Google Analytics regex (dvs. reguljära uttryck) är en underskattad färdighet set.
Om du vill göra någon form av filtrering eller målinriktning bortom grunderna, ett bra grepp på regex kommer att ge dig Analytics superkrafter.

Regex ger dig superkrafter. – image source
Självklart har reguljära uttryck mycket bredare användningsområden än analys och marknadsföring. Men i den här artikeln kommer vi att täcka några taktiska användningsfall som kan hjälpa dig med användarinsikter, dataorganisation och till och med avancerade användningsfall för målinriktning och sökmotormarknadsföring.
Men först ska vi kortfattat sammanfatta vad reguljära uttryck är, särskilt i förhållande till Google Analytics.
- Google Analytics RegEx: Vad är det?
- Google Analytics RegEx Cheat Sheet
- Pipe (|)
- Backslash (\)
- Karett (^)
- Dollartecken ($)
- Punkt (.)
- Asterisk (*)
- Punkt-Asterisk-kombination (.*)
- Plustecken (+)
- Frågastecken (?)
- Parenteser ()
- Kvadratparenteser ()
- Dashes (-)
- Kurliga parenteser ({ })
- Google Analytics RegEx: Specifika exempel som du kan använda
- Google Analytics RegEx Tips & Misstag att undvika
- Utomhändertagande av Google Analytics: RegEx för andra marknadsföringsändamål
- Slutsats
Google Analytics RegEx: Vad är det?
Reguljära uttryck är speciella textsträngar för att beskriva sökmönster.
Hur sa?
I förhållande till analys hjälper reguljära uttryck dig att hitta, definiera och extrahera saker. Ännu mer specifikt, med Google Analytics, kan de hjälpa dig att skapa mer flexibla definitioner för saker som visningsfilter, mål, segment, målgrupper, innehållsgrupper och kanalgrupperingar.
I grund och botten är de fördefinierade tecken eller serier av tecken som på ett brett eller snävt sätt matchar och väljer ut mönster i dina digitala analysdata. De är ett allmänt verktyg som kan användas på många sätt (massor av programmeringsspråk och verktyg tillåter regex). Men i Analytics kommer vi främst att använda dem för att matcha mönster i data.
Det är förstås inte bara användbart i Analytics. Särskilt om du använder Google Tag Manager eller om du kör komplicerad målinriktning i dina A/B-tester kommer du att använda mycket regex. Som Chris Mercer, grundare av MeasurementMarketing.io, säger:
”Vi använder regex dagligen. Det hjälper oss att tydligt definiera allt från trattsteg i ett Google Analytics-mål till specifika utlösare i Google Tag Manager.”
Och om du vill göra en djupdykning och verkligen lära dig reguljära uttryck finns här några resurser (inte nödvändigt för grundläggande saker i Google Analytics, och troligen för någon som är mer tekniskt kunnig):
- Regulära uttryck: The Complete Tutorial
- Mastering Regular Expressions 3rd Edition (Book)
- Learn Regular Expressions the Hard Way
Du kan också lära dig interaktivt genom något som RegexOne eller RegexR, som båda är coola. Men låt oss gå förbi det och gå igenom de vanligaste Google Analytics-regex-tecknen, så att du kan börja använda dem.
Google Analytics RegEx Cheat Sheet
Se följande Google Analytics-regex-tecken som ett slags fusklapp – du kommer förmodligen inte att använda dem direkt, men om du kortfattat går igenom vad du kan göra med regex kan du leta efter svaret när det är nödvändigt.
För en kort sammanfattning har jag inte hittat något mer komprimerat och rakt på sak än den här guiden:

En mycket kortfattad guide till Google Analytics regex – bildkälla
Hur som helst kan du dock konstatera att den, med enbart den som referens, är lite vag och otydlig. Så låt oss gå igenom de vanligaste Google Analytics-regexen och samtidigt visa motsvarande användningsfall.
Pipe (|)
När du vill säga ”ELLER” ska du använda ett pipe (|). Som i ”This | That” som skulle betyda ”This OR That”.
Om du är en flitig användare av Google Analytics-segment är du redan van vid att använda logiska operatorerna OR.
Detta är ett av de enklare och vanligare reguljära uttrycken som används i Google Analytics. Det har många användningsområden, men ett av de mest använda kan vara när du ställer in mål. Om du har två tacksidor med olika webbadresser (/thank-you/ och /subscription-confirmed/), men vill spåra båda sidorna som ett slutfört mål, kan du använda det här reguljära uttrycket.
Du kan också använda det i filter. Säg att du vill visa en beteenderapport för två artiklar (om Content Marketing Lessons och Content Analytics), med URL:erna /content-marketing-analytics/ och /content-marketing-lessons/. Du kan skriva ”content-marketing-analytics|content-marketing-lessons” som ett filter och bara få fram dessa artiklar.
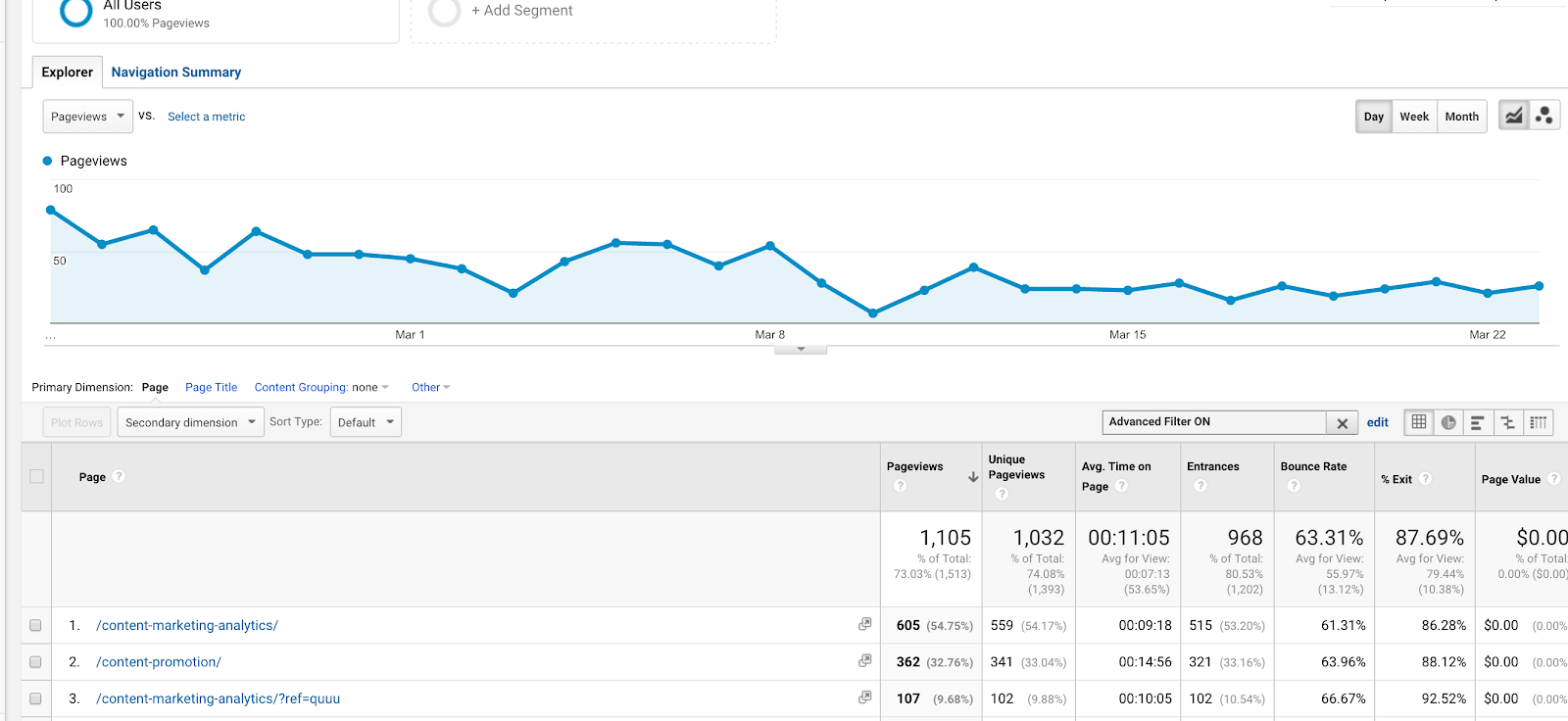
Användning av ett pipe (|) i ett filter för att få resultat för två separata blogginlägg
Backslash (\)
Backslash (\) är ett annat rakt och vanligt förekommande reguljärt uttryck i Google Analytics. Det betyder ”betrakta nästa tecken som vanlig text och inte som regex.”
Med andra ord finns det många reguljära uttryck som förekommer i vanlig text, t.ex. punkt, frågetecken och andra, som vi måste klargöra om de ska läsas som reguljära uttryck eller som vanlig text.
En vanlig frågeteckensträng på nätet används när någon söker efter något på din webbplats. När jag till exempel söker efter ”small dog toys” (små hundleksaker) på petsmart.com är detta den söksträng som kommer upp:
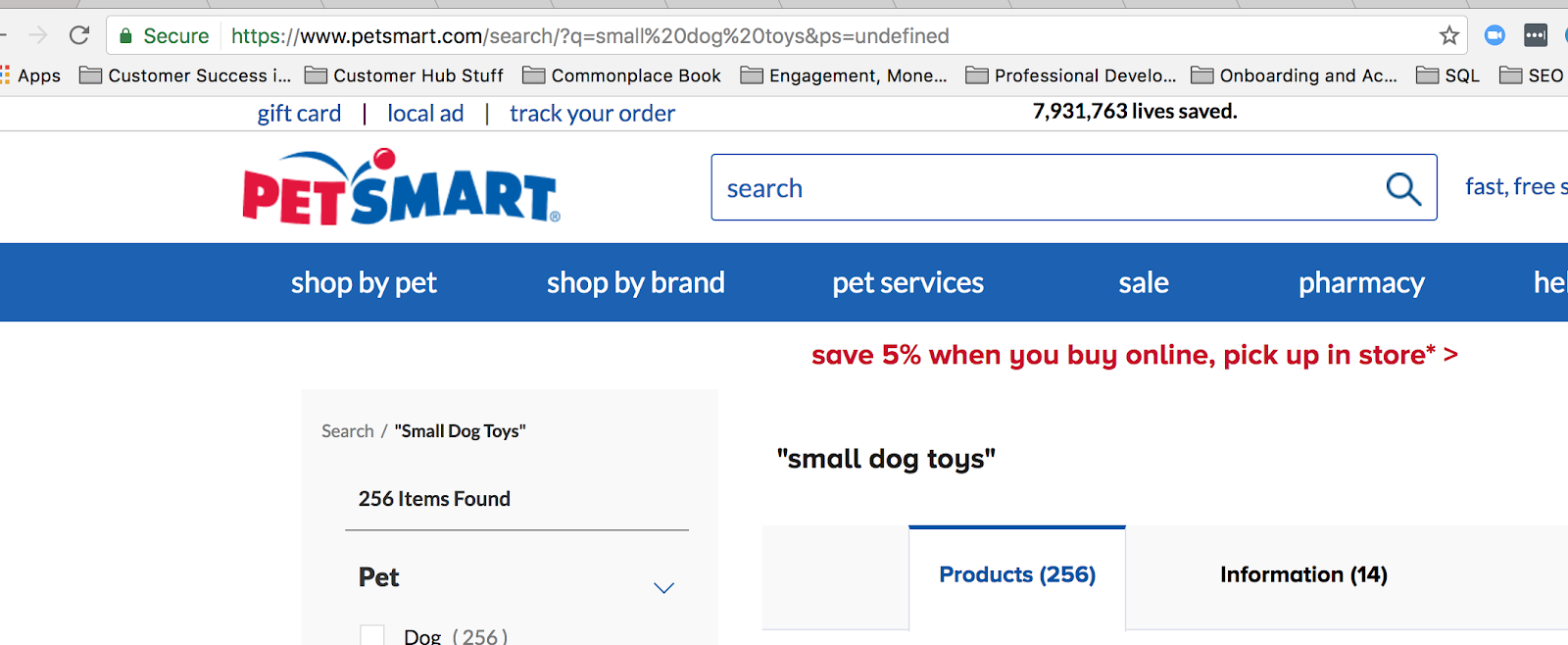
När du använder sökning på webbplatsen skapar du en söksträng i webbadressen.
Frågemärket här innebär att en sökning på webbplatsen har ägt rum, men frågetecknet är också ett vanligt förekommande reguljärt uttryck i Google Analytics. Därför måste vi förtydliga när vi använder ett backslash att frågetecknet i det här fallet ska läsas som vanlig text.
Säg att vi vill matcha alla söksträngar i Google Analytics som börjar med /search/?q= (eftersom det innebär en sökning). Då skulle det reguljära uttrycket vara:
search\/\?q=
Du kan kontrollera detta med hjälp av en debugger som regex101.com:
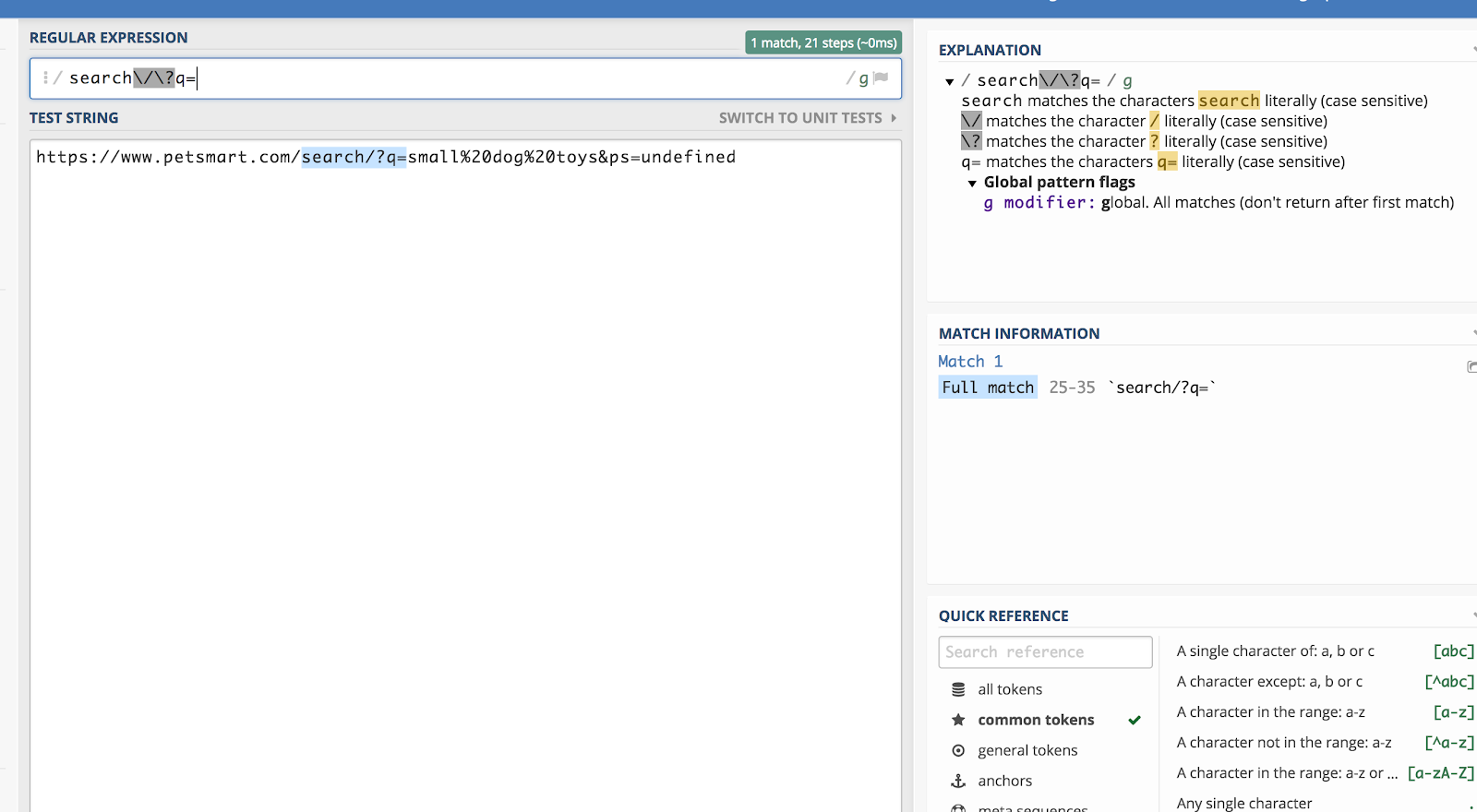
Backslash (\) ”undslipper” från regex för ett tecken efteråt och läser det som vanlig text.
Karett (^)
Karett (^) betyder att en fras börjar med något. Detta är viktigt när du har en fras som kan förekomma var som helst, men du vill specifikt matcha frasen vid startpunkten. Titta till exempel på det här exemplet med några olika fraser som innehåller orden ”Uppdrag: lyckat.”
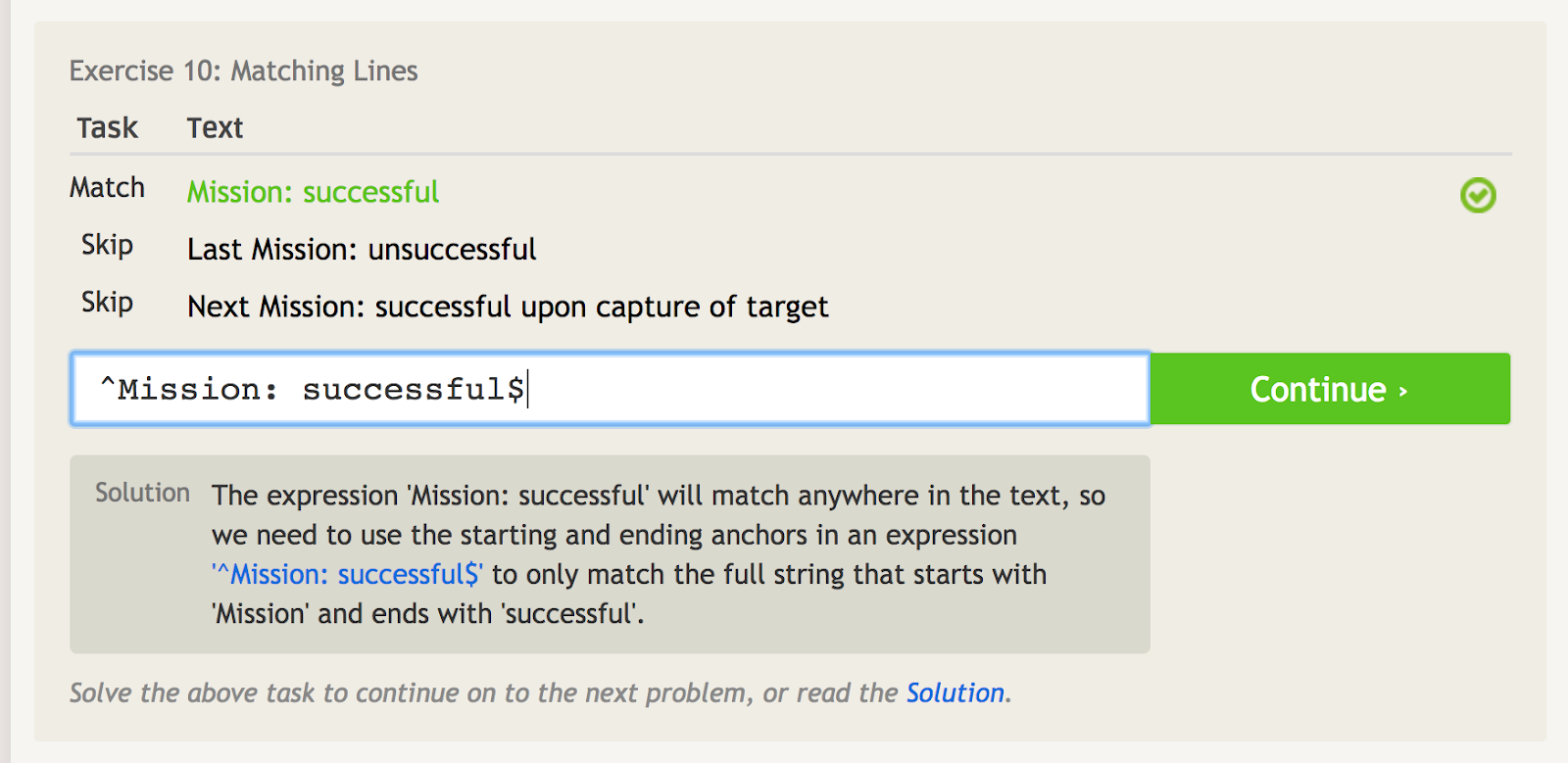
Den caret signalerar startankaret, så vi kan enbart matcha den första frasen här.
Vad sägs om att du har ett gäng AdWords-kampanjer som alla börjar med samma fras (eftersom du är en dålig planerare för framtiden):
- Freemium Campaign Final
- Vår första Freemium Campaign
- Kreativt Freemium Campaign-erbjudande
- Test Freemium Campaign
Du vill skriva ^Freemium Campaign för att matcha den första kampanjen och ingen av de andra.
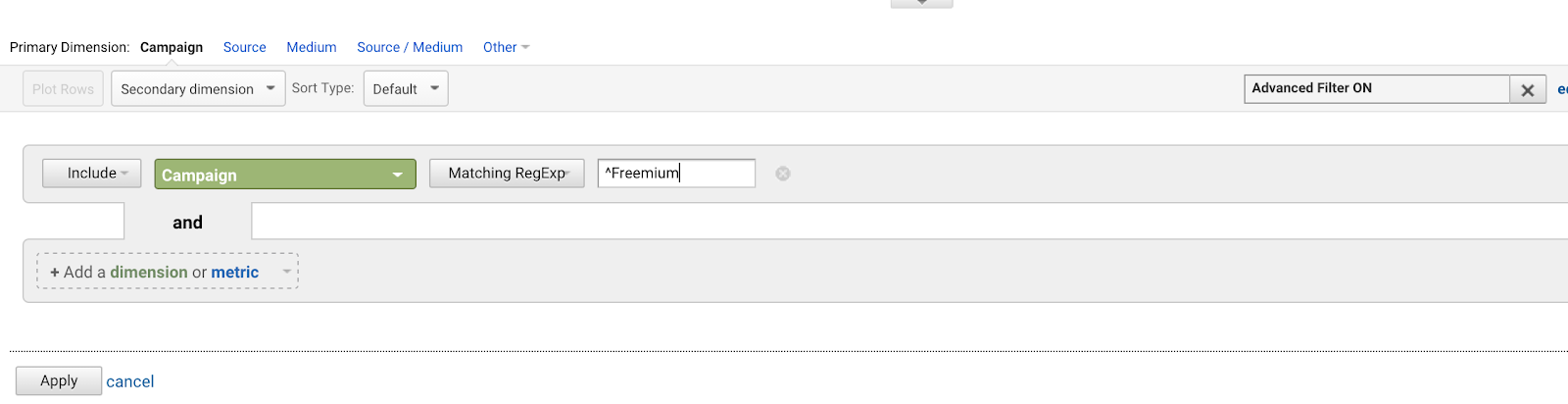
Användning av karet (^) matchar strängar som börjar med dessa tecken
Dollartecken ($)
Dollartecken ($) betyder att en fras slutar med något.
När du kombinerar de två kan du rikta in dig på fraser som matchar exakt.
Om du lanserade en kampanj med titeln ”paidacquisitionfb” och senare en kampanj med titeln ”paidacquisitionfb-2” för att du inte planerade bra och trodde att du skulle ha andra kampanjer med liknande titlar (händer hela tiden), kan du isolera den första genom att skriva:
^paidacquisitionfb$
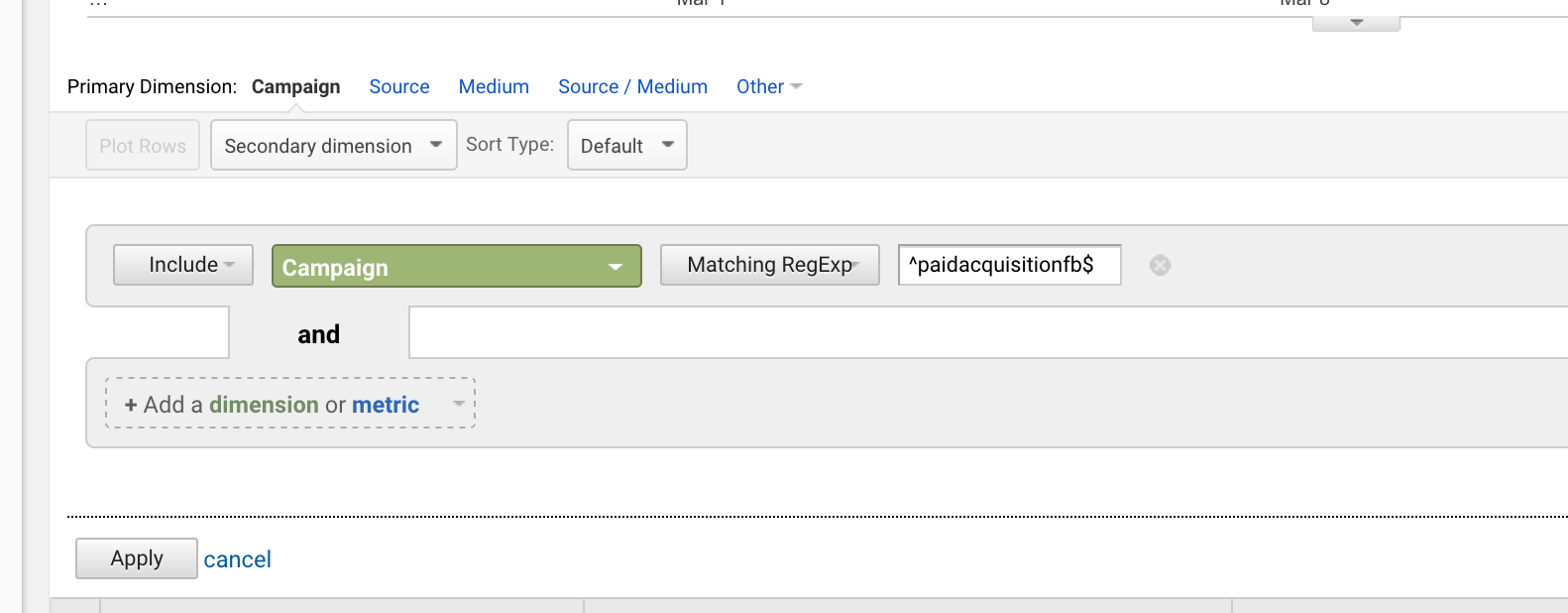
Det är mycket vanligt att använda carett och dollar tillsammans.
Om du till exempel har massor av kategorisidor på din blogg, och alla slutar på ett sidnummer, kan du skriva ett enkelt stycke Google Analytics-regex för att endast visa bloggens kategorisidor (^/page/*/$). Detta skulle ge dig listor som:
- /page/1
- /page/2
- /page/3
…och så vidare.
Punkt (.)
Punkt (.) matchar vilket tecken som helst, vilket innebär vad som helst på tangentbordet: siffror, bokstäver, till och med blanksteg. Det är inte superanvändbart i sig självt, men det används hela tiden tillsammans med andra reguljära uttryck, särskilt asterisken (kommer härnäst).
Säg att du vill använda det i sig självt, och låt oss använda exemplet ”ki…”. Det skulle matcha allt som börjar med bokstäverna K och I, och sedan de två följande tecknen, vilka de än är.
Så om du hade en sträng som innehöll orden kill, kind, kiss, kin, kid!, och kit, skulle det matcha dem alla. Vänta, vad är det? Ja, den skulle matcha ”kit” och ”kin” så länge det finns ett mellanslag efteråt (den plockar upp vitrymden också). Enligt samma logik skulle den också ta upp utropstecknet i ”kid!”
Du kan se varför det blir rörigt om du bara använder den här.
Här är en illustration av ovanstående exempel med Regex101.com:
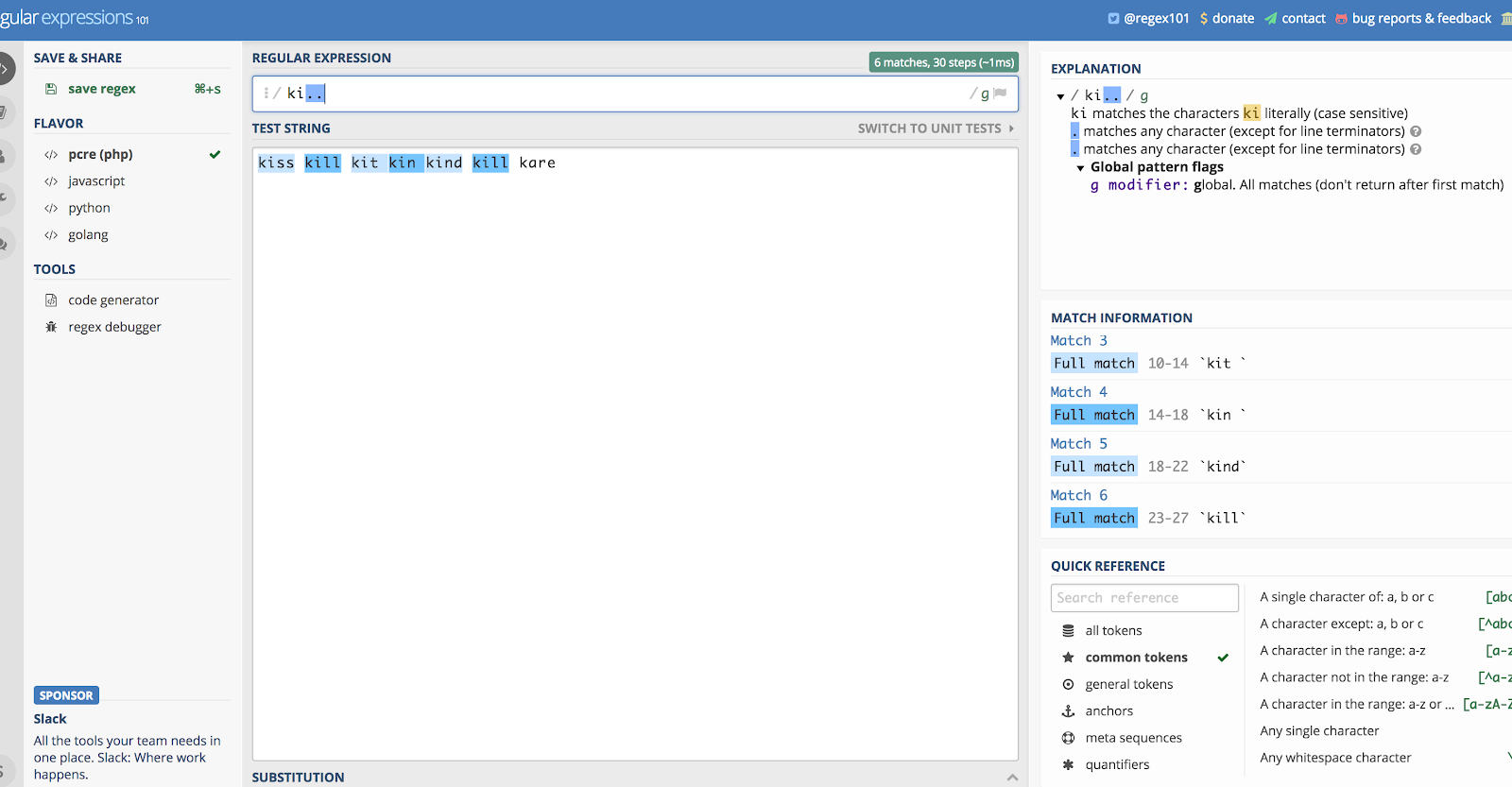
Punkten (.) matchar det mesta.
Asterisk (*)
Asterisken (*) matchar noll eller flera av de föregående punkterna. Det är lite förvirrande när man säger det så här, så jag ska bara använda ett exempel.
Håller du ihåg den där ”wazzup”-reklamen från Budweiser för ett tag sedan? Det skulle vara ganska svårt att gissa hur någon skulle stava den frasen om de sökte efter den (till exempel på YouTube). Men du skulle teoretiskt sett kunna kapsla in alla stavningsvarianter genom att göra så här:
waz*up
Här är en illustration av hur det fungerar i regex101:
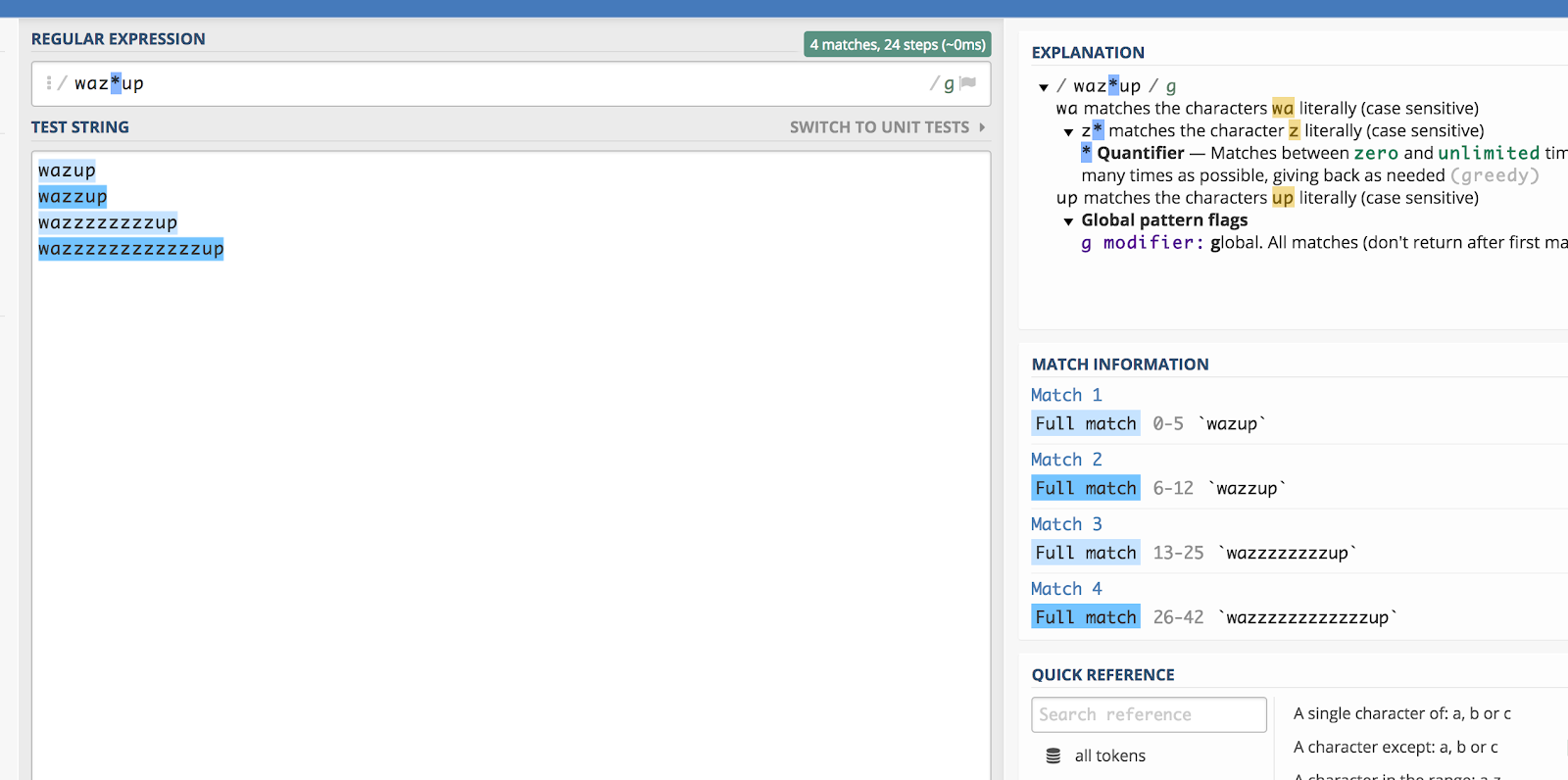
Asterisken (*) matchar det föregående tecknet noll eller fler gånger.
Om du vill vara superprecis och ta hänsyn till stora och små bokstäver kan du skriva något liknande:
*
Men jag avviker.
Där asterisken faktiskt är mest kraftfull och används oftare är med en punkt eller som en del av andra regex-kombinationer.
Punkt-Asterisk-kombination (.*)
Punkt-Asterisk-kombinationen (.*) betyder i princip att allt är tillåtet. Den används mycket ofta.
Den här kombinationen använder du när du vill matcha vad som helst i en sträng. Eftersom pricken betyder att matcha vilket tecken som helst och * betyder att matcha noll eller fler tecken före det, är den här kombinationen mycket kraftfull.
Exempel: Du har flera olika typer av kundkonton, men du vill se dina data för dem alla. De har alla liknande sidor, så dina sidor ser ut ungefär så här:
/customer/pro/login/
/customer/free/login/
/customer/starter/login/
Du kan skriva följande regex för att göra det:
/customer/.*/login
Jag använder vanligen det här Google Analytics-regex-uttrycket för att ställa in segment för användare med ett användar-ID.
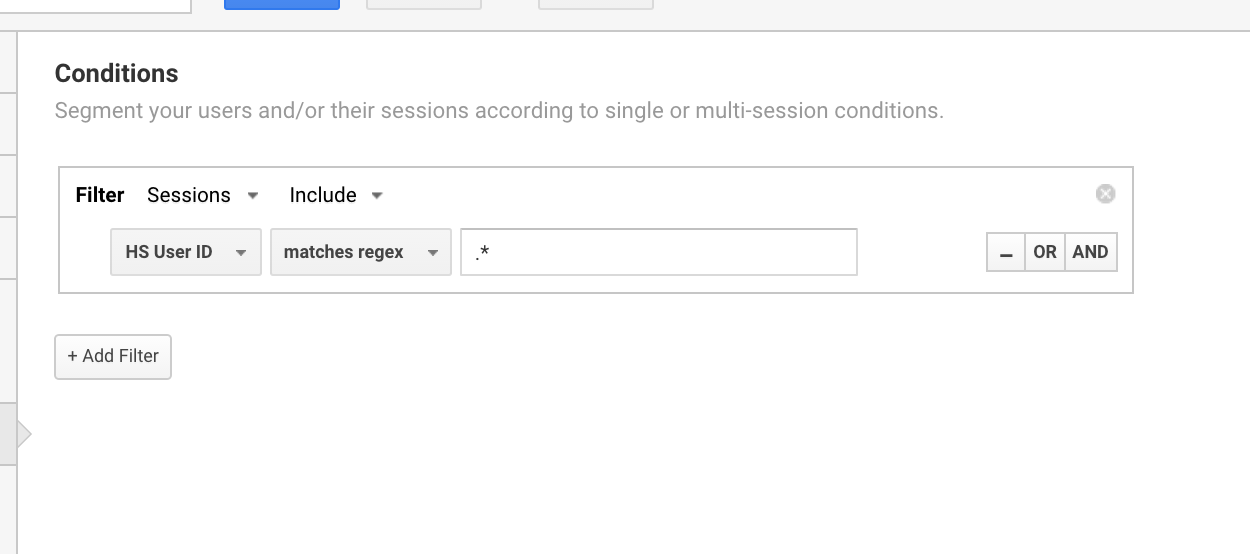
Användning av Google Analytics-regex för att isolera alla sessioner som har ett användar-ID.
Plustecken (+)
Plustecknet (+) liknar i hög grad *, med den skillnaden att det matchar ETT eller flera av de föregående tecknen. Det finns inte mycket mer som behöver sägas om detta, bara att det skiljer sig mycket lite från asterisken. Här är skillnaden:
Föreställ dig att du har orden: hello, hhello och hhhello.
Om du skriver hh+ello matchar det bara de två andra, men om du skriver hh*ello matchar det alla.
Minor skillnad. I verkligheten använder jag nästan alltid asterisken i stället för plustecknet.
Frågastecken (?)
Frågastecken (?) är en enkel fråga. Det betyder helt enkelt att det sista tecknet är alternativ.
Säg att du inte bryr dig särskilt mycket om huruvida ordet är i plural eller inte (som med skor). Det kan vara ”sko” eller ”skor” och du vill fånga det på båda sätten. Då kan du skriva ”shoes?”
Här är ett exempel med mitt namn. Om någon stavade det ”Alex Birket” under en sökning på en webbplats skulle jag förmodligen fortfarande vilja se det. Så jag kan skriva:
Alex Birkett?
Så här ser det ut i regex101.com:
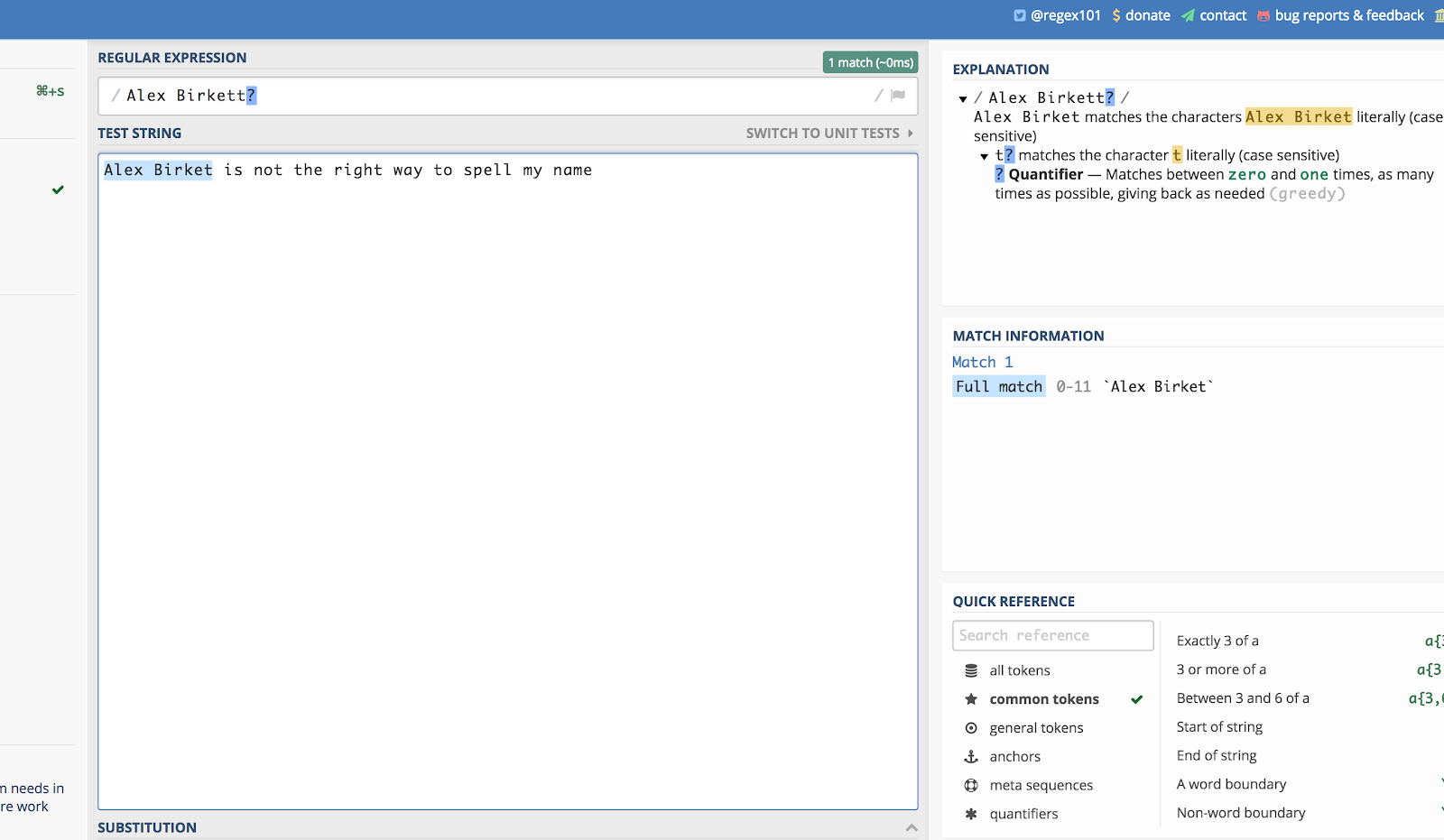
Frågetecknet (?) gör att det sista tecknet som föregår det är valfritt.
Parenteser ()
Parenteser fungerar på samma sätt som de gör i matematik. De talar om för dig att du ska prioritera och isolera den logik som det är på spel inuti dem.
Säg att du har ett SaaS-företag med tre erbjudanden och att du vill matcha alla dina prissidor. Dina webbadresser är följande:
site.com/products/meetings/pricing
site.com/products/crm/pricing
site.com/products/email/pricing
För att fånga upp alla tre kan du använda ett reguljärt uttryck som detta:
^/products/(meetings|crm|email)/pricing$
Kvadratparenteser ()
Kvadratparenteser () skapar en lista. Om du har tre strängar, ”thing1”, ”thing 2” och ”thing3”, kan du matcha dem alla genom att skriva ”thing” eller ”thing” (mer om streck om en stund – de används vanligen tillsammans med hakparenteser.
Häckparenteser kan användas för att matcha flera iterationer av ett ord eller en sträng, samtidigt som man utesluter flera andra iterationer. Om du till exempel vill matcha ”can”, ”man” och ”fan”, men inte ”dan”, ”ran” eller ”pan”, kan du använda följande regex för att göra det:
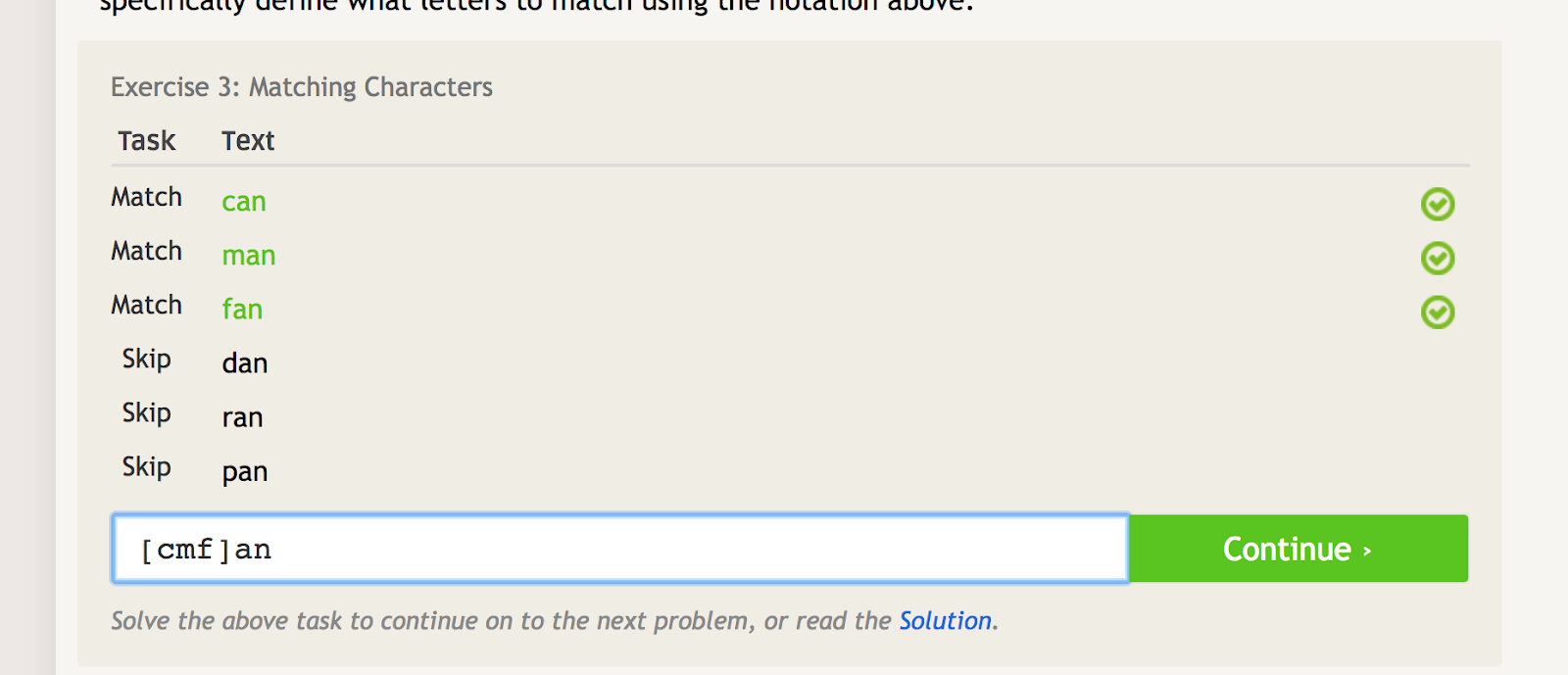
Vad gäller de fyrkantiga parenteser som skapar flera matchningsvillkor beroende på vilka tecken du sätter i dem. – image source
Detta är något du kan använda om du har några olika produkter med liknande namn, som ”shoes1”, ”shoes3” och ”shoes5”. Du kan matcha dessa, och inget annat, med hjälp av ”shoes”
Dashes (-)
Dashes (-) fungerar för att skapa linjära listor över objekt.
När du använder hakparenteser behöver du inte bara räkna upp allting om det förekommer linjärt. Så om du vill matcha en sträng av siffror där den sista kan vara vad som helst från noll till nio kan du skriva så här:
1234
Och du kan skriva det mycket enklare:
1234
Detta fungerar även för bokstäver. Låt oss föreställa oss att du har en sidkategori som slutar på två slumpmässiga bokstäver. Något liknande:
/page-aa/
Du kan matcha alla dessa genom att skriva:
/page-*/
Du kan se ett exempel på det på regex101 här:
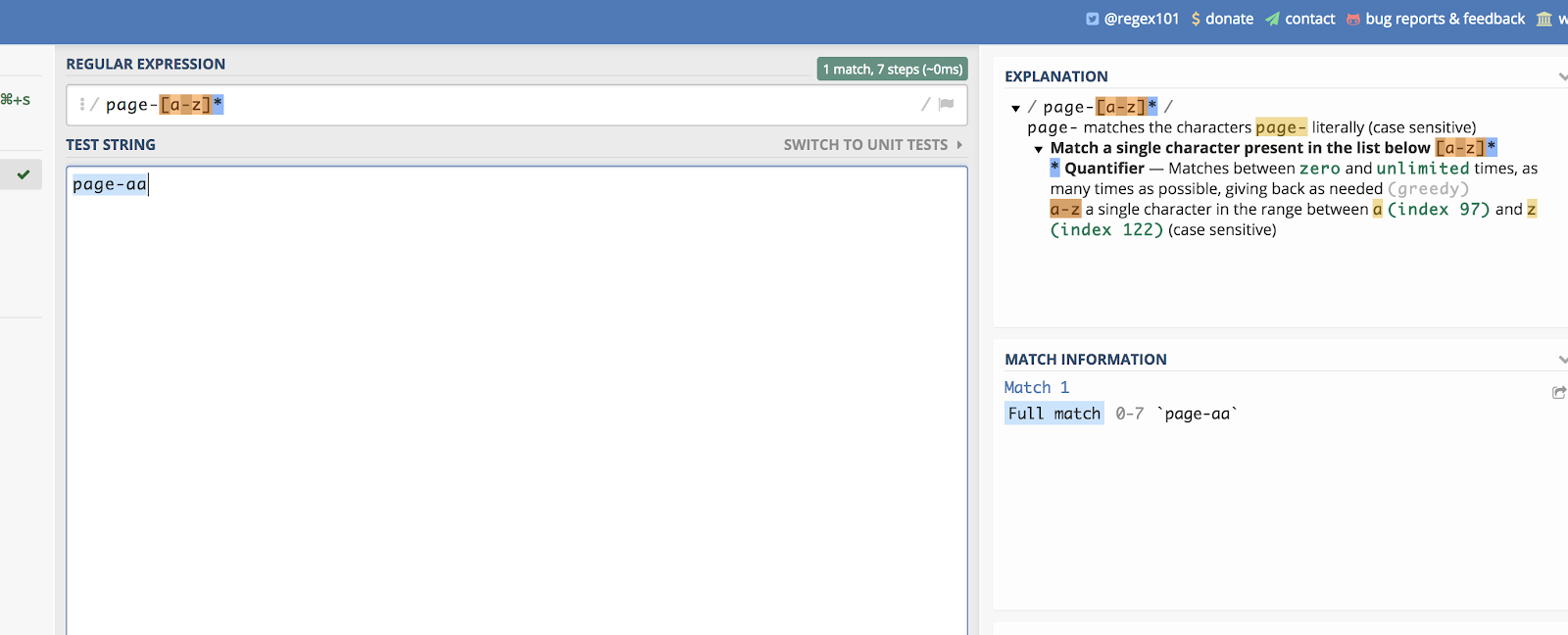
Tryck hjälper dig att skapa en linjär lista för att matcha.
Kurliga parenteser ({ })
Kurliga parenteser ({}) anger hur många gånger du ska upprepa den sista punkten.
Om du till exempel vill matcha endast ”wazzzzzzup” kan du använda ”waz{4}up”.
Men om du vill matcha ”wazzzzzzzup” och ”wazzzup” men inte ”wazup” kan du använda ”waz{3,5}up”. Detta säger i princip att man ska matcha tecknet ”z” inte mindre än 3 gånger, men inte mer än 5 gånger.
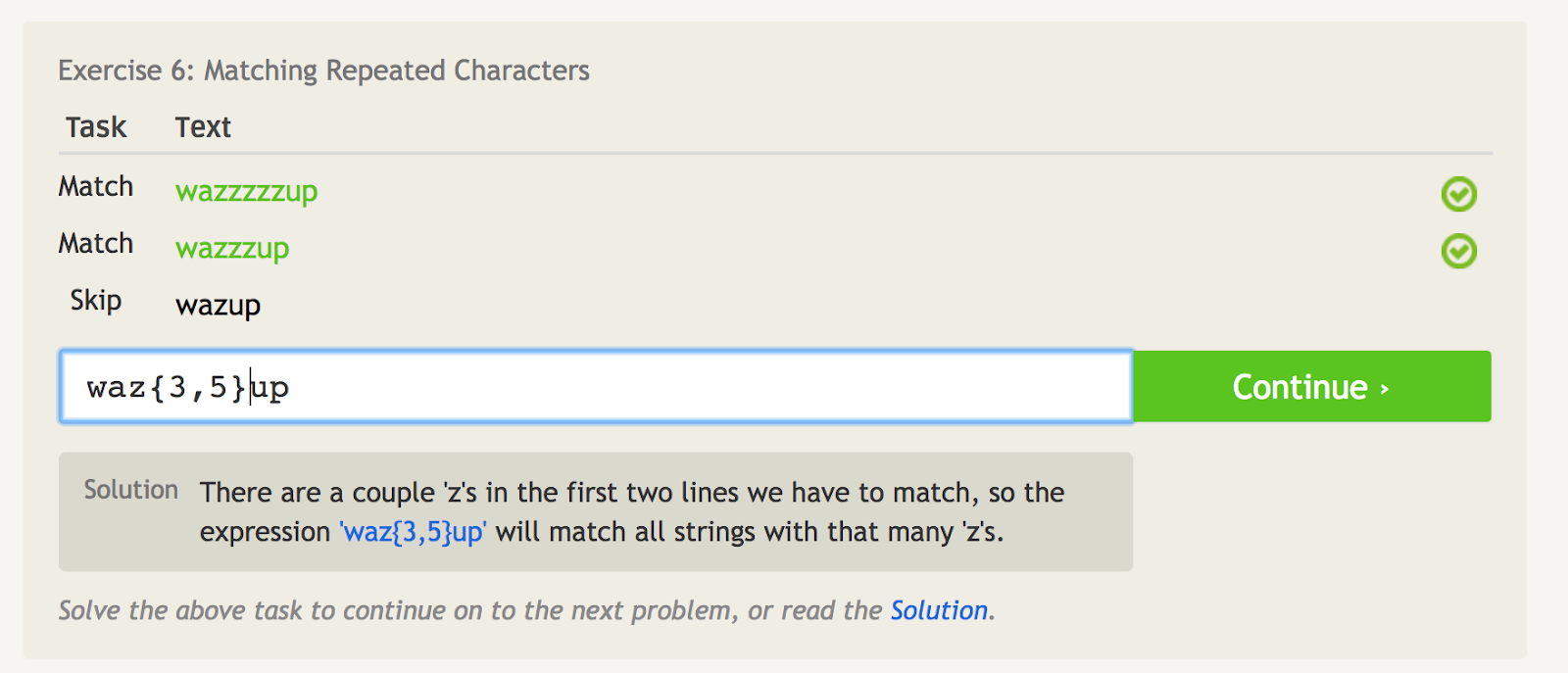
De krusade parenteserna talar om hur många gånger du ska upprepa den sista punkten. – bildkälla
Jag har egentligen inte använt det här reguljära uttrycket särskilt mycket i Google Analytics, men ett vanligt användningsområde kan vara för postnummer. Vanligtvis är de två första tecknen samma i en stad (78- för Austin, TX, till exempel). Så du kan matcha alla postnummer i Austin, TX genom att skriva:
78{3}
Detta säger att de tre sista bokstäverna kan vara vilket slumpmässigt tal som helst från noll till nio.
Google Analytics RegEx: Specifika exempel som du kan använda
En av de vanligaste användningsområdena för Google Analytics regex är att bygga upp filter. Låt oss gå igenom tre exempel, ett enkelt och ett lite mer komplicerat.
Först ett exempel inspirerat av ett bra inlägg på Search Engine Land av Jenny Halasz.
Säg att du har en rörig webbplatsarkitektur, men du vill titta på alla inlägg med en viss underkatalog. Det kan vara vad som helst, till exempel en kategori eller typ av innehåll. I det här exemplet letar vi efter en kategori på webbplatsen för /music/, men bara i den tredje underkatalogen. I det här fallet kan du skriva ^/.*/.*/.*/music/.* så får du den rapporten.

Denna Google Analytics-regex visar dig endast /music/ i den tredje underkatalogen. – image source
Det ser förvirrande ut vid en första anblick – men efter att ha lärt sig vad dessa reguljära uttryck betyder är det ganska okomplicerat. I grund och botten säger vi bara till GA att matcha landningssidor som börjar med (^) ett snedstreck, sedan alla tecken (.*), sedan ett snedstreck, sedan alla tecken (.*), sedan ett snedstreck och sedan musik.
LawnStarter använder en liknande taktik för rapportering. Deras strategi är att skapa stadsspecifikt innehåll i denpå en undermapp till deras stadssidor, med följande format:
https://www.lawnstarter.com/{{transaktionell stadssida }}/{{informationellt innehållsstycke }}
För att filtrera bort innehållet från omvandlingstrattar och trafikrapportering använder de följande regex, enligt grundaren Ryan Farley.
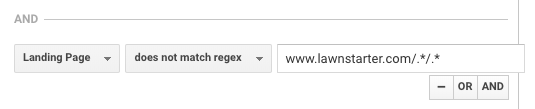
Denna regex hjälper LawnStarter att matcha stadsspecifikt innehåll på sin webbplats.
För det andra går vi igenom hur du ställer in ett filter för en av dina Google Analytics-vyer. Det är troligt att du har en implementeringsspecialist som gör detta – men om inte, mät alltid två gånger och skär en gång här. Det är lätt att ställa till det här (vilket också är anledningen till att du bör konfigurera ditt Google Analytics-konto med en sandlåda-vy för att prova saker och ting först).
För att konfigurera filter går du till Admin > Filters > Add Filter.
Det vanligaste filtret som används i Google Analytics är förmodligen att utesluta trafik från dina egna IP-adresser.
För många är det enkelt att ställa in detta eftersom du bara har en IP-adress. För större företag kanske du har en rad olika IP-adresser, och då kan du ställa in uteslutningar enklare med Google Analytics regex.
Om du till exempel skriver 63\.212\.171\. skulle det utesluta alla IP-adresser från 63.212.171.1 till 63.212.171.9.
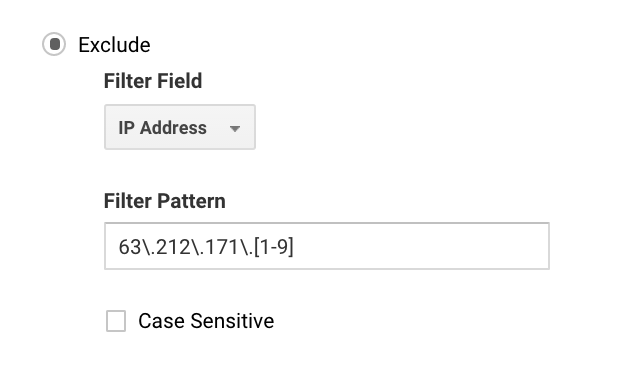
Detta Google Analytics-regex utesluter flera IP-adresser.
En annan sak du kan göra med Google Analytics-regex är att sätta upp filter för att rensa upp i frågasparametrar.
Detta kan vara både irriterande och problematiskt för din dataanalys.
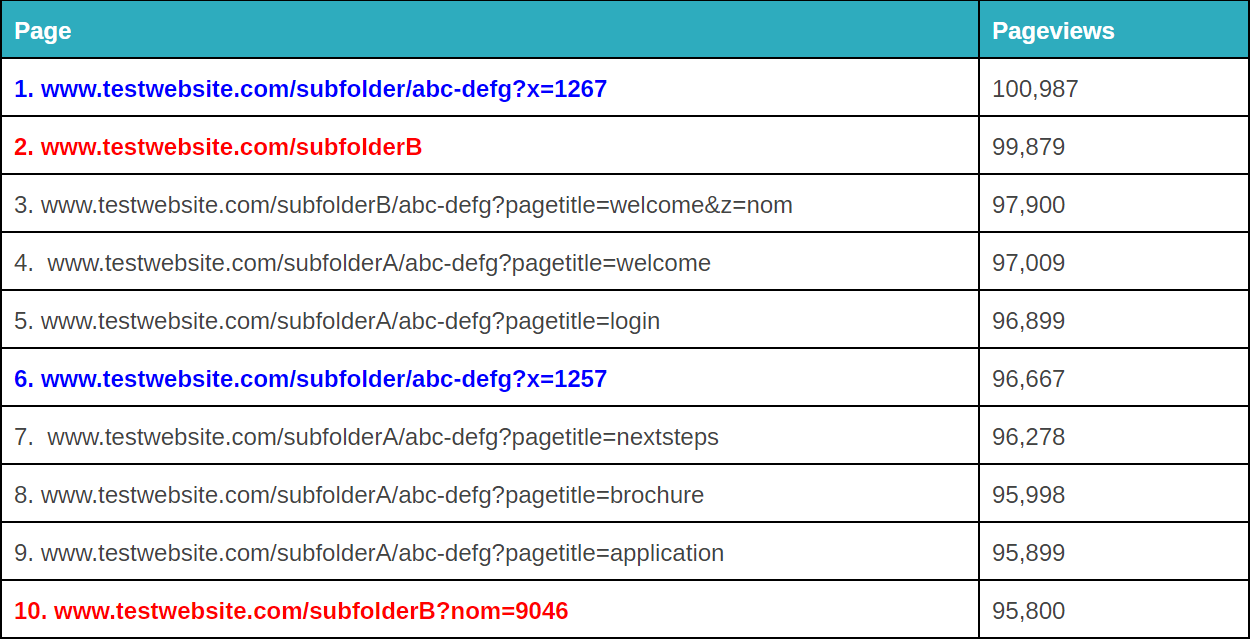
Frakturerade frågeparametrar kan vara irriterande. – image source
Det beror på hur din specifika situation ser ut, men det finns några olika sätt som du kan använda regex för att städa upp det (observera: du kan också göra detta i Google Tag Manager eller Excel, beroende på problemets omfattning. Mer om det här).
Slutligt ska vi prata om ett exempel som vi kan använda för att bättre organisera vår spårning av underdomäner. Om du har flera domäner eller underdomäner är det möjligt att du får dubbla webbadresser om du inte ställer in ett filter för att prependiera ditt värdnamn till din begäran URi. Med andra ord kan du ha följande URL:
- site.com/about
- blog.site.com/about
Dessa representerar två olika sidor (den ena är en sida om ditt företag och den andra är ett avsnitt om din blogg). Men de skulle båda ses i Google Analytics som /about, om du inte ställer in följande filter (med hjälp av punkt-asteriskkombination Google Analytics reguljära uttryck):
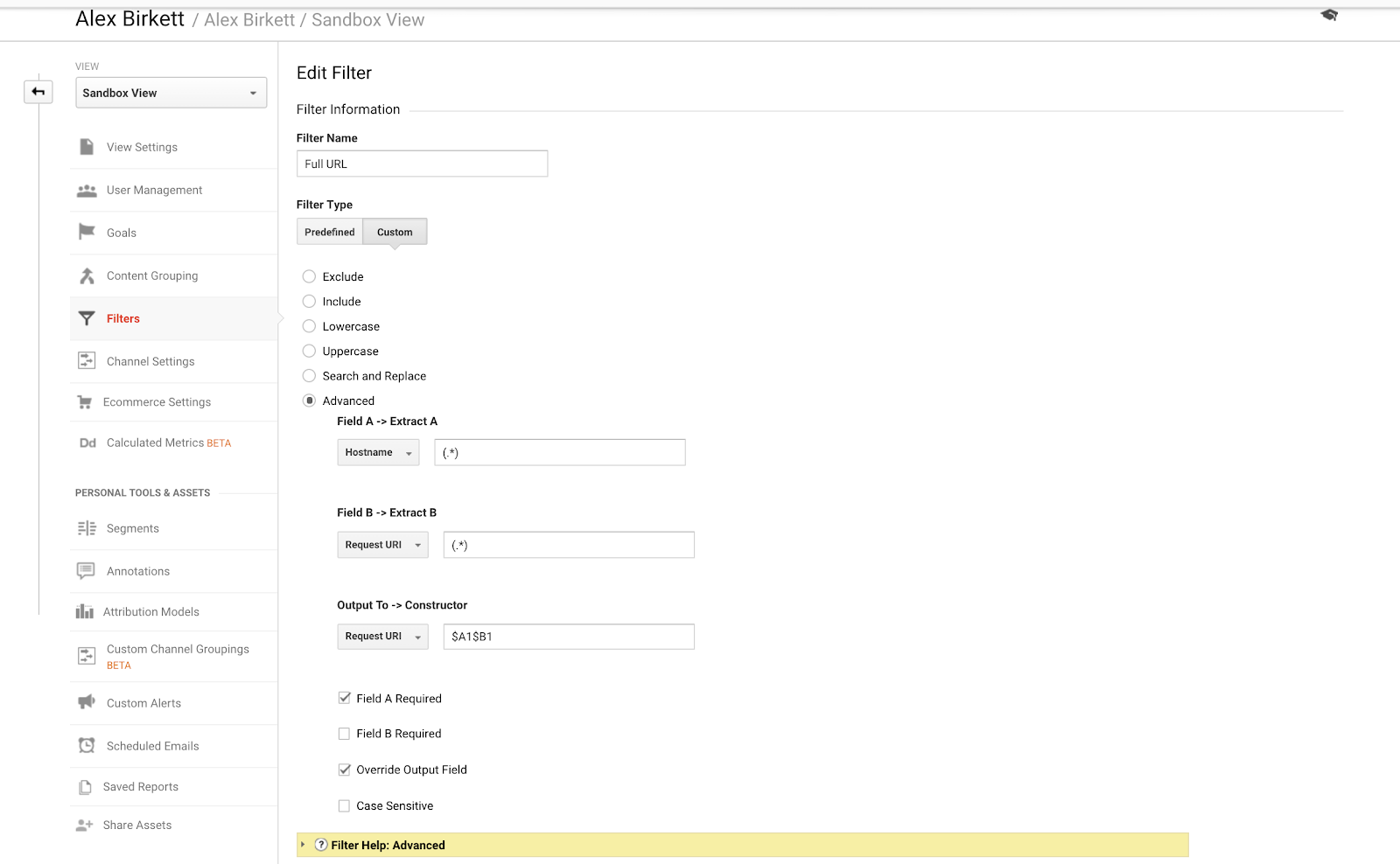
Det är ganska enkelt att ställa in detta grundläggande GA-filter. – bildkälla
Vi har faktiskt redan täckt hur man ställer in dessa filter ganska ingående i ett tidigare KlientBoost-inlägg om spårning över domäner och underdomäner.
Google Analytics RegEx Tips & Misstag att undvika
Reguljära uttryck är en av de där sakerna som du bara måste öva på och få dina händer smutsiga för att lära dig. Som sådan kommer du att göra misstag.
Det är egentligen det viktigaste tipset: prova saker och ting och se om de fungerar. Jag har listat massor av resurser i det här inlägget om hur du testar din regex, från regex101.com till regexbuddy.com. Doppa tårna och använd dessa resurser.
Hur som helst, med lite förarbete och heuristik kan du lära dig snabbare och fånga fler misstag.
En sak att verkligen lära sig är hur man ”escape” i regex (vi pratade om detta om med backslash). Leho Kraav, CTO på CXL Institute, uttrycker det så här:
”Jag skulle säga ”lär dig hur man korrekt undviker saker” – det är lätt att få felmatchningar när tecknen är desamma, men deras innebörd är olika beroende på om de är undvikna eller inte.”
Till exempel, om din fråga har ett frågetecken, är det också ett reguljärt uttryck, så du måste klargöra det med backlash. Chris Mercer, grundare av MeasurementMarketing.io, säger också att det är ett av de största misstagen han ser att nybörjare gör att inte lära sig den här förmågan:
”Det vanligaste misstaget vi ser hos nybörjare som använder regex är att de glömmer att ”escape” regex-symboler. Om du till exempel letar efter sidor som matchar regex ”thankyou/?success=yes” kommer det inte att fungera. Själva ”?” är en regex-symbol och måste avaktiveras med hjälp av ett ”escape-tecken” (” \ ”. I det här fallet skulle ”thankyou/\?success=yes” fungera.”
Ett annat tips? Håll det enkelt. Folk försöker komplicera saker och ting (kolla in den mest komplicerade regex du någonsin sett, skriven av Leho, här), men reguljära uttryck är ”giriga” och kommer att matcha så mycket de kan. Google Analytics publicerade ett blogginlägg med tips och förklarade det så här:
”Om du behöver skriva ett uttryck för att matcha ”nya besök”, och de enda alternativen som du kommer att matcha mot är ”nya besök” och ”upprepade besök”, räcker det med ordet ”nya”.
De kommer att matcha allt de kan, såvida du inte tvingar dem att låta bli. Om ditt uttryck är ”besök” kommer det att matcha ”nya besök” och ”upprepade besök”. Båda innehåller ju trots allt uttrycket ”besök”. För att göra dem mindre giriga måste du göra dem mer specifika.”
Så börja långsamt, håll det enkelt och överväldiga inte dig själv med komplexitet (risken för fel korrelerar med komplexiteten i det här fallet).
Mercer upprepar också den här punkten, och rekommenderar att man tar saker och ting stegvis:
”När du först börjar, fokusera på att bli duktig… och sedan bli bättre. Det är lätt att bli överväldigad av alla olika möjligheter som regex erbjuder dig, men om du bara börjar med grunderna, som att behärska symbolen för ”eller” (” | ”) får du snabbt erfarenhet och börjar inse vad som är möjligt med regex.”
Sista tipset från mig: lär dig att googla saker. Detta gäller för all programmering, men särskilt för reguljära uttryck. Du kommer att glömma saker, och om du inte skriver regex dagligen finns det egentligen ingen mening med att memorera allt. Lär dig att slå upp saker och hitta svar på vad du försöker göra.
Utomhändertagande av Google Analytics: RegEx för andra marknadsföringsändamål
Regex är också något som alla SEO-utövare bör titta på. Först och främst naturligtvis för att SEO och digital analys (t.ex. Google Analytics) är oupplösligt sammanflätade. För det andra för att några av samma matchande uttryck som vi skriver för att filtrera och matcha tecken på våra Google Analytics-data också kan användas vid dataextraktion för SEO-taktik.
Med andra ord är reguljära uttryck viktiga för webbskrapning.
I fråga om webbskrapning och SEO arbetar du vanligtvis med hjälp av ett programmeringsspråk som Python, men principerna är desamma.
Som exempel kan man skrapa all fet text på en sida genom att använda detta:
<strong>(+)</strong>
Och som nämnts i den här SEJ-artikeln, om man skulle skrapa ESPN för alla författare, skulle man kunna skriva så här:
”columnist”:”(.*?)”
För sammanhållningens och förnuftets skull kommer jag inte att dyka ner helt och hållet i avancerad webbskrapning. Det räcker med att veta att regex är viktigt även på detta område. Men om du vill lära dig mer föreslår jag dessa källor:
- Web Scraping with Regular Expressions
- Scraping with Regular Expressions (Stanford)
- How to Use Regex for SEO & Website Data Extraction
Reguljära uttryck hjälper dig också att arbeta med dina SEO-data, bortom att bara skrapa webben. Du kan till exempel använda regex för att ytterligare anpassa hur du använder Screaming Frog.
Jenny Halasz gav ett bra exempel på att använda regex för att rensa upp data i ett inlägg i Search Engine Land:
”Låt oss till exempel säga att du har en lista med webbadresser och att du behöver bryta ner dem till bara TLD (Top Level Domain).
Du kan använda en enkel find/replace för http och www, men hur slår du enkelt bort alla filnamn? Du kan ta bort dem alla manuellt, men det är jobbigt. Med hjälp av ett enkelt regex wildcard (/*) kan du ta bort snedstrecket och allt som kommer efter det.”
Vi skulle kunna prata för evigt om reguljära uttryck för SEO och webscraping, men jag ska bara länka ut till några bra resurser om du vill lära dig mer (det är trots allt ett mycket mångsidigt språk, med många användningsområden bortom analys):
- Hur reguljära uttryck påverkar SEO
- 5 Kraftfulla Awesome Htaccess Redirect Tricks
- Hur man använder reguljära uttryck för segmentering av rapporter
Slutsats
Google Analytics regex är verkligen något som alla analytiker bör känna till, även om du inte tycker att du är så teknisk. Utöver det kan kunskap om vissa reguljära uttryck (eller åtminstone hur man söker efter svar och tillämpar dem på rätt problem) hjälpa marknadsförare med olika aktiviteter också.
Just saying, it’s not a very common skill set, so you’ll probably impress some colleagues with your newfound technical marketing skills.
So I urge you, start learning, and more importantly, just start practicing using regular expressions. De är inte så skrämmande.