Google Analytics regex (c’est-à-dire les expressions régulières) est un ensemble de compétences sous-appréciées.
Si vous voulez faire une sorte de filtrage ou de ciblage au-delà des bases, une bonne prise en main de regex vous donnera des superpouvoirs Analytics.

Le regex vous donne des superpouvoirs. – image source
Bien sûr, les expressions régulières ont des cas d’utilisation beaucoup plus larges que l’analyse et le marketing. Mais pour les besoins de cet article, nous allons couvrir quelques cas d’utilisation tactiques qui pourraient vous aider avec les connaissances des utilisateurs, l’organisation des données, et même des cas d’utilisation avancés de ciblage et de marketing par moteur de recherche.
Mais d’abord, résumons brièvement ce que sont les expressions régulières, spécifiquement en relation avec Google Analytics.
- Google Analytics RegEx : qu’est-ce que c’est?
- Fiche de cheat RegEx de Google Analytics
- Pipe (|)
- Touche oblique inverse (\)
- Caret (^)
- Signe de dollar ($)
- Point (.)
- Astérisque (*)
- Combinaison point-astérisque (.*)
- Signe plus (+)
- Point d’interrogation ( ?)
- Parenthèses ()
- Crochets ()
- Les tirets (-)
- Parenthèses bouclées ({ })
- Google Analytics RegEx : Exemples spécifiques que vous pouvez utiliser
- Conseils sur les RegEx de Google Analytics & Erreurs à éviter
- En dehors de Google Analytics : RegEx pour d’autres utilisations marketing
- Conclusion
Google Analytics RegEx : qu’est-ce que c’est?
Les expressions régulières sont des chaînes de texte spéciales pour décrire des modèles de recherche.
Huh?
En ce qui concerne l’analytique, les expressions régulières vous aident à trouver, définir et extraire des choses. Encore plus spécifiquement, avec Google Analytics, elles peuvent vous aider à créer des définitions plus flexibles pour des choses comme les filtres d’affichage, les objectifs, les segments, les audiences, les groupes de contenu et les groupes de canaux.
Basiquement, ce sont des caractères prédéfinis ou une série de caractères qui correspondent largement ou étroitement et sélectionnent des modèles dans vos données d’analyse numérique. Ils sont un outil général qui peut être utilisé de nombreuses façons (des tonnes de langages de programmation et d’outils permettent regex). Mais dans Analytics, nous allons principalement les utiliser pour faire correspondre des modèles dans les données.
Ce n’est pas seulement utile dans Analytics, bien sûr. En particulier, si vous êtes un utilisateur de Google Tag Manager ou si vous exécutez un ciblage compliqué sur vos tests A/B, vous utiliserez beaucoup de regex. Comme le dit Chris Mercer, fondateur de MeasurementMarketing.io :
« Nous utilisons le regex au quotidien. Cela nous aide à définir clairement tout, des étapes de l’entonnoir dans un objectif Google Analytics, à un déclencheur spécifique dans Google Tag Manager. »
Toutefois, si vous souhaitez faire une plongée profonde et vraiment apprendre les expressions régulières, voici quelques ressources (non nécessaires pour les choses de base dans Google Analytics, et probablement pour quelqu’un de plus de prouesses techniques):
- Regular Expressions : The Complete Tutorial
- Mastering Regular Expressions 3rd Edition (Book)
- Learn Regular Expressions the Hard Way
Vous pouvez également apprendre de manière interactive à travers quelque chose comme RegexOne ou RegexR, qui sont tous deux cool. Mais passons outre et parcourons les caractères regex de Google Analytics les plus couramment utilisés, afin que vous puissiez commencer à mettre cela à profit.
Fiche de cheat RegEx de Google Analytics
Regardez les caractères regex de Google Analytics suivants comme une sorte d’aide-mémoire – vous ne les utiliserez probablement pas tout de suite, mais passer brièvement en revue ce dont vous êtes capable avec regex vous permettra de rechercher la réponse lorsque cela sera nécessaire.
Pour un bref résumé, je n’ai rien trouvé de plus condensé et de plus pertinent que ce guide :

Un guide très bref des regex de Google Analytics – source de l’image
Cependant, vous pouvez voir que, avec cela seul comme référence, c’est un peu vague et ambigu. Parcourons donc les regex les plus couramment utilisées par Google Analytics tout en montrant les cas d’utilisation correspondants.
Pipe (|)
Lorsque vous voulez dire « OU », vous devez utiliser un pipe (|). Comme dans « This | That » qui signifierait « This OR That ».
Si vous êtes un utilisateur assidu des segments Google Analytics, vous êtes déjà habitué à utiliser les opérateurs logiques OR.
C’est l’une des expressions régulières les plus simples et les plus courantes utilisées dans Google Analytics. Elle a de nombreuses applications, bien que l’une des plus utilisées pourrait être lors de la mise en place d’objectifs. Si vous avez deux pages de remerciement avec des URL distinctes (/thank-you/ et /subscription-confirmed/), mais que vous souhaitez les suivre toutes les deux en tant qu’achèvement d’objectif, vous pouvez utiliser cette expression régulière.
Vous pouvez également l’utiliser dans des filtres. Supposons que vous souhaitiez afficher un rapport de comportement sur deux articles (sur les leçons de marketing de contenu et les analyses de contenu), avec les URL /content-marketing-analytics/ et /content-marketing-lessons/. Vous pourriez écrire, comme filtre, « content-marketing-analytics|content-marketing-lessons » et obtenir uniquement ces articles.
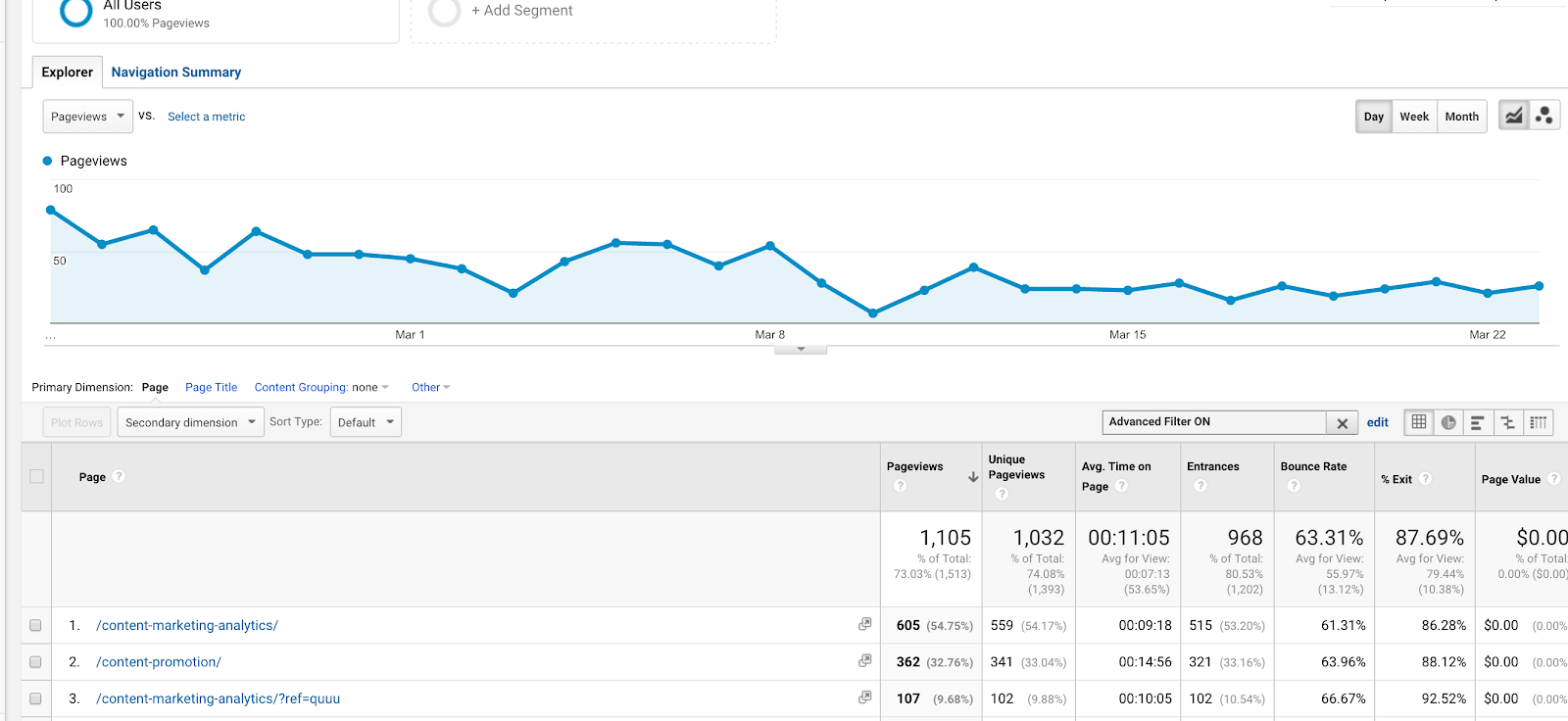
Utilisation d’un tuyau (|) dans un filtre pour obtenir les résultats de deux articles de blog distincts
Touche oblique inverse (\)
La touche oblique inverse (\) est une autre expression régulière directe et couramment utilisée dans Google Analytics. Elle signifie « considérez le caractère suivant comme du texte brut, et non comme une expression régulière. »
En d’autres termes, il y a beaucoup d’expressions régulières qui apparaissent en texte brut, comme le point, le point d’interrogation, et d’autres, que nous devons préciser si elles doivent être lues comme des expressions régulières ou du texte brut.
Une chaîne de requête commune en ligne est utilisée lorsque quelqu’un recherche quelque chose sur votre site. Par exemple, lorsque je recherche « petits jouets pour chiens » sur petsmart.com, voici la chaîne de requête qui s’affiche :
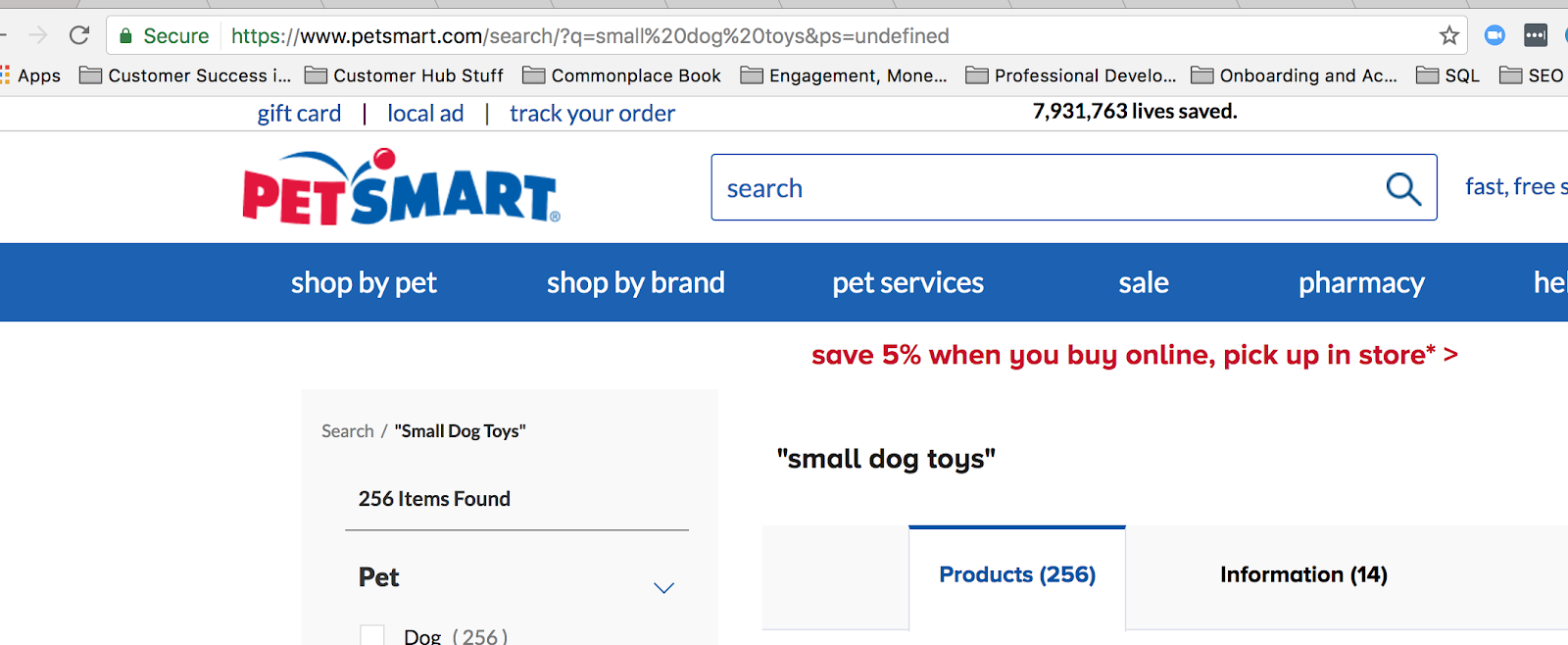
Lorsque vous utilisez la recherche sur site, vous créez une chaîne de requête dans l’URL.
Le point d’interrogation signifie ici qu’une recherche sur site a eu lieu, mais le point d’interrogation est également une expression régulière couramment utilisée dans Google Analytics. Par conséquent, nous devons préciser, lors de l’utilisation d’une barre oblique inverse, que dans ce cas, le point d’interrogation doit être lu comme du texte en clair.
Disons que nous voulons faire correspondre toutes les chaînes de requête dans Google Analytics qui commencent par /search/?q= (car cela signifie une recherche). Alors, l’expression régulière serait:
search\/\?q=
Vous pouvez vérifier cela en utilisant un débogueur comme regex101.com:
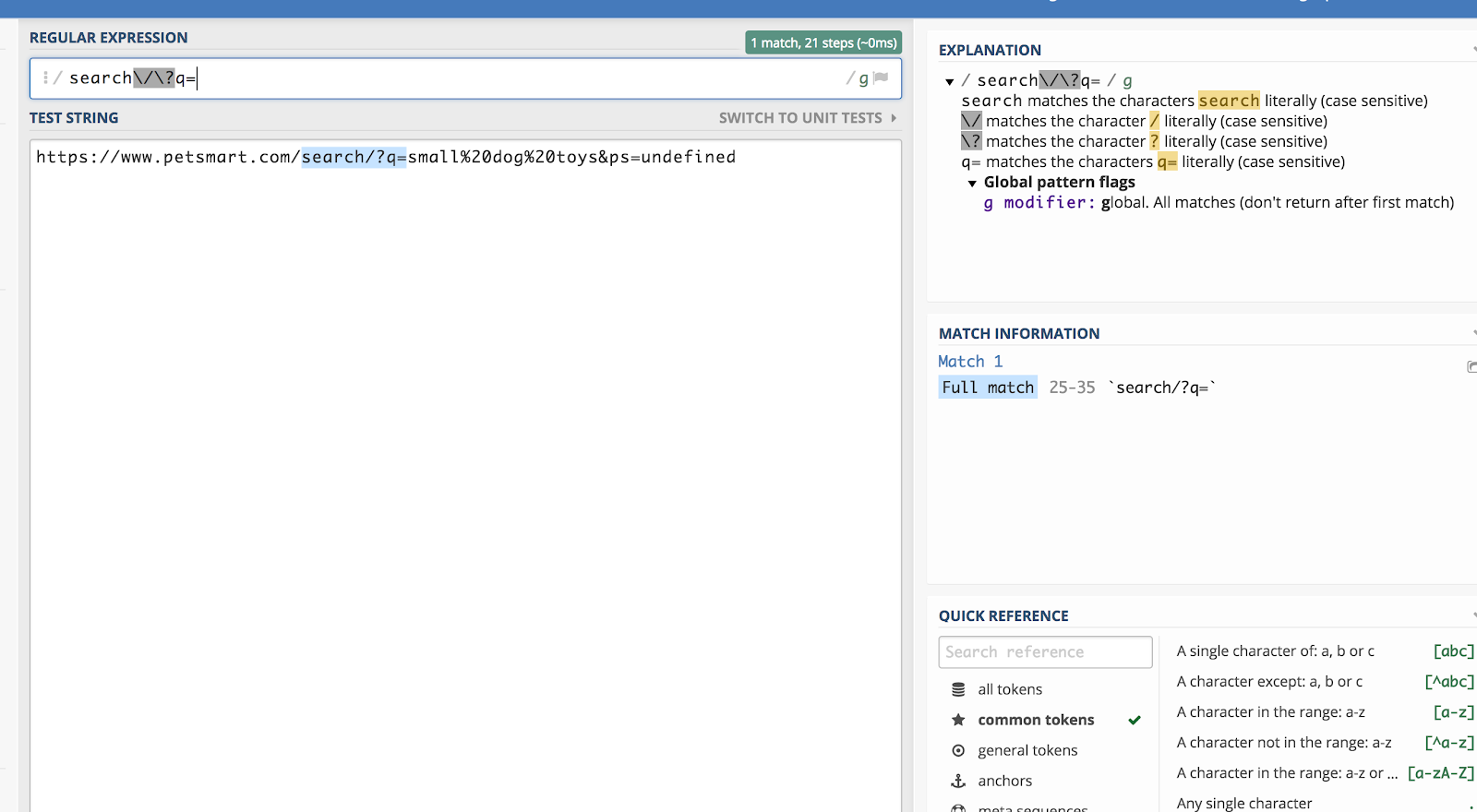
La barre oblique inverse (\) « s’échappe » de la regex pour un caractère après et la lit comme du texte brut.
Caret (^)
Caret (^) signifie qu’une phrase commence par quelque chose. C’est important lorsque vous avez une phrase qui pourrait apparaître n’importe où, mais que vous voulez faire correspondre spécifiquement la phrase au point de départ. Par exemple, regardez cet exemple de quelques phrases différentes qui incluent les mots « Mission : réussie. »
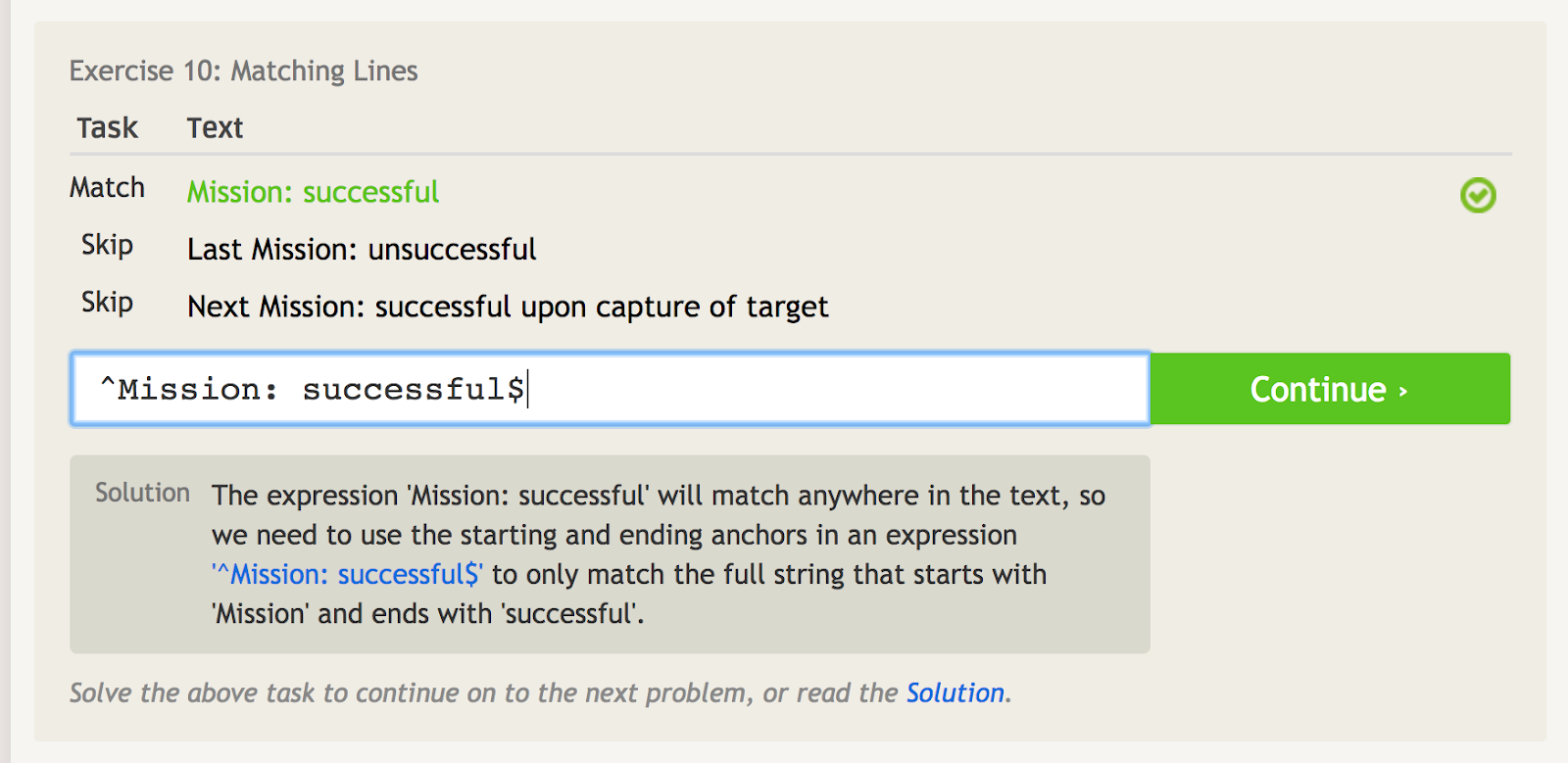
Le caret signale l’ancre de départ, donc nous pouvons uniquement faire correspondre la première phrase ici.
Disons que vous avez un tas de campagnes AdWords qui commencent toutes par la même phrase (parce que vous êtes un mauvais planificateur pour l’avenir) :
- Campagne Freemium Finale
- Notre première campagne Freemium
- Offre créative de campagne Freemium
- Tester la campagne Freemium
Vous voudriez écrire ^Campagne Freemium pour correspondre à la première, et à aucune des autres.
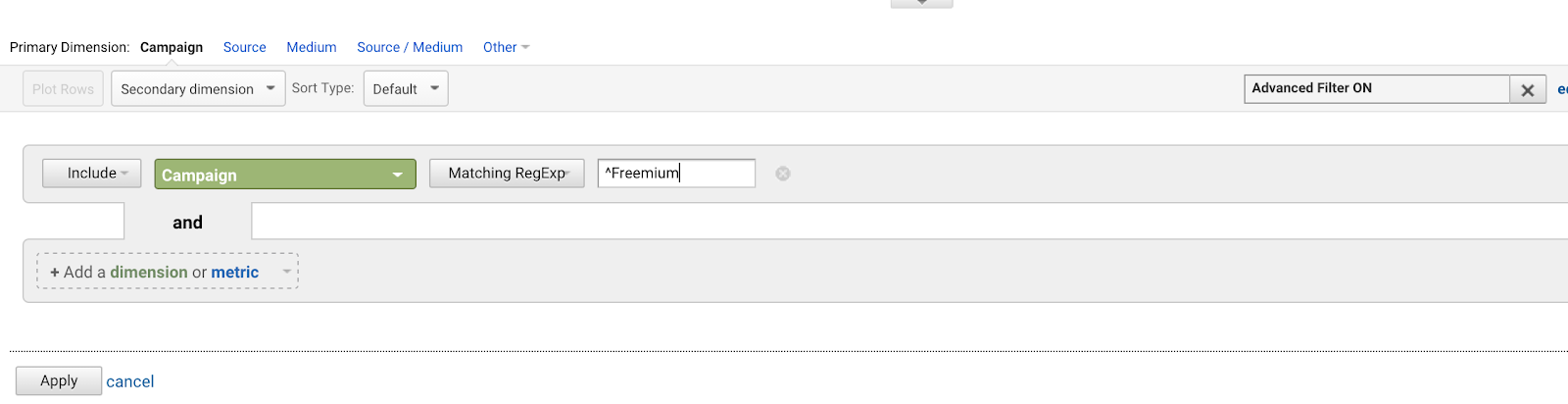
L’utilisation du signe d’insertion (^) correspond aux chaînes qui commencent par ces caractères
Signe de dollar ($)
Le signe de dollar ($) signifie qu’une phrase se termine par quelque chose.
Lorsque vous combinez les deux, vous pouvez cibler une formulation à correspondance exacte.
Si vous avez lancé une campagne intitulée « paidacquisitionfb » puis, plus tard, une autre appelée « paidacquisitionfb-2 » parce que vous n’avez pas bien planifié et pensé que vous auriez d’autres campagnes au titre similaire (cela arrive tout le temps), vous pourriez isoler la première en écrivant :
^paidacquisitionfb$
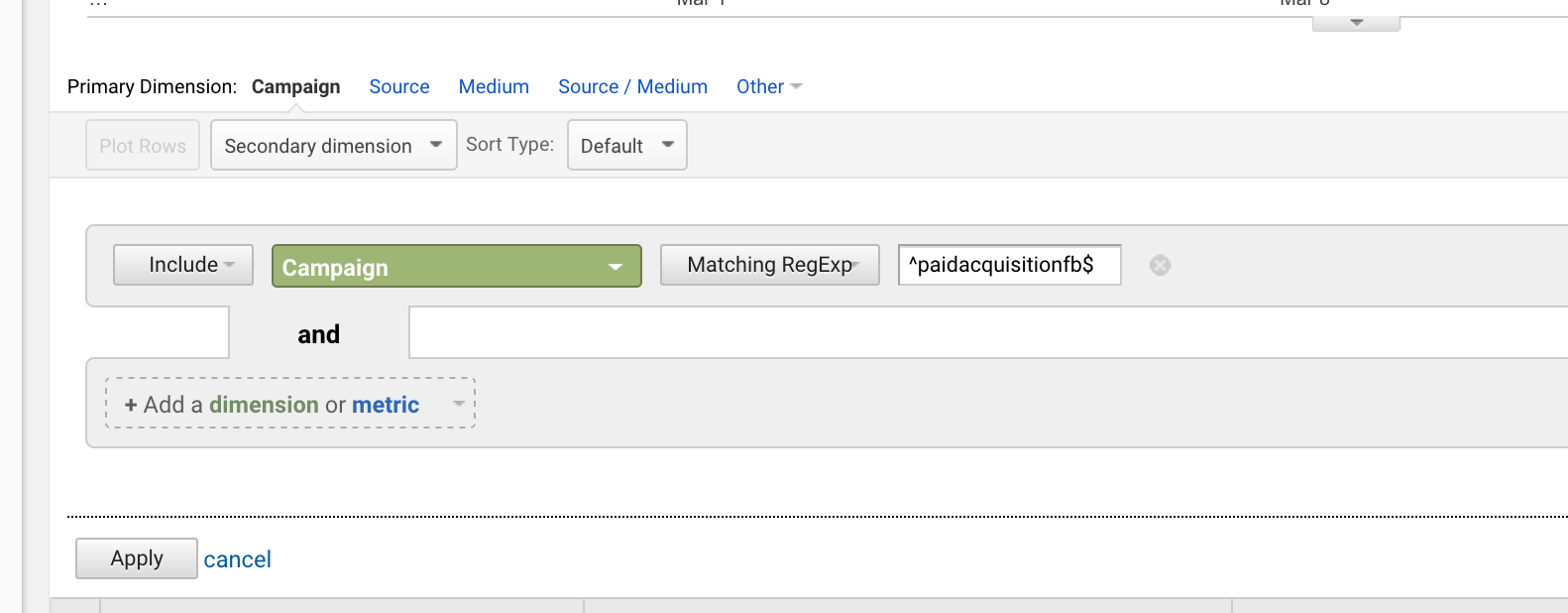
L’utilisation du carett et du dollar ensemble est très courante.
Si vous avez des pages de catégories sur votre blog, par exemple, et qu’elles se terminent toutes par un numéro de page, vous pouvez écrire un simple morceau de regex Google Analytics pour afficher uniquement les pages de catégories de blog (^/page/*/$). Cela vous donnerait des listes comme:
- /page/1
- /page/2
- /page/3
…et ainsi de suite.
Point (.)
Un point (.) correspond à n’importe quel caractère, ce qui signifie tout ce que vous pouvez trouver sur votre clavier : chiffres, lettres, même les espaces. Il n’est pas super utile en soi, mais il est utilisé tout le temps en conjonction avec d’autres expressions régulières, en particulier l’astérisque (à venir).
Disons que vous voulez l’utiliser seul, et utilisons l’exemple » ki… « . Cela correspondrait à tout ce qui commence par les lettres K et I, puis les deux caractères suivants, quels qu’ils soient.
Donc, si vous aviez une chaîne qui comprenait les mots kill, kind, kiss, kin, kid ! et kit, cela correspondrait à tous ces mots. Attendez, quoi ? Oui, elle correspondrait à « kit » et « kin » tant qu’il y a un espace après (elle capte aussi les espaces). En suivant cette logique, elle ramasserait également le point d’exclamation dans « kid ! »
Vous pouvez voir pourquoi les choses deviennent désordonnées si vous utilisez celui-ci seul.
Voici une illustration de l’exemple ci-dessus en utilisant Regex101.com:
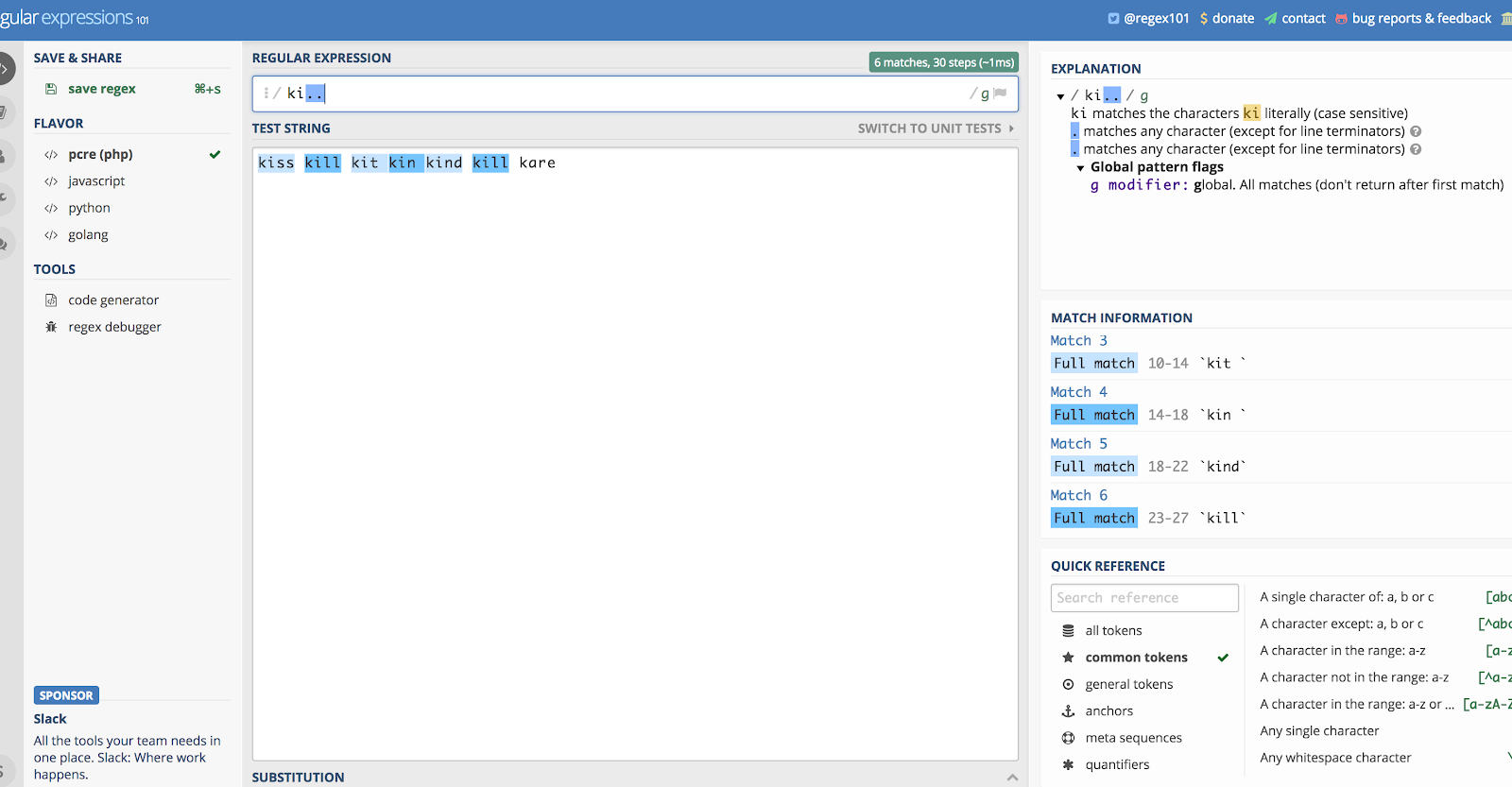
Le point (.) correspond à presque tout.
Astérisque (*)
L’astérisque (*) correspond à zéro ou plus des éléments précédents. C’est un peu confus quand on l’énonce de cette façon, alors je vais juste utiliser un exemple.
Vous vous souvenez de la publicité « wazzup » de Budweiser il y a quelque temps ? Il serait assez difficile de deviner comment quelqu’un épellerait cette phrase s’il la recherchait (disons, sur YouTube). Mais vous pourriez théoriquement encapsuler toutes les variations orthographiques en faisant ceci:
waz*up
Voici une illustration de comment cela fonctionne dans regex101:
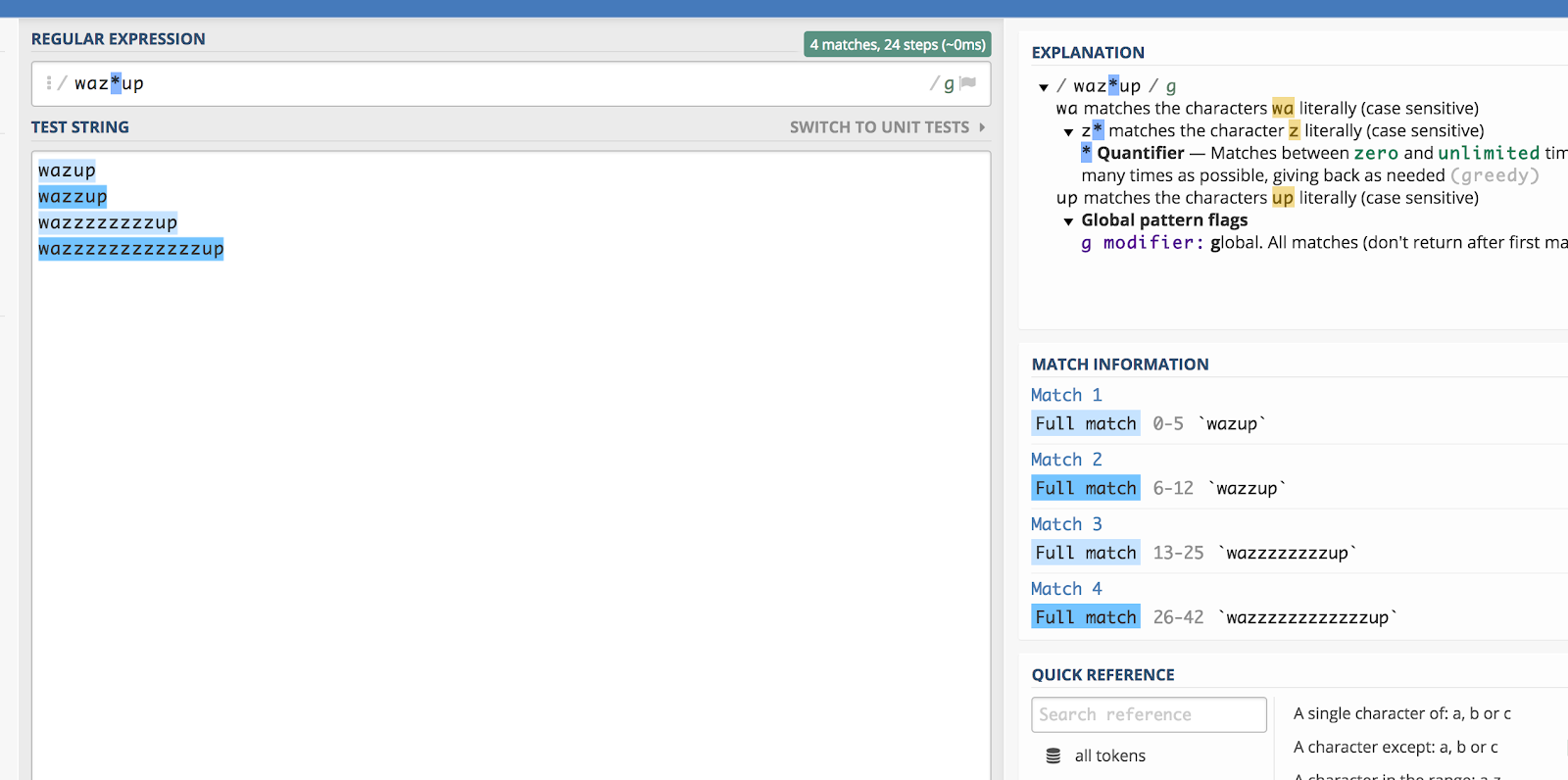
L’astérisque (*) correspond au caractère précédent zéro fois ou plus.
Si vous voulez être super précis et tenir compte des caractères majuscules et minuscules, vous pouvez écrire quelque chose comme ceci :
*
Mais je m’égare.
Là où l’astérisque est en fait le plus puissant et le plus couramment utilisé, c’est avec un point ou dans le cadre d’autres combinaisons regex.
Combinaison point-astérisque (.*)
La combinaison point-astérisque (.*) signifie fondamentalement que tout est permis. Elle est très couramment utilisée.
Vous utiliseriez cette combinaison lorsque vous voulez faire correspondre n’importe quoi dans une chaîne de caractères. Puisque le point signifie correspondre à n’importe quel caractère, et que l’* signifie correspondre à zéro ou plus des caractères qui le précèdent, cette combo est très puissante.
Exemple : vous avez plusieurs types différents de comptes clients, mais vous aimeriez voir vos données pour tous ces comptes. Ils ont tous des pages similaires, de sorte que vos pages ressemblent à quelque chose comme ceci:
/customer/pro/login/
/customer/free/login/
/customer/starter/login/
Vous pouvez écrire la regex suivante pour faire cela:
/customer/.*/login
J’utilise couramment cette expression regex de Google Analytics pour configurer des segments pour les utilisateurs avec un ID utilisateur.
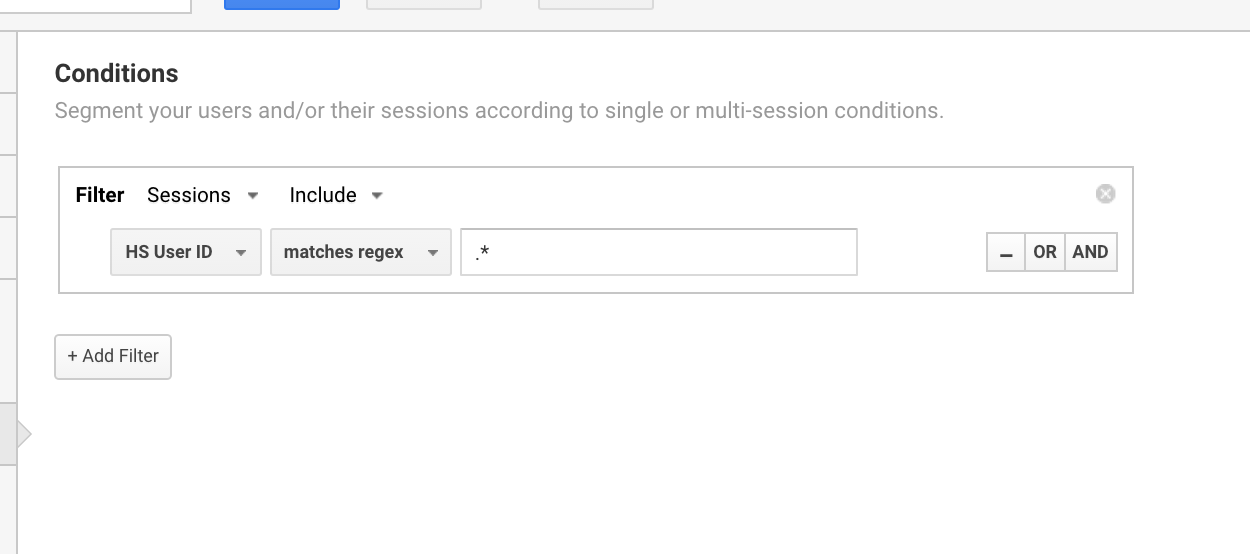
Utilisation de la regex de Google Analytics pour isoler toutes les sessions qui ont un ID utilisateur.
Signe plus (+)
Le signe plus (+) est très similaire à l’*, sauf qu’il correspond à UN ou plusieurs des caractères précédents. Il n’y a pas grand chose de plus à dire sur celui-ci, seulement qu’il est très légèrement différent de l’astérisque. Voici la différence :
Imaginez que vous avez les mots : bonjour, hhello, et hhhello.
Si vous écrivez hh+ello, il ne correspondra qu’aux deux seconds, mais si vous écrivez hh*ello, il correspondra à tous.
Distinction mineure. En réalité, j’utilise presque toujours l’astérisque au lieu du signe plus.
Point d’interrogation ( ?)
Le point d’interrogation ( ?) est facile. Il signifie simplement que le dernier caractère est une option.
Disons que vous ne vous souciez pas beaucoup de savoir si le mot est pluriel ou non (comme pour les chaussures). Il peut être « chaussure » ou « chaussures », et vous voulez le capturer dans les deux cas. Alors, vous pouvez écrire « shoes ? »
Voici un exemple en utilisant mon nom. Si quelqu’un l’épelle « Alex Birket » lors d’une recherche de site, je voudrais probablement toujours le voir. Je peux donc écrire:
Alex Birkett?
Voici comment cela se présente dans regex101.com:
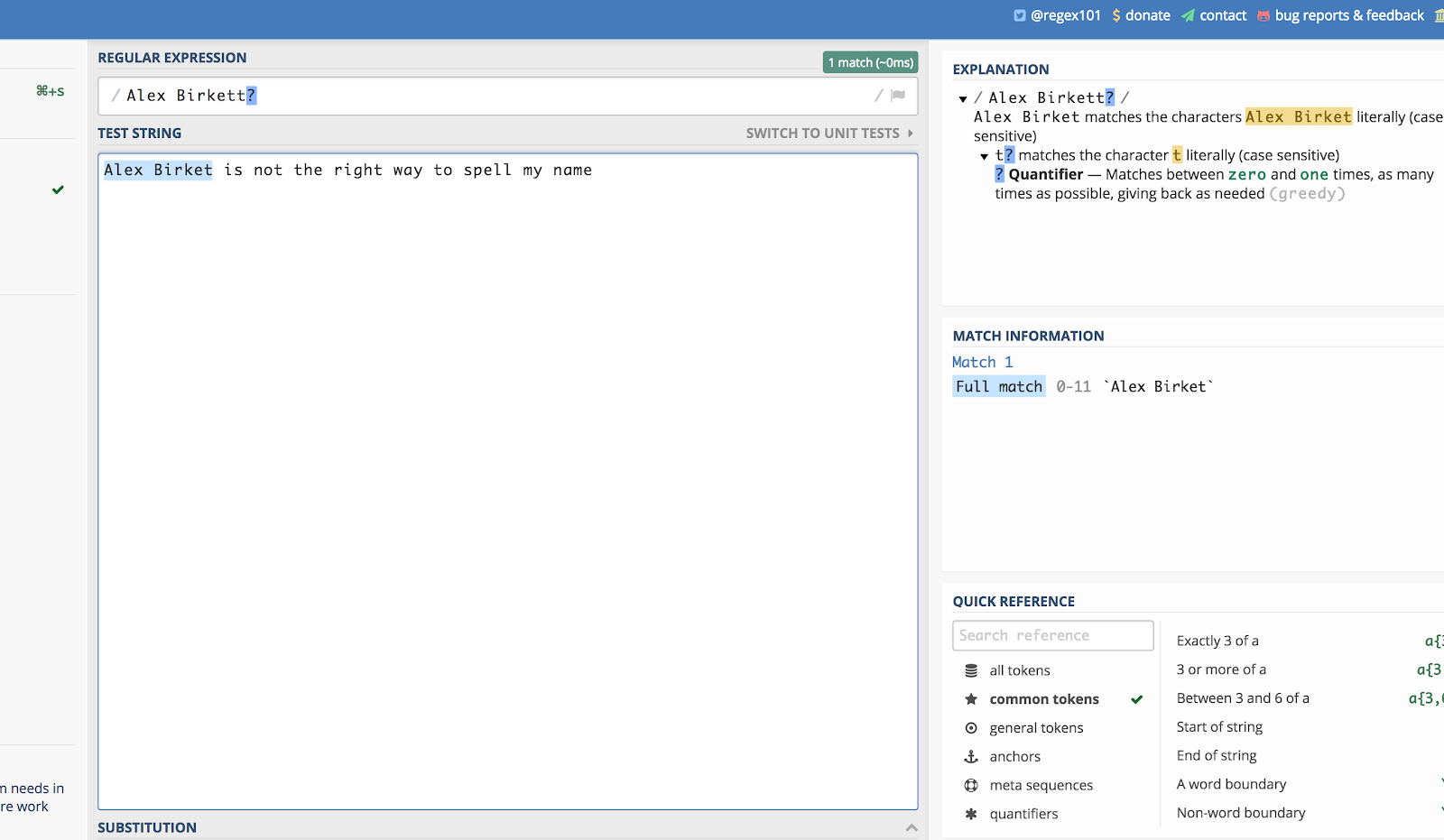
Le point d’interrogation ( ?) fait en sorte que le dernier caractère qui le précède est facultatif.
Parenthèses ()
Les parenthèses fonctionnent de la même manière qu’en mathématiques. Ils vous disent de hiérarchiser et d’isoler la logique qu’il est en jeu à l’intérieur d’eux.
Disons que vous avez une entreprise SaaS avec trois offres et que vous voulez faire correspondre toutes vos pages de prix. Vos URL sont les suivantes :
site.com/produits/meetings/pricing
site.com/produits/crm/pricing
site.com/produits/email/pricing
Pour les attraper tous les trois, vous pourriez utiliser une expression régulière comme celle-ci:
^/produits/(meetings|crm|email)/pricing$
Crochets ()
Les crochets () créent une liste. Si vous avez trois chaînes de caractères, « chose1″, chose 2 » et « chose3 », vous pouvez toutes les faire correspondre en écrivant « chose » ou « chose » (nous reviendrons sur les tirets dans un instant – ils sont couramment utilisés avec les crochets.
Les crochets peuvent être utilisés pour faire correspondre plusieurs itérations d’un mot ou d’une chaîne de caractères, tout en excluant plusieurs autres itérations. Par exemple, si vous voulez faire correspondre « can », « man » et « fan », mais pas « dan », « ran » ou « pan », vous pouvez utiliser la regex suivante pour le faire :
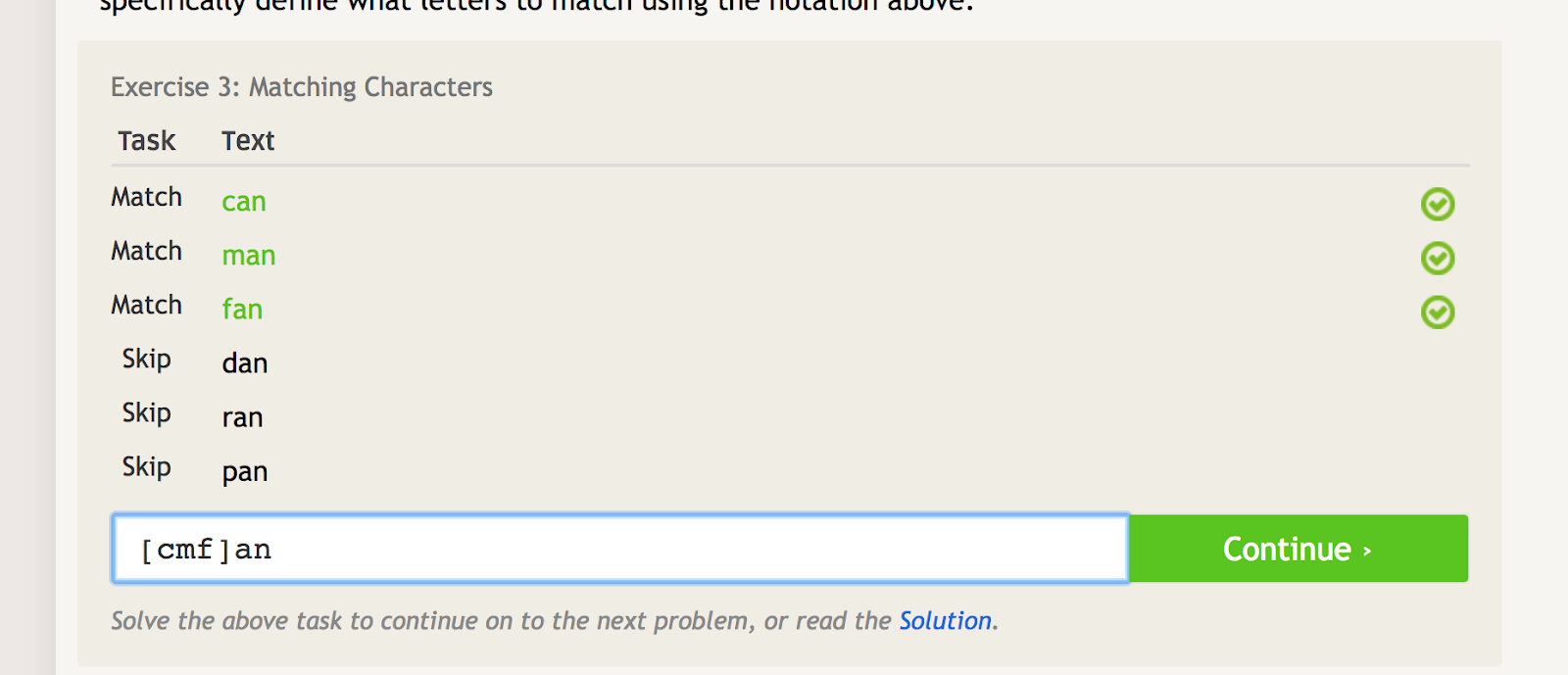
Les crochets créent plusieurs conditions de correspondance en fonction des caractères que vous mettez à l’intérieur. – image source
C’est quelque chose que vous pouvez utiliser si vous avez quelques produits différents avec des noms similaires, comme « chaussures1, » chaussures3, » et « chaussures5 ». Vous pourriez les faire correspondre, et rien d’autre, en utilisant « chaussures »
Les tirets (-)
Les tirets (-) fonctionnent pour créer des listes linéaires d’éléments.
Comme dans, lorsque vous utilisez des crochets, vous n’avez pas à simplement tout énumérer si cela se produit linéairement. Ainsi, si vous vouliez faire correspondre une chaîne de chiffres où le dernier peut être n’importe quoi de zéro à neuf, vous pourriez écrire ceci :
1234
Ou, vous pourriez écrire le beaucoup plus simple :
1234
Cela fonctionne aussi pour les lettres. Imaginons que vous ayez une catégorie de page qui se termine par deux lettres aléatoires. Quelque chose comme ceci:
/page-aa/
Vous pouvez faire correspondre tous ces éléments en écrivant:
/page-*/
Vous pouvez voir un exemple de cela sur regex101 ici:
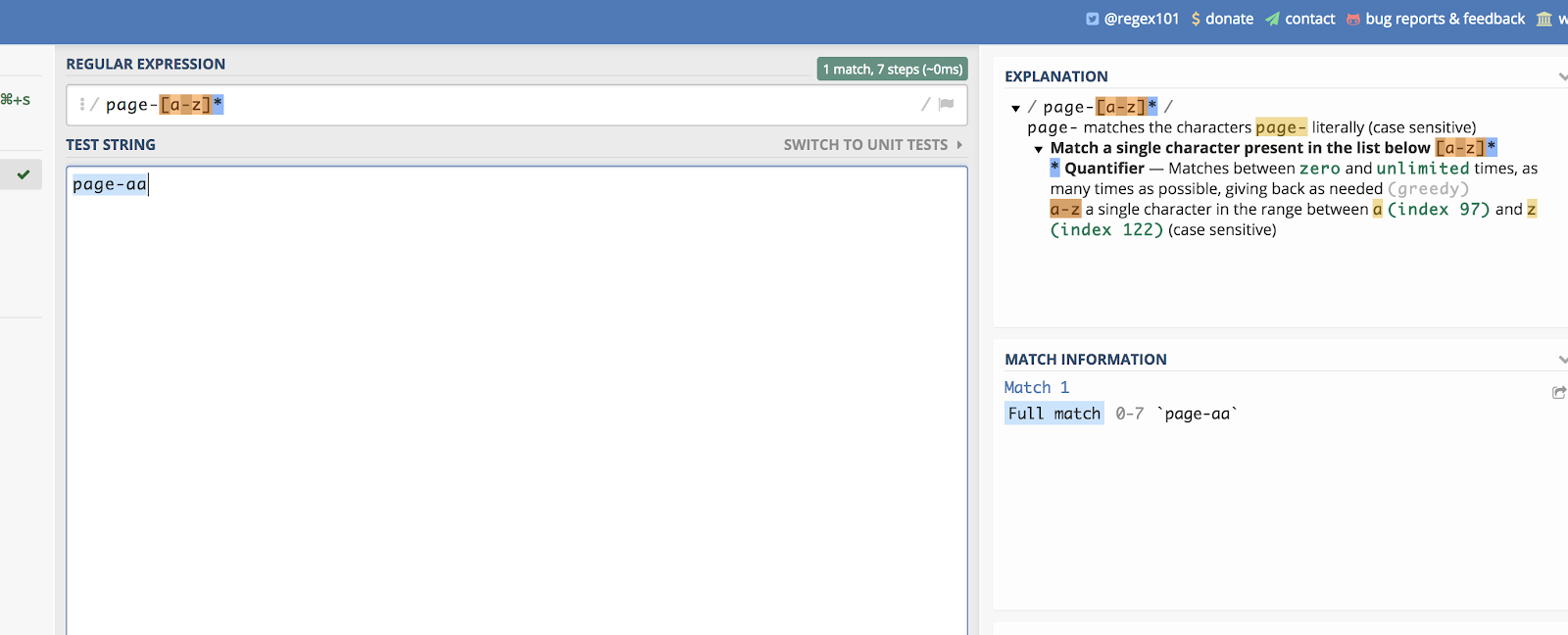
Les tirets vous aident à créer une liste linéaire à faire correspondre.
Parenthèses bouclées ({ })
Les parenthèses bouclées ({}) vous indiquent combien de fois répéter le dernier élément.
Par exemple, si vous voulez faire correspondre seulement « wazzzzup », vous pouvez utiliser « waz{4}up ».
Mais si vous voulez faire correspondre « wazzzzzup », et « wazzzup », mais pas « wazup », vous pouvez utiliser « waz{3,5}up ». Cela revient à dire qu’il faut faire correspondre le caractère « z » pas moins de 3 fois, mais pas plus de 5 fois.
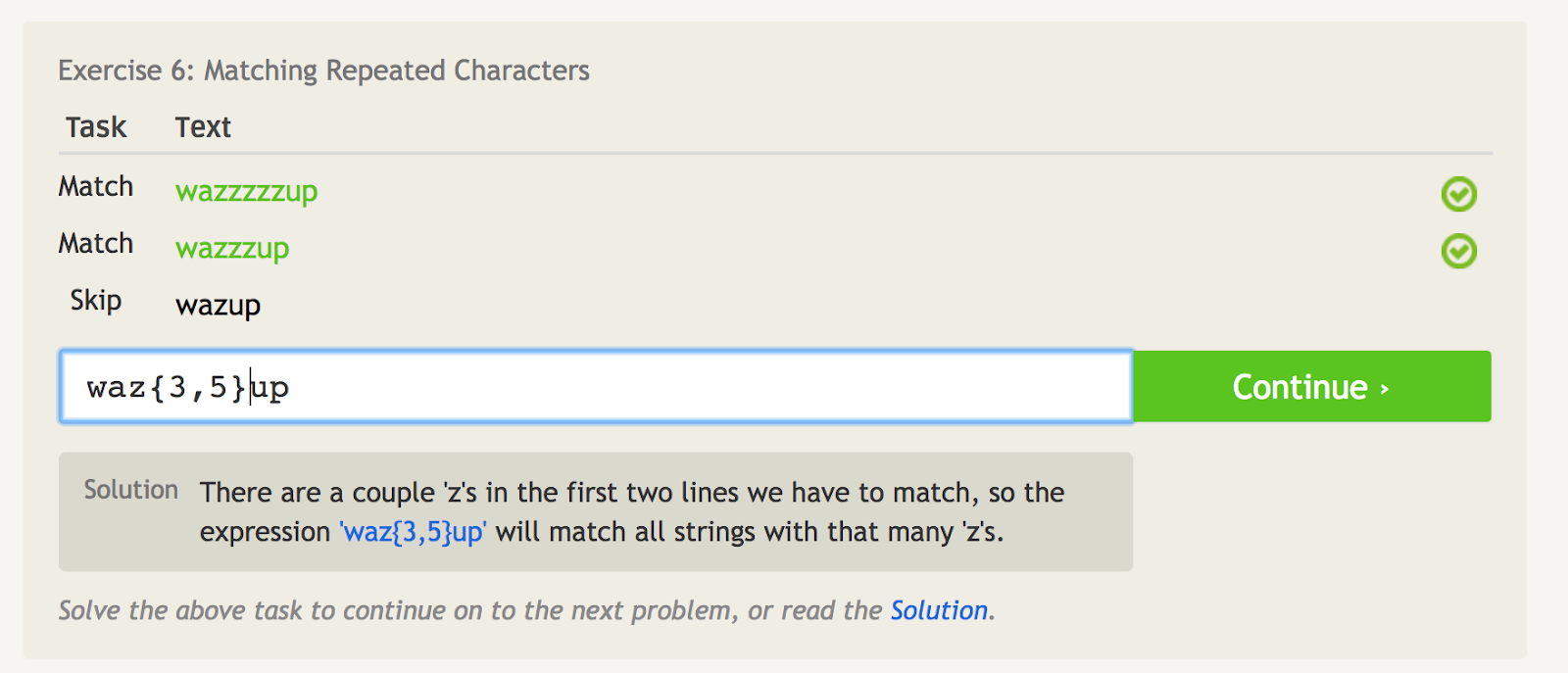
Les crochets arrondis vous indiquent combien de fois répéter le dernier élément. – source image
Je n’ai vraiment pas beaucoup utilisé cette expression régulière dans Google Analytics, mais un cas d’utilisation commun pourrait être pour les codes postaux. Habituellement, les deux premiers caractères sont les mêmes dans une ville (78- pour Austin, TX, par exemple). Vous pourriez donc faire correspondre n’importe quel code postal d’Austin, TX, en écrivant :
78{3}
Cela dit que les trois dernières lettres peuvent être n’importe quel nombre aléatoire de zéro à neuf.
Google Analytics RegEx : Exemples spécifiques que vous pouvez utiliser
L’un des cas d’utilisation de regex les plus courants de Google Analytics est la construction de filtres. Parcourons trois exemples, l’un simple et l’autre un peu plus compliqué.
Premièrement, un exemple inspiré d’un grand post sur Search Engine Land par Jenny Halasz.
Disons que vous avez une architecture de site désordonnée, mais que vous voulez regarder tous les articles avec un certain sous-répertoire. Cela pourrait être n’importe quoi, disons une catégorie de site ou un type de contenu. Dans cet exemple, nous recherchons une catégorie du site pour /music/, mais uniquement dans le troisième sous-répertoire. Dans ce cas, vous pouvez écrire ^/.*/.*/music/.* et cela vous donnera ce rapport.

Cette regex Google Analytics vous montrera uniquement /music/ dans le troisième sous-répertoire. – image source
Cela semble déroutant à première vue – mais après avoir appris ce que ces expressions régulières signifient, c’est assez simple. Fondamentalement, nous disons simplement à GA de faire correspondre la page d’atterrissage qui commence par (^) une barre oblique, puis tous les caractères (.*), puis une barre oblique, puis tous les caractères (.*), puis une barre oblique, et enfin de la musique.
LawnStarter utilise une tactique similaire pour les rapports. Leur stratégie consiste à créer un contenu spécifique à la ville dans leon un sous-dossier de leurs pages de ville, en utilisant le format suivant:
https://www.lawnstarter.com/{{page transactionnelle de la ville }}/{pièce de contenu informationnel }}
Pour filtrer le contenu des entonnoirs de conversion et des rapports de trafic, ils utilisent le regex suivant, selon le fondateur Ryan Farley.
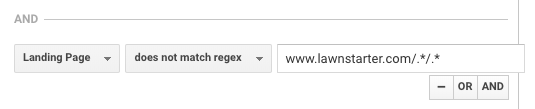
Cette regex aide LawnStarter à faire correspondre le contenu spécifique à une ville sur leur site.
Deuxièmement, voyons comment configurer un filtre pour l’une de vos vues Google Analytics. Il est probable que vous ayez un spécialiste de la mise en œuvre qui fait cela – mais si ce n’est pas le cas, toujours mesurer deux fois et couper une fois ici. Il est facile de gâcher ces choses (c’est aussi pourquoi vous devriez configurer votre compte Google Analytics avec une vue bac à sable pour essayer les choses d’abord).
Pour configurer les filtres, allez dans Admin > Filtres > Ajouter un filtre.
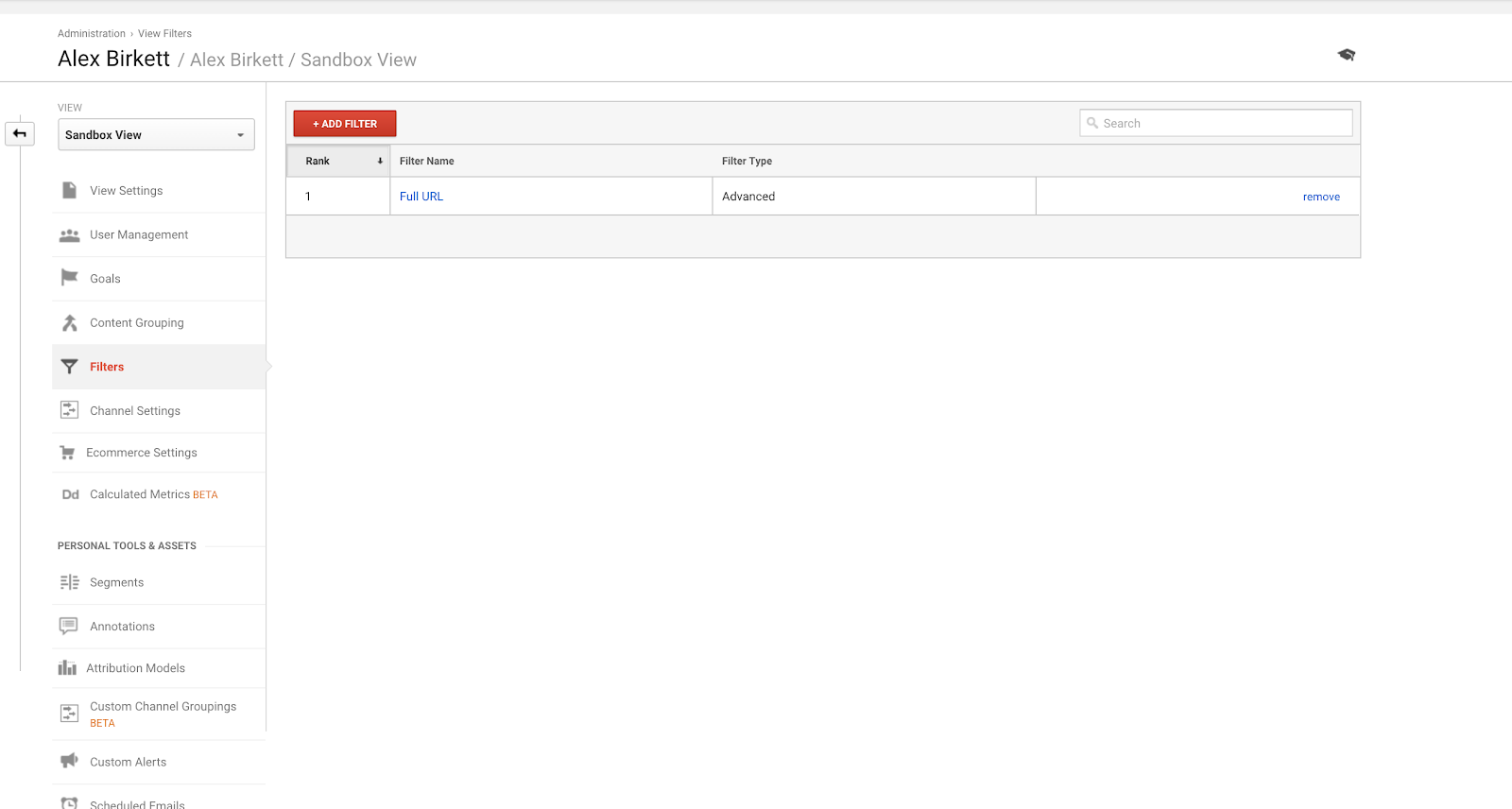
Le filtre le plus couramment utilisé dans Google Analytics est probablement d’exclure le trafic de votre ou vos propres adresses IP.
Pour beaucoup, vous pouvez configurer cela simplement, car vous n’avez qu’une seule IP. Pour les plus grandes entreprises, vous pouvez avoir une série d’IP, et vous pouvez configurer des exclusions plus facilement avec la regex de Google Analytics.
Par exemple, si vous écrivez 63\.212\.171\, cela exclurait toutes les adresses IP de 63.212.171.1 à 63.212.171.9.
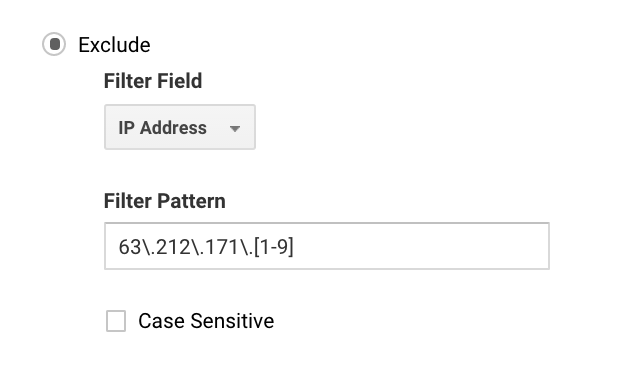
Cette regex Google Analytics exclut plusieurs adresses IP.
Une autre chose que vous pouvez faire avec la regex Google Analytics est de mettre en place des filtres pour nettoyer les paramètres de requête.
Cela peut être à la fois ennuyeux et problématique pour votre analyse de données.
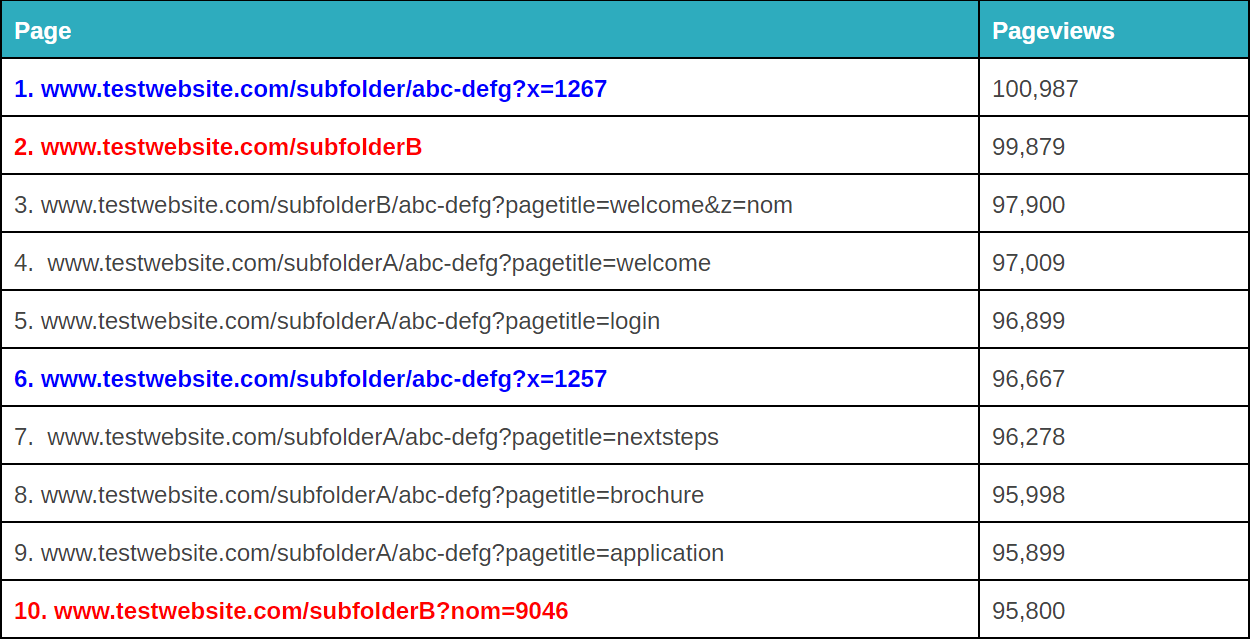
Les paramètres de requête fracturés peuvent être ennuyeux. – image source
Cela dépendra de la façon dont votre situation spécifique est, mais il y a quelques façons différentes dont vous pouvez utiliser regex pour nettoyer cela (note : vous pouvez également le faire dans Google Tag Manager ou Excel, selon l’étendue du problème. Plus d’informations à ce sujet ici).
Enfin, parlons d’un exemple que nous pouvons utiliser pour mieux organiser notre suivi des sous-domaines. Si vous avez plusieurs domaines ou sous-domaines, il est possible que vous ayez des URL en double, à moins que vous ne configuriez un filtre pour faire précéder votre nom d’hôte de votre URi de requête. En d’autres termes, vous pourriez avoir deux URL:
- site.com/about
- blog.site.com/about
Ils représentent deux pages différentes (l’une est une page sur votre entreprise et l’autre est une section about pour votre blog). Mais elles seraient toutes deux vues dans Google Analytics comme /about, à moins que vous ne configuriez le filtre suivant (en utilisant des expressions régulières de Google Analytics combinant point et astérisque):
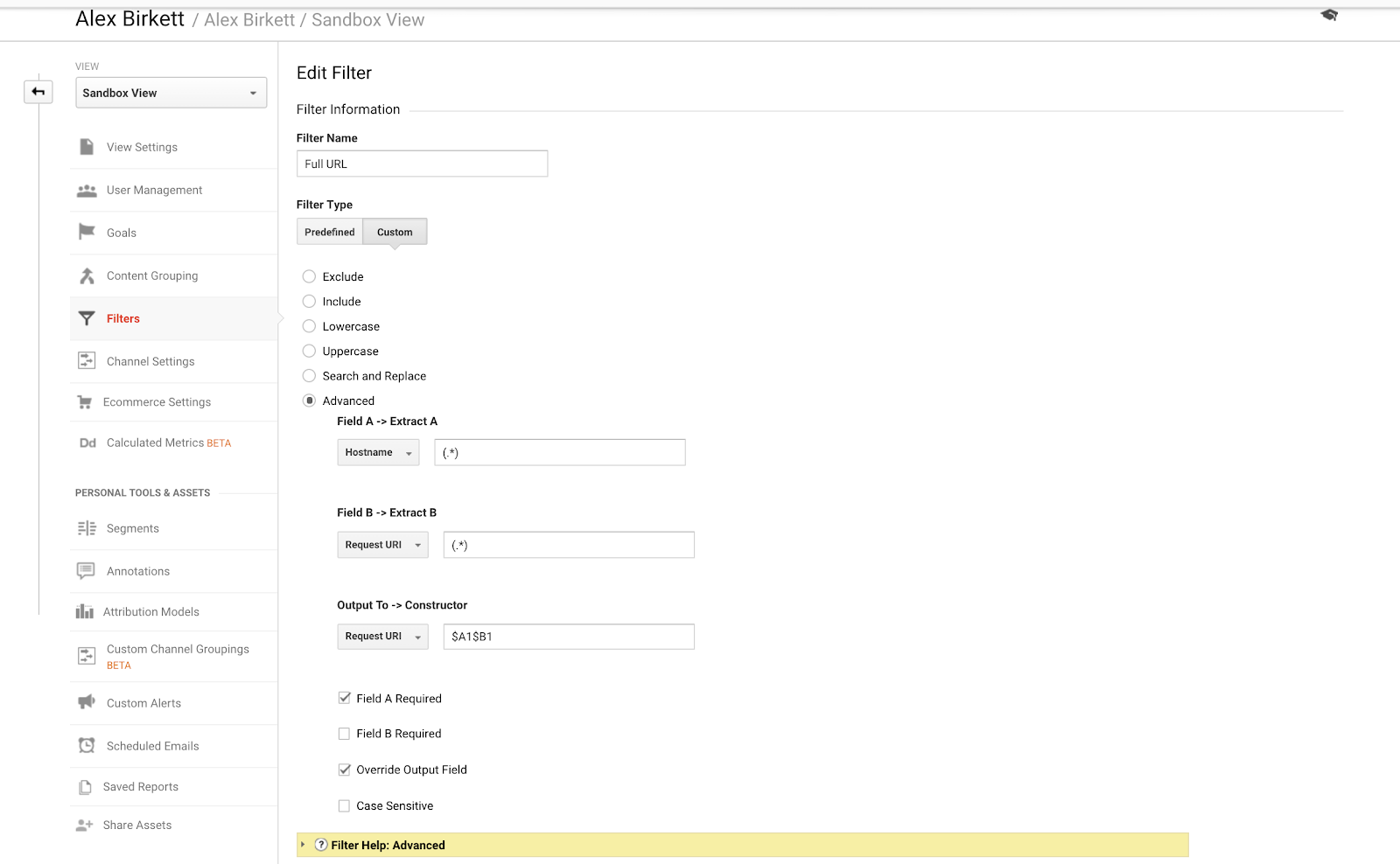
Il est assez simple de mettre en place ce filtre fondamental de GA. – source de l’image
Nous avons en fait déjà couvert la façon de configurer ces filtres de façon assez approfondie dans un post précédent de KlientBoost sur le suivi des domaines croisés et des sous-domaines.
Conseils sur les RegEx de Google Analytics & Erreurs à éviter
Les expressions régulières font partie de ces choses que vous devez juste pratiquer et vous salir les mains pour apprendre. En tant que tel, vous allez faire des erreurs.
C’est le conseil le plus important, vraiment : essayez les choses et voyez si elles fonctionnent. J’ai listé des tonnes de ressources dans ce post sur la façon de tester votre regex, de regex101.com à regexbuddy.com. Trempez vos orteils et utilisez ces ressources.
Cependant, avec un peu de foresite et d’heuristique, vous pouvez apprendre plus rapidement et attraper plus d’erreurs.
Une chose à vraiment apprendre est comment « échapper » en regex (nous en avons parlé à propos de la barre oblique inverse). Leho Kraav, directeur technique chez CXL Institute, le formule ainsi :
« Je dirais « apprendre à bien échapper les choses » – il est facile d’obtenir des incompatibilités lorsque les caractères sont les mêmes, mais que leur signification est différente selon qu’ils sont échappés ou non. »
Par exemple, si votre requête comporte un point d’interrogation, il s’agit également d’une expression régulière, vous devez donc le préciser avec l’antislash. Chris Mercer, fondateur de MeasurementMarketing.io, affirme également que ne pas apprendre cette capacité est l’une des plus grandes erreurs qu’il voit les débutants faire :
« L’erreur la plus courante que nous voyons avec les débutants qui utilisent les regex est d’oublier d' »échapper » les symboles de regex. Par exemple, si vous recherchez des pages qui correspondent au regex « thankyou/?success=yes », cela ne fonctionnera pas. Le » ? » lui-même est un symbole de regex et doit être désactivé à l’aide du » caractère d’échappement » (le » \ « ). Dans ce cas, « thankyou/\?success=yes » fonctionnerait. »
Un autre conseil ? Restez simple. Les gens essaient de compliquer les choses (regardez la regex la plus compliquée que vous ayez jamais vue, écrite par Leho, ici), mais les expressions régulières sont « gourmandes » et correspondront autant que possible. Google Analytics a publié un billet de blog de conseils et l’a expliqué comme suit :
« Si vous devez écrire une expression pour correspondre à « nouvelles visites », et que les seules options contre lesquelles vous allez correspondre sont « nouvelles visites » et « visites répétées », juste le mot « nouvelles » est suffisant.
Elles correspondront à tout ce qu’elles peuvent, sauf si vous les forcez à ne pas le faire. Si votre expression est « visites », elle correspondra à « nouvelles visites » et « visites répétées ». Après tout, ils ont tous deux inclus l’expression « visites ». Pour les rendre moins gourmands, vous devez les rendre plus spécifiques. »
Donc, commencez lentement, restez simple, et ne vous submergez pas de complexité (le risque d’erreur est corrélé à la complexité dans ce cas).
Mercer réitère également ce point, en conseillant de prendre les choses progressivement :
« Lorsque vous commencez, concentrez-vous sur le fait de devenir bon… puis de devenir meilleur. Il est facile d’être submergé par toutes les différentes possibilités que la regex vous offre, mais si vous commencez simplement par les bases, comme la maîtrise du symbole pour « ou » (le » | « ), vous obtenez rapidement de l’expérience et commencez à réaliser ce qui est possible avec la regex. »
Dernier conseil de ma part : apprenez à chercher des trucs sur Google. C’est vrai pour toute programmation, mais surtout pour les expressions régulières. Vous allez oublier des choses, et si vous n’écrivez pas quotidiennement des regex, il n’y a pas vraiment d’intérêt à tout mémoriser. Apprenez à chercher des choses et à trouver des réponses à ce que vous essayez de faire.
En dehors de Google Analytics : RegEx pour d’autres utilisations marketing
Regex est également quelque chose que tous les praticiens du référencement devraient examiner. D’abord, évidemment, parce que le référencement et l’analyse numérique (par exemple, Google Analytics) sont inextricablement liés. Deuxièmement, parce que certaines des mêmes expressions de correspondance que nous écrivons pour filtrer et faire correspondre des caractères sur nos données Google Analytics peuvent également être utilisées dans l’extraction de données pour les tactiques de référencement.
En d’autres termes, les expressions régulières sont importantes pour le web scraping.
En cas de web scraping et de référencement, vous travaillerez généralement à travers un langage de programmation comme Python, mais les principes sont les mêmes.
À titre d’exemple, vous pourriez scraper tout le texte en gras sur une page en utilisant ceci:
<strong>(+)</strong>
Or comme mentionné dans cet article du SEJ, si l’on scrape ESPN pour tous les auteurs, on pourrait écrire ceci:
« chroniqueur » : »(.* ?) »
Pour des raisons de cohérence et de bon sens, je ne vais pas me plonger entièrement dans le web scraping avancé. Il suffit de savoir que regex est important dans ce domaine, aussi. Cependant, si vous souhaitez en savoir plus, je vous suggère ces sources :
- Web Scraping with Regular Expressions
- Scraping with Regular Expressions (Stanford)
- How to Use Regex for SEO & Website Data Extraction
Les expressions régulières vous aident également à travailler avec vos données de référencement, au-delà du simple scraping du web. Par exemple, vous pouvez utiliser des regex pour personnaliser davantage la façon dont vous utilisez Screaming Frog.
Jenny Halasz a donné un bon exemple d’utilisation de regex pour nettoyer les données dans un post de Search Engine Land:
« Par exemple, disons que vous avez une liste d’URL et que vous avez besoin de les décomposer en juste le TLD (Top Level Domain).
Vous pouvez utiliser un simple rechercher/remplacer pour http et www, mais comment faire pour éliminer facilement tous les noms de fichiers ? Vous pourriez les supprimer tous manuellement, mais c’est pénible. En utilisant un simple joker regex (/*), vous pouvez supprimer la barre oblique et tout ce qui vient après. »
Nous pourrions parler à l’infini des expressions régulières pour le référencement et le web scraping, mais je vais simplement faire un lien vers de bonnes ressources au cas où vous voudriez en savoir plus (c’est un langage très polyvalent, après tout, avec de nombreux cas d’utilisation au-delà de l’analytique) :
- Comment l’expression régulière affecte le SEO
- 5 Powerful Awesome Htaccess Redirect Tricks
- Comment utiliser l’expression régulière pour la segmentation des rapports
Conclusion
Google Analytics regex est vraiment quelque chose que chaque analyste devrait connaître, même si vous ne vous imaginez pas être un technicien. Au-delà de cela, connaître quelques expressions régulières (ou au moins comment rechercher des réponses et les appliquer aux bons problèmes) peut aider les marketeurs dans diverses activités également.
Je dis juste que ce n’est pas un ensemble de compétences très commun, donc vous allez probablement impressionner certains collègues avec vos nouvelles compétences techniques en marketing.
Je vous exhorte donc, commencez à apprendre, et plus important encore, commencez juste à pratiquer l’utilisation des expressions régulières. Elles ne sont pas si effrayantes que ça.