読了。 30分
識別モデルは、条件付きモデルとも呼ばれ、統計的分類、特に教師あり機械学習で用いられるモデルのクラスである。
共同確率P(x,y)から研究する生成モデルとは異なり、識別モデルはP(y|x)すなわちを研究している。
- これを数学的な例で理解しよう。
入力データがxで、xに対するラベルのセットがyであるとする。
(x,y) –> {(0,0), (0,0), (1,0), (1,1)}上記のデータについて、p(x,y)は次のようになります:
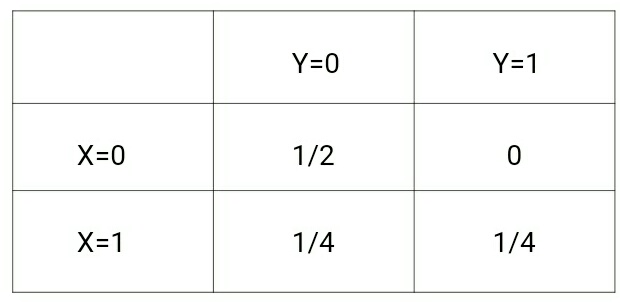
一方p(y|x)は次のようになります:
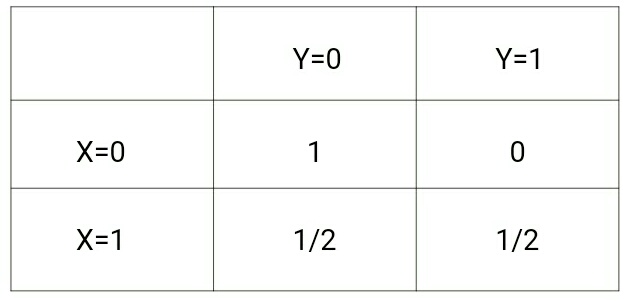
これらの二つの行列を見てみると、二つの確率分布間の違いが理解できます。
つまり、識別的アルゴリズムはデータから直接 p(y|x) を学習して、データを分類しようとする。
一方、生成的アルゴリズムは p(x,y) を学習して、後で p(y|x) に変換してデータを分類しようとする。 生成的アルゴリズムの利点は、p(x,y)を使って既存のデータに似た新しいデータを生成できることです。 一方、識別アルゴリズムは一般に分類タスクにおいてより良い性能を与えます。
識別モデルでは、学習例 x からラベル y を予測するために、
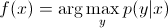
を評価しなければなりません。これは単に x を考慮して最も可能性の高いクラス y は何かを選択するだけで、クラスの間の決定境界をモデル化しようとしているようなものです。 この動作はニューラルネットワークで非常に明確で、計算された重みは、空間内のクラスの要素を分離する複雑な形の曲線として見ることができます。
- focus on decision boundary.
- more powerful with lot of examples.
- not designed to use unlabeled data.
- only supervised task.
Discriminative Classifiers Examples
Discriminative models are preferred in the following approches.Discriminative models are preferred in the following approach:
- ロジスティック回帰
- スカラーベクターマシン
- 従来のニューラルネットワーク
- 最近傍探索
- 条件付きランダムフィールド(CRF)