er “besøg”, vil det matche “nye besøg” og “gentagne besøg”. De indeholdt trods alt begge udtrykket “besøg”. For at gøre dem mindre grådige er du nødt til at gøre dem mere specifikke.”
Så start langsomt, hold det simpelt, og lad være med at overvælde dig selv med kompleksitet (risikoen for fejl korrelerer med kompleksiteten i dette tilfælde).
Mercer gentager også dette punkt og råder til at tage tingene gradvist:
“Når du først starter, skal du fokusere på at blive god … og derefter blive bedre. Det er nemt at blive overvældet af alle de forskellige muligheder, som regex giver dig, men hvis du bare starter med det grundlæggende, som f.eks. at mestre symbolet for “eller” (” | “), får du hurtigt erfaring og begynder at indse, hvad der er muligt med regex.”
Sidste tip fra mig: Lær at google ting. Dette gælder for al programmering, men især for regulære udtryk. Du kommer til at glemme ting, og hvis du ikke skriver regex dagligt, er der ikke rigtig nogen mening med at lære alting udenad. Lær at slå tingene op og finde svar på det, du forsøger at gøre.
Udvendigt i Google Analytics: RegEx til andre markedsføringsformål
Regex er også noget, som alle SEO-folk bør se nærmere på. Først og fremmest naturligvis, fordi SEO og digital analyse (f.eks. Google Analytics) er uløseligt forbundet med hinanden. For det andet fordi nogle af de samme matchende udtryk, som vi skriver for at filtrere og matche tegn på vores Google Analytics-data, også kan bruges i dataudtræk til SEO-taktikker.
Med andre ord er regulære udtryk vigtige for webscraping.
Hvis det gælder webscraping og SEO, vil du normalt arbejde via et programmeringssprog som Python, men principperne er de samme.
Som eksempel kunne man skrabe al fed tekst på en side ved at bruge dette:
<strong>(+)</strong>
Og som nævnt i denne SEJ-artikel kunne man, hvis man skrabede ESPN for alle forfattere, skrive dette:
“columnist”:”(.*?)”
For sammenhængen og fornuftets skyld vil jeg ikke dykke helt ned i avanceret webscraping. Det er tilstrækkeligt at vide, at regex også er vigtig på dette område. Men hvis du gerne vil lære mere, foreslår jeg disse kilder:
- Web Scraping with Regular Expressions
- Scraping with Regular Expressions (Stanford)
- How to Use Regex for SEO & Website Data Extraction
Regular expressions also help you work with your SEO data, beyond simply scraping the web. Du kan f.eks. bruge regex til yderligere at tilpasse, hvordan du bruger Screaming Frog.
Jenny Halasz gav et godt eksempel på at bruge regex til at rydde op i data i et indlæg i Search Engine Land:
“Lad os for eksempel sige, at du har en liste over URL’er, og at du skal opdele dem i kun TLD (Top Level Domain).
Du kan bruge en simpel find/replace for http og www, men hvordan kan du nemt slå alle filnavne fra? Du kan fjerne dem alle manuelt, men det er en smerte. Ved hjælp af et simpelt regex-jokertegn (/*) kan du droppe skråstregen og alt, hvad der kommer efter den.”
Vi kunne tale i al evighed om regulære udtryk til SEO og webscraping, men jeg vil blot linke ud til nogle gode ressourcer, hvis du vil lære mere (det er trods alt et meget alsidigt sprog med mange anvendelsesmuligheder ud over analytics):
- Hvordan Regular Expression Affects SEO
- 5 Powerful Awesome Htaccess Redirect Tricks
- Hvordan man bruger Regular Expression til Report Segmentation
Konklusion
Google Analytics regex er virkelig noget enhver analytiker bør vide, selv om du ikke fancy dig selv som teknisk. Ud over det kan det at kende nogle regulære udtryk (eller i det mindste hvordan man søger efter svar og anvender dem på de rigtige problemer) også hjælpe marketingfolk med forskellige aktiviteter.
Det er bare at sige, at det ikke er et meget almindeligt færdighedssæt, så du vil sikkert imponere nogle kolleger med dine nyfundne tekniske marketingfærdigheder.
Så jeg opfordrer dig indtrængende til at begynde at lære, og endnu vigtigere, bare begynde at øve dig på at bruge regulære udtryk. De er ikke så skræmmende.