Google Analytics regex(すなわち正規表現)は、あまり評価されていないスキルセットです。
基本以上の何らかのフィルタリングやターゲット化を行う場合、regexをよく理解することでAnalyticsスーパーパワーとなるのです。
Regex はあなたにスーパーパワーを与えてくれます。 – image source
もちろん、正規表現は分析やマーケティングよりもはるかに広い使用例があります。 しかし、この記事では、ユーザー インサイト、データ整理、さらには高度なターゲティングや検索エンジン マーケティングのユースケースに役立つ、戦術的な使用例を取り上げます。
その前に、正規表現とは何か、特に Google Analytics に関連して簡単にまとめておきましょう。
- Google Analytics RegEx: What is It?
- Google Analytics RegEx Cheat Sheet
- Pipe (|)
- バックスラッシュ( \ )
- キャレット (^)
- ドル記号 ($)
- アスタリスク (*)
- Dot-Asterisk combination (.*)
- Plus sign (+)
- Question mark (?)
- 括弧 ()
- 角カッコ ()
- ダッシュ (-)
- カーリーブラケット({ })
- Google Analytics RegEx: Specific Examples You Can Use
- Google Analytics RegEx Tips & Mistakes to Avoid
- Outside of Google Analytics: Google Analytics以外:Regexの他のマーケティング用途
- Conclusion
Google Analytics RegEx: What is It?
正規表現は、検索パターンを記述するための特別なテキスト文字列です。 より具体的には、Google Analytics では、ビュー フィルター、目標、セグメント、オーディエンス、コンテンツ グループ、チャネル グループなどのより柔軟な定義を作成するのに役立ちます。
基本的には、デジタル分析データ内のパターンに広くまたは狭く一致し、選択する、定義済みの文字または一連の文字です。 正規表現は、さまざまな方法で使用できる一般的なツールです(多くのプログラミング言語やツールで正規表現が使用できます)。 しかし、Analytics では、主にデータのパターンに一致させるために使用します。
もちろん、Analytics だけに役立つわけではありません。 特に、Google タグマネージャのユーザーや、A/B テストで複雑なターゲティングを実行している場合は、正規表現を多用することになるでしょう。 MeasurementMarketing.ioの創設者であるChris Mercer氏は次のように語っています:
「私たちは日常的に正規表現を使用しています。 Google Analytics の目標におけるファネルステップから、Google タグマネージャの特定のトリガーまで、すべてを明確に定義するのに役立ちます」
ただし、深く掘り下げて正規表現を学びたい場合は、以下のリソースがあります(Google Analytics の基本機能には必要ありませんし、おそらくより技術力のある人向けです)。 The Complete Tutorial
RegexOne や RegexR などで対話的に学ぶこともできますし、どちらも格好いいです。 7536>
Google Analytics RegEx Cheat Sheet
以下の Google Analytics regex 文字を一種のカンニングペーパーとして見てみましょう。

A very brief guide to Google Analytics regex – image source
しかしながら、これだけでは少し曖昧で漠然としていることがわかると思います。 そこで、よく使われるGoogle Analyticsの正規表現を、対応するユースケースを示しながら解説します。
Pipe (|)
「or」と言いたいときは、パイプ(|)を使用します。 This | That」のように、「This OR That」という意味になります。
Google Analytics のセグメントの熱心なユーザーであれば、OR 論理演算子の使用にはすでに慣れていると思います。 多くの用途がありますが、最も活用されるのは目標を設定するときかもしれません。 例えば、2つのサンキューページがあり、それぞれ異なるURL(/thank-you/ と /subscription-confirmed/ )があるが、両方を目標の完了としてトラッキングしたい場合、この正規表現を使用することが可能です。 例えば、/content-marketing-analytics/ と /content-marketing-lessons/ というURLの2つの記事(コンテンツマーケティングレッスンとコンテンツアナリティクスについて)の行動レポートを表示したいとします。 フィルタとして「content-marketing-analytics|content-marketing-lessons」と書けば、それらの記事だけを取得することができます。
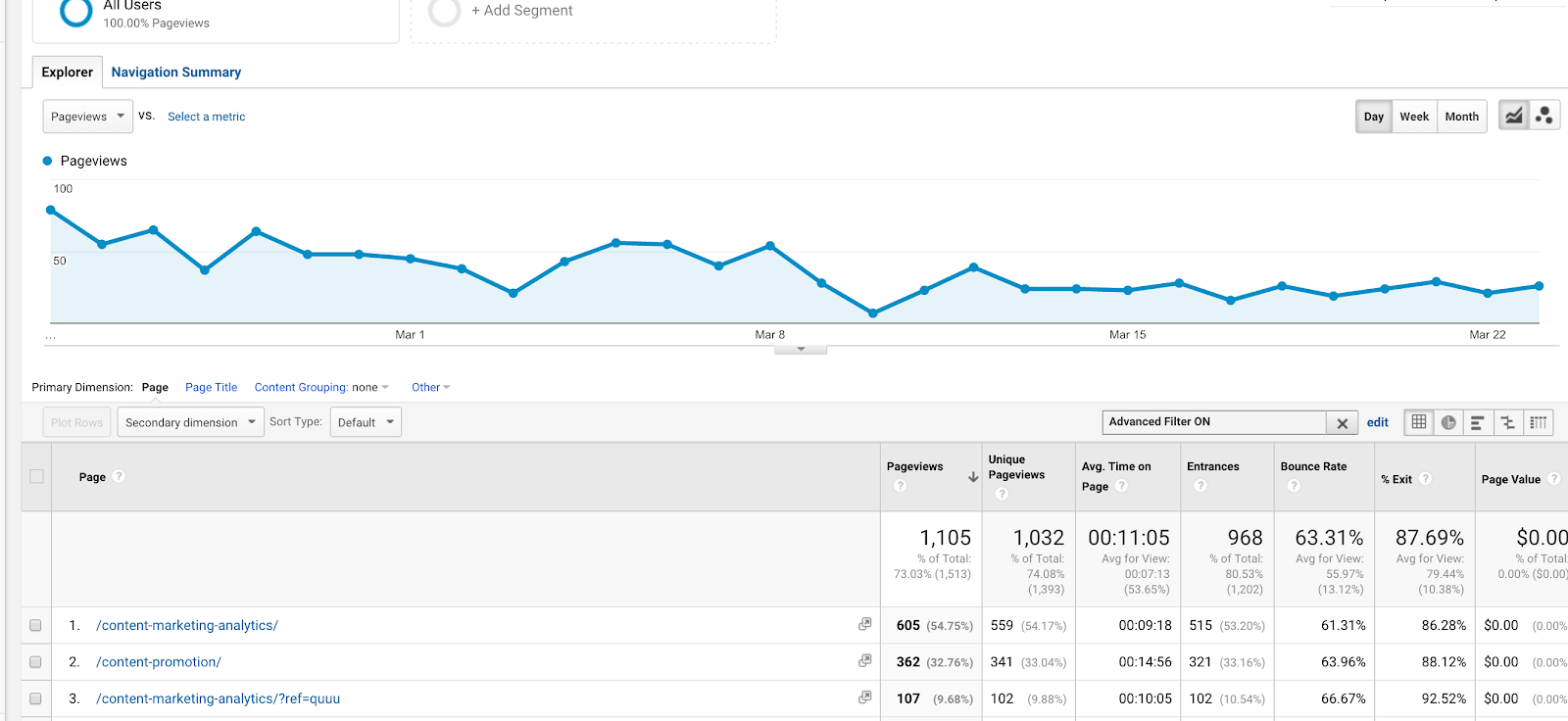
フィルターにパイプ(|)を使って2つの別々のブログ記事の結果を得る
バックスラッシュ( \ )
The backslash (\) is another straightforward forward and commonly used in Google Analytics regular expression in this. 意味は「次の文字は正規表現ではなくプレーンテキストとみなす」
つまり、ドットやクエスチョンマークなど、プレーンテキストで現れる正規表現が多いので、正規表現として読むのかプレーンテキストとして読むのかを明確にする必要があります。
オンラインでよくあるクエリー文字列は、誰かがあなたのサイトで何かを検索するときに使用されます。 たとえば、petsmart.com で「小型犬のおもちゃ」を検索すると、このようなクエリ文字列が表示されます。
ここで疑問符はオンサイト検索が行われたことを意味しますが、Google Analytics でも疑問符はよく用いられる正規表現となっています。 したがって、バックスラッシュを使用する場合は、この場合、クエスチョンマークはプレーンテキストとして読み取られることを明確にしなければなりません。
たとえば、Google Analytics で /search/?q= で始まるすべてのクエリー文字列にマッチさせたいとします(これは検索を意味するため)。 その場合、正規表現は次のようになります。
search/?q=
regex101 などのデバッガーを使用して、これを確認することができます。3549>
キャレット (^)
キャレット (^) は、フレーズが何かで始まっていることを意味します。 これは、どこにでも現れるようなフレーズがあり、そのフレーズの開始点で特にマッチさせたい場合に重要です。 たとえば、”Mission: successful.” という単語を含むいくつかの異なるフレーズの例を見てみましょう。
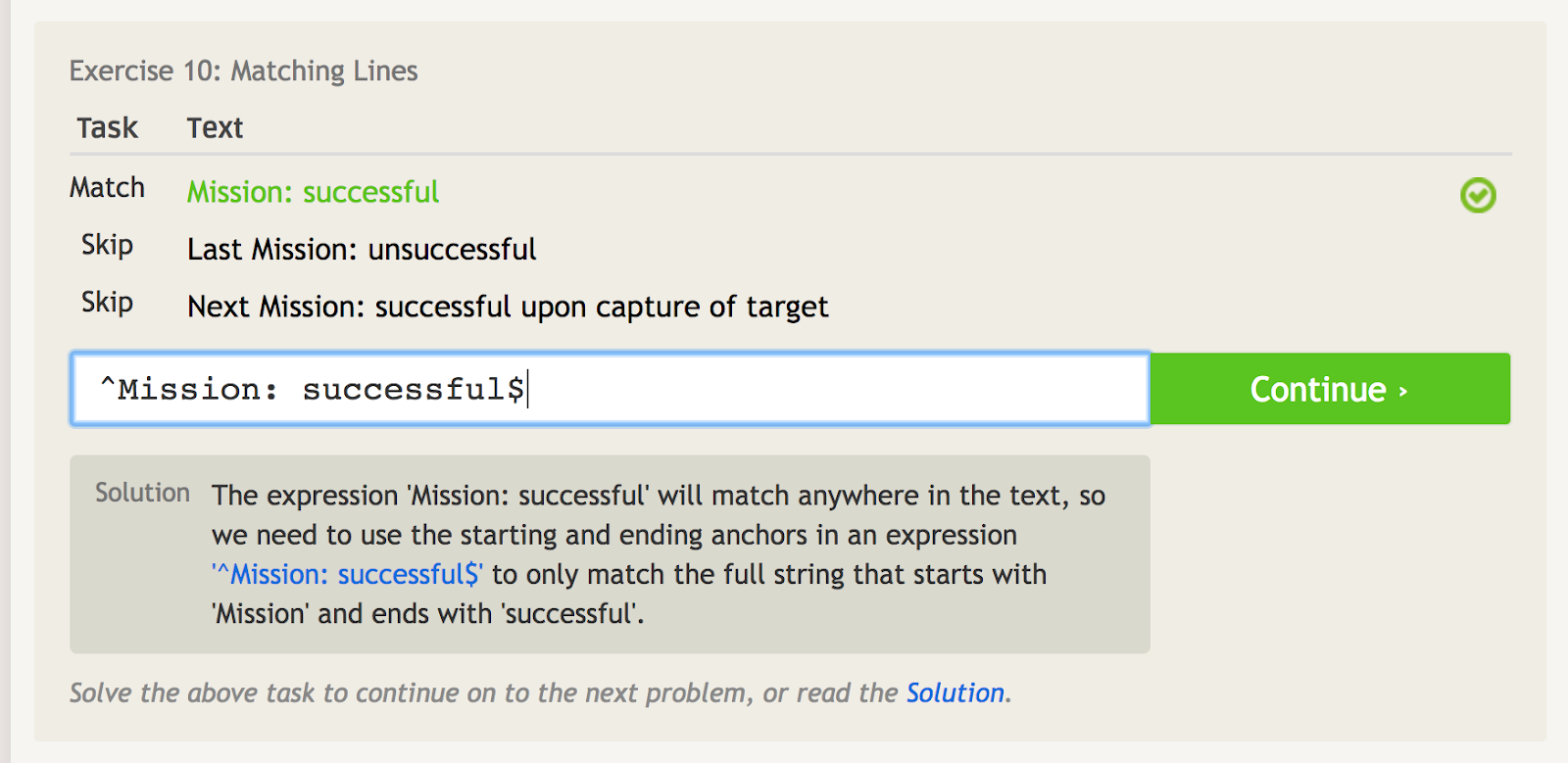
The caret signals the starting anchor, so we can solely match the first phrase here.というように、キャレットは開始アンカーを示します。
すべて同じフレーズで始まる AdWords キャンペーンをたくさん持っているとします(あなたは将来の計画を立てるのが下手なためです)。
- Freemium Campaign Final
- Our first Freemium Campaign
- Creative Freemium Campaign offer
- Test Freemium Campaign
最初の 1 つにマッチするように ^Freemium Campaign と書き、他のものは一切書かないようにしたいと思います。
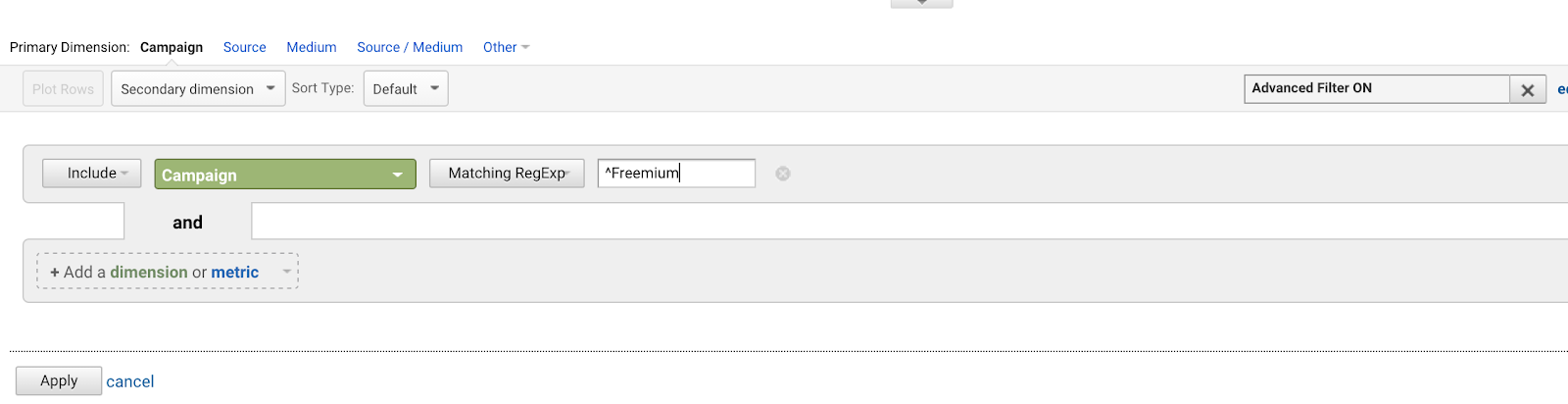
キャレット (^) を使用すると、これらの文字で始まる文字列にマッチします
ドル記号 ($)
ドル記号 ($) はフレーズが何かで終わることを示します
両者を組み合わせると完全一致フレーズをターゲットにすることができます。
「paidacquisitionfb」というタイトルのキャンペーンを開始し、その後「paidacquisitionfb-2」というタイトルのキャンペーンを開始した場合、
^paidacquisitionfb$
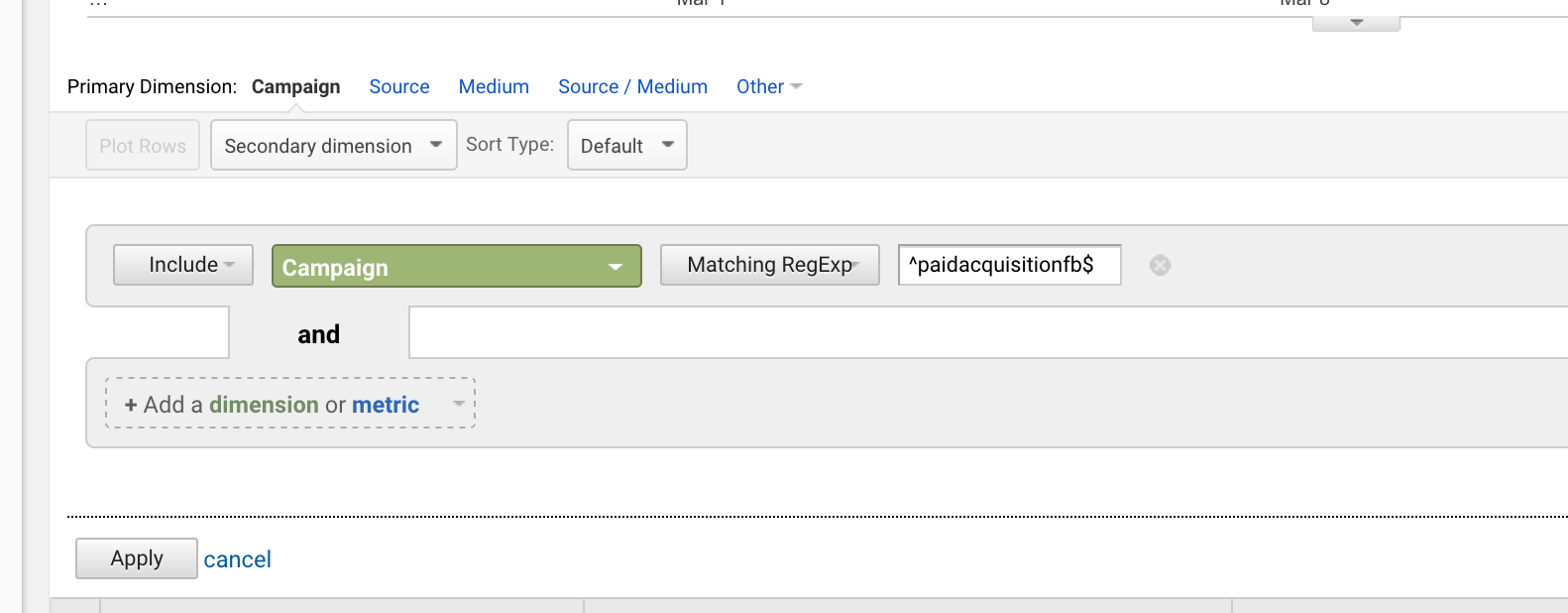
Using the carett and the dollar together is very common.
たとえば、ブログに大量のカテゴリページがあって、それらがすべてページ番号で終わっている場合、Google Analytics regex でブログカテゴリページ (^/page/*/$) のみを表示するように簡単に記述することが可能です。 3549>
- /page/1
- /page/2
- /page/3
…といった具合になります。 これ単独ではあまり役に立ちませんが、他の正規表現、特にアスタリスク(次で説明します)と組み合わせて常に使用されます。
単独で使用したい場合を考えてみましょう。 これは、文字 K と I で始まり、次の 2 文字が何であっても一致します。
つまり、kill、kind、kiss、kin、kid!、kit という単語を含む文字列があった場合、それらすべてに一致することになります。 待って、何? そうです。”kit” と “kin” の後にスペースがある限りマッチします(空白文字も拾います)。 このロジックに従うと、”kid!”の感嘆符も検出されます。
これだけを使用すると、なぜ物事が面倒になるかわかりますね。3549>
アスタリスク (*)
アスタリスク (*) は、前の項目のうち 0 個以上にマッチします。 このように述べるとちょっとわかりにくいので、例で説明します。
少し前のバドワイザーの「ワザップ」というコマーシャルを覚えていますか? 誰かがそのフレーズを検索していた場合 (たとえば、YouTube で)、そのスペルを推測するのはかなり難しいでしょう。
waz*up
regex101 でどのように動作するかの説明です。
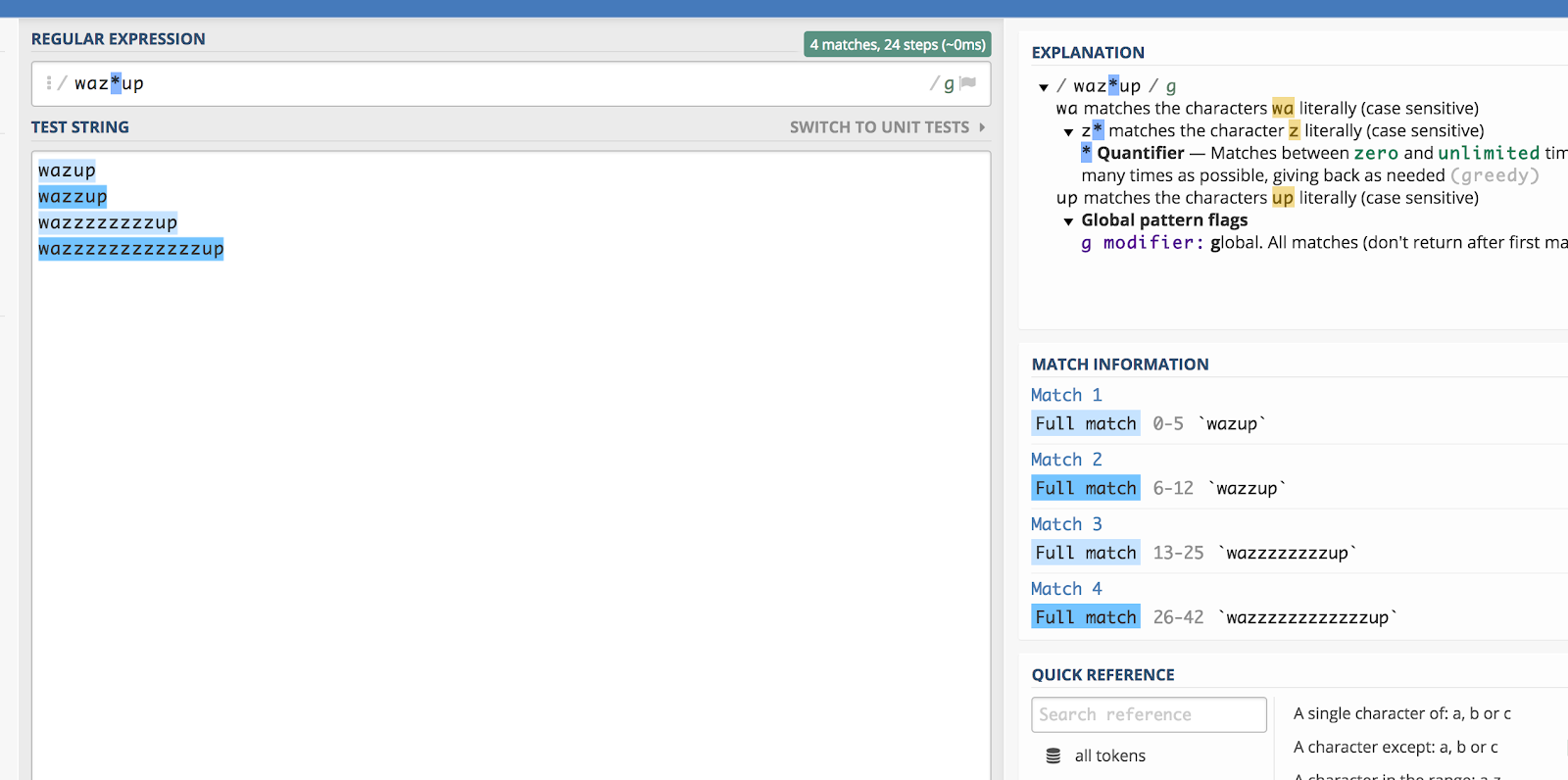
The asterisk (*) matches the previous character zero or more times.All the spelling variations by doing this:
アスタリスクは、前の文字と 0 回以上マッチします。
超正確に、大文字と小文字を考慮したい場合は、次のように書くことができます:
*
余談ですが。
Dot-Asterisk combination (.*)
Dot-Asterisk combo (.*) は、基本的に何でもありという意味です。 これは非常に一般的に使用される。
このコンボは、文字列内の任意のものにマッチさせたいときに使用される。 ドットは任意の文字にマッチし、*はその前の0文字以上にマッチするので、このコンボは非常に強力です。
例:いくつかの異なるタイプの顧客アカウントを持っていますが、それらすべてのデータを見たいとします。
/customer/pro/login/
/customer/free/login/
/customer/starter/login/
以下の正規表現を書くと、このようになります。
/customer/.*/login
私はよくこの Google Analytics 正規表現を使って、ユーザー ID のユーザーに対してセグメントを設定することがあります。
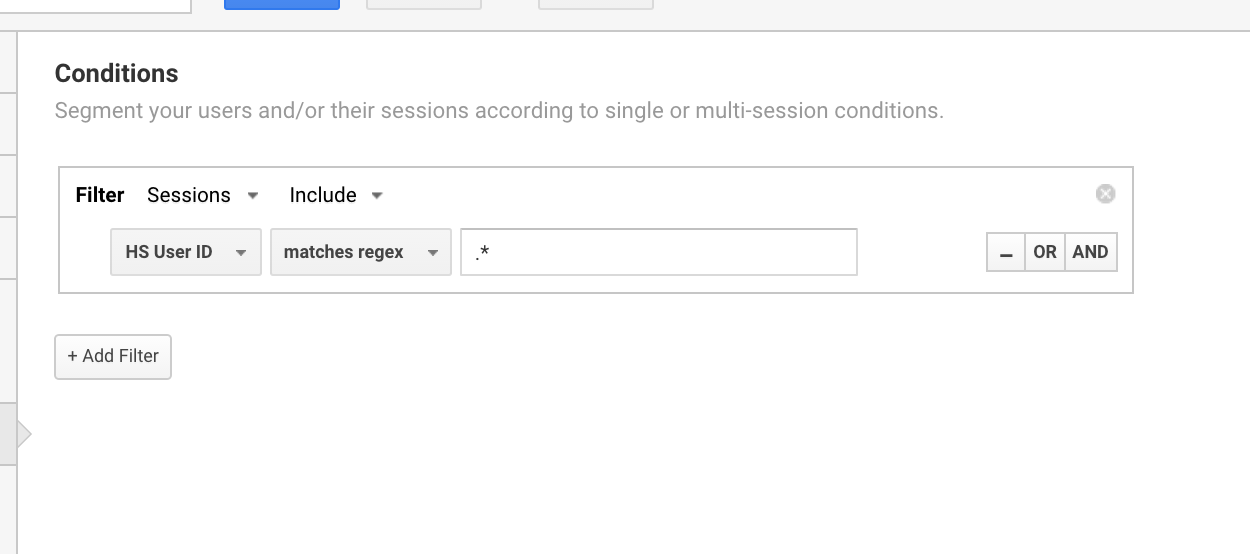
Using Google Analytics regex to isolate all sessions that have a User ID.
Plus sign (+)
plus sign (+) is very similar with the * except it matches one or more of the previous characters.The plus sign ⧏35⧐ + は、1つ以上の文字にマッチすることを除いては、とてもよく似ています。 これについては、アスタリスクとは非常に微妙に異なるということだけで、これ以上言うべきことはないだろう。
たとえば、hello、hhello、hhhello という単語があるとします。
hh+ello と書くと、2 番目の単語にのみマッチしますが、hh*ello と書くと、すべての単語にマッチします。 実際はプラス記号の代わりにアスタリスクを使うことがほとんどです。
Question mark (?)
疑問符(?)は簡単なものです。 最後の文字がオプションであることを意味します。
(靴のように)単語が複数であるかどうかはあまり気にしないことにします。 shoe」でも「shoes」でもよくて、どちらでも捕捉したい。 そうすると、”shoes? “と書くことができます。
ここで、私の名前を使った例を挙げましょう。 サイト内検索で誰かが「Alex Birket」と綴ったとしても、私はそれを見たいと思うでしょう。
Alex Birkett?
regex101.com ではこのように表示されます。
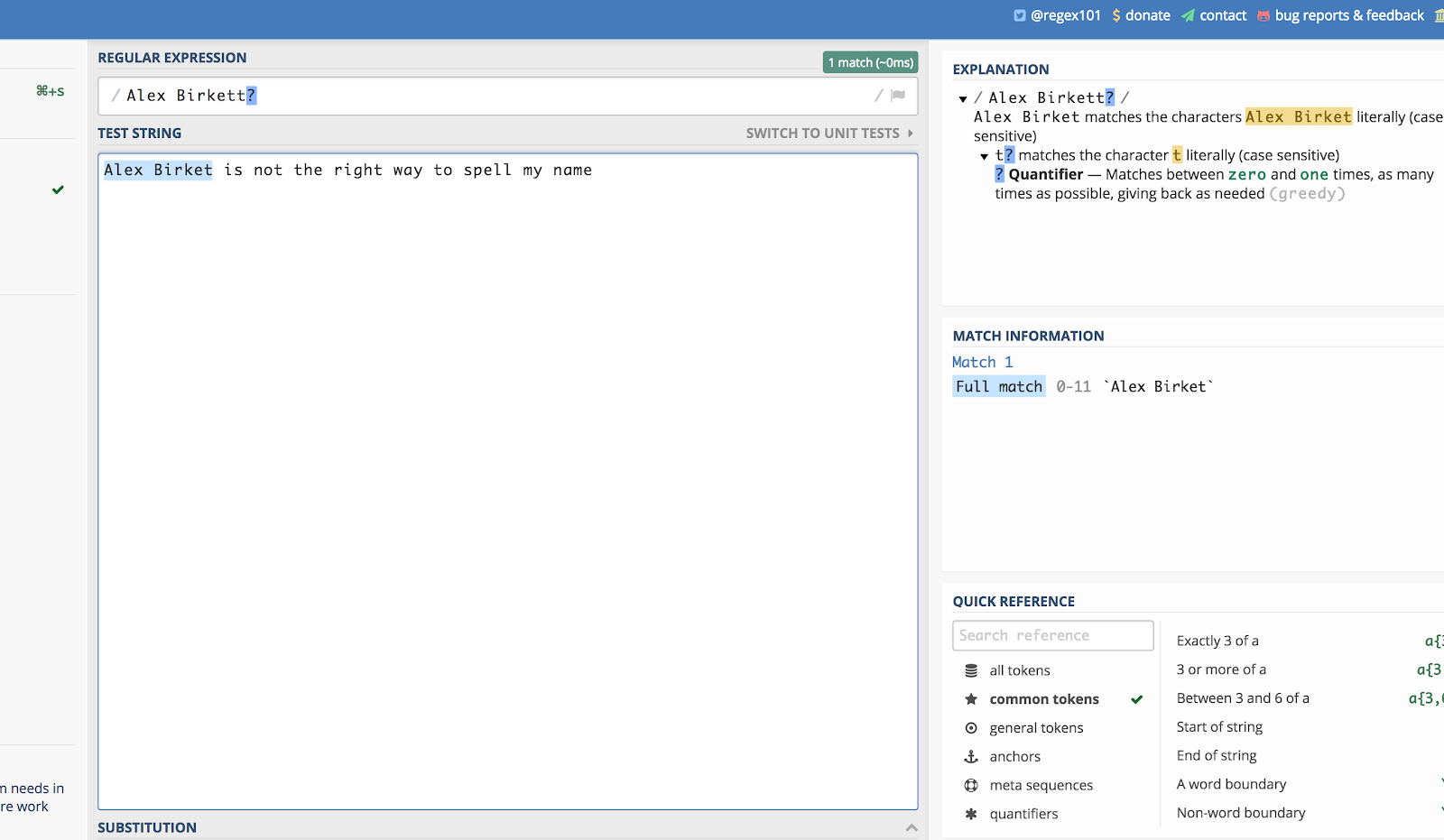
The question mark (?) makes it that the last character that precedes is optional.
括弧 ()
Parentheses operate the same way they do in mathematics.これは、数学の括弧と同じように機能します。
Let’s say you have a SaaS company with three offerings and you want to match all of your pricing pages.これは、3つの製品を提供する SaaS 企業があり、すべての価格ページを一致させたいとします。 URL は次のとおりです。
site.com/products/meetings/pricing
site.com/products/crm/pricing
site.com/products/crm/pricing
site.com/products/meetings/pricing
。com/products/email/pricing
これら 3 つすべてを検索するには、次のような正規表現を使用できます。
^/products/(meeting|crm|email)/pricing$
角カッコ ()
角カッコ ()はリストを作成します。 thing1」、「thing2」、「thing3」という 3 つの文字列がある場合、「thing」または「thing」と書くことで、それらすべてにマッチします (ダッシュについては後述します。ダッシュは角かっこと一緒によく使われます。
角かっこは単語や文字列のいくつかの繰り返しにマッチし、他のいくつかの繰り返しも除外するために使用されます)。 たとえば、”can”, “man” および “fan” にはマッチするが、”dan”, “ran” および “pan” にはマッチしない場合、次の正規表現を使用します。
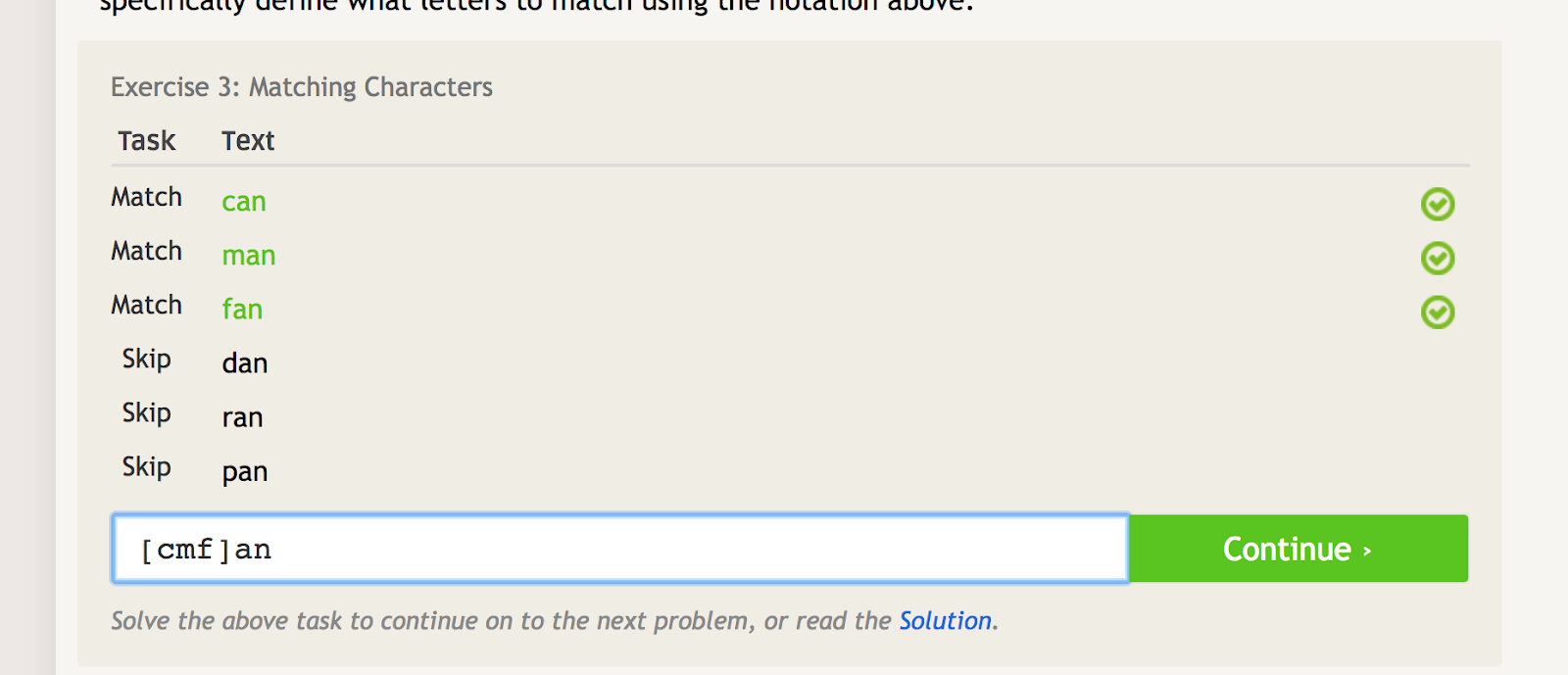
角括弧は、その中に入れる文字によって複数のマッチング条件を作成します。 – image source
これは、「靴1」「靴3」「靴5」のように、似た名前のいくつかの異なる製品がある場合に使用されるものです。 shoes”
ダッシュ (-)
ダッシュ (-) は項目の線形リストを作成するために働きます。
角括弧を使用しているとき、それが線形に発生するなら、すべてを単にリストする必要はない、というように。 つまり、最後の 1 つが 0 から 9 までの数字であるような文字列にマッチさせたい場合は、次のように書くことができます:
1234
あるいは、もっと単純に
1234
これは文字にも当てはまります。 例えば、末尾がランダムな2文字で構成されるページ・カテゴリがあるとします。 次のようなものです:
/page-aa/
これらのすべてにマッチするには:
/page-*/
regex101 でその例を見ることができます:
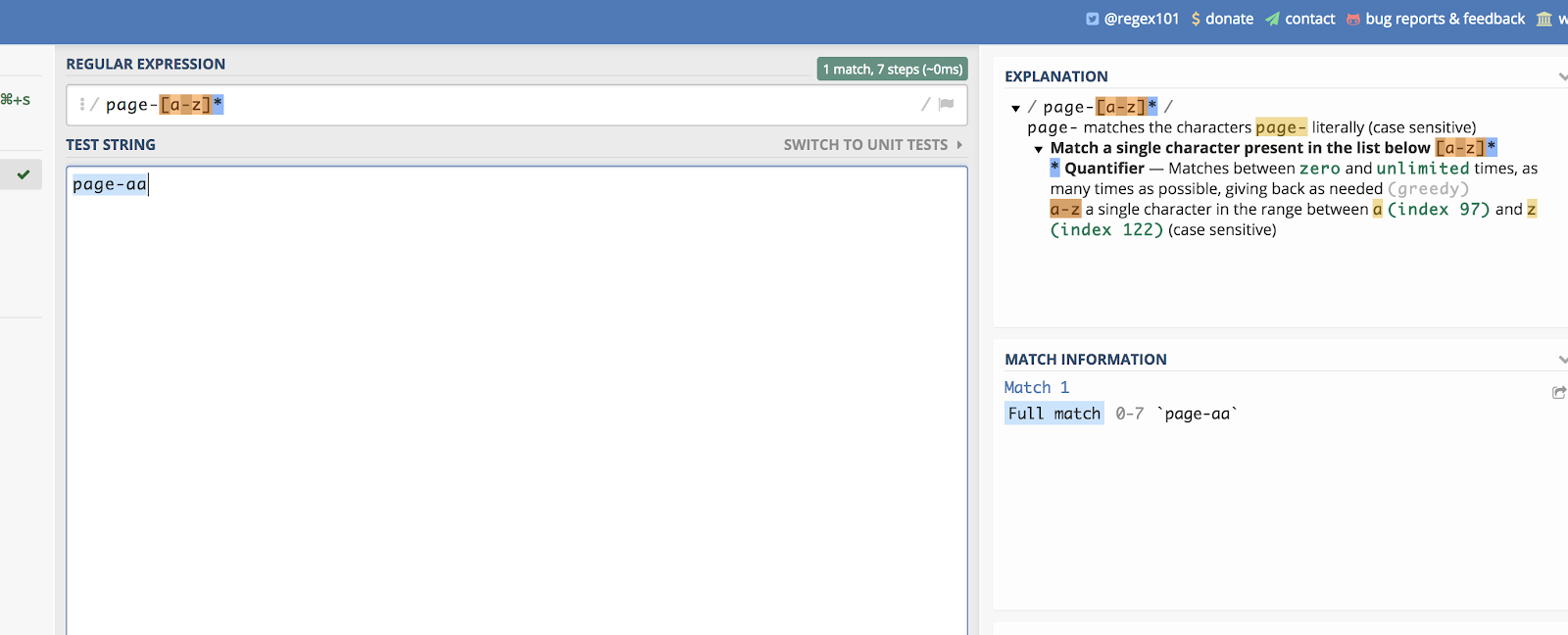
Dashes help you create a linear list to match.All the table to be matching by regex101(英語).
カーリーブラケット({ })
カーリーブラケット({})は、最後の項目を何回繰り返すかを指定します。
例えば、”wazzzzup” のみにマッチさせたい場合は、”waz{4}up” を使用します。
しかし、”wazzzup” と “wazzzup” にはマッチするが “wazup” にはマッチしない場合は “waz{3,5}up” を使用します。
カーリーブラケットは、最後の項目を何回繰り返すかを示しています
私はGoogle Analyticsでこの正規表現をあまり使ったことがありませんが、よく使うケースは郵便番号の場合かもしれませんね。 通常、都市の場合、最初の2文字は同じです(例えば、テキサス州オースチンの場合は78-)。 つまり、次のように書けば、Austin, TX の郵便番号にマッチします。
78{3}
これは、最後の 3 文字は 0 から 9 までの任意のランダムな数字にすることができます。
Google Analytics RegEx: Specific Examples You Can Use
Google Analytics regex で最もよく使用する例の 1 つはフィルターを構築することです。
Search Engine Land の Jenny Halasz 氏による素晴らしい投稿に触発された例です。
めちゃくちゃなサイト構造があるとして、特定のサブディレクトリを持つすべての投稿を見たいとします。 それは、サイトのカテゴリやコンテンツの種類など、何でもかまいません。 この例では、サイト内の /music/ のカテゴリで、3番目のサブディレクトリにあるものだけを探します。 この場合、^/.*/.*/music/.* と書くと、そのレポートが得られます。

This Google Analytics regex will show you only /music/ in the third subirectory.このGoogle Analytics正規表現は、第3サブディレクトリにある音楽だけを表示します。 – image source
一見するとわかりにくいですが、これらの正規表現の意味を理解すると、とてもわかりやすくなります。 基本的には、(^) で始まるスラッシュ、任意の文字 (.*)、スラッシュ、任意の文字 (.*)、スラッシュ、音楽の順にランディングページにマッチするように GA に指示しているだけです。
LawnStarter では、レポートに同様の戦術を採用しています。 彼らの戦略は、都市ページのサブフォルダに都市固有のコンテンツを作成し、次のフォーマットを使用します。
https://www.lawnstarter.com/{{取引用都市ページ}}/{{情報コンテンツ作品}}
コンバージョンファンネルとトラフィックレポートからコンテンツを除外するために、創設者のライアン・ファーリーによると、彼らは次の正規表現を使用しているとのことです。
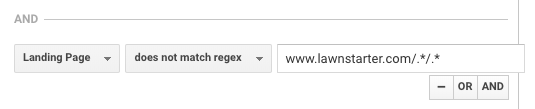
This regex helps LawnStarter match city specific content on their site.
次に、Google Analytics ビューにフィルターを設定する方法を説明します。 しかし、そうでない場合は、常にここで2回測定して1回切断してください。 フィルタを設定するには、管理画面 > フィルタ > フィルタの追加 に移動します。
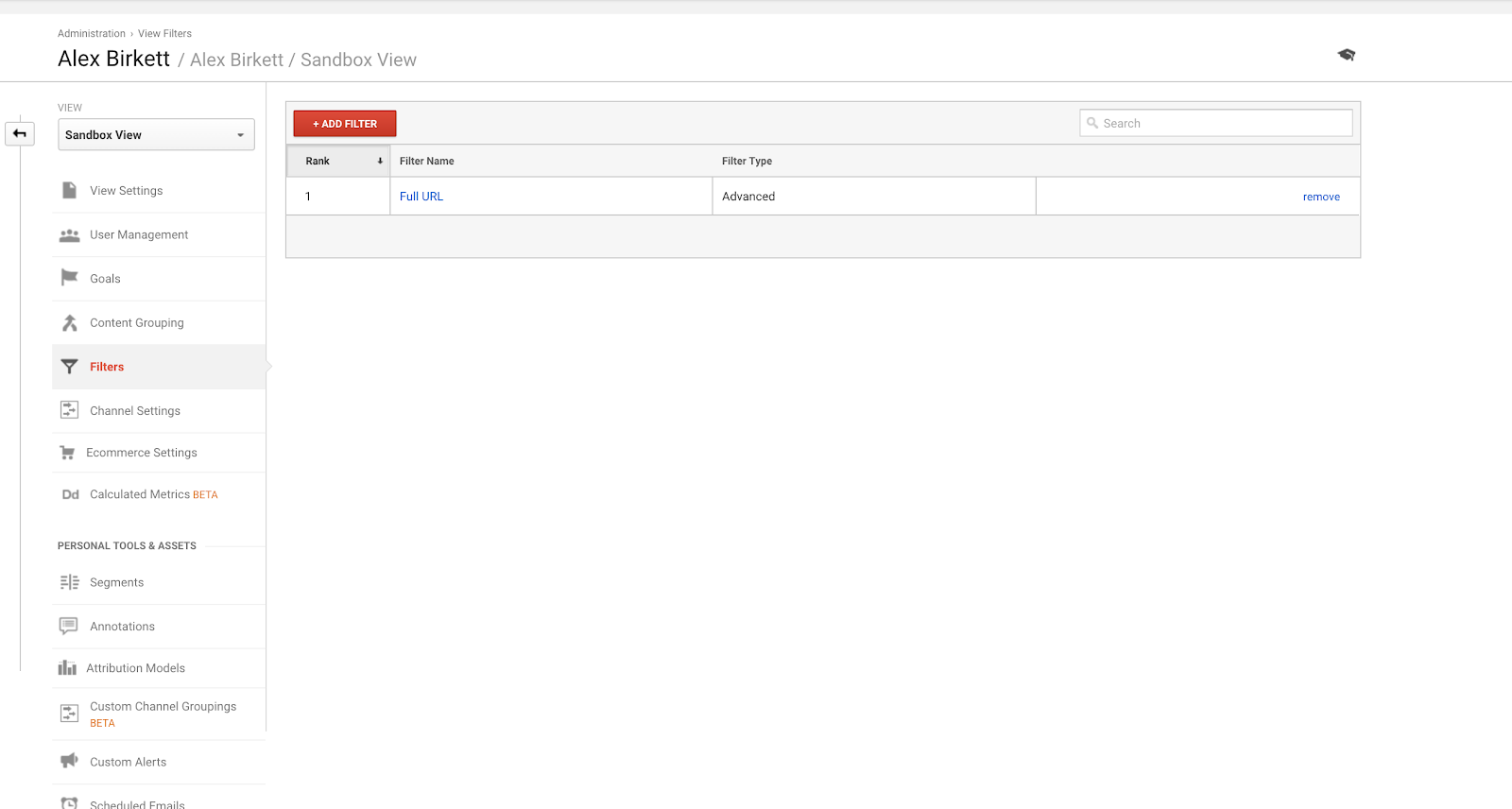
Google Analytics で最もよく使われるフィルタは、おそらく自分の IP アドレスからのトラフィックを除外することです。
多くの場合、IPは1つだけなので、簡単に設定できます。大きな会社では、一連のIPを持っていて、Google Analytics regexでより簡単に除外を設定できます。
たとえば、63.212.171.と書いた場合、63.212.171.1 から 63.212.171.9 まですべてのIPアドレスを除外できます。
This Google Analytics regex excludes several IP addresses.
Another thing you can do with Google Analytics regex is set up filters to clean up query parameters.
This can be both annoying and problematic for your data analysis.
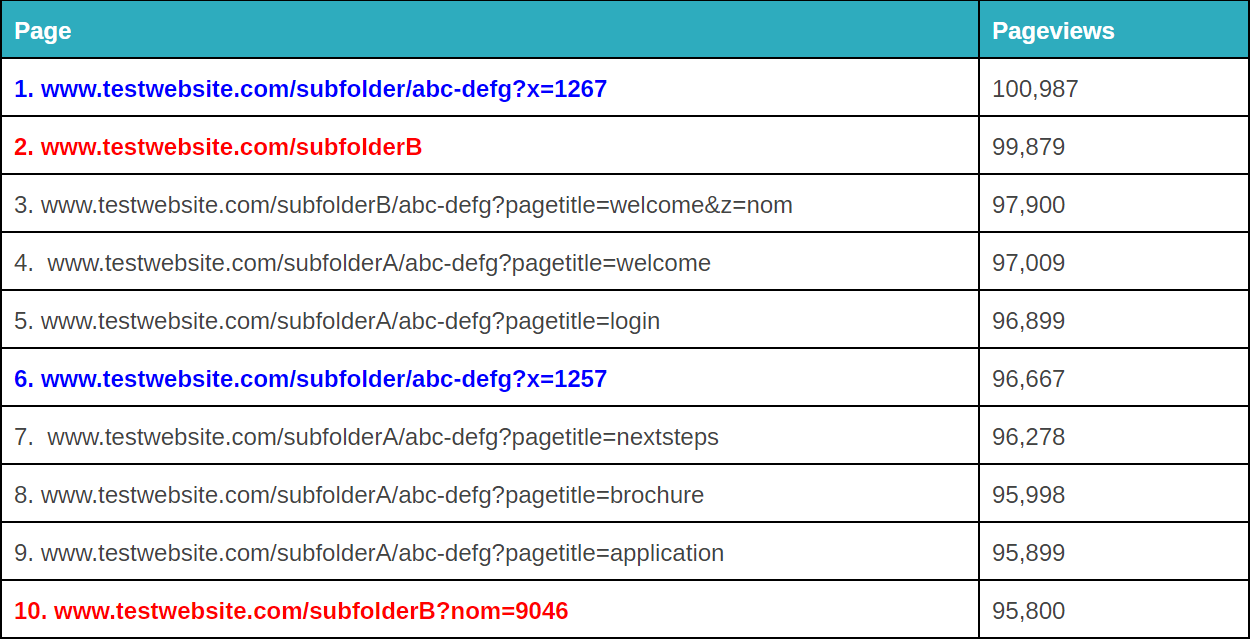
Fractured query parameters can be annoying.これは、クエリパラメータが破損すると、データ分析に問題が生じる可能性があります。 – image source
具体的な状況がどうであるかによりますが、正規表現を使用してそれをきれいにする方法がいくつかあります(注:問題の程度に応じて、Google タグ マネージャーまたは Excel でこれを行うこともできます)。 詳細はこちら)
最後に、サブドメインのトラッキングをよりよく整理するために使用できる1つの例についてお話しましょう。 複数のドメインまたはサブドメインを持っている場合、要求 URi の前にホスト名を付けるフィルタを設定しない限り、URLが重複する可能性があります。 言い換えると、次のような URL があるかもしれません。
- site.com/about
- blog.site.com/about
これらは 2 つの異なるページ(一方は会社に関するページ、他方はブログの About セクション)を表わします。 しかし、次のフィルタ(ドットアスタリスクの組み合わせGoogle Analytics正規表現を使用)を設定しない限り、Google Analyticsではどちらも/aboutとして表示されます:
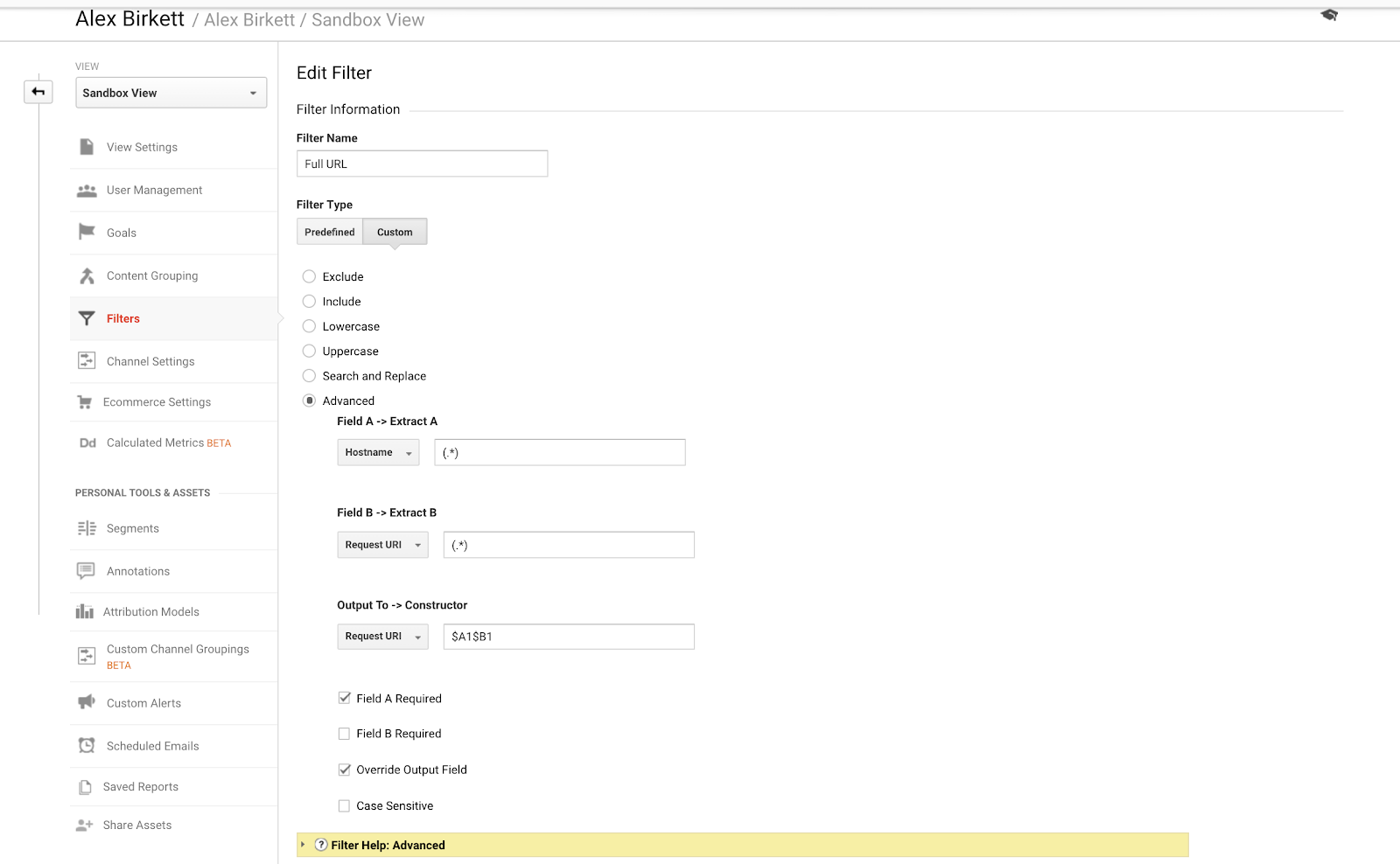
この基本的なGAフィルタを設定するのはかなり簡単です。 – 画像ソース
これらのフィルタの設定方法については、クロスドメインとサブドメインのトラッキングに関する KlientBoost の以前の記事でかなり詳しく説明しています。
Google Analytics RegEx Tips & Mistakes to Avoid
正規表現は練習して手を動かさないと習得できないものの 1 つです。 そのため、間違いを犯すことになります。
これは本当に最も重要なヒントです: 物事を試し、それが機能するかどうかを確認します。 この投稿では、regex101.com から regexbuddy.com まで、正規表現をテストする方法について大量のリソースをリストアップしました。 しかし、いくつかのフォアサイトとヒューリスティックがあれば、より早く学習し、より多くの間違いを発見できます。
本当に学ぶべきことの1つは、正規表現における「エスケープ」の方法です(バックスラッシュについてお話しました)。 CXL InstituteのCTOであるLeho Kraavはこのように言っています:
「適切にエスケープすることについて学ぶ」と言いたいですね。同じ文字であっても、エスケープするかどうかで意味が違ってくると、ミスマッチを起こしやすくなります」
たとえば、クエリーに疑問符がついていたらそれも正規表現なので、バックラッシュで明確にする必要があるのです。 MeasurementMarketing.io の創設者である Chris Mercer 氏も、この機能を学んでいないことが、初心者が犯す最大の間違いの 1 つであると述べています。
「初心者が正規表現を使う際に最もよく見られる間違いは、正規表現のシンボルを「エスケープ」し忘れていることです。 例えば、”thankyou/?success=yes “という正規表現にマッチするページを探している場合、それはうまくいきません。 この「?」自体が正規表現なので、「エスケープ文字」(「?」)を使って無効にする必要があるのです。 この場合、”thankyou/?success=yes “で動作します。」
もう一つのヒント? “シンプルに “だ。 人々は物事を複雑にしようとしますが(Leho氏が書いた「今まで見た中で最も複雑な正規表現」をご覧ください)、正規表現は「貪欲」なので、できる限りマッチングさせます。 Google Analytics はブログでヒントを発表し、次のように説明しています:
“If you need to write an expression to match “new visits”, and the only options that you will be matching against “new visits” and “repeat visits”, just the word “new” is good enough.
They will match everything they possibly, unless you force not to them not possible. 表現が “visits” であれば、”new visits” と “repeat visits” にマッチします。 結局のところ、両方とも “visits” という表現を含んでいるのです。 欲張らないようにするには、より具体的にする必要があります」
だから、ゆっくり始めて、シンプルに保ち、複雑さで自分を圧倒しないようにしましょう (この場合、エラーの可能性は複雑さと相関しています)
Mercer もこの点を繰り返し、物事を徐々に進めるようアドバイスしています。 正規表現が提供するさまざまな可能性に圧倒されがちですが、「または」を表す記号 (「 | 」) をマスターするなど、基本的なことから始めれば、すぐに経験を積み、正規表現で何が可能かを理解し始めることができます」
私からの最後のアドバイス:Google を学ぶこと。 これはどんなプログラミングにも当てはまりますが、特に正規表現に当てはまります。 毎日正規表現を書かないのであれば、すべてを記憶することに意味はないのです。 7536>
Outside of Google Analytics:
Google Analytics以外:Regexの他のマーケティング用途
RegexもすべてのSEO実践者が調べるべきことです。 まず、明らかに、SEO とデジタル分析 (Google Analytics など) は密接に絡み合っているからです。 第二に、Google Analytics のデータで文字をフィルタリングして一致させるために書く同じ一致式のいくつかは、SEO 戦術のデータ抽出でも使用できるからです。
言い換えれば、正規表現は Web スクレイピングでも重要です。
<strong>(+)</strong>
あるいは、この SEJ 記事で述べたように、すべての著者の ESPN をスクレイピングする場合、次のように書くことができます。
“コラムニスト”:”(.*?)”
整合性と正気のために、上級ウェブスクレイピングには深く立ち入るつもりはありませんが、このように書いています。 この分野でも正規表現が重要であることは十分承知しています。 3549>
- Web Scraping with Regular Expressions
- Scraping with Regular Expressions (Stanford)
- How to Use Regex for SEO & Website Data Extraction
正規表現も単に Web をこするだけではなく SEO データで作業するのに役に立ちます。 たとえば、正規表現を使用して、Screaming Frog の使用方法をさらにカスタマイズできます。
Jenny Halasz は Search Engine Land の投稿で、正規表現を使用してデータをクリーンアップする良い例を挙げています:
「たとえば、URL のリストがあって、それを TLD(トップレベルドメイン)だけに分割する必要があるとします。
http と www については単純な検索/置換を使用できますが、すべてのファイル名を簡単に削除するにはどうしたらよいでしょうか。 手動ですべて削除することも可能ですが、それは面倒です。 単純な正規表現のワイルドカード (/*) を使えば、スラッシュとその後に続くすべてを削除することができます。「SEO や Web スクレイピングのための正規表現については、永遠に語り続けることができますが、もっと学びたい方のために、いくつかの良いリソースにリンクしておきます(結局のところ、正規表現は非常に汎用性の高い言語で、分析以外にも多くの使用事例があります)。
- How Regular Expression Affects SEO
- 5 Powerful Awesome Htaccess Redirect Tricks
- How to Use Regular Expression for Report Segmentation
Conclusion
Google Analytics regex は技術者ならずとも知っておくべきものでしょう。 さらに、いくつかの正規表現を知っていると (少なくとも、答えを検索して適切な問題に適用する方法)、マーケティング担当者のさまざまな活動にも役立ちます。
ただ、あまり一般的なスキルセットではないので、新しく見つけた技術的マーケティング スキルで一部の同僚に感銘を与えることができるでしょう。 それほど怖いものではありません。