Google Analytics regex (tj. regulární výrazy) je nedoceněná sada dovedností.
Pokud chcete provádět jakékoliv filtrování nebo cílení nad rámec základů, dobré ovládání regexu vám dá v Analytics superschopnosti.

Regex vám dává superschopnosti. – zdroj obrázku
Regulární výrazy mají samozřejmě mnohem širší využití než jen v analytice a marketingu. Pro účely tohoto článku se však budeme zabývat některými taktickými případy použití, které by vám mohly pomoci při získávání informací o uživatelích, organizaci dat a dokonce i v případech pokročilého cílení a marketingu ve vyhledávačích.
Nejprve si však stručně shrňme, co jsou regulární výrazy, konkrétně ve vztahu ke službě Google Analytics.
- Google Analytics RegEx: Co to je?“
- Google Analytics RegEx Cheat Sheet
- Pipe (|)
- Zpětné lomítko (\)
- Caret (^)
- Znak dolaru ($)
- Tečka (.)
- Hvězdička (*)
- Kombinace tečka-hvězdička (.*)
- Znak plus (+)
- Otázkový znak (?)
- Parentheses ()
- Čtvercové závorky ()
- Pomlčky (-)
- Kudrnaté závorky ({ })
- Google Analytics RegEx: Konkrétní příklady, které můžete použít
- Google Analytics RegEx Tips & Chyby, kterým se vyhnout
- Mimo Google Analytics: RegEx pro další marketingové využití
- Závěr
Google Analytics RegEx: Co to je?“
Regulární výrazy jsou speciální textové řetězce pro popis vzorů vyhledávání.
Hmm?“
V souvislosti s analýzou vám regulární výrazy pomáhají najít, definovat a extrahovat věci. Ještě konkrétněji, v nástroji Google Analytics, vám mohou pomoci vytvořit flexibilnější definice pro věci, jako jsou filtry zobrazení, cíle, segmenty, publika, skupiny obsahu a seskupení kanálů.
Zásadně se jedná o předdefinované znaky nebo série znaků, které široce nebo úzce odpovídají a vybírají vzory v datech digitální analytiky. Jsou obecným nástrojem, který lze použít mnoha způsoby (spousta programovacích jazyků a nástrojů umožňuje použití regexů). V Analytice je však budeme používat hlavně k porovnávání vzorů v datech.
Není samozřejmě užitečný jen v Analytice. Zejména pokud používáte Google Tag Manager nebo pokud provádíte složité cílení A/B testů, budete regex používat často. Jak říká Chris Mercer, zakladatel společnosti MeasurementMarketing.io:
„Regex používáme denně. Pomáhá nám jasně definovat vše od kroků trychtýře v cíli Google Analytics až po konkrétní spouštěče v Google Tag Manageru.“
Pokud byste se však chtěli ponořit do hloubky a regulární výrazy se opravdu naučit, zde je několik zdrojů (nejsou nutné pro základní věci v Google Analytics a pravděpodobně pro někoho technicky zdatnějšího):
- Regulární výrazy:
- Mastering Regular Expressions 3rd Edition (Book)
- Learn Regular Expressions the Hard Way
Můžete se také učit interaktivně pomocí něčeho jako RegexOne nebo RegexR, obojí je super. Ale pojďme se přes to přenést a projděme si nejčastěji používané regexové znaky Google Analytics, abyste to mohli začít používat.
Google Analytics RegEx Cheat Sheet
Podívejte se na následující regexové znaky Google Analytics jako na jakýsi tahák – pravděpodobně je hned tak nepoužijete, ale stručné projití toho, co s regexy umíte, vám umožní vyhledat odpověď, až to bude potřeba.
Pro stručné shrnutí jsem nenašel nic stručnějšího a výstižnějšího než tuto příručku:

Velmi stručný průvodce regexem Google Analytics – zdroj obrázku
Je však vidět, že jen s tímto odkazem je to trochu vágní a nejednoznačné. Projděme si tedy nejčastěji používané regexy Google Analytics a zároveň si ukažme odpovídající případy použití.
Pipe (|)
Když chcete říci „NEBO“, měli byste použít pipe (|). Jako například „Tohle | To“, což by znamenalo „Tohle NEBO To“.
Pokud jste vášnivými uživateli segmentů Google Analytics, jste již zvyklí používat logické operátory OR.
Jedná se o jeden z jednodušších a častějších regulárních výrazů používaných v Google Analytics. Má mnoho aplikací, i když jedna z nejvyužívanějších může být při nastavování cílů. Pokud máte dvě děkovné stránky s odlišnými adresami URL (/děkuji/ a /předplatné-potvrzeno/), ale chcete obě sledovat jako splnění cíle, můžete použít tento regulární výraz.
Můžete ho také použít ve filtrech. Řekněme, že chcete zobrazit zprávu o chování dvou článků (o lekcích obsahového marketingu a analýze obsahu) s adresami URL /content-marketing-analytics/ a /content-marketing-lessons/. Jako filtr byste mohli napsat „content-marketing-analytics|content-marketing-lessons“ a získat pouze tyto články.
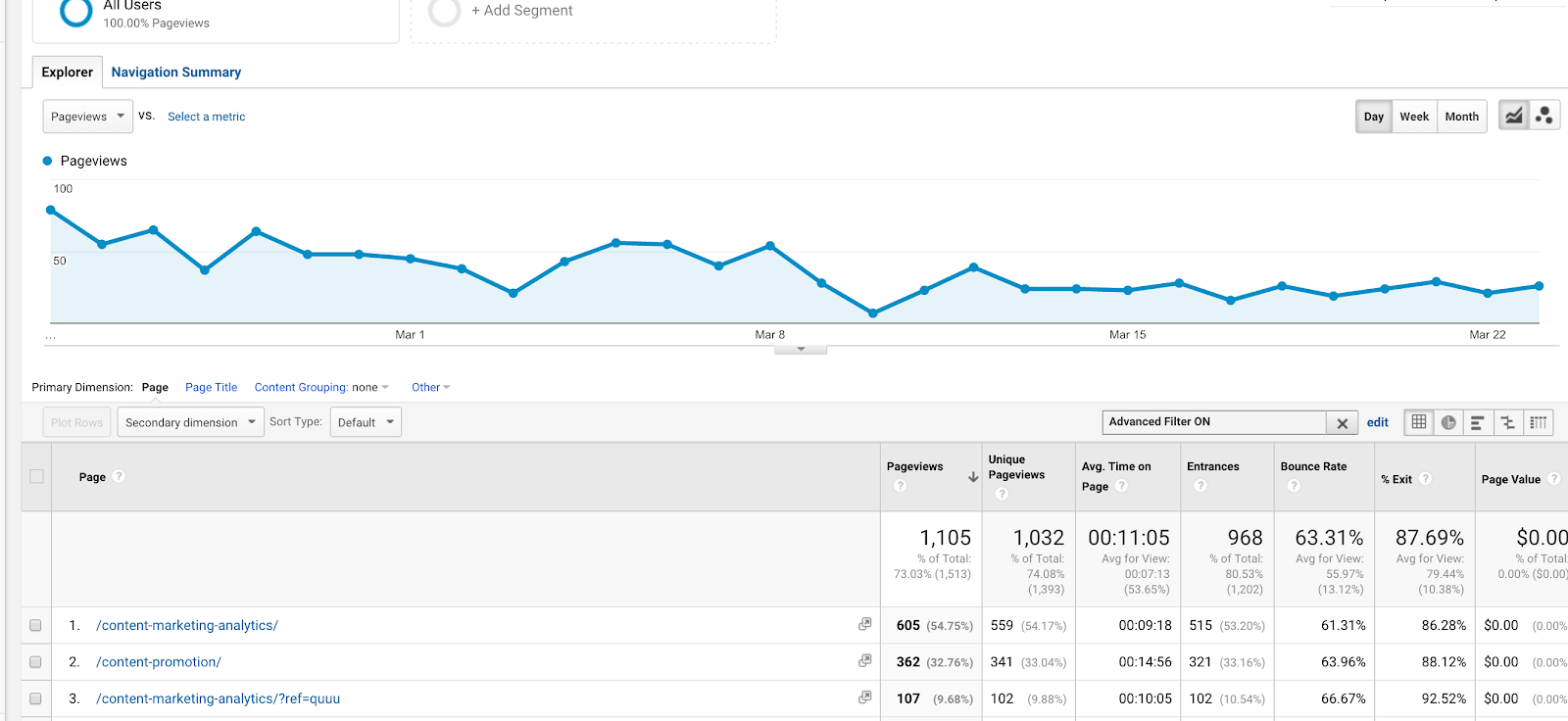
Použití fajfky (|) ve filtru pro získání výsledků pro dva samostatné příspěvky na blogu
Zpětné lomítko (\)
Zpětné lomítko (\) je další přímočarý a často používaný regulární výraz v Google Analytics. Znamená „považujte následující znak za obyčejný text, nikoliv za regex.“
Jinými slovy, existuje mnoho regulárních výrazů, které se objevují v obyčejném textu, například tečka, otazník a další, u kterých je třeba vyjasnit, zda se mají číst jako regulární výrazy, nebo jako obyčejný text.
Běžný řetězec dotazu online se používá, když někdo něco hledá na vašich stránkách. Například když na webu petsmart.com hledám „malé hračky pro psy“, zobrazí se tento řetězec dotazu:
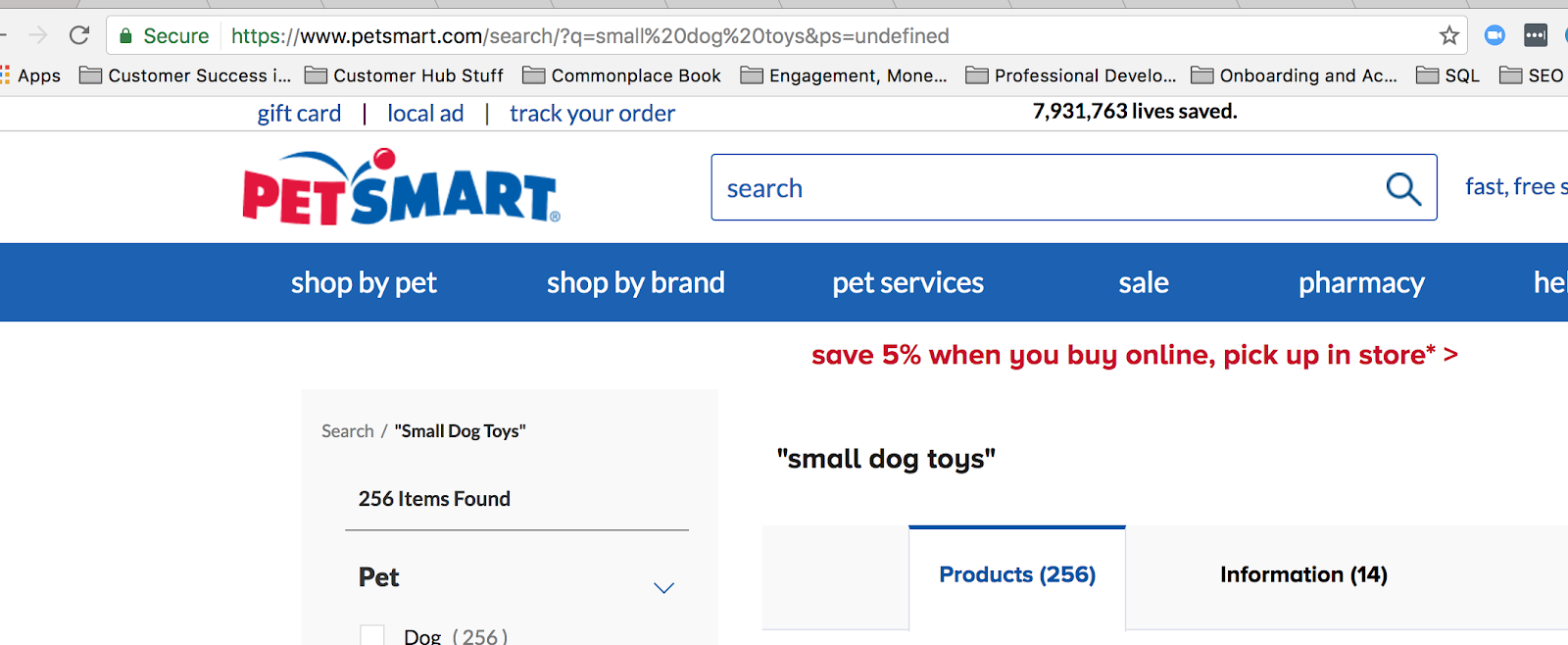
Při použití vyhledávání na webu vytvoříte řetězec dotazu v adrese URL.
Otázkový znak zde znamená, že proběhlo vyhledávání na webu, ale otazník je také běžně používaný regulární výraz v nástroji Google Analytics. Proto musíme při použití zpětného lomítka upřesnit, že v tomto případě by se otazník měl číst jako prostý text.
Řekněme, že chceme porovnat všechny řetězce dotazů v Google Analytics, které začínají /search/?q= (protože to znamená vyhledávání). Pak by regulární výraz byl:
search\/\?q=
To si můžete ověřit pomocí ladicího programu, například regex101.com:
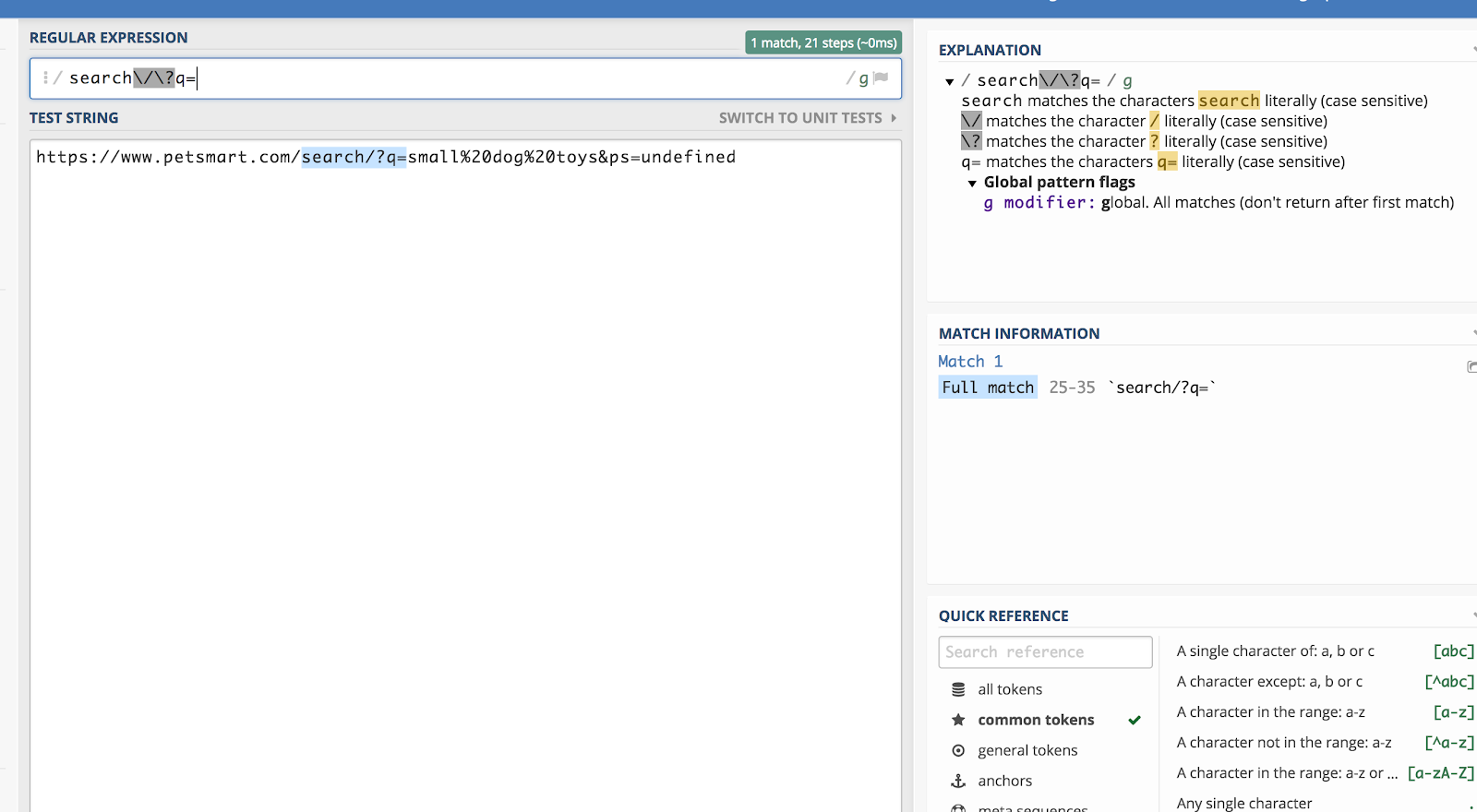
Zpětné lomítko (\) „uteče“ z regexu o jeden znak a přečte ho jako prostý text.
Caret (^)
Caret (^) znamená, že věta něčím začíná. To je důležité, když máte frázi, která se může vyskytovat kdekoli, ale chcete ji konkrétně porovnat s počátečním bodem. Podívejte se například na tento příklad několika různých frází, které obsahují slova „Mise: úspěšná.“
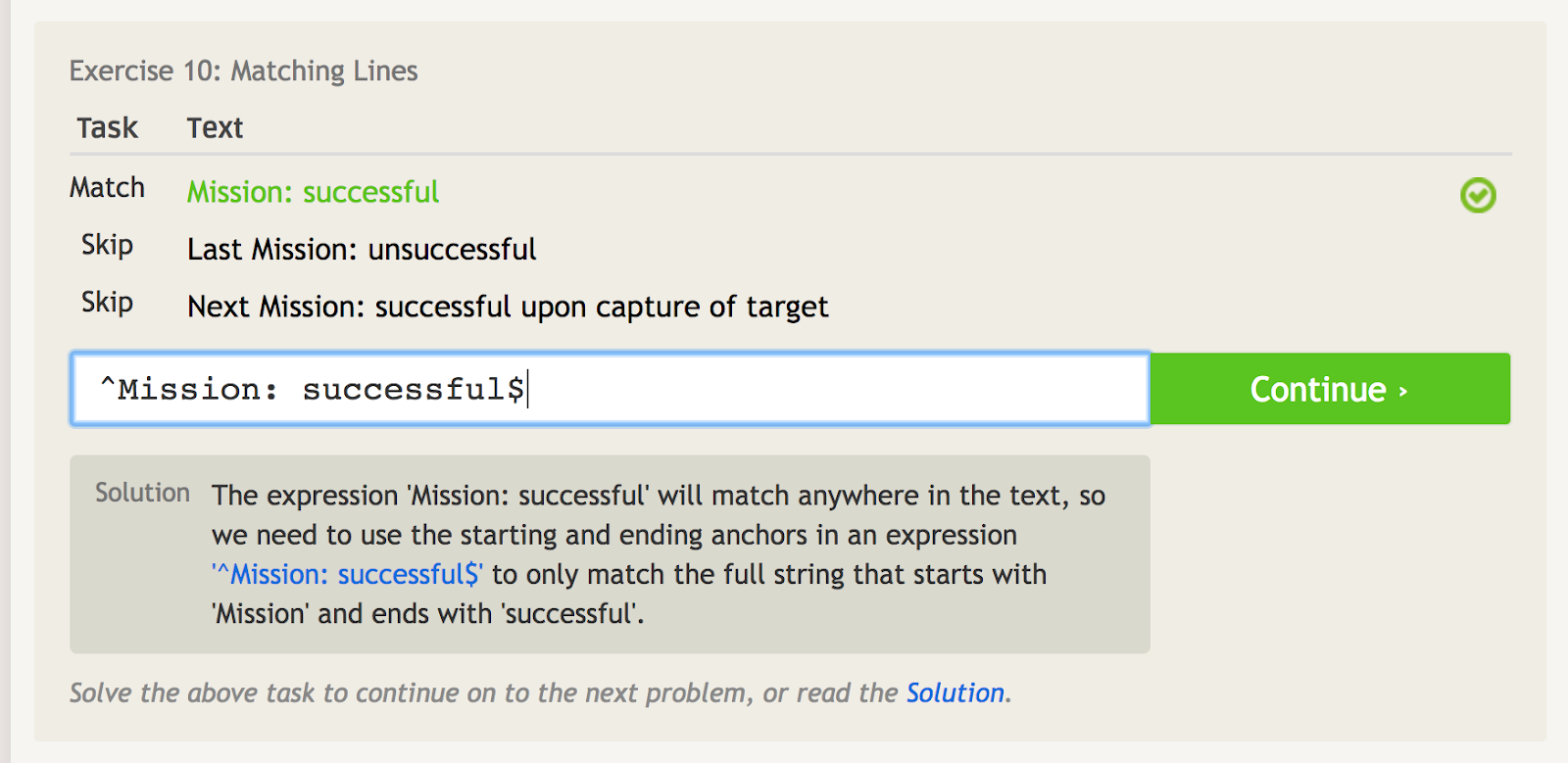
Caret signalizuje počáteční kotvu, takže zde můžeme přiřazovat výhradně první frázi.
Řekněme, že máte několik kampaní AdWords, které všechny začínají stejnou frází (protože jste špatný plánovač budoucnosti):
- Finální freemium kampaň
- Naše první freemium kampaň
- Kreativní nabídka freemium kampaně
- Testovací freemium kampaň
Chcete napsat ^Freemium kampaň, aby odpovídala té první, a žádné z ostatních.
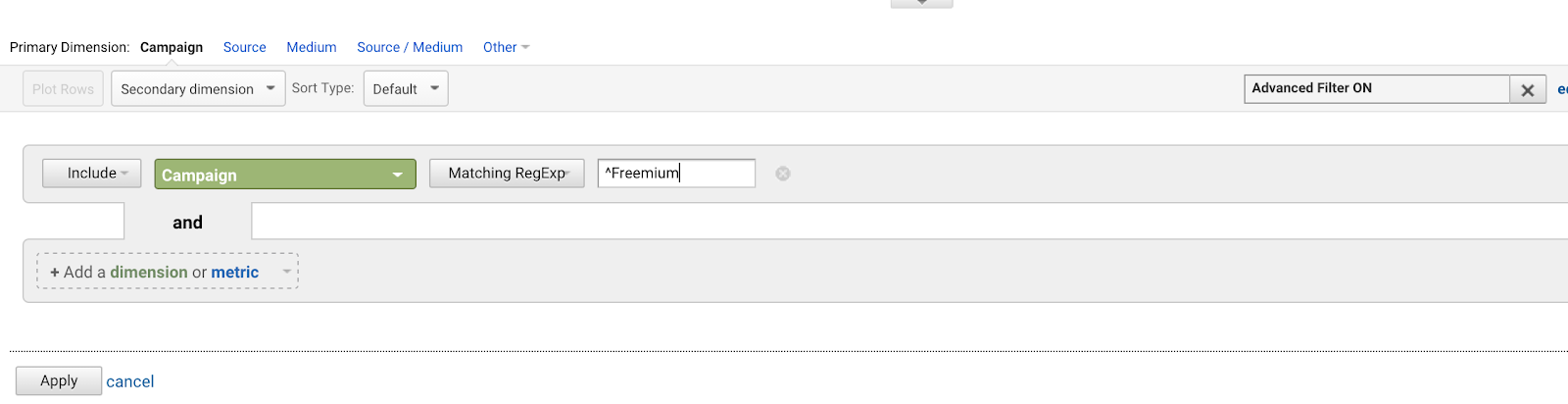
Použití znaku caret (^) odpovídá řetězcům, které začínají těmito znaky
Znak dolaru ($)
Znak dolaru ($) znamená, že fráze něčím končí.
Když tyto dva znaky zkombinujete, můžete cílit na přesnou shodu frází.
Pokud jste spustili kampaň s názvem „paidacquisitionfb“ a později jste spustili kampaň s názvem „paidacquisitionfb-2“, protože jste to dopředu dobře nenaplánovali a myslíte si, že budete mít další kampaně s podobným názvem (to se stává pořád), můžete tu první izolovat tak, že napíšete:
^paidacquisitionfb$
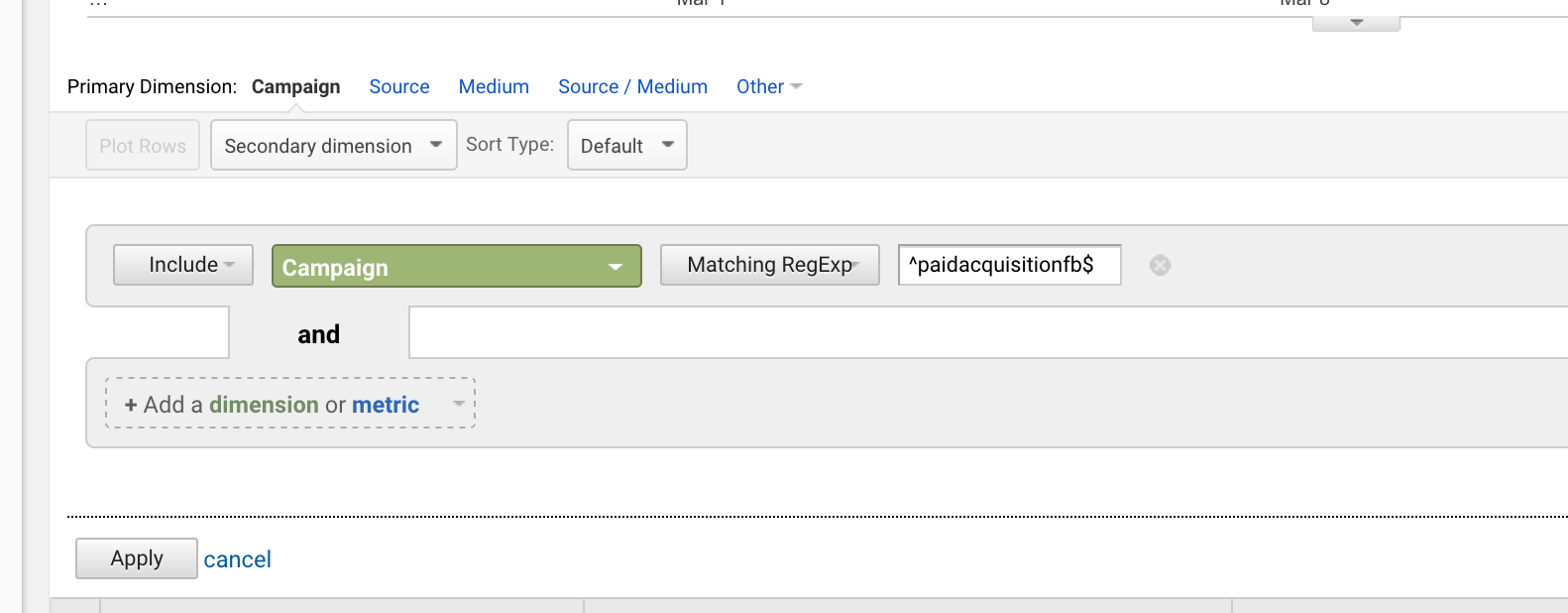
Použití carett a dolaru dohromady je velmi časté.
Pokud máte na svém blogu například spoustu stránek kategorií a všechny končí číslem stránky, můžete napsat jednoduchý kus regexu Google Analytics, který zobrazí pouze stránky kategorií blogu (^/page/*/$). Získali byste tak výpisy jako:
- /page/1
- /page/2
- /page/3
…a tak dále.
Tečka (.)
Tečka (.) odpovídá jakémukoli jednomu znaku, což znamená cokoli, co najdete na klávesnici: čísla, písmena, dokonce i bílé znaky. Sama o sobě není příliš užitečná, ale používá se neustále ve spojení s jinými regulárními výrazy, zejména s hvězdičkou (bude následovat).
Řekněme, že ji chcete použít samostatně, a použijme příklad „ki.“. Ten by odpovídal všemu, co začíná písmeny K a I, a pak dalším dvěma znakům, ať už jsou jakékoliv.
Takže pokud byste měli řetězec, který by obsahoval slova kill, kind, kiss, kin, kid! a kit, odpovídal by jim všem. Počkat, cože? Ano, vyhověl by slovům „kit“ a „kin“, pokud je za nimi mezera (zachytí i bílé znaky). Podle této logiky by také zachytil vykřičník ve slově „kid!“
Je vám jasné, proč se věci zamotají, pokud použijete pouze tento příklad.
Tady je ilustrace výše uvedeného příkladu pomocí Regex101.com:
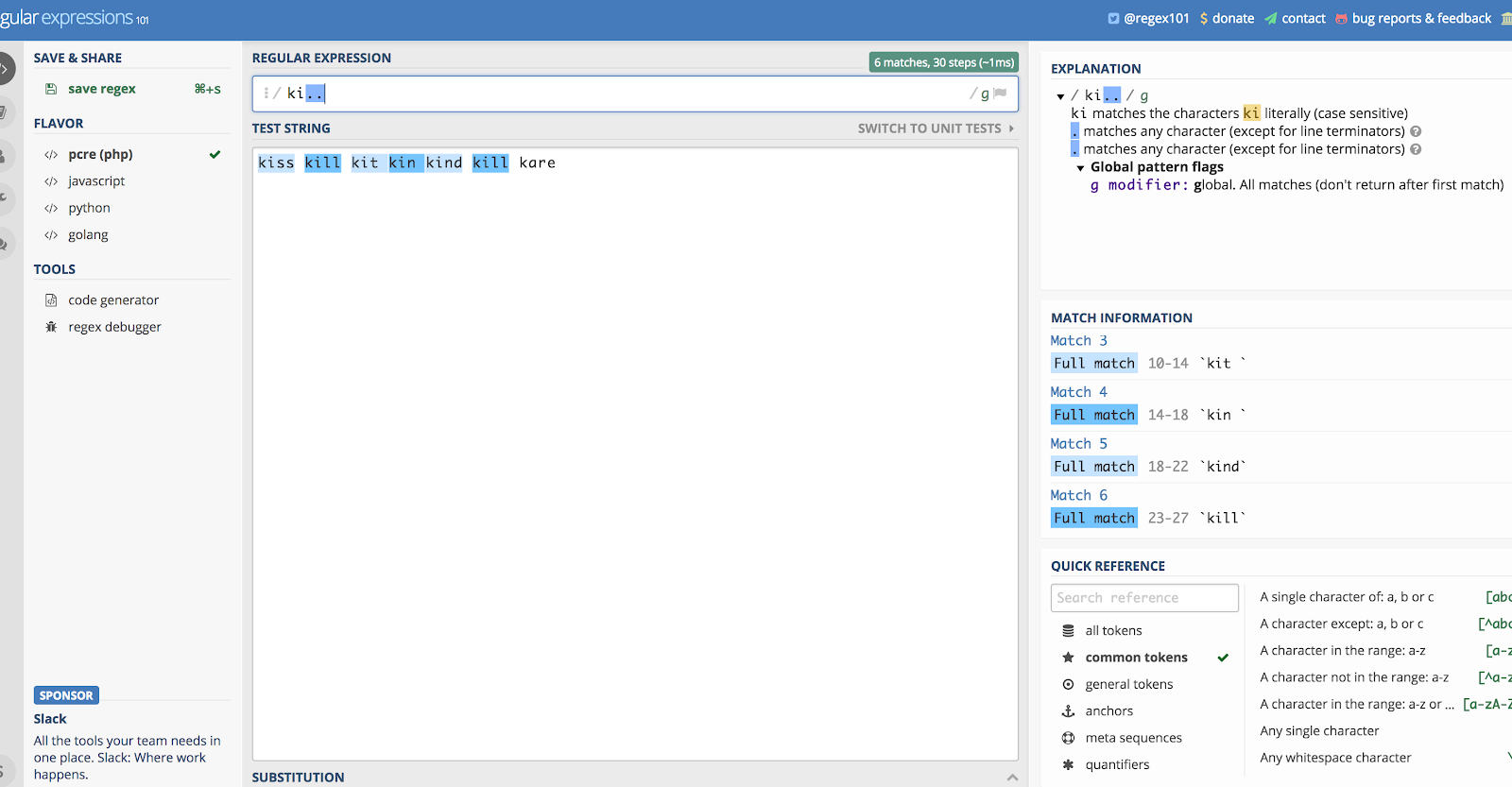
Tečka (.) odpovídá většině čehokoli.
Hvězdička (*)
Hvězdička (*) odpovídá nule nebo více předchozím položkám. Trochu matoucí, když to uvedete tímto způsobem, takže použiji jen příklad.
Pamatujete si na tu „wazzup“ reklamu od Budweiseru před časem? Bylo by dost obtížné odhadnout, jak by někdo tuto frázi napsal, kdyby ji hledal (třeba na YouTube). Ale teoreticky byste mohli všechny varianty pravopisu zapouzdřit takto:
waz*up
Tady je ukázka, jak to funguje v regex101:
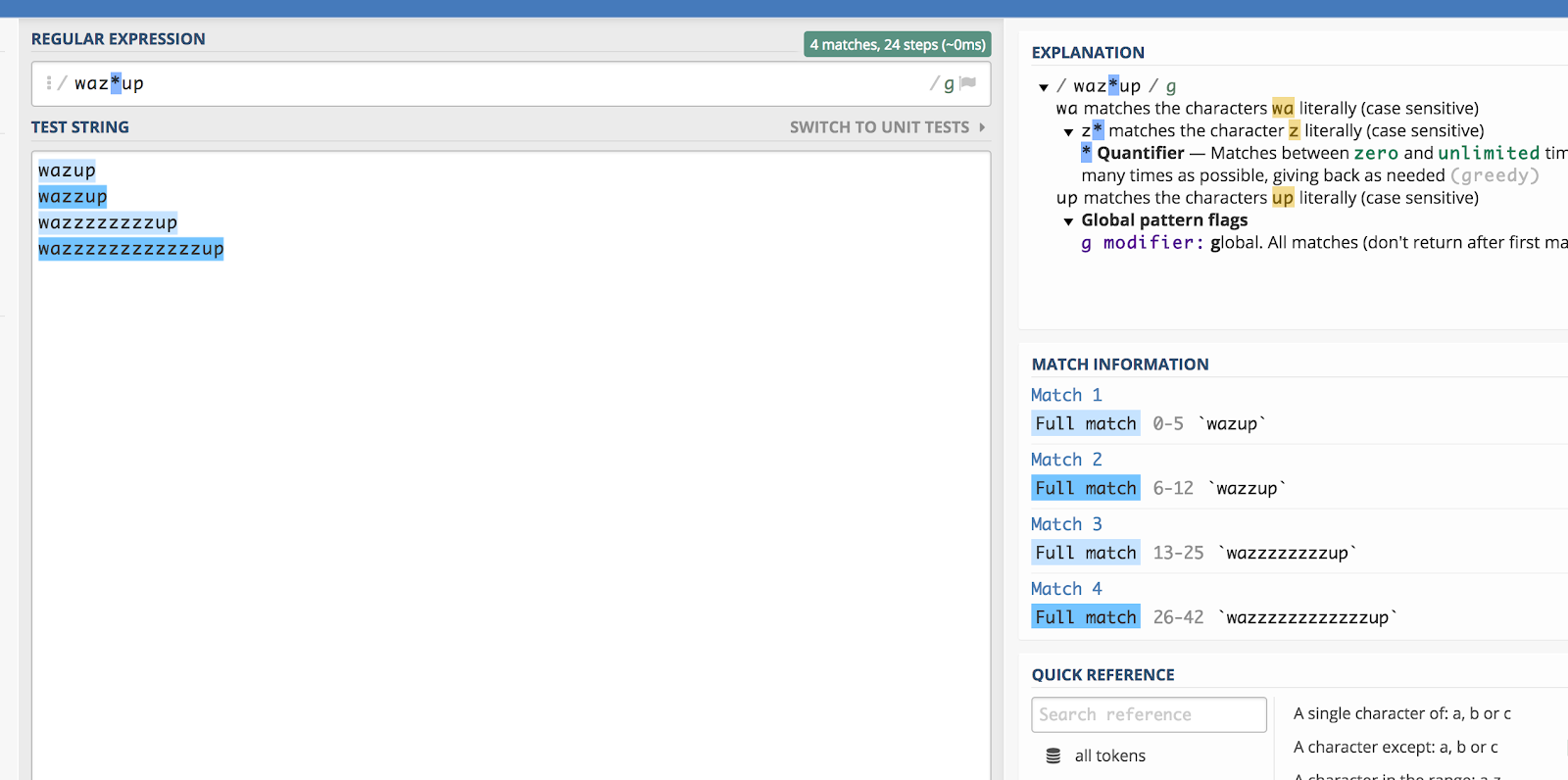
Hvězdička (*) odpovídá předchozímu znaku nula nebo vícekrát.
Pokud chcete být superpřesní a zohlednit velká a malá písmena, můžete napsat něco takového:
*
Ale to odbočuji.
Kde je hvězdička skutečně nejsilnější a častěji používaná, je s tečkou nebo jako součást jiných kombinací regexů.
Kombinace tečka-hvězdička (.*)
Kombinace tečka-hvězdička (.*) v podstatě znamená, že je možné cokoli. Používá se velmi často.
Tuto kombinaci použijete, když chcete v řetězci přiřadit cokoli. Protože tečka znamená shodu s jakýmkoli znakem a * znamená shodu s nulou nebo více znaky před ním, je tato kombinace velmi mocná.
Příklad: Máte několik různých typů zákaznických účtů, ale chtěli byste vidět data pro všechny z nich. Všechny mají podobné stránky, takže vaše stránky vypadají nějak takto:
/zákazník/pro/přihlášení/
/zákazník/zdarma/přihlášení/
/zákazník/starter/přihlášení/
Můžete k tomu napsat následující regex:
/zákazník/.*/přihlášení
Tento regexový výraz Google Analytics běžně používám k nastavení segmentů pro uživatele s ID uživatele.
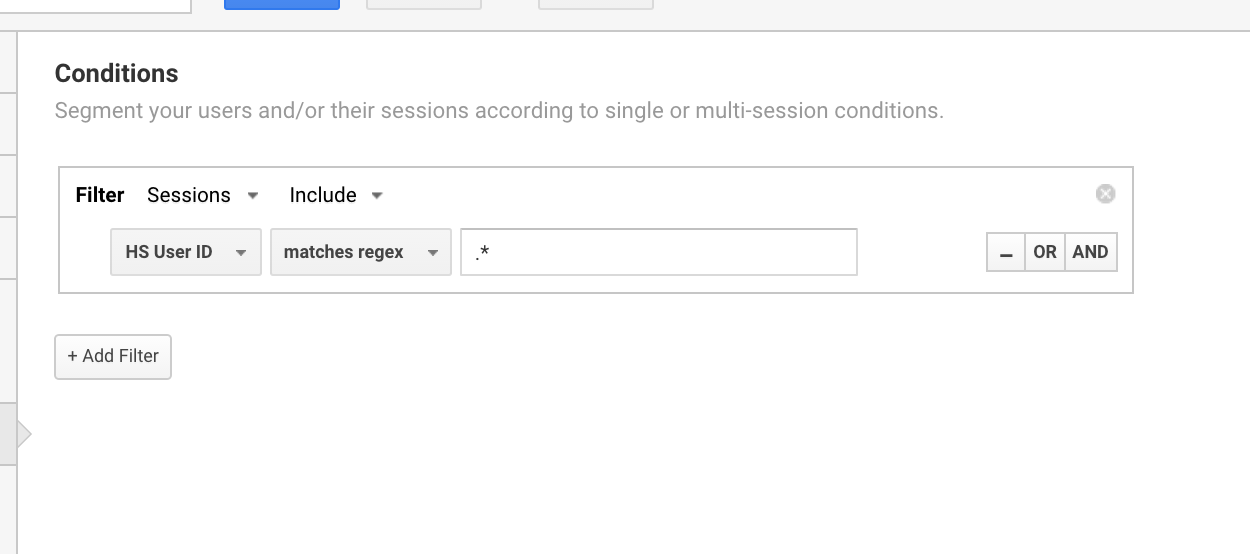
Pomocí regexu Google Analytics lze vyčlenit všechny relace, které mají ID uživatele.
Znak plus (+)
Znak plus (+) je velmi podobný znaku *, až na to, že odpovídá JEDNOMU nebo více předchozím znakům. K tomuto znaku není třeba říkat nic víc, jen to, že se velmi mírně liší od hvězdičky. Zde je rozdíl:
Představte si, že máte slova: ahoj, hhello a hhhello.
Pokud napíšete hh+ello, bude odpovídat pouze druhým dvěma, ale pokud napíšete hh*ello, bude odpovídat všem.
Menší rozdíl. Ve skutečnosti téměř vždy používám hvězdičku místo znaménka plus.
Otázkový znak (?)
Otázkový znak (?) je jednoduchý. Jednoduše znamená, že posledním znakem je možnost.
Řekněme, že vám příliš nezáleží na tom, zda je slovo v množném čísle, nebo ne (jako v případě bot). Může to být „bota“ nebo „boty“ a vy ho chcete zachytit v obou případech. Pak můžete napsat „boty?“
Tady je příklad s použitím mého jména. Kdyby ho někdo při vyhledávání na webu napsal „Alex Birket“, asi bych to stejně chtěl vidět. Takže mohu napsat:
Alex Birkett?
Takto to vypadá v regex101.com:
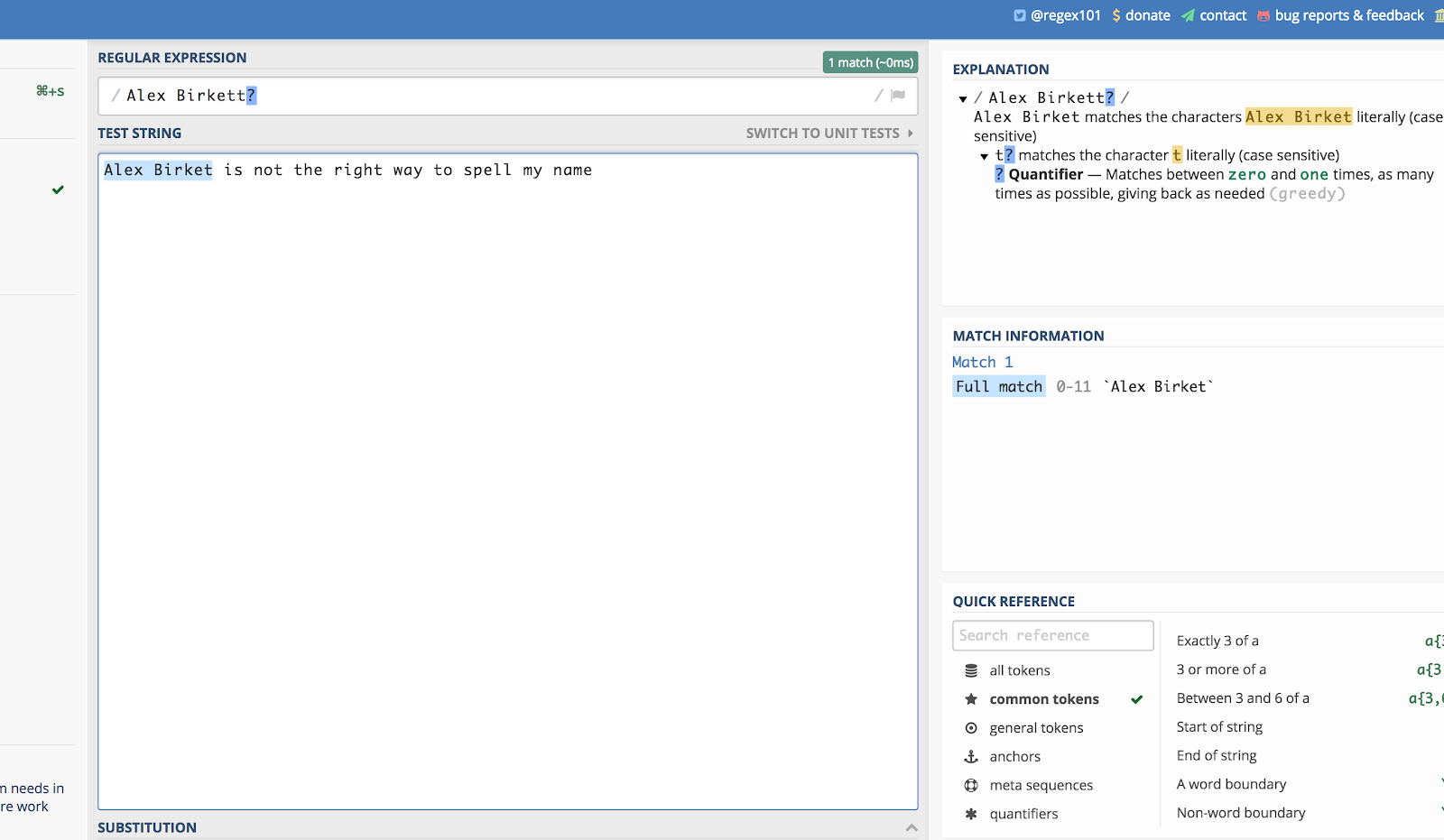
Otazník (?) způsobuje, že poslední znak, který mu předchází, je nepovinný.
Parentheses ()
Parentheses fungují stejně jako v matematice. Říkají vám, abyste upřednostnili a izolovali logiku, která je v nich ve hře.
Řekněme, že máte společnost SaaS se třemi nabídkami a chcete sladit všechny své cenové stránky. Vaše adresy URL jsou následující:
site.com/products/meetings/pricing
site.com/products/crm/pricing
site.com/products/email/pricing
Chcete-li zachytit všechny tři z nich, můžete použít regulární výraz, jako je tento:
^/products/(meetings|crm|email)/pricing$
Čtvercové závorky ()
Čtvercové závorky () vytvoří seznam. Pokud máte tři řetězce „věc1″, věc2“ a „věc3“, můžete je všechny porovnat tak, že napíšete „věc“ nebo „věc“ (více o pomlčkách za chvíli – běžně se používají s hranatými závorkami.
Hranaté závorky lze použít k porovnání několika iterací slova nebo řetězce a zároveň k vyloučení několika dalších iterací. Pokud například chcete porovnat slova „can“, „man“ a „fan“, ale ne „dan“, „ran“ nebo „pan“, můžete k tomu použít následující regex:
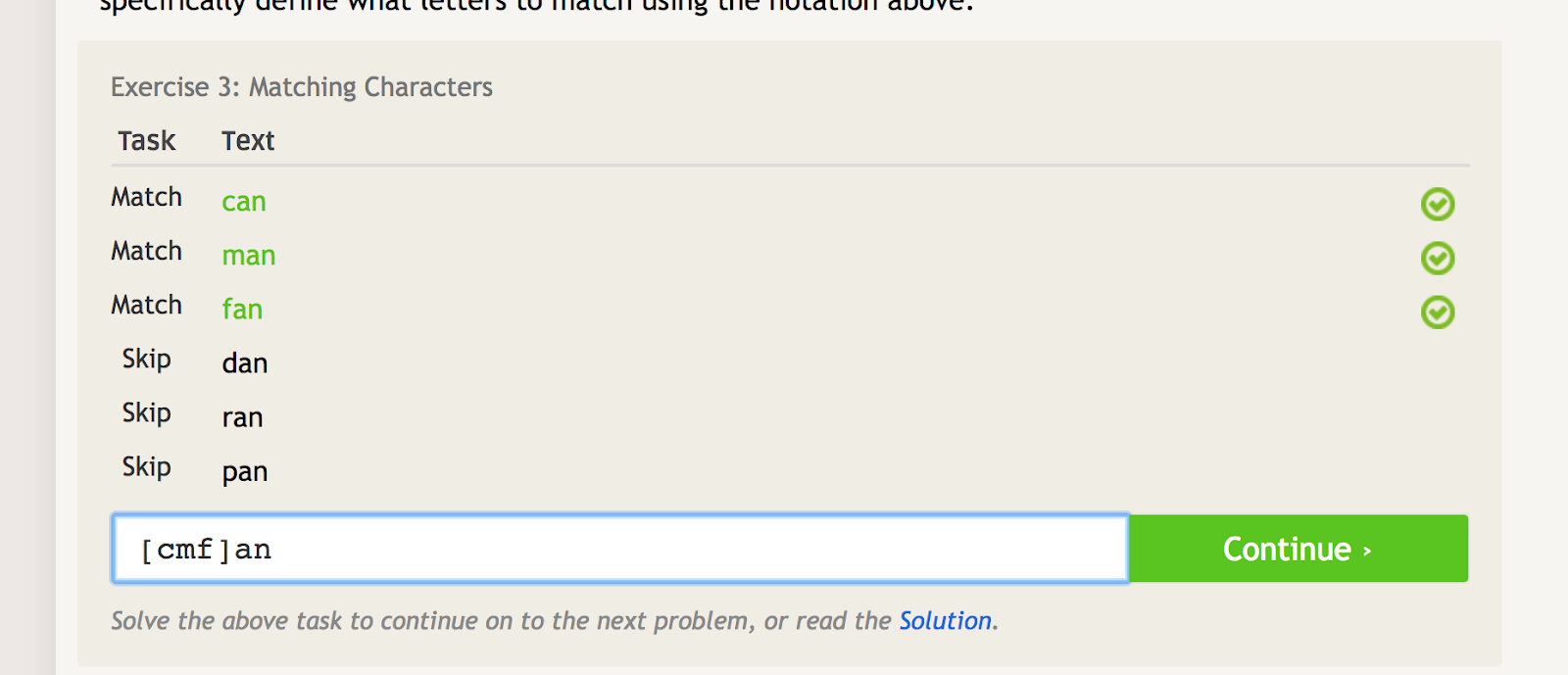
Čtvercové závorky vytvářejí několik odpovídajících podmínek v závislosti na tom, jaké znaky do nich vložíte. – zdroj obrázku
To můžete použít, pokud máte několik různých produktů s podobnými názvy, například „boty1“, „boty3“ a „boty5“. Ty a nic jiného byste mohli přiřadit pomocí „shoes“
Pomlčky (-)
Pomlčky (-) fungují při vytváření lineárních seznamů položek.
Při použití hranatých závorek nemusíte jednoduše vypisovat vše, pokud se to vyskytuje lineárně. Pokud tedy chcete přiřadit řetězec čísel, kde poslední může být cokoli od nuly do devíti, můžete napsat toto:
1234
Nebo můžete napsat mnohem jednodušší:
1234
Toto funguje i pro písmena. Představme si, že máte kategorii stránky, která končí dvěma náhodnými písmeny. Něco takového:
/page-aa/
Všem těmto písmenům můžete odpovídat tak, že napíšete:
/page-*/
Příklad na regex101 můžete vidět zde:
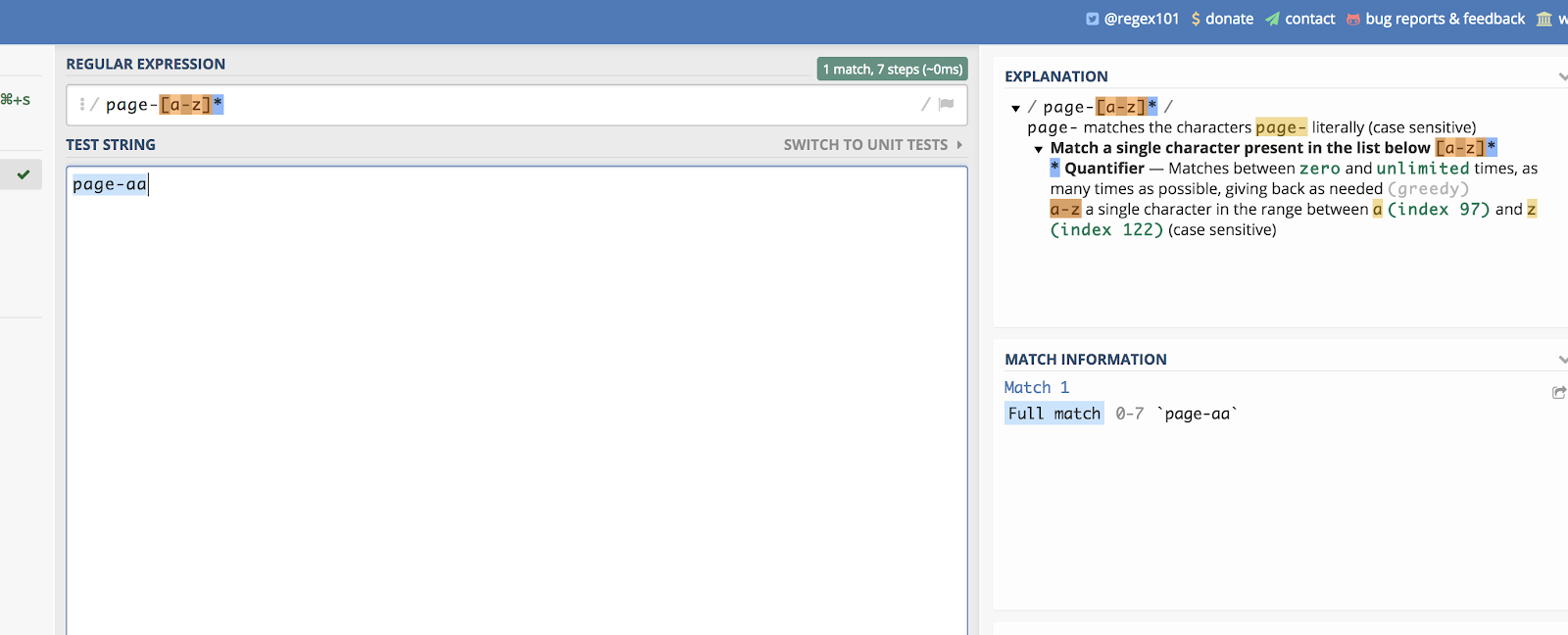
Mlčky vám pomohou vytvořit lineární seznam, kterému budete odpovídat.
Kudrnaté závorky ({ })
Kudrnaté závorky ({}) říkají, kolikrát se má poslední položka opakovat.
Například pokud chcete porovnat pouze „wazzzzup“, můžete použít „waz{4}up“.
Ale pokud chcete porovnat „wazzzzzup“ a „wazzzup“, ale ne „wazup“, můžete použít „waz{3,5}up“. To v podstatě říká, že se má znak „z“ shodovat ne méně než třikrát, ale ne více než pětkrát.
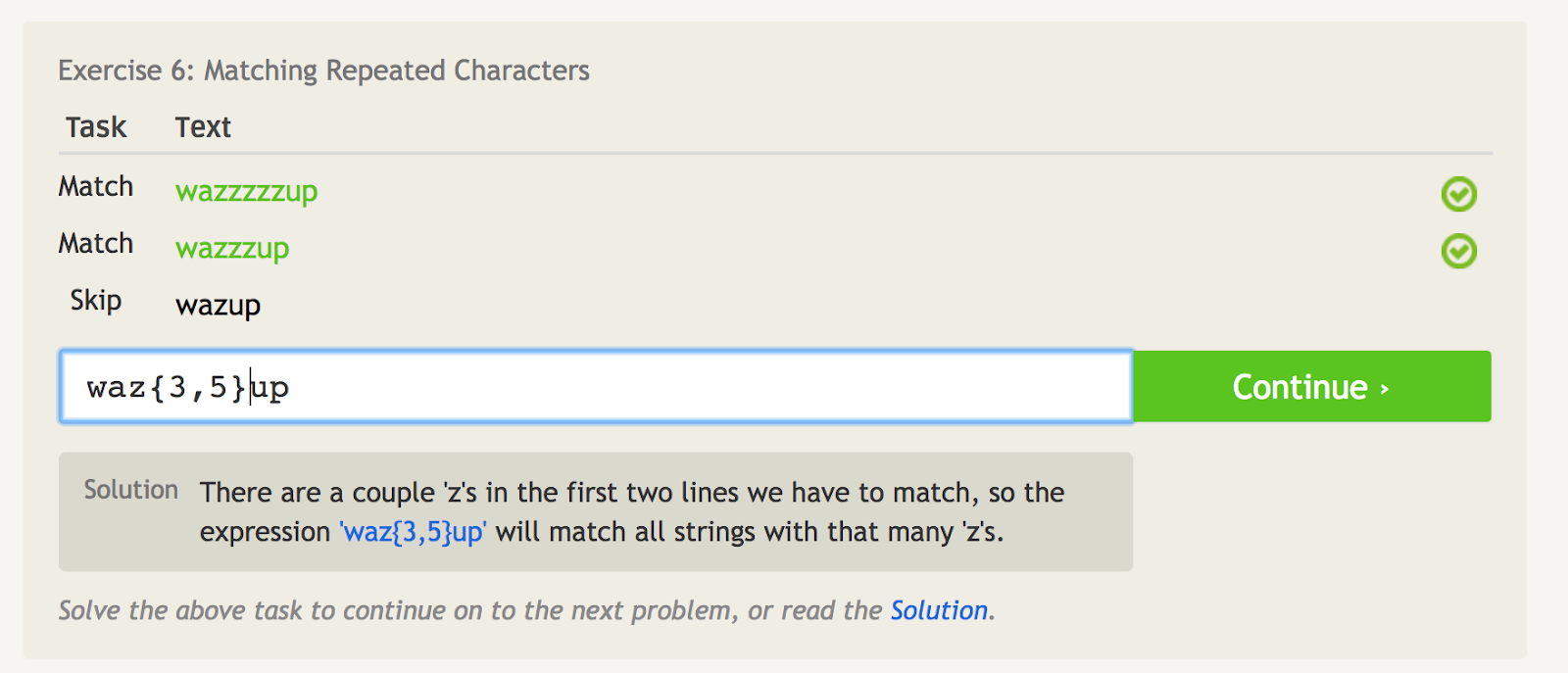
Kudrnaté závorky vám říkají, kolikrát se má poslední položka opakovat. – zdroj obrázku
Tento regulární výraz jsem v Google Analytics opravdu moc nepoužíval, ale častým případem použití může být poštovní směrovací číslo. Obvykle jsou první dva znaky ve městě stejné (například 78- pro Austin, TX). Takže byste mohli porovnat libovolné poštovní směrovací číslo města Austin, TX tak, že napíšete:
78{3}
Tím je řečeno, že poslední tři písmena mohou být libovolné náhodné číslo od nuly do devíti.
Google Analytics RegEx: Konkrétní příklady, které můžete použít
Jedním z nejčastějších případů použití regexu v Google Analytics je sestavení filtrů. Projdeme si tři příklady, jeden jednoduchý a jeden trochu složitější.
Nejprve příklad inspirovaný skvělým příspěvkem na serveru Search Engine Land od Jenny Halasz.
Řekněme, že máte zpřeházenou architekturu webu, ale chcete se podívat na všechny příspěvky s určitým podadresářem. Může to být cokoli, třeba kategorie webu nebo typ obsahu. V tomto příkladu hledáme kategorii na webu pro /music/, ale pouze ve třetím podadresáři. V tomto případě můžete napsat ^/.*/.*/music/.* a zobrazí se vám tato zpráva.

Tento regex Google Analytics vám zobrazí pouze /music/ ve třetím podadresáři. – zdroj obrázku
Na první pohled to vypadá zmateně – ale poté, co se naučíte, co tyto regulární výrazy znamenají, je to docela jednoduché. V podstatě jen říkáme systému GA, aby porovnával vstupní stránku, která začíná (^) lomítkem, pak libovolnými znaky (.*), pak lomítkem, pak libovolnými znaky (.*), pak lomítkem a pak hudbou.
Podobnou taktiku používá i nástroj LawnStarter pro hlášení. Jejich strategie spočívá v tom, že vytvářejí obsah specifický pro jednotlivá města v podsložce svých městských stránek v následujícím formátu:
https://www.lawnstarter.com/{{ transakční stránka města }}/{{ kus informačního obsahu }}
Pro odfiltrování obsahu z konverzních trychtýřů a hlášení návštěvnosti používají podle zakladatele Ryana Farleyho následující regex.
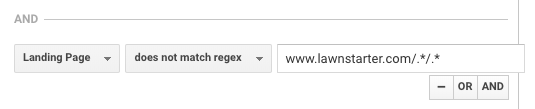
Tento regex pomáhá společnosti LawnStarter přiřadit obsah na jejich webu ke konkrétnímu městu.
Druhé si projdeme, jak nastavit filtr pro jedno ze zobrazení Google Analytics. Je pravděpodobné, že máte specialistu na implementaci, který toto provádí – ale pokud ne, vždy zde dvakrát měřte a jednou řežte. Je snadné tyto věci pokazit (což je také důvod, proč byste měli nastavit svůj účet Google Analytics se sandboxovým zobrazením, abyste si vše nejprve vyzkoušeli).
Chcete-li nastavit filtry, přejděte do části Admin > Filtry > Přidat filtr.
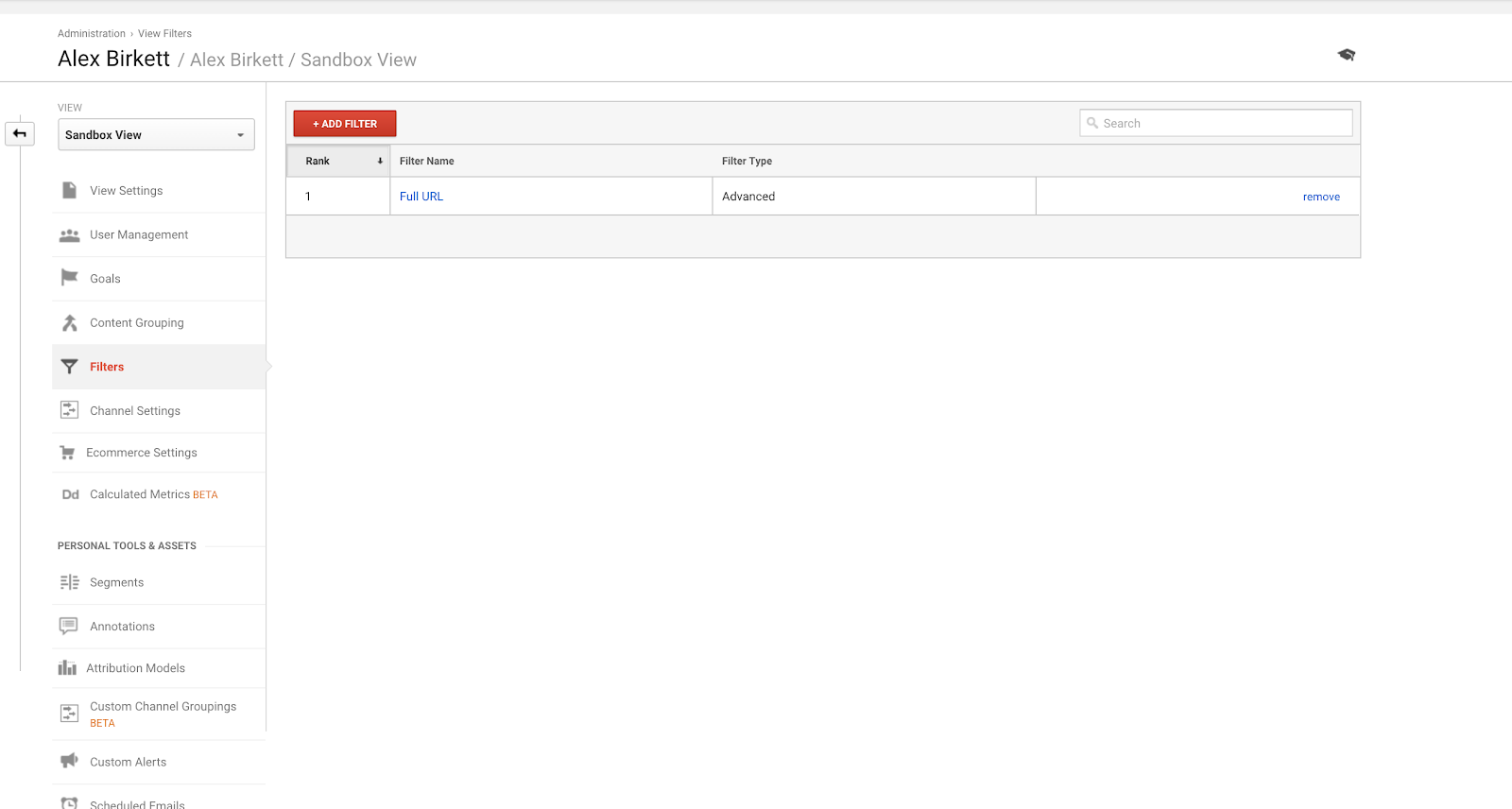
Nejčastěji používaným filtrem používaným v Google Analytics je pravděpodobně vyloučení provozu z vlastní IP adresy (vlastních IP adres).
Pro mnohé to můžete nastavit jednoduše, protože máte pouze jednu IP adresu. U větších společností můžete mít řadu IP adres a vyloučení můžete nastavit snadněji pomocí regexu Google Analytics.
Příklad pokud byste napsali 63\.212\.171\., vyloučilo by to všechny IP adresy od 63.212.171.1 do 63.212.171.9.
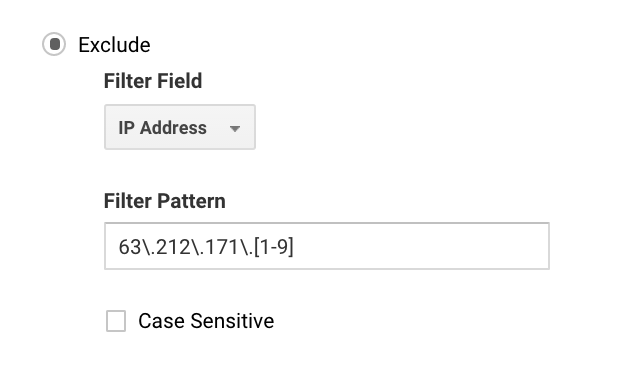
Tento regex Google Analytics vylučuje několik IP adres.
Další věc, kterou můžete udělat s regexem Google Analytics, je nastavit filtry pro čištění parametrů dotazu.
To může být pro analýzu dat nepříjemné i problematické.
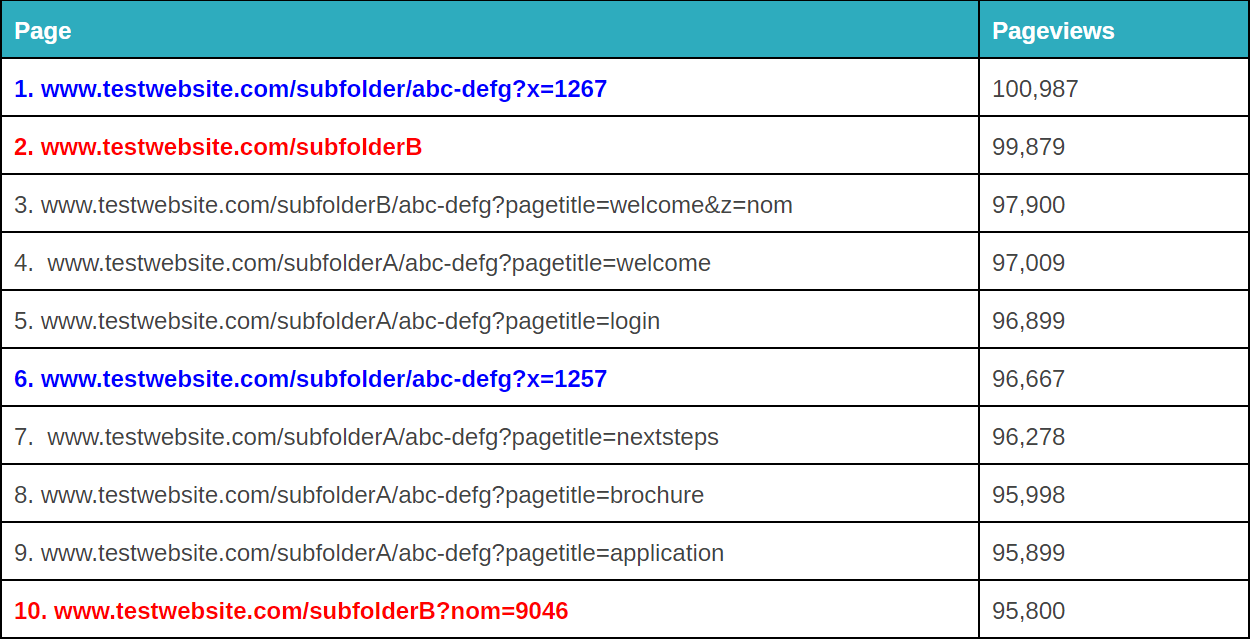
Zlomené parametry dotazu mohou být nepříjemné. – zdroj obrázku
Záleží na tom, jaká je vaše konkrétní situace, ale existuje několik různých způsobů, jak to pomocí regexu vyčistit (poznámka: můžete to udělat také v Google Tag Manageru nebo Excelu, v závislosti na rozsahu problému. Více o tom zde).
Nakonec si řekneme o jednom příkladu, který můžeme použít k lepší organizaci sledování subdomén. Pokud máte více domén nebo subdomén, je možné, že budete mít duplicitní adresy URL, pokud nenastavíte filtr, který předřazuje název hostitele do požadavku URi. Jinými slovy, můžete mít adresy URL:
- site.com/about
- blog.site.com/about
Tyto adresy představují dvě různé stránky (jedna je stránka o vaší společnosti a druhá je sekce about pro váš blog). Obě by se však v Google Analytics zobrazily jako /about, pokud nenastavíte následující filtr (pomocí regulárních výrazů Google Analytics v kombinaci tečka-astrička):
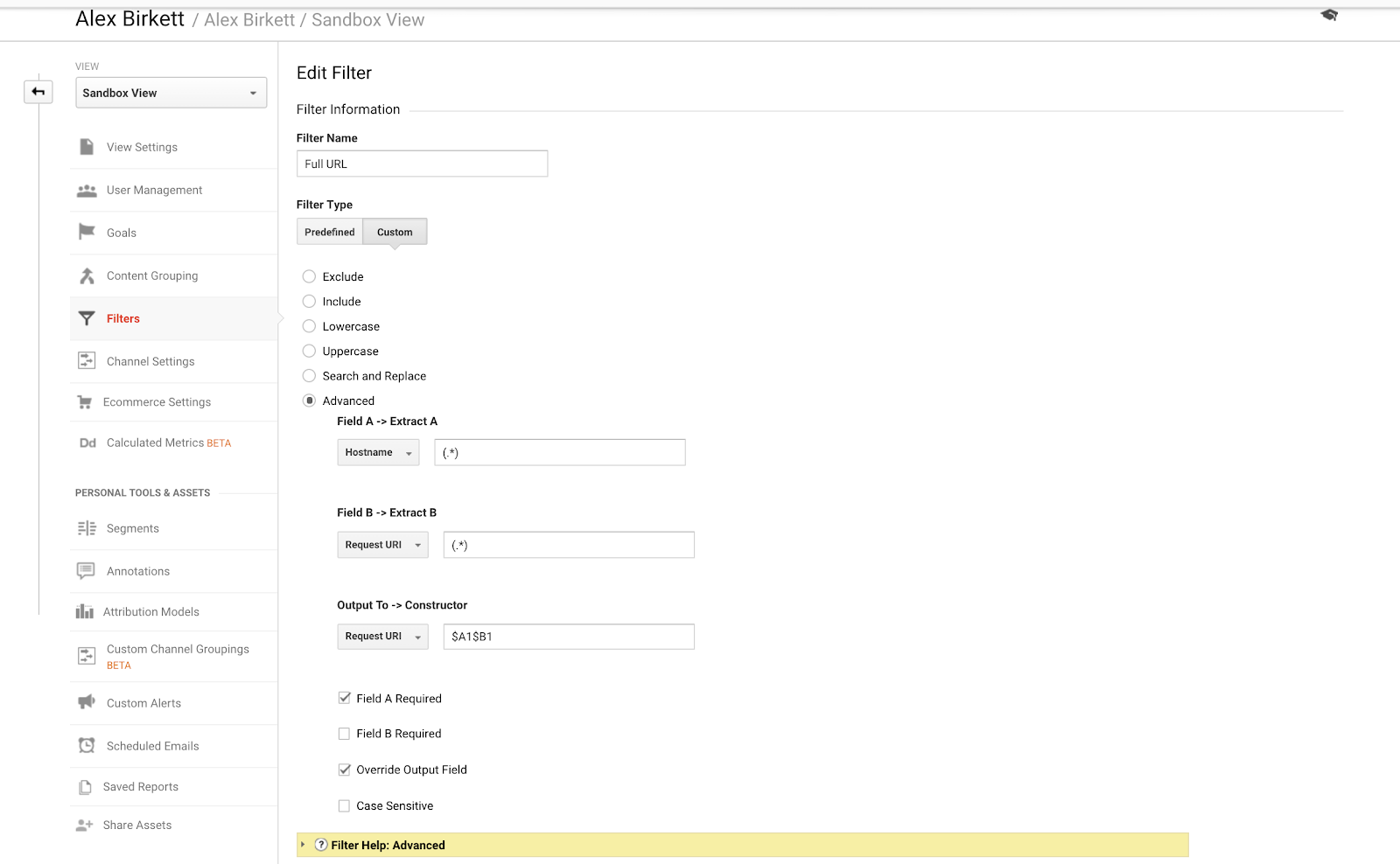
Je poměrně jednoduché nastavit tento základní filtr GA. – zdroj obrázku
Vlastně jsme se již zabývali tím, jak tyto filtry nastavit docela podrobně v předchozím příspěvku KlientBoost o sledování napříč doménami a subdoménami.
Google Analytics RegEx Tips & Chyby, kterým se vyhnout
Regulární výrazy jsou jednou z těch věcí, které prostě musíte praktikovat a zašpinit si ruce, abyste se to naučili. Jako takoví budete dělat chyby.
To je vlastně nejdůležitější rada: vyzkoušejte si věci a zjistěte, zda fungují. V tomto příspěvku jsem uvedl spoustu zdrojů o tom, jak testovat regex, od regex101.com po regexbuddy.com. Ponořte se do těchto zdrojů a používejte je.
S trochou foresite a heuristiky se však můžete naučit rychleji a vychytat více chyb.
Jednou z věcí, kterou se opravdu naučte, je „escape“ v regexu (mluvili jsme o tom u zpětného lomítka). Leho Kraav, technický ředitel společnosti CXL Institute, to vyjadřuje takto:
„Řekl bych „naučte se správně escapovat věci“ – snadno dojde k neshodám, když jsou znaky stejné, ale jejich význam se liší v závislosti na tom, zda jsou escapované, nebo ne.“
Například pokud váš dotaz obsahuje otazník, je to také regulární výraz, takže to musíte dát jasně najevo pomocí zpětného lomítka. Chris Mercer, zakladatel společnosti MeasurementMarketing.io, také říká, že nenaučení se této schopnosti je jednou z největších chyb, které vidí u začátečníků:
„Nejčastější chybou, kterou vidíme u začátečníků používajících regex, je, že zapomínají „escapovat“ regexové symboly. Pokud například hledáte stránky, které odpovídají regexu „thankyou/?success=yes“, nebude to fungovat. Samotný znak „?“ je symbolem regexu a je třeba ho deaktivovat pomocí „escape znaku“ (znak “ \ „. V tomto případě by fungovalo „thankyou/\?success=yes“.“
Další tip? Zachovejte jednoduchost. Lidé se snaží věci komplikovat (podívejte se na nejsložitější regex, jaký jste kdy viděli, napsal ho Leho, zde), ale regulární výrazy jsou „nenasytné“ a budou odpovídat, jak jen to půjde. Google Analytics vydal na blogu příspěvek s tipy a vysvětlil to takto:
„Pokud potřebujete napsat výraz, který bude odpovídat „novým návštěvám“, a jediné možnosti, proti kterým budete odpovídat, jsou „nové návštěvy“ a „opakované návštěvy“, stačí slovo „nové“.
Budou odpovídat všemu možnému, pokud je nedonutíte, aby to nedělaly. Pokud je váš výraz „návštěvy“, bude odpovídat „novým návštěvám“ a „opakovaným návštěvám“. Koneckonců oba obsahují výraz „návštěvy“. Aby byly méně chamtivé, musíte je více specifikovat.“
Začněte tedy pomalu, zjednodušte to a nezahlcujte se složitostí (pravděpodobnost chyby v tomto případě koreluje se složitostí).
Mercer tento bod také opakuje a radí postupovat postupně:
„Když začínáte, soustřeďte se na to, abyste byli dobří… pak se zlepšujte. Je snadné nechat se zahltit všemi různými možnostmi, které vám regex nabízí, ale pokud začnete jen se základy, například zvládnutím symbolu pro „nebo“ (“ | „), rychle získáte zkušenosti a začnete si uvědomovat, co všechno je s regexem možné.“
Závěrečný tip ode mě: naučte se věci googlit. To platí pro jakékoliv programování, ale pro regulární výrazy obzvlášť. Věci budete zapomínat, a pokud nepíšete regex denně, nemá smysl se všechno učit nazpaměť. Naučte se věci vyhledávat a hledat odpovědi na to, co se snažíte udělat.
Mimo Google Analytics: RegEx pro další marketingové využití
Regex je také něco, čím by se měli zabývat všichni odborníci na SEO. Jednak samozřejmě proto, že SEO a digitální analytika (např. Google Analytics) jsou spolu neoddělitelně spjaty. Zadruhé proto, že některé ze stejných odpovídajících výrazů, které píšeme pro filtrování a porovnávání znaků v datech služby Google Analytics, lze použít také při získávání dat pro taktiku SEO.
Jinými slovy, regulární výrazy jsou důležité pro škrábání webu.
V případě škrábání webu a SEO budete obvykle pracovat prostřednictvím programovacího jazyka, jako je Python, ale principy jsou stejné.
Jako příklad můžete seškrábat veškerý tučně vyznačený text na stránce pomocí tohoto:
<strong>(+)</strong>
Nebo, jak je uvedeno v tomto článku SEJ, pokud by někdo seškrábal ESPN pro všechny autory, mohl by napsat toto:
„sloupkař“:“(.*?)“
V zájmu ucelenosti a zdravého rozumu se nebudu pouštět až do pokročilého webového scrapování. Stačí vědět, že regex je důležitý i v této oblasti. Pokud byste se však chtěli dozvědět více, doporučuji tyto zdroje:
- Web Scraping with Regular Expressions
- Scraping with Regular Expressions (Stanford)
- How to Use Regex for SEO & Website Data Extraction
Regulární výrazy vám také pomohou pracovat s daty pro SEO nejen při scrapování webu. Regex můžete například použít k dalšímu přizpůsobení způsobu, jakým používáte Screaming Frog.
Jenny Halasz uvedl dobrý příklad použití regexu k vyčištění dat v příspěvku na Search Engine Land:
„Řekněme například, že máte seznam adres URL a potřebujete je rozdělit pouze na TLD (Top Level Domain).
Můžete použít jednoduché vyhledání/nahrazení pro http a www, ale jak snadno vyřadit všechny názvy souborů? Můžete je všechny odstranit ručně, ale to je otrava. Pomocí jednoduchého zástupného znaku regex (/*) můžete odstranit lomítko a vše, co následuje za ním.“
O regulárních výrazech pro SEO a web scraping bychom mohli mluvit donekonečna, ale já jen odkážu na několik dobrých zdrojů pro případ, že byste se chtěli dozvědět víc (je to koneckonců velmi univerzální jazyk s mnoha případy použití mimo analytiku):
- Jak regulární výrazy ovlivňují SEO
- 5 výkonných úžasných triků přesměrování Htaccess
- Jak používat regulární výrazy pro segmentaci zpráv
Závěr
Regulární výrazy Google Analytics by měl znát opravdu každý analytik, i když se nepovažujete za technické. Kromě toho znalost některých regulárních výrazů (nebo alespoň toho, jak hledat odpovědi a aplikovat je na správné problémy) může pomoci i marketérům při různých činnostech.
Jen podotýkám, že to není příliš běžná dovednost, takže svými nově nabytými technickými marketingovými dovednostmi pravděpodobně ohromíte některé kolegy.
Takže vás vyzývám, začněte se učit, a co je důležitější, prostě začněte používat regulární výrazy prakticky. Nejsou tak děsivé.