Door Altexsoft.
Klantbehoud is een van de primaire groeipijlers voor producten met een op abonnementen gebaseerd bedrijfsmodel. De concurrentie is hevig in de SaaS-markt, waar klanten zelfs binnen één productcategorie de keuze hebben uit een groot aantal aanbieders. Meerdere slechte ervaringen – of zelfs één – en een klant kan afhaken. En als drommen ontevreden klanten in een snel tempo afhaken, zouden zowel de materiële verliezen als de reputatieschade enorm zijn.
Voor dit artikel hebben we de hulp ingeroepen van experts van HubSpot en ScienceSoft om te bespreken hoe SaaS-bedrijven omgaan met het probleem van klantenchurn met behulp van voorspellende modellering. U zult benaderingen en best practices ontdekken voor het oplossen van dit probleem. We bespreken het verzamelen van gegevens over de klantrelatie met een merk, kenmerken van klantgedrag die het meest correleren met churn en onderzoeken de logica achter het selecteren van de best presterende machine learning-modellen.
- Wat is customer churn?
- Impact van klantenchurn op bedrijven
- Use cases voor klantchurnvoorspelling
- Identificeren van risicoklanten met machine learning: probleemoplossing in één oogopslag
- Predicting customer churn with machine learning
- Begrijpen van een probleem en een einddoel
- Gegevensverzameling
- Gegevensvoorbereiding en voorbewerking
- Modelleren en testen
- Deployment en monitoring
- Conclusie
Wat is customer churn?
Customer churn (of klantonttrekkingsgedrag) is de neiging van klanten om een merk in de steek te laten en geen betalende klant meer te zijn van een bepaald bedrijf. Het percentage klanten dat gedurende een bepaalde periode niet langer gebruik maakt van de producten of diensten van een bedrijf, wordt de “customer churn (attrition) rate” genoemd. Een van de manieren om een churn rate te berekenen is het aantal klanten dat gedurende een bepaalde tijdsperiode verloren gaat te delen door het aantal verworven klanten, en dat getal vervolgens te vermenigvuldigen met 100 procent. Bijvoorbeeld, als je 150 klanten hebt gekregen en er vorige maand drie hebt verloren, dan is je maandelijkse churn rate 2 procent.
Churn rate is een gezondheidsindicator voor bedrijven waarvan de klanten abonnees zijn en betalen voor diensten op een terugkerende basis, merkt hoofd van de afdeling data analytics bij ScienceSoft Alex Bekker op, “Klanten kiezen voor een product of een dienst voor een bepaalde periode, die vrij kort kan zijn – zeg, een maand. Zo blijft een klant openstaan voor interessantere of voordeligere aanbiedingen. Bovendien hebben klanten elke keer dat hun huidige verbintenis afloopt, de kans om zich te bedenken en ervoor te kiezen niet verder te gaan met het bedrijf. Natuurlijk is een zekere mate van natuurlijke churn onvermijdelijk, en het cijfer verschilt van branche tot branche. Maar een hoger opzeggingscijfer is een duidelijk teken dat een bedrijf iets verkeerd doet.”
Er zijn veel dingen die merken verkeerd kunnen doen, van ingewikkelde onboarding waarbij klanten geen begrijpelijke informatie krijgen over het gebruik en de mogelijkheden van het product tot slechte communicatie, bijvoorbeeld het gebrek aan feedback of vertraagde antwoorden op vragen. Een andere situatie: Langdurige klanten kunnen zich niet gewaardeerd voelen omdat ze niet zoveel bonussen krijgen als de nieuwe.
In het algemeen is het de algehele klantervaring die de merkperceptie bepaalt en beïnvloedt hoe klanten de prijs-kwaliteitverhouding herkennen van producten of diensten die ze gebruiken.
De realiteit is dat zelfs loyale klanten een merk niet zullen tolereren als ze er een of meerdere problemen mee hebben gehad. Zo merkte 59 procent van de Amerikaanse respondenten in het onderzoek van PricewaterhouseCoopers (PwC) op dat zij een merk vaarwel zullen zeggen na meerdere slechte ervaringen, en 17 procent van hen na slechts één slechte ervaring.
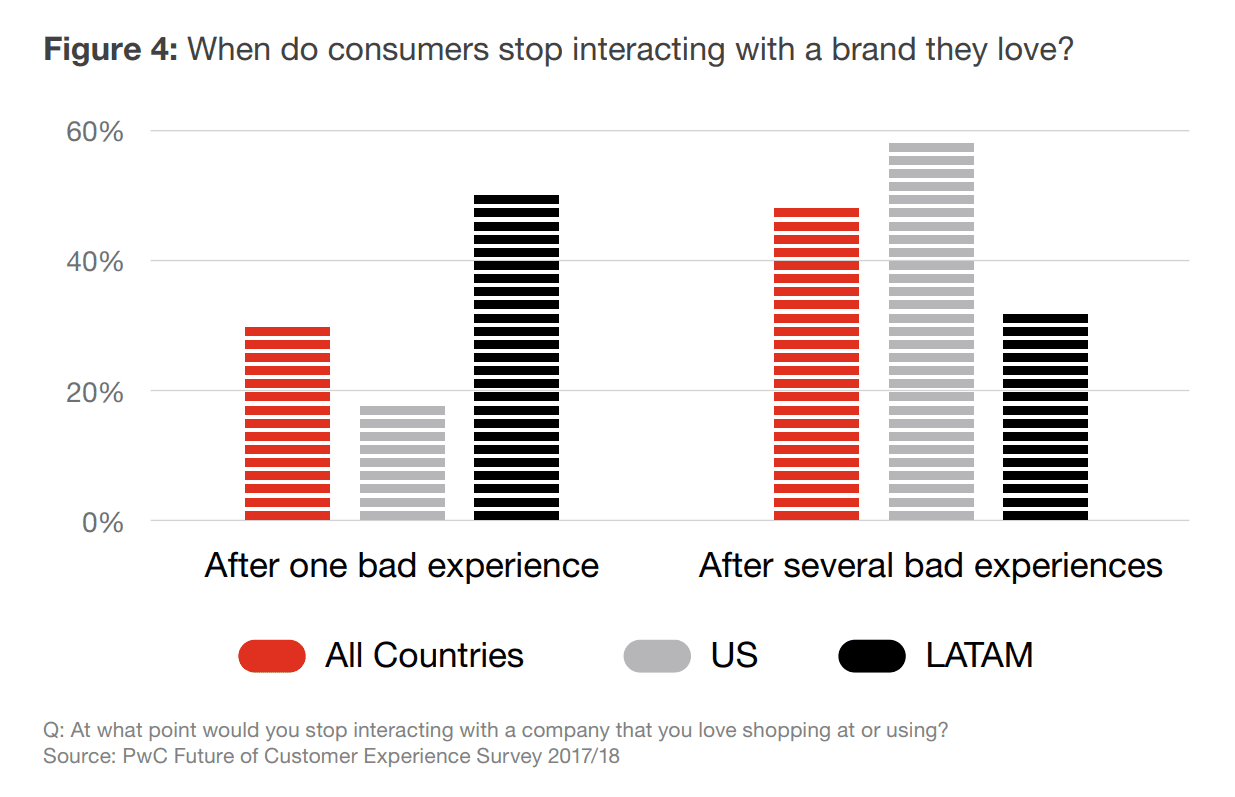
Slechte ervaringen kunnen zelfs loyale klanten van zich vervreemden. Bron: PwC
Impact van klantenchurn op bedrijven
Well, churn is slecht. Maar hoe beïnvloedt het precies de bedrijfsprestaties op de lange termijn?
Onderschat de impact van zelfs een heel klein percentage churn niet, zegt Michael Redbord, general manager van Service Hub bij HubSpot. “In een op abonnementen gebaseerde business, zal zelfs een klein percentage maandelijkse/kwartaalelijkse churn snel oplopen in de tijd. Slechts 1 procent maandelijkse churn vertaalt zich naar bijna 12 procent jaarlijkse churn. Aangezien het veel duurder is om een nieuwe klant te werven dan om een bestaande klant te behouden, zullen bedrijven met hoge opzeggingspercentages zich snel in een financieel gat bevinden omdat ze steeds meer middelen moeten besteden aan het werven van nieuwe klanten.”
Veel onderzoeken die zich richten op de kosten van het werven en behouden van klanten zijn online beschikbaar. Volgens dit onderzoek van Invesp, een bedrijf dat conversieratio’s optimaliseert, kan het verkrijgen van een nieuwe klant tot vijf keer meer kosten dan het behouden van een bestaande klant.
Churn rates correleren inderdaad met verloren inkomsten en hogere acquisitie-uitgaven. Daarnaast spelen ze een meer genuanceerde rol in het groeipotentieel van een bedrijf, vervolgt Michael: “Hedendaagse kopers zijn niet verlegen om hun ervaringen met verkopers te delen via kanalen zoals beoordelingssites en sociale media, evenals peer-to-peer netwerken. Uit HubSpot Research blijkt dat 49 procent van de kopers aangeeft een ervaring die ze met een bedrijf hebben gehad te delen via sociale media. In een wereld waarin het vertrouwen in bedrijven afbrokkelt, speelt mond-tot-mondreclame een belangrijkere rol in het koopproces dan ooit tevoren. Uit hetzelfde onderzoek van HubSpot Research blijkt dat 55 procent van de kopers de bedrijven waar ze kopen niet meer zo vertrouwt als vroeger, 65 procent vertrouwt persberichten van bedrijven niet, 69 procent vertrouwt advertenties niet en 71 procent vertrouwt gesponsorde advertenties op sociale netwerken niet.”

Een blik op de staat van het vertrouwen van klanten in bedrijven. Bron: HubSpot Research Trust Survey
De expert concludeert dat bedrijven met hoge churn rates niet alleen tekortschieten in hun relaties met ex-klanten, maar ook hun toekomstige acquisitie-inspanningen schaden door negatieve mond-tot-mondreclame rond hun producten te creëren.
CallMiner, leverancier van conversational analytics-oplossingen, ondervroeg 1000 volwassenen om te leren waarom en hoe ze met bedrijven omgaan. Uit het onderzoek bleek dat Amerikaanse bedrijven ongeveer 136 miljard dollar per jaar verliezen als gevolg van klantverloop. Wat meer is, het gedrag van het bedrijf dat ervoor zorgde dat klanten de banden met merken verbraken, had kunnen worden gecorrigeerd.
Use cases voor klantchurnvoorspelling
Zoals we al eerder zeiden, is churn rate een van de kritieke prestatie-indicatoren voor abonnementsbedrijven. Het abonnementsmodel – in de 17e eeuw geïntroduceerd door Engelse uitgevers van boeken – is erg populair onder moderne dienstverleners. Laten we eens een snelle blik werpen op deze bedrijven:
Muziek- en videostreamingdiensten worden waarschijnlijk het meest geassocieerd met het abonnementsbedrijfsmodel (Netflix, YouTube, Apple Music, Google Play, Spotify, Hulu, Amazon Video, Deezer, enz.).
Media. Digitale aanwezigheid is een must voor de pers, dus bieden nieuwsbedrijven hun lezers digitale abonnementen aan naast de gedrukte abonnementen (Bloomberg, The Guardian, Financial Times, The New York Times, Medium, enz.).
Telecombedrijven (kabel of draadloos). Deze bedrijven kunnen een volledig assortiment producten en diensten aanbieden, waaronder draadloze netwerken, internet, TV, mobiele telefonie en huistelefoondiensten (AT&T, Sprint, Verizon, Cox Communications, enz.). Sommige zijn gespecialiseerd in mobiele telecommunicatie (China Mobile, Vodafone, T-Mobile, enz.).
Software as a service providers. De toepassing van in de cloud gehoste software neemt toe. Volgens Gartner blijft de SaaS-markt het grootste segment van de cloud-markt. De omzet ervan zal naar verwachting met 17,8 procent groeien en in 2019 85,1 miljard dollar bedragen. Het productaanbod van SaaS-aanbieders is uitgebreid: grafische en videobewerking (Adobe Creative Cloud, Canva), boekhouding (Sage 50cloud, FreshBooks), e-commerce (BigCommerce, Shopify), e-mailmarketing (MailChimp, Zoho Campaigns), en vele anderen.
Deze bedrijfstypen kunnen churn rate gebruiken om de effectiviteit van afdelingsoverstijgende operaties en productbeheer te meten.
Identificeren van risicoklanten met machine learning: probleemoplossing in één oogopslag
Bedrijven die voortdurend in de gaten houden hoe mensen zich bezighouden met producten, klanten aanmoedigen om meningen te delen en hun problemen snel oplossen, hebben grotere kansen om wederzijds voordelige klantrelaties te onderhouden.
En stel je nu een bedrijf voor dat al een tijdje klantgegevens verzamelt, zodat het deze kan gebruiken om gedragspatronen van potentiële churners te identificeren, deze risicoklanten te segmenteren en passende acties te ondernemen om hun vertrouwen terug te winnen. Degenen die een proactieve benadering van het beheer van klantenchurn volgen, maken gebruik van voorspellende analyses. Dat is een van de vier soorten analytics waarbij de waarschijnlijkheid van toekomstige uitkomsten, gebeurtenissen of waarden wordt voorspeld door analyse van huidige en historische gegevens. Voorspellende analyses maken gebruik van verschillende statistische technieken, zoals data mining (patroonherkenning) en machine learning (ML).
“De enige zwakte van het bijhouden van alleen echte churn is dat het slechts dient als een achterblijvende indicator van slechte klantervaring, dat is waar een voorspellend churn-model uiterst waardevol wordt,” merkt Michael Redbord van HubSpot op.
De belangrijkste eigenschap van machine learning is het bouwen van systemen die in staat zijn om patronen in gegevens te vinden, ervan te leren zonder expliciete programmering. In de context van klantchurnvoorspelling zijn dit online gedragskenmerken die wijzen op afnemende klanttevredenheid van het gebruik van diensten/producten van het bedrijf.
Het opsporen van klanten die het risico lopen op churn helpt om vooraf maatregelen te nemen
ScienceSoft’s Alex Bekker benadrukt ook het belang van machine learning voor proactief churnmanagement: “Wat betreft het identificeren van potentiële churners, kunnen machine learning-algoritmes hier uitstekend werk verrichten. Ze onthullen enkele gedeelde gedragspatronen van de klanten die het bedrijf al hebben verlaten. Vervolgens toetsen ML-algoritmen het gedrag van de huidige klanten aan dergelijke patronen en signaleren of ze potentiële churners ontdekken.”
Op abonnementen gebaseerde bedrijven maken gebruik van ML voor voorspellende analyses om erachter te komen welke huidige gebruikers niet volledig tevreden zijn met hun diensten en pakken hun problemen aan als het nog niet te laat is: “Het identificeren van klanten die het risico lopen op churn zo veel als 11 maanden voor hun verlenging stelt ons klantsucces team in staat om deze klanten te betrekken, hun pijnpunten te begrijpen, en met hen een langetermijnplan samen te stellen dat is gericht op het helpen van de klant om waarde te realiseren van de service die ze hebben gekocht, “legt Michael uit.
Use cases voor voorspellende churn-modellering gaan verder dan proactieve betrokkenheid bij prospectieve churn-klanten en het selecteren van effectieve retentieacties. Volgens Redbord stelt ML-gebaseerde software customer success managers in staat om te definiëren met welke klanten ze contact moeten opnemen. Met andere woorden, medewerkers kunnen er zeker van zijn dat ze op het juiste moment met de juiste klanten spreken.
Sales-, klantsucces- en marketingteams kunnen de kennis uit de data-analyse ook gebruiken om hun acties op elkaar af te stemmen. “Als een klant bijvoorbeeld tekenen vertoont dat hij dreigt af te haken, is dat waarschijnlijk niet het juiste moment voor sales om hem te benaderen met informatie over aanvullende diensten waarin de klant geïnteresseerd zou kunnen zijn. De CSM kan de klant helpen opnieuw betrokken te raken en de waarde in te zien van de producten die hij nu heeft. Net als verkoop, kan marketing zich op verschillende manieren met klanten bezighouden, afhankelijk van hun huidige indicatie van het risico op churn: Klanten zonder churn-risico zijn bijvoorbeeld betere kandidaten om deel te nemen aan een case study dan een klant die op dit moment een churn-risico is,” legt de expert van HubSpot uit. In het algemeen moet de strategie van klantinteractie gebaseerd zijn op ethiek en gevoel voor timing. En het gebruik van machine learning voor de analyse van klantgegevens kan inzichten opleveren om deze strategie kracht bij te zetten.
Predicting customer churn with machine learning
Maar hoe ga je aan de slag met het voorspellen van churn rates? Welke gegevens zijn nodig? En wat zijn de stappen voor de implementatie?
Zoals bij elke machine learning taak, hebben data science specialisten eerst gegevens nodig om mee te werken. Afhankelijk van het doel bepalen onderzoekers welke gegevens ze moeten verzamelen. Vervolgens worden de geselecteerde gegevens voorbereid, voorbewerkt en getransformeerd in een vorm die geschikt is voor het bouwen van modellen voor machinaal leren. Het vinden van de juiste methoden om machines te trainen, het verfijnen van de modellen en het selecteren van de best presterende modellen is een ander belangrijk onderdeel van het werk. Zodra een model is gekozen dat voorspellingen doet met de hoogste nauwkeurigheid, kan het in productie worden genomen.
De totale omvang van het werk dat data scientists uitvoeren om ML-aangedreven systemen te bouwen die in staat zijn om klantverloop te voorspellen, kan er als volgt uitzien:
- Begrip van een probleem en einddoel
- Gegevensverzameling
- Gegevensvoorbereiding en voorbewerking
- Modellering en testen
- Modelimplementatie en monitoring
Als u wilt leren wat er tijdens deze stappen gebeurt, leest u ons artikel over de machine learning-projectstructuur. Laten we nu uitzoeken hoe elk van deze fasen in de context van churn-voorspelling kan worden voltooid.
Begrijpen van een probleem en een einddoel
Het is belangrijk om te begrijpen welke inzichten men uit de analyse moet halen. Kortom, u moet beslissen welke vraag u wilt stellen en bijgevolg welk type machine-learningprobleem u wilt oplossen: classificatie of regressie. Klinkt ingewikkeld, maar denk even met ons mee.
Classificatie. Het doel van classificatie is om te bepalen tot welke klasse of categorie een datapunt (klant in ons geval) behoort. Voor classificatieproblemen gebruiken datawetenschappers historische gegevens met vooraf gedefinieerde doelvariabelen AKA labels (churner/non-churner) – antwoorden die moeten worden voorspeld – om een algoritme te trainen. Met classificatie kunnen bedrijven de volgende vragen beantwoorden:
- Zal deze klant churnen of niet?
- Zal een klant zijn abonnement verlengen?
- Zal een gebruiker een prijsplan downgraden?
- Zijn er tekenen van ongebruikelijk klantgedrag?
De vierde vraag over tekenen van atypisch gedrag vertegenwoordigt een type classificatieprobleem dat anomaliedetectie wordt genoemd. Anomalie detectie gaat over het identificeren van outliers – datapunten die significant afwijken van de rest van de gegevens.
Regressie. De voorspelling van klantenchurn kan ook worden geformuleerd als een regressietaak. Regressieanalyse is een statistische techniek om de relatie te schatten tussen een doelvariabele en andere gegevenswaarden die de doelvariabele beïnvloeden, uitgedrukt in continue waarden. Als dat te moeilijk is – het resultaat van regressie is altijd een getal, terwijl classificatie altijd een categorie voorstelt. Bovendien kan met regressieanalyse worden geschat hoeveel verschillende variabelen in de gegevens een doelvariabele beïnvloeden. Met regressie kunnen bedrijven voorspellen in welke periode een bepaalde klant waarschijnlijk zal afhaken of een schatting krijgen van de waarschijnlijkheid van afhaken per klant.
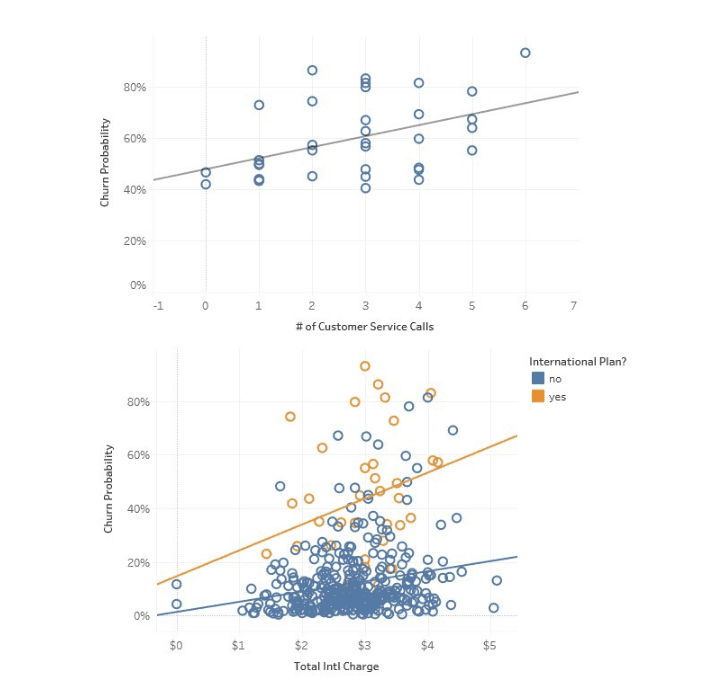
Dit is het voorbeeld van logistische regressie die door Towards Data Science wordt gebruikt om de kans op churn in de telecomsector te voorspellen. Hier laat de visualisatie zien hoe het aantal service calls en het gebruik van internationale plannen correleren met churn
Gegevensverzameling
Identificeren van gegevensbronnen. Zodra u hebt vastgesteld naar welk soort inzichten u op zoek bent, kunt u beslissen welke gegevensbronnen nodig zijn voor verdere voorspellende modellering. Laten we uitgaan van de meest voorkomende gegevensbronnen die u kunt gebruiken voor het voorspellen van churn:
- CRM-systemen (inclusief verkoop- en klantenondersteuningsrecords)
- Analytische diensten (bijv, Google Analytics, AWStats, CrazyEgg)
- Feedback op sociale media en recensieplatforms
- Feedback die op verzoek voor uw organisatie wordt verstrekt, enz.
Uiteraard kan de lijst langer of korter zijn, afhankelijk van de branche.
Gegevensvoorbereiding en voorbewerking
Historische gegevens die zijn geselecteerd voor het oplossen van het probleem, moeten worden omgezet in een formaat dat geschikt is voor machinaal leren. Aangezien de prestaties van het model en dus de kwaliteit van de verkregen inzichten afhangen van de kwaliteit van de gegevens, moet er in de eerste plaats voor worden gezorgd dat alle datapunten volgens dezelfde logica worden gepresenteerd en dat de totale dataset vrij is van inconsistenties. Eerder schreven we een artikel over basistechnieken voor datasetvoorbereiding, dus voel je vrij om dat te bekijken als je meer wilt weten over het onderwerp.
Feature engineering, extractie, en selectie. Feature engineering is een zeer belangrijk onderdeel van datasetvoorbereiding. Tijdens dit proces creëren datawetenschappers een set attributen (input features) die verschillende gedragspatronen vertegenwoordigen met betrekking tot de mate van betrokkenheid van klanten bij een dienst of product. In brede zin zijn features meetbare kenmerken van waarnemingen waarmee een ML-model rekening houdt om uitkomsten te voorspellen (in ons geval heeft de beslissing betrekking op de churn-kans.)
Hoewel gedragskenmerken specifiek zijn voor elke branche, zijn benaderingen voor het identificeren van risicoklanten universeel, merkt Alex op: “Een bedrijf zoekt naar specifieke gedragspatronen die potentiële churners onthullen.”
Digitale marketeer en ondernemer Neil Patel classificeert features in vier groepen. Klantendemografie en ondersteuningsfuncties werken voor elke branche. Gebruikersgedrag en contextuele kenmerken, op hun beurt, zijn typisch voor het SaaS-businessmodel:
- klantdemografische kenmerken die basisinformatie over een klant bevatten (bijv. leeftijd, opleidingsniveau, locatie, inkomen)
- kenmerken van gebruikersgedrag die beschrijven hoe een persoon een dienst of product gebruikt (bijv, levenscyclusfase, aantal keren dat zij inloggen op hun account, actieve sessielengte, tijdstip van de dag waarop een product actief wordt gebruikt, gebruikte functies of modules, acties, geldwaarde)
- ondersteuningskenmerken die de interacties met de klantenservice karakteriseren (bijv, verzonden vragen, aantal interacties, geschiedenis van klanttevredenheidsscores)
- contextuele kenmerken die andere contextuele informatie over een klant weergeven.
HubSpot-specialisten proberen te begrijpen “wat een succesvolle klant maakt” door gebruik te maken van statistieken zoals websitebezoekers, gegenereerde leads en gemaakte deals. General manager van Service Hub Michael Redbord zegt: “We houden niet alleen gebruiksgegevens bij (bijvoorbeeld het publiceren van een blogbericht, het bewerken van de verwachte gesloten waarde van een deal of het verzenden van een e-mail), maar ook uitkomstgegevens (bijvoorbeeld het aantal klikken op een e-mail, het aantal views op een blogbericht, de dollarwaarde van gesloten deals gedurende een kwartaal). Het is belangrijk om niet alleen te begrijpen hoe uw klanten uw product gebruiken, maar ook welke resultaten ze zien. Als klanten geen waarde uit het product halen, zien we meestal een toename van de kans op churn.”
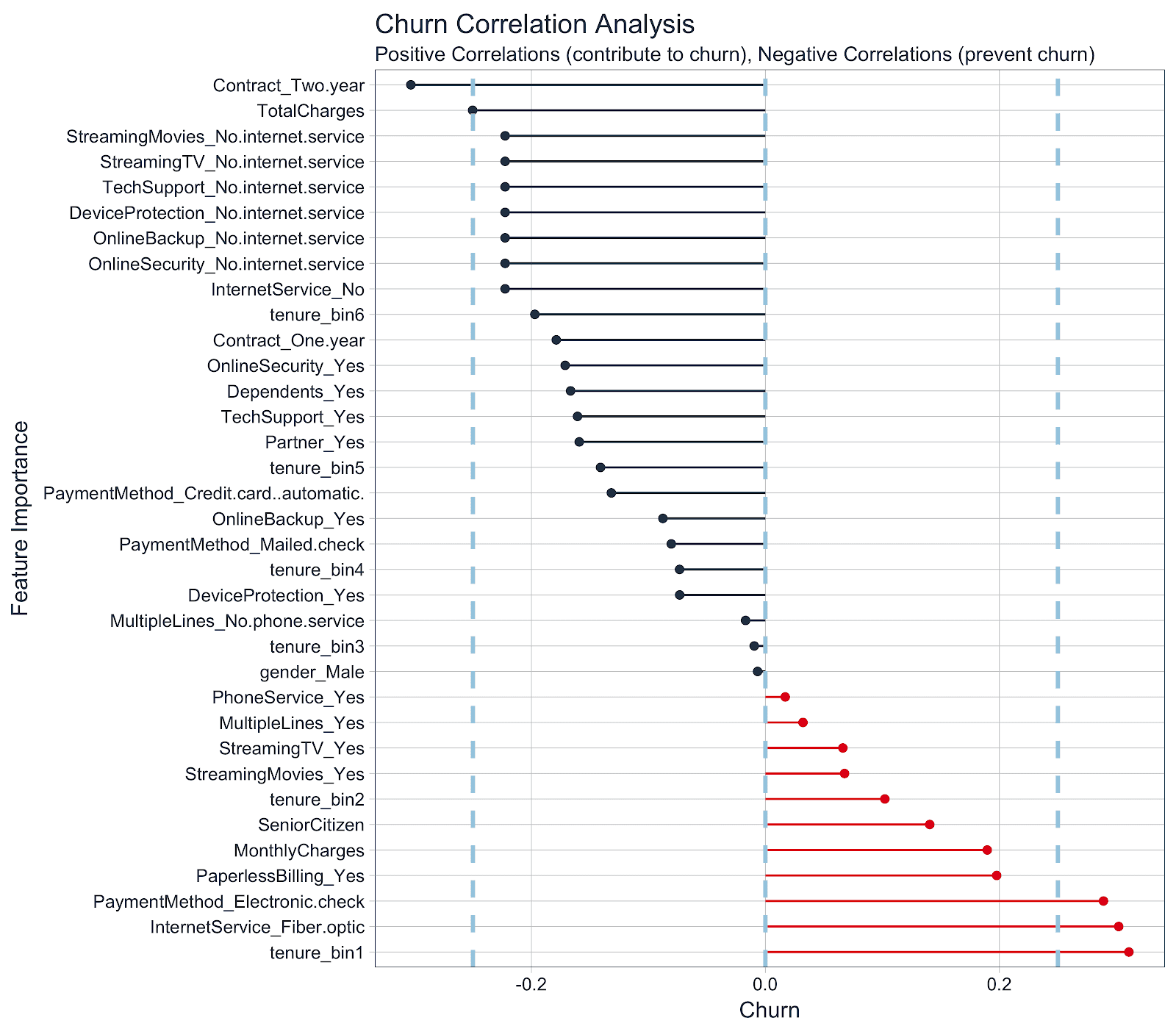
Hoe verschillend gebruikersgedrag, abonnements- en demografische kenmerken correleren met churn in internetservices door Matt Dancho voor RStudio blog
Maar te veel gegevens hebben is niet altijd goed.
Feature-extractie is gericht op het verminderen van het aantal variabelen (attributen) door diegene over te houden die de meest discriminerende informatie vertegenwoordigen. Feature-extractie helpt de datadimensionaliteit te verminderen (dimensies zijn kolommen met attributen in een dataset) en irrelevante informatie uit te sluiten.
Tijdens feature-selectie herzien specialisten eerder geëxtraheerde features en definiëren ze een subgroep daarvan die het meest gecorreleerd is met klantenchurn. Als gevolg van de selectie van kenmerken, hebben specialisten een dataset met alleen relevante kenmerken.
Methodes. Hoofd van ScienceSoft data analytics afdeling Alex Bekker merkt op dat methoden als permutation importance, ELI5 Python pakket, en SHAP (SHapley Additive exPlanations) kunnen worden gebruikt om de meest relevante en bruikbare features te bepalen.
Het principe van het werk van alle methoden ligt in het uitleggen hoe modellen hun voorspellingen doen (op basis van welke features een model een bepaalde conclusie heeft getrokken). Interpretabiliteit van modellen is een van de problemen met een hoge prioriteit in het veld, en data wetenschappers blijven oplossingen ontwikkelen om het op te lossen. U kunt meer lezen over interpreteerbaarheid in ons artikel over AI en data science vooruitgang en trends.
Permutatie belang is een van de manieren om feature belang te definiëren – een impact die een feature maakt op de voorspellingen. Het wordt berekend op modellen die al zijn getraind. Dit is hoe permutation importance wordt gedaan: Een data scientist verandert de volgorde van datapunten in een enkele kolom, voedt het model met de resulterende dataset, en bepaalt in welke mate die verandering de nauwkeurigheid ervan vermindert. Functies die de grootste invloed hebben op de resultaten zijn het belangrijkst.
Een andere manier om permutatie-belang te doen is om een kenmerk uit een dataset te verwijderen en het model opnieuw te trainen.
Permutatie-belang kan worden gedaan met ELI5 – een open-source Python-bibliotheek die het mogelijk maakt om ML-classifiers (algoritmen) te visualiseren, te debuggen, en hun outputs te interpreteren.
Volgens de ELI5-documentatie werkt deze methode het beste op datasets die geen groot aantal kolommen (features) bevatten.
Met behulp van het SHAP-framework (SHapley Additive exPlanations) kunnen specialisten beslissingen van “elk machine learning-model” interpreteren. SHAP kent ook aan elk kenmerk een belangrijkheidswaarde toe voor een bepaalde voorspelling.
Klantensegmentatie. Groeiende bedrijven en bedrijven die hun productassortiment uitbreiden, segmenteren hun klanten gewoonlijk aan de hand van vooraf gedefinieerde en geselecteerde kenmerken. Klanten kunnen worden onderverdeeld in subgroepen op basis van hun levenscyclusfase, behoeften, gebruikte oplossingen, mate van betrokkenheid, monetaire waarde, of basisinformatie. Aangezien elke klantcategorie gemeenschappelijke gedragspatronen deelt, is het mogelijk om de nauwkeurigheid van voorspellingen te verhogen door het gebruik van ML-modellen die specifiek zijn getraind op datasets die elk segment vertegenwoordigen.
Hubspot gebruikt bijvoorbeeld dergelijke segmentatiecriteria als klantpersona, levenscyclusfase, producten in eigendom, regio, taal en totale inkomsten van de account. “Combinaties van segmenten zoals deze zijn hoe we eigendom van accounts opdelen en het boek van een CSM of verkoper definiëren”, zegt Michael.
Wapend met kennis over de waarde van de klant, kunnen medewerkers bovendien hun retentieactiviteiten prioriteren.
Na de voorbereiding van de gegevens, de selectie van kenmerken en de klantsegmentatiefasen, komt het moment om te definiëren hoe lang het zal duren om het gedrag van de gebruiker te volgen voordat er voorspellingen worden gedaan.
Selecteren van een observatievenster (geschiedenis van klantgebeurtenissen). Bij voorspellend modelleren gaat het om het leren van de relatie tussen waarnemingen gedurende een periode (venster) die eindigt vóór een bepaald tijdstip en voorspellingen over een periode die na datzelfde tijdstip begint. De eerste periode wordt aangeduid als observatie, onafhankelijk, verklarend venster, of klantgebeurtenisgeschiedenis (laten we voor de duidelijkheid de laatste definitie gebruiken). De tweede periode, die volgt op een observatieperiode, wordt een prestatie-, afhankelijk of responsvenster genoemd. Met andere woorden, we voorspellen gebeurtenissen (een gebruiker churns of blijft) in een prestatievenster, in de toekomst.

Het is van cruciaal belang om de juiste gebeurtenisgeschiedenis en observatievensters te definiëren
Machine learning engineer bij Spotify, Guilherme Dinis, Jr., bestudeerde in zijn masterscriptie het gedrag van nieuwe Spotify-gebruikers die waren geregistreerd voor een gratis plan om te bepalen of ze weggaan of actief blijven tijdens de tweede week na hun registratie.
Hij koos de eerste week van gebruik als de gebeurtenisgeschiedenis. Om gebruikers te classificeren als churners en actieve gebruikers controleerde Guilherme of er enige streaming activiteit was in de tweede week. Als gebruikers naar muziek bleven luisteren, werden ze geclassificeerd als niet-churners.
“De redenen om de observatie- en activeringsvensters relatief klein te houden, is ingegeven door interne eerdere studies op dezelfde populatie gebruikers, die wezen op een hoge churn waarschijnlijkheid twee weken na registratie,” legde de ingenieur uit.
Dus, om de event history levensduur en het prestatievenster te definiëren, moet u overwegen wanneer uw gebruikers gewoonlijk churnen. Het kan de tweede week zijn, zoals in het Spotify-voorbeeld, of het kan de 11e maand van het jaarabonnement zijn. Maar waarschijnlijk wil je niet te weten komen dat deze abonnee waarschijnlijk binnen een maand zal afhaken.
Het in evenwicht brengen van de tijd voor observaties en voorspellingen is eigenlijk een lastige taak. Bijvoorbeeld, als een waarnemingsvenster één maand is, dan zal een prestatievenster voor een klant met een jaarabonnement 11 maanden zijn. Het lijkt erop dat het maken van een korte event history en lange performance windows het meest gunstig zou zijn voor bedrijven. Je neemt weinig tijd voor observatie en hebt genoeg tijd voor re-engagement. Helaas werkt het niet altijd op deze manier. Een korte voorgeschiedenis is misschien niet genoeg om betrouwbare voorspellingen te doen, zodat het experimenteren met deze parameters een zich herhalend continu proces kan worden met de nodige afwegingen. In principe moet u de gebeurtenisgeschiedenis definiëren die genoeg zou zijn voor een model om een gerechtvaardigde voorspelling te doen, maar toch genoeg tijd zou hebben om potentiële churn aan te pakken.
Modelleren en testen
Het belangrijkste doel van deze projectfase is de ontwikkeling van een churn-voorspellingsmodel. Specialisten trainen meestal tal van modellen, stemmen ze af, evalueren en testen ze om het model te definiëren dat potentiële opzeggers detecteert met het gewenste niveau van nauwkeurigheid op trainingsgegevens.
Klassieke machine learning-modellen worden vaak gebruikt voor het voorspellen van klantverloop, bijvoorbeeld logistische regressie, beslisbomen, willekeurig bos, en anderen. Alex Bekker van ScienceSoft stelt voor om Random Forest als basismodel te gebruiken, waarna “de prestaties van modellen als XGBoost, LightGBM of CatBoost kunnen worden beoordeeld”. Data scientists gebruiken over het algemeen de prestaties van een basismodel als een metriek om de voorspellingsnauwkeurigheid van complexere algoritmen te vergelijken.
Logistische regressie is een algoritme dat wordt gebruikt voor binaire classificatieproblemen. Het voorspelt de waarschijnlijkheid van een gebeurtenis door de relatie te meten tussen een afhankelijke variabele en een of meer onafhankelijke variabelen (kenmerken). Meer specifiek voorspelt logistische regressie de kans dat een instantie (gegevenspunt) tot de standaardcategorie behoort.
Een beslissingsboom is een soort algoritme voor begeleid leren (met een vooraf gedefinieerde doelvariabele.) Hoewel het meestal wordt gebruikt voor classificatietaken, kan het ook numerieke gegevens verwerken. Dit algoritme splitst een gegevensmonster in twee of meer homogene sets op basis van de belangrijkste differentiator in invoervariabelen om een voorspelling te doen. Bij elke splitsing wordt een deel van een boom gegenereerd. Het resultaat is een boom met beslissingsknooppunten en bladknooppunten (die beslissingen of classificaties zijn). Een boom begint bij een hoofdknooppunt – de beste voorspeller.
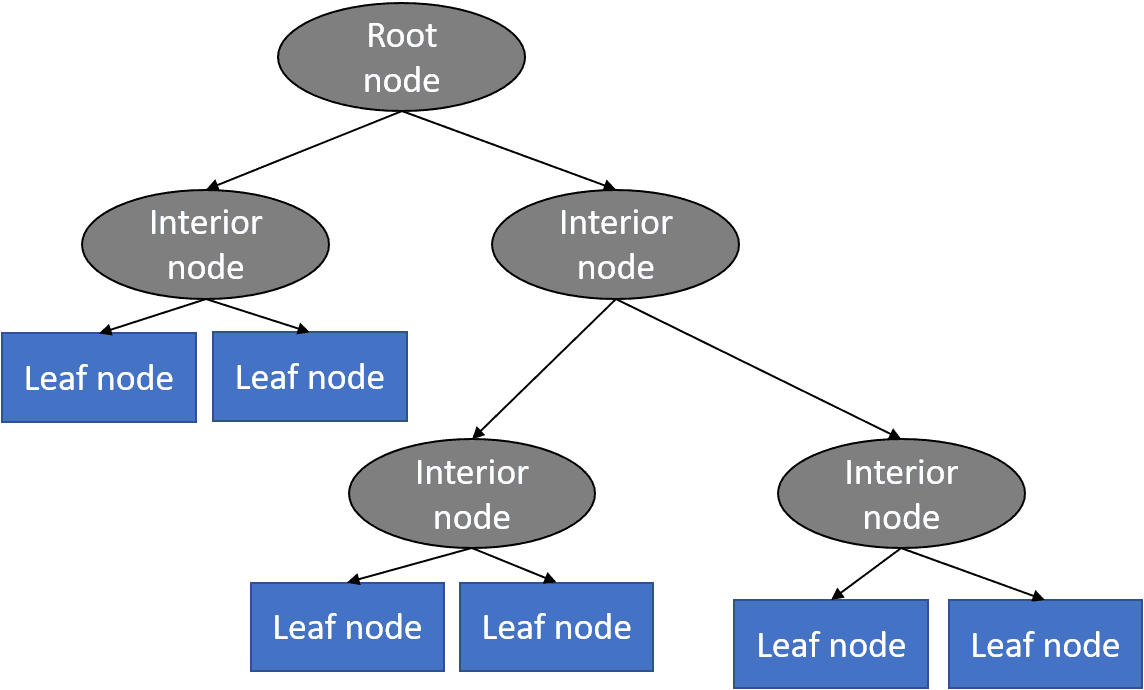
Beslissingsboom basisstructuur. Bron: Python Machine Learning Tutorial
Voorspellingsresultaten van beslisbomen kunnen eenvoudig worden geïnterpreteerd en gevisualiseerd. Zelfs mensen zonder analytische of data science achtergrond kunnen begrijpen hoe een bepaalde output is ontstaan. Vergeleken met andere algoritmen vereisen beslisbomen minder datavoorbereiding, wat ook een voordeel is. Ze kunnen echter onstabiel zijn als er kleine veranderingen in de gegevens worden aangebracht. Met andere woorden, variaties in de gegevens kunnen ertoe leiden dat radicaal verschillende bomen worden gegenereerd. Om dit probleem aan te pakken, gebruiken datawetenschappers beslisbomen in een groep (AKA ensemble) waarover we het hierna zullen hebben.
Een Random forest is een soort van een ensemble-leermethode die talrijke beslisbomen gebruikt om een hogere voorspellingsnauwkeurigheid en modelstabiliteit te bereiken. Deze methode kan zowel regressie- als classificatietaken aan. Elke boom classificeert een gegevensinstantie (of stemt voor zijn klasse) op basis van attributen, en het bos kiest de classificatie die de meeste stemmen heeft gekregen. In het geval van regressietaken wordt het gemiddelde genomen van de beslissingen van de verschillende bomen.
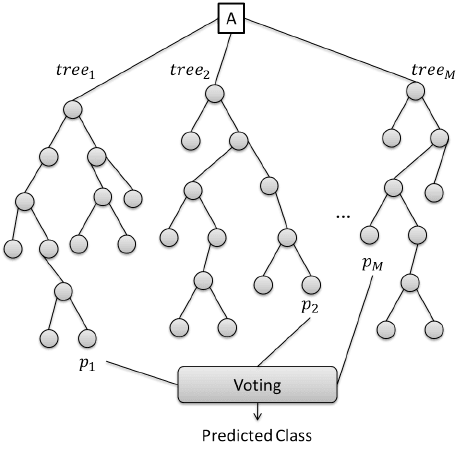
Dat is hoe Random Forest voorspellingen doet. Bron: ResearchGate
XGBoost is de implementatie van de gradient boosted tree-algoritmen die vaak worden gebruikt voor classificatie- en regressieproblemen. Gradient boosting is een algoritme dat bestaat uit een groep zwakkere modellen (bomen), die hun schattingen sommeren om een doelvariabele met meer nauwkeurigheid te voorspellen.
Een groep onderzoekers van de Universiteit van Virginia bestudeerde de tijdsafhankelijke gebruiksgegevens van softwarekenmerken, zoals inlognummers en commentaarnummers, om een SaaS-klantenchurn binnen de tijdshorizon van drie maanden te voorspellen. De auteurs vergeleken de prestaties van het model met vier classificatiealgoritmen, en “het XGBoost-model behaalde de beste resultaten voor het identificeren van de belangrijkste softwaregebruikskenmerken en voor het classificeren van klanten als ofwel churn type of niet-risicotype.” Het vermogen van het XGBoost-model om de belangrijkste kenmerken te definiëren die vertegenwoordigen hoe klanten SaaS-software gebruiken, kan dienstverleners helpen effectievere marketingcampagnes te lanceren bij het targeten van potentiële klanten, aldus onderzoekers.
LightGBM is een gradient boosting-framework dat boomgebaseerde leeralgoritmen gebruikt. Het kan worden gebruikt voor veel ML-taken, bijvoorbeeld classificatie en rangschikking. Volgens de documentatie zijn enkele voordelen van LightGBM een snellere trainingssnelheid en een hogere efficiëntie, evenals een grotere nauwkeurigheid. Deze algoritmen gebruiken minder geheugen en kunnen grote hoeveelheden gegevens aan – het is niet raadzaam om ze te gebruiken op datasets met minder dan 10.000 rijen. LightGBM ondersteunt ook parallel en GPU leren (het gebruik van grafische verwerkingseenheden voor het trainen van grote datasets).
CatBoost is een andere gradient boosting op beslisbomen bibliotheek. Het kan zowel numerieke als categorische kenmerken verwerken, en kan dus worden gebruikt voor classificatie, regressie, rangschikking, en andere machine-leertaken. Een van de voordelen van CatBoost is dat het modellen kan trainen met CPU en twee of meer GPU’s.
Techniekkeuze. Talrijke factoren kunnen van invloed zijn op het aantal vereiste modellen in productie en hun type. Hoewel het geval van elk bedrijf uniek is, wegen in het algemeen de benaderingen van het beheer van klantgegevens en de bedrijfsbehoeften wel mee. De keuze van een voorspellingstechniek kan afhangen van:
- Levenscyclusfase van de klant. Specialisten van HubSpot concludeerden bijvoorbeeld dat de modelkeuze kan afhangen van de fase van interactie tussen een klant en een merk. “Klanten in onboarding vertonen meestal niet dezelfde waarde metrics als klanten die HubSpot al langer dan een jaar gebruiken. Dus, een model getraind op klanten ouder dan een jaar kan echt geweldig werken voor die klanten, maar niet accuraat zijn wanneer het wordt toegepast op klanten die nog in onboarding zijn, “legt Michael van HubSpot uit.
- De behoefte aan outputuitleg. Wanneer vertegenwoordigers van het bedrijf (bijvoorbeeld customer success managers) de redenen voor churn moeten begrijpen, kunnen zogenaamde white box-technieken zoals decision trees, random forest of logistieke regressie worden gebruikt. Verhoogde interpreteerbaarheid is een van de belangrijkste redenen waarom HubSpot kiest voor random forest. Soms is het voldoende om alleen churn te detecteren, bijvoorbeeld wanneer het bedrijfsmanagement de budgettering voor het volgende jaar moet inschatten en daarbij rekening moet houden met mogelijke verliezen als gevolg van klantenchurn. In deze gevallen zouden minder interpreteerbare modellen werken.
- Customer persona. Denk aan een bedrijf dat talrijke producten levert, die elk een specifiek gebruikerstype hebben ontworpen. Aangezien verschillende klantpersona’s typische gedragspatronen kunnen hebben, lijkt het gebruik van speciale modellen om de waarschijnlijkheid van hun churn te voorspellen redelijk. Michael Redbord voegt daaraan toe: “In een groeiend bedrijf zal de aard van het klantenbestand evolueren, vooral wanneer nieuwe producten worden geïntroduceerd. Modellen die op een bepaalde groep klanten zijn gebaseerd, werken mogelijk niet meer zo goed wanneer er een nieuwe klantpersoonlijkheid in het klantenbestand wordt opgenomen. Wanneer we een nieuwe productlijn hebben geïntroduceerd, hebben we dus meestal nieuwe modellen gebouwd om de churn van die klanten te voorspellen.”
Deployment en monitoring
En nu de laatste fase van de workflow van het churn-voorspellingsproject. Het (de) geselecteerde model(len) moet(en) in productie worden genomen. Een model kan in bestaande software worden opgenomen of de kern van een nieuw programma worden. Het “deploy-and-forget”-scenario zal echter niet werken: Data scientists moeten de nauwkeurigheidsniveaus van een model in de gaten houden en het zo nodig verbeteren.
“Het voorspellen van klantenchurn met machine learning en kunstmatige intelligentie is een iteratief proces dat nooit eindigt. We monitoren de prestaties van het model en passen waar nodig functies aan om de nauwkeurigheid te verbeteren wanneer klantgerichte teams ons feedback geven of wanneer er nieuwe gegevens beschikbaar komen. Op het punt van elke menselijke interactie – een support call, een CSM QBR , een Sales discovery call – monitoren en loggen we de menselijke interpretatie van de hulp van de klant, die de machine learning-modellen verbetert en de nauwkeurigheid van onze gezondheidsvoorspelling voor elke klant verhoogt,” vat Michael samen.
De frequentie waarmee de prestaties van een model worden getest, hangt af van hoe snel gegevens verouderen in een organisatie.
Conclusie
Churn rate is een gezondheidsindicator voor op abonnementen gebaseerde bedrijven. De mogelijkheid om klanten te identificeren die niet tevreden zijn met de geleverde oplossingen, stelt bedrijven in staat om meer te weten te komen over de zwakke punten van product- of prijsplannen, operationele problemen en de voorkeuren en verwachtingen van klanten om de redenen voor churn proactief te verminderen.
Het is belangrijk om gegevensbronnen en observatieperiode te definiëren om een volledig beeld te krijgen van de geschiedenis van de interactie met klanten. De selectie van de belangrijkste kenmerken voor een model zou van invloed zijn op de voorspellende prestaties: Hoe kwalitatiever de dataset, hoe nauwkeuriger de voorspellingen zijn.
Bedrijven met een groot klantenbestand en talrijke aanbiedingen zouden baat hebben bij klantsegmentatie. Het aantal en de keuze van ML-modellen kan ook afhangen van de resultaten van segmentatie. Data scientists moeten ook ingezette modellen monitoren, en functies herzien en aanpassen om het gewenste niveau van voorspellingsnauwkeurigheid te behouden.
Original. Herplaatst met toestemming.